CogPortrait: Fine-Grained Eye-Region Control in Portrait Animation via Hierarchical Agent Planning
Pith reviewed 2026-06-29 13:00 UTC · model grok-4.3
The pith
CogPortrait translates high-level labels into precise eye-region keypoints using three chain-of-thought MLLM agents before synthesizing animations in a DiT backbone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
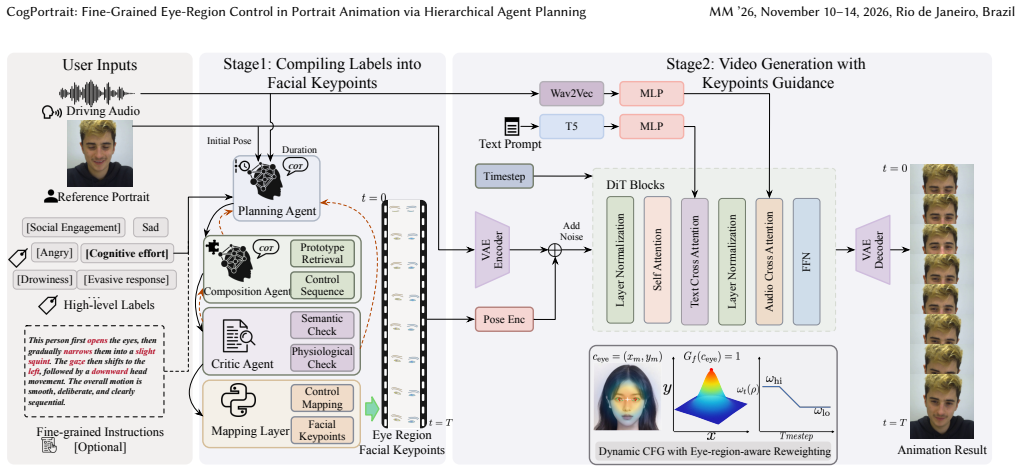
The central discovery is a two-stage pipeline in which three chain-of-thought MLLM agents compile high-level labels into temporally coherent facial keypoints drawn from a real-behavior library and refined by semantic-physiological constraints; these keypoints then drive a DiT-based generator that incorporates dynamic classifier-free guidance with eye-region reweighting and KTO refinement, yielding animations that achieve finer eye-region control than prior label-driven or video-driven methods while retaining superior visual quality and identity consistency on both the HDTF dataset and the introduced EMH benchmark.
What carries the argument
Three chain-of-thought MLLM agents performing temporal event planning, prototype retrieval from a real-behavior library, and semantic-physiological constraint enforcement to convert high-level labels into facial-keypoint sequences.
If this is right
- High-level emotion and state labels become sufficient input for controlling subtle, non-emotional eye behaviors such as thinking or drowsiness.
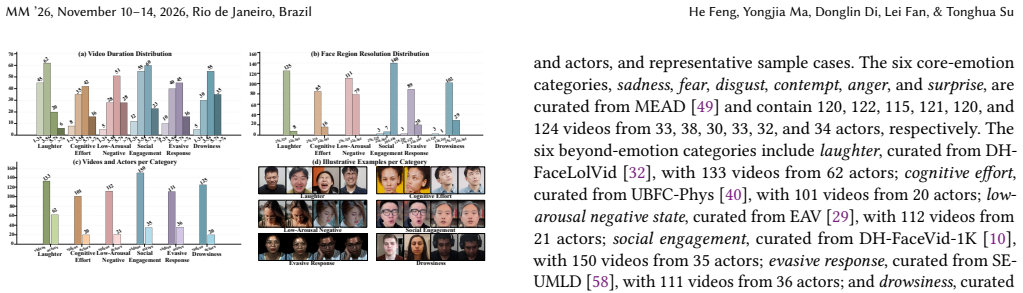
- The EMH benchmark supplies AU-level metrics that quantify fine-grained eye-region and head-motion fidelity separately from overall visual quality.
- Dynamic classifier-free guidance with eye-region reweighting plus KTO refinement improves handling of boundary cases without degrading identity consistency.
- The two-stage separation allows the keypoint planner to be swapped or extended independently of the DiT video backbone.
Where Pith is reading between the lines
- If the same agent-planning pattern works for eye keypoints, analogous libraries and planners could be built for mouth, eyebrow, or hand motion in full-body animation.
