A Factory-Floor Deployment Case Study of VLA Pipelines for Industrial Packaging Task: Workflow, Failures, and Lessons
Pith reviewed 2026-06-29 21:14 UTC · model grok-4.3
The pith
Deploying a pretrained VLA policy to a factory packaging task requires repeated cycles of on-site data collection and fine-tuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
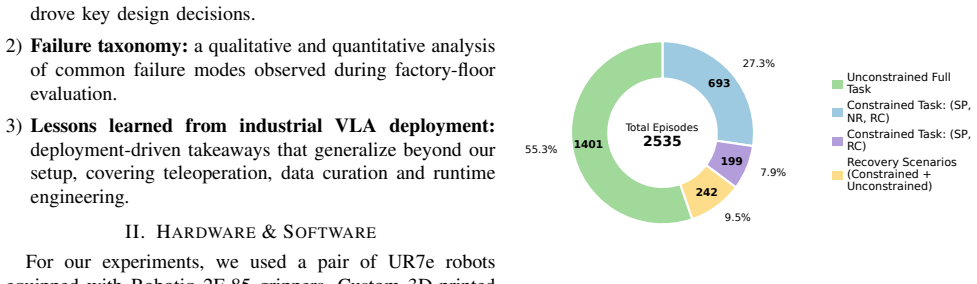
The paper contributes an empirical account of adapting a Pi0.5 policy to a factory packaging task through an iterative pipeline of data collection, curation, fine-tuning, evaluation, and targeted recovery data collection, resulting in 2535 episodes from the factory floor and documentation of recurring failure modes.
What carries the argument
The iterative deployment pipeline of data collection, curation, fine-tuning, evaluation, and recovery data collection that refines the policy based on observed failures.
If this is right
- The workflow allows adaptation of pretrained policies to specific factory tasks.
- Targeted collection of recovery data addresses particular failure modes.
- Real factory settings expose failure modes not apparent in controlled environments.
- Accumulating on-site data improves the policy's performance on the task.
Where Pith is reading between the lines
- This approach may indicate that each new industrial task demands substantial custom data collection.
- Similar iterative methods could be tested on other manipulation tasks to see if the lessons generalize.
- Future work could add quantitative success metrics to better assess the pipeline's effectiveness.
Load-bearing premise
That the failure modes and workflow lessons observed in this single packaging task at one factory are representative for broader VLA deployment practices.
What would settle it
Finding that a one-time fine-tuning without the iterative recovery loops achieves comparable or better results on the same task would undermine the necessity of the described pipeline.
Figures


read the original abstract
Vision-Language-Action (VLA) policies have shown promising manipulation capabilities, yet their practical impact is often limited by the reliability demands of real-world deployment. We present a deployment study of an industrial packaging task at Siemens Factory (GWE, Erlangen, Germany), where a robot must pick a transparent accessory bag from a cluttered pile, insert it into the remaining cavity of a cardboard package, and ensure that the bag and its contents remain below the closing plane. Our goal is to understand the practical effort required to adapt a pretrained Pi0.5 policy to a single factory-floor task through iterative fine-tuning and deployment-driven refinement. The pipeline consists of repeated loops of data collection, curation, fine-tuning, evaluation, and targeted recovery data collection. We have accumulated 2535 episodes (10 hours) from the on-site factory settings. In this paper, we contribute an empirical account of a factory-floor VLA deployment, highlighting recurring failure modes and lessons that inform how to improve the deployment workflow.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a deployment case study of adapting a pretrained Pi0.5 Vision-Language-Action (VLA) policy to a single industrial packaging task at the Siemens Factory (GWE, Erlangen). The task requires picking a transparent accessory bag from a cluttered pile and inserting it into a cardboard package while ensuring contents remain below the closing plane. The authors describe an iterative workflow of data collection, curation, fine-tuning, evaluation, and targeted recovery data collection, resulting in 2535 episodes (10 hours) collected on-site, and contribute an empirical account of recurring failure modes and workflow lessons for VLA deployment.