- Replacing the offline MLLM stage with a distilled model could enable interactive, label-driven portrait editing at runtime.
- The approach implies that MLLMs can serve as semantic-to-motion translators in other animation domains where direct supervision is scarce.
Load-bearing premise
The MLLM agents can convert high-level labels into accurate temporal keypoint sequences from the real-behavior library without introducing systematic errors for states outside basic emotions.
What would settle it
On the EMH benchmark, measure AU-level eye and head motion accuracy of CogPortrait outputs against ground-truth sequences for thinking or drowsiness labels; if the error exceeds that of driving-video baselines while visual quality also drops, the central claim fails.
Figures



read the original abstract
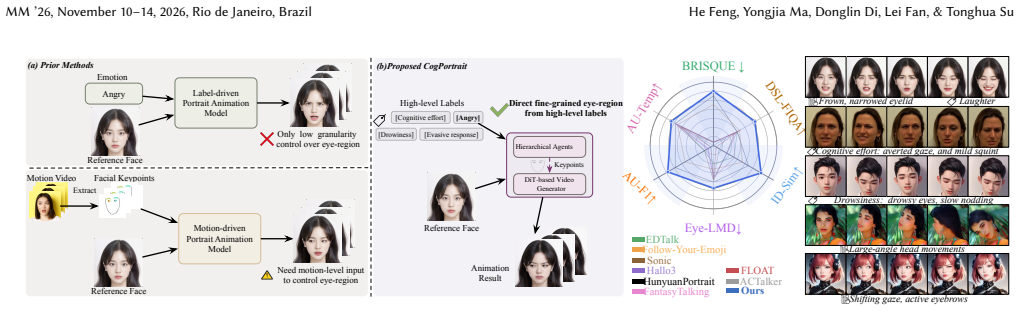
Portrait animation methods have achieved substantial visual quality and lip synchronization, but fine-grained manipulation of the eye region still faces a trade-off between input granularity and motion accuracy. Existing methods using emotion labels or coarse text prompts are insufficient for describing subtle ocular dynamics, whereas approaches based on Action Units or driving videos provide higher fidelity at the cost of a heavier input burden. These limitations are still restrictive for beyond-emotion states (e.g., thinking) and drowsiness. In light of the above, we propose CogPortrait, a two-stage framework that generates portrait animations from high-level labels. In the first stage, three chain-of-thought Multimodal Large Language Models (MLLMs) agents compile high-level labels into facial keypoints through temporal event planning, prototype retrieval, and composition from a real-behavior library, and semantic-physiological constraint enforcement. In the second stage, a DiT-based video generation backbone synthesizes the final animation conditioned on the keypoints, reference portrait, audio, and text prompt, enhanced by a dynamic classifier-free guidance strategy with eye-region-aware reweighting and KTO-based refinement for boundary cases. We further introduce the EMH benchmark covering diverse emotions and beyond-emotion categories with two AU-level metrics for evaluating fine-grained eye-region and head-motion control. Extensive experiments on HDTF and the EMH benchmark demonstrate that CogPortrait achieves more precise eye-region control than existing methods while maintaining supe- rior visual quality and identity consistency
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CogPortrait, a two-stage framework for portrait animation from high-level labels. Stage 1 uses three chain-of-thought MLLM agents for temporal event planning, prototype retrieval/composition from a real-behavior library, and semantic-physiological constraint enforcement to produce facial keypoint sequences. Stage 2 employs a DiT-based video generator conditioned on the keypoints, reference image, audio, and text, with dynamic classifier-free guidance (eye-region-aware reweighting) and KTO refinement. A new EMH benchmark is introduced with AU-level metrics for eye-region and head-motion evaluation. Experiments on HDTF and EMH claim superior eye-region control, visual quality, and identity consistency over prior methods.
Significance. If the central claims hold with proper validation, the work could meaningfully advance fine-grained, high-level control in portrait animation by addressing limitations of emotion labels, coarse text, or driving videos, particularly for beyond-emotion states like thinking or drowsiness. The hierarchical agent approach and new benchmark with AU metrics represent a potentially useful direction for controllable generation.
major comments (2)
- [Method (agent pipeline) and Experiments] The central claim of more precise eye-region control (abstract and § on experiments) rests on the three CoT MLLM agents producing temporally accurate keypoint sequences from high-level labels, especially for beyond-emotion states. No intermediate quantitative metrics are reported on agent output accuracy (e.g., keypoint L2 error vs. ground-truth extracted keypoints, AU activation F1, or temporal alignment scores), so end-to-end HDTF/EMH metrics do not isolate whether gains derive from better keypoints or from the DiT enhancements.
- [EMH benchmark definition and evaluation protocol] The EMH benchmark is presented with two AU-level metrics, but the manuscript does not report baseline comparisons or ablations that would confirm the metrics isolate eye-region control independent of overall motion quality or identity preservation.
minor comments (1)
- [DiT stage description] Notation for the dynamic CFG reweighting and KTO refinement could be clarified with explicit equations or pseudocode to show how eye-region awareness is implemented.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and agree that additional analyses will strengthen the isolation of contributions and validation of the benchmark.
read point-by-point responses
-
Referee: [Method (agent pipeline) and Experiments] The central claim of more precise eye-region control (abstract and § on experiments) rests on the three CoT MLLM agents producing temporally accurate keypoint sequences from high-level labels, especially for beyond-emotion states. No intermediate quantitative metrics are reported on agent output accuracy (e.g., keypoint L2 error vs. ground-truth extracted keypoints, AU activation F1, or temporal alignment scores), so end-to-end HDTF/EMH metrics do not isolate whether gains derive from better keypoints or from the DiT enhancements.
Authors: We agree that the absence of intermediate metrics on the agent outputs limits the ability to isolate the source of improvements. In the revised manuscript, we will add quantitative evaluations of the three MLLM agents, including keypoint L2 error against ground-truth keypoints, AU activation F1 scores, and temporal alignment metrics computed on a held-out validation set from the behavior library. These will be reported alongside the end-to-end results to clarify the contribution of the hierarchical planning stage. revision: yes
-
Referee: [EMH benchmark definition and evaluation protocol] The EMH benchmark is presented with two AU-level metrics, but the manuscript does not report baseline comparisons or ablations that would confirm the metrics isolate eye-region control independent of overall motion quality or identity preservation.
Authors: We acknowledge that further validation is needed to confirm the metrics' specificity. In the revision, we will add baseline method comparisons on the EMH benchmark using the proposed AU-level metrics and include targeted ablations (such as metrics computed with vs. without eye-region conditioning) to demonstrate that the metrics isolate fine-grained eye-region and head-motion control from general visual quality and identity preservation factors. revision: yes
Circularity Check
No circularity: claims rest on external benchmarks and new dataset, not internal redefinitions
full rationale
The paper describes a two-stage pipeline (MLLM agents for keypoint sequences from labels, followed by DiT synthesis with dynamic CFG and KTO) whose performance is asserted via experiments on HDTF and the newly introduced EMH benchmark using AU-level metrics. No equations, fitted parameters, or self-citations are presented that reduce any prediction or uniqueness claim to the inputs by construction. The central claims therefore remain empirically falsifiable against external data rather than tautological.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Oleg Alexander, Mike Rogers, et al. 2010. The digital Emily project: Achieving a photorealistic digital actor.IEEE Comput. Graph. Appl.30, 4 (2010), 20–31
2010
-
[2]
Alexei Baevski, Yuhao Zhou, et al . 2020. wav2vec 2.0: A framework for self- supervised learning of speech representations. InNeurIPS. 12449–12460
2020
-
[3]
Ryan Canales, Eakta Jain, et al. 2023. Real-time conversational gaze synthesis for avatars. InMIG. 1–7
2023
- [4]
-
[5]
Wei-Ting Chen, Gurunandan Krishnan, et al. 2024. DSL-FIQA: Assessing facial image quality via dual-set degradation learning and landmark-guided transformer. InCVPR. 2931–2941
2024
-
[6]
Zhiyuan Chen, Jiajiong Cao, et al. 2025. EchoMimic: Lifelike audio-driven portrait animations through editable landmark conditioning. InAAAI
2025
-
[7]
Jiahao Cui, Hui Li, et al. 2025. Hallo2: Long-duration and high-resolution audio- driven portrait image animation. InICLR
2025
-
[8]
Jiahao Cui, Hui Li, et al . 2025. Hallo3: Highly dynamic and realistic portrait image animation with diffusion transformer networks. InCVPR
2025
-
[9]
Jiankang Deng, Jia Guo, et al. 2019. ArcFace: Additive angular margin loss for deep face recognition. InCVPR. 4690–4699
2019
- [10]
-
[11]
Nina Döllinger, Erik Wolf, et al . 2023. Are embodied avatars harmful to our self-experience? The impact of virtual embodiment on body awareness. InCHI. 1–14
2023
-
[12]
Nikita Drobyshev, Jenya Chelishev, et al . 2022. MegaPortraits: One-shot megapixel neural head avatars. InACM MM. 2663–2671
2022
-
[13]
Kawin Ethayarajh, Winnie Xu, et al. 2024. KTO: Model alignment as prospect theory.arXiv preprint arXiv:2402.01306(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [14]
- [15]
-
[16]
Maia Garau, Mel Slater, et al. 2003. The impact of avatar realism and eye gaze control on perceived quality of communication in a shared immersive virtual environment. InCHI. 529–536
2003
-
[17]
Reza Ghoddoosian, Marnim Galib, et al. 2019. A realistic dataset and baseline temporal model for early drowsiness detection. InCVPRW
2019
- [18]
-
[19]
Siddharth Gururani, Arun Mallya, et al. 2023. SPACE: Speech-driven portrait animation with controllable expression. InICCV. 20914–20923
2023
-
[20]
Tiankai Hang, Huan Yang, et al . 2023. Language-Guided Face Animation by Recurrent StyleGAN-Based Generator.IEEE Transactions on Multimedia(2023), 1–12
2023
-
[21]
Martin Heusel, Hubert Ramsauer, et al. 2017. GANs trained by a two time-scale update rule converge to a local Nash equilibrium. InNeurIPS
2017
-
[22]
Fa-Ting Hong, Zunnan Xu, et al. 2025. Audio-visual controlled video diffusion with masked selective state spaces modeling for natural talking head generation. InICCV
2025
-
[23]
Li Hu. 2024. Animate anyone: Consistent and controllable image-to-video syn- thesis for character animation. InCVPR. 8153–8163
2024
-
[24]
Xiaozhong Ji, Xiaobin Hu, et al . 2025. Sonic: Shifting focus to global audio perception in portrait animation. InCVPR. 193–203
2025
-
[25]
Cheng Jin, Qitan Shi, et al. 2026. Stage-wise dynamics of classifier-free guidance in diffusion models. InICLR
2026
-
[26]
Taekyung Ki, Dongchan Min, et al. 2025. FLOAT: Generative motion latent flow matching for audio-driven talking portrait. InICCV. 14699–14710
2025
-
[27]
Diederik P Kingma. 2013. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114(2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[28]
Jiye Lee, Chenghui Li, et al. 2025. Audio driven real-time facial animation for social telepresence. InSIGGRAPH Asia. 1–12
2025
-
[29]
Min-Ho Lee, Adai Shomanov, et al . 2024. EAV: EEG-audio-video dataset for emotion recognition in conversational contexts.Scientific Data11, 1 (2024), 1026
2024
- [30]
-
[31]
Yaron Lipman, Ricky T. Q. Chen, et al . 2023. Flow matching for generative modeling. InICLR
2023
-
[32]
Huaize Liu, Wenzhang Sun, et al. 2025. MoEE: Mixture of emotion experts for audio-driven portrait animation. InCVPR
2025
-
[33]
Camillo Lugaresi, Jiuqiang Tang, et al. 2019. MediaPipe: A framework for building perception pipelines.arXiv preprint arXiv:1906.08172(2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[34]
Jiayi Lyu, Leigang Qu, et al . 2026. AUHead: Realistic emotional talking head generation via action units control. InICLR
2026
-
[35]
Yue Ma, Hongyu Liu, et al . 2024. Follow-your-emoji: Fine-controllable and expressive freestyle portrait animation. InSIGGRAPH Asia. 1–12
2024
-
[36]
Yifeng Ma, Jinwei Qi, et al. 2025. Exploring timeline control for facial motion generation. InCVPR
2025
-
[37]
Anish Mittal, Anush Krishna Moorthy, and Alan Conrad Bovik. 2012. No- Reference Image Quality Assessment in the Spatial Domain.IEEE Transactions on Image Processing21, 12 (2012), 4695–4708
2012
-
[38]
Colin Raffel, Noam Shazeer, Adam Roberts, et al. 2020. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer.Journal of Machine Learning Research21, 140 (2020), 1–67
2020
-
[39]
Andre Rochow, Max Schwarz, et al . 2024. FSRT: Facial scene representation transformer for face reenactment from factorized appearance, head-pose, and facial expression features. InCVPR. 7716–7726
2024
-
[40]
Rita Meziati Sabour, Yannick Benezeth, et al. 2023. UBFC-Phys: A multimodal database for psychophysiological studies of social stress.TAFFC14, 1 (2023), 622–636
2023
-
[41]
Seyedmorteza Sadat, Otmar Hilliges, et al. 2024. Eliminating oversaturation and artifacts of high guidance scales in diffusion models. InICLR
2024
-
[42]
Achint Soni, Sreyas Venkataraman, et al. 2025. VideoAgent: Self-improving video generation for embodied planning. InNeurIPS Workshop
2025
-
[43]
Michal Stypulkowski, Konstantinos Vougioukas, et al . 2024. Diffused heads: Diffusion models beat GANs on talking-face generation. InW ACV. 5091–5100
2024
- [44]
-
[45]
Shuai Tan, Bin Ji, et al. 2025. EDTalk: Efficient disentanglement for emotional talking head synthesis. InECCV. 398–416
2025
-
[46]
Linrui Tian, Qi Wang, et al. 2025. EMO: Emote portrait alive generating expressive portrait videos with audio2video diffusion model under weak conditions. InECCV. 244–260
2025
-
[47]
Team Wan, Ang Wang, et al. 2025. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
Jiawen Wang, Jingjing Wang, et al. 2026. Towards closed-loop embodied empathy evolution: Probing LLM-centric lifelong empathic motion generation in unseen scenarios. InAAAI, Vol. 40. 33539–33547
2026
-
[49]
Kaisiyuan Wang, Qianyi Wu, et al . 2020. MEAD: A large-scale audio-visual dataset for emotional talking-face generation. InECCV. 700–717
2020
-
[50]
Mengchao Wang, Qiang Wang, et al . 2025. FantasyTalking: Realistic talking portrait generation via coherent motion synthesis. InACM MM. 9891–9900
2025
-
[51]
Ting-Chun Wang, Ming-Yu Liu, et al. 2018. Video-to-video synthesis. InNeurIPS. 1152–1164
2018
- [52]
- [53]
-
[54]
Jason Wei, Xuezhi Wang, et al. 2022. Chain-of-thought prompting elicits reason- ing in large language models. InNeurIPS. 24824–24837
2022
- [55]
- [56]
- [57]
-
[58]
Xiaolin Xu, Wenming Zheng, et al. 2025. Multimodal lie detection dataset based on Chinese dialogue.Journal of Image and Graphics30, 8 (2025), 2729–2742
2025
- [59]
-
[60]
Zunnan Xu, Zhentao Yu, et al. 2025. HunyuanPortrait: Implicit condition control for enhanced portrait animation. InCVPR. 15909–15919
2025
- [61]
-
[62]
Shurong Yang, Huadong Li, et al. 2025. MegActor- Σ: Unlocking flexible mixed- modal control in portrait animation with diffusion transformer. InAAAI
2025
-
[63]
Zhuoyi Yang, Jiayan Teng, et al. 2025. CogVideoX: Text-to-video diffusion models with an expert transformer. InICLR
2025
-
[64]
Jianhui Yu, Hao Zhu, et al . 2023. CelebV-Text: A large-scale facial text-video dataset. InCVPR. 14805–14814
2023
-
[65]
Shuyan Zhai, Meng Liu, et al. 2023. Talking face generation with audio-deduced emotional landmarks.TNNLS(2023)
2023
-
[66]
Lisai Zhang, Baohan Xu, et al. 2025. AniME: Adaptive multi-agent planning for long animation generation. InSIGGRAPH Asia. 1–3
2025
-
[67]
Richard Zhang, Phillip Isola, et al. 2018. The unreasonable effectiveness of deep features as a perceptual metric. InCVPR. 586–595
2018
-
[68]
Wenxuan Zhang, Xiaodong Cun, et al. 2023. SadTalker: Learning realistic 3D motion coefficients for stylized audio-driven single image talking face animation. CogPortrait