Significance. A well-documented factory-floor VLA deployment study could offer valuable practical guidance on the effort and failure modes involved in adapting pretrained policies to industrial settings, an area with limited published evidence. However, without quantitative performance data the contribution remains primarily anecdotal and does not yet establish the effectiveness or generalizability of the described iterative pipeline.
major comments (1)
- [Abstract] Abstract: The central claim that the iterative fine-tuning loops and 2535 episodes produce transferable lessons about failure modes and workflow improvements for general VLA deployment is not supported by any reported quantitative metrics (success rates, failure frequencies per iteration, recovery rates, or comparisons to the base Pi0.5 policy), leaving the practical informativeness of the workflow unverified beyond qualitative description.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback highlighting the need to align the abstract's claims with the manuscript's qualitative scope. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the iterative fine-tuning loops and 2535 episodes produce transferable lessons about failure modes and workflow improvements for general VLA deployment is not supported by any reported quantitative metrics (success rates, failure frequencies per iteration, recovery rates, or comparisons to the base Pi0.5 policy), leaving the practical informativeness of the workflow unverified beyond qualitative description.
Authors: We agree that the abstract's language implies broader transferability than the single-case-study evidence supports. The manuscript is positioned as an empirical account of workflow, failure modes, and lessons observed during on-site adaptation of the Pi0.5 policy, based on direct experience with 2535 episodes. No quantitative success rates, iteration-wise failure frequencies, or baseline comparisons are reported because the contribution centers on documenting the iterative data-collection and refinement process rather than benchmarking policy performance. We will revise the abstract to explicitly frame the lessons as observational insights from this specific industrial deployment, without claiming statistical validation or generalizability to other VLA tasks. This change will be incorporated in the revised manuscript. revision: yes
Circularity Check
Purely descriptive empirical case study with no derivations or fitted predictions
full rationale
The paper is an empirical deployment report describing a workflow of data collection, fine-tuning, and evaluation on 2535 episodes for one industrial task. It contains no equations, no parameter fitting presented as prediction, no uniqueness theorems, and no self-citation chains that reduce the central claims to inputs by construction. The contribution is an observational account of failure modes and lessons; the derivation chain is absent, so no circularity exists.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Openvla: An open-source vision-language-action model, 2024
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. Openvla: An open-source vision-language-action model, 2024
2024
-
[2]
Gr00t n1: An open foundation model for generalist humanoid robots, 2025
NVIDIA, :, Johan Bjorck, Fernando Casta ˜neda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi ”Jim” Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, Joel Jang, Zhenyu Jiang, Jan Kautz, Kaushil Kundalia, Lawrence Lao, Zhiqi Li, Zongyu Lin, Kevin Lin, Guilin Liu, Edith Llontop, Loic Magne, Ajay Mandlekar, Avnish Narayan, Soroush Nasiriany, Scott Reed,...
2025
-
[3]
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xi- aoyang Shi, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, and Ury Zhilinsky.π 0: A vi...
2026
-
[4]
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Manuel Y . Galliker, Dibya Ghosh, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Devin LeBlanc, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsc...
2025
-
[5]
J. Wang, M. Leonard, K. Daniilidis, D. Jayaraman, and E. S. Hu. Evaluating pi0 in the wild: Strengths, problems, and the future of generalist robot policies, 2025
2025
-
[6]
Unfolding robotics: The open-source recipe for teaching a robot to fold your clothes, 2026
Pepijn Kooijmans, Michel Aractingi, Steven Palma, Caroline Pascal, Jade Choghari, Khalil Meftah, Martino Russi, Nicolas Rabault, Virgile Batto, Leandro von Werra, and Thomas Wolf. Unfolding robotics: The open-source recipe for teaching a robot to fold your clothes, 2026
2026
-
[7]
Galliker, and Sergey Levine
Kevin Black, Manuel Y . Galliker, and Sergey Levine. Real-time execution of action chunking flow policies, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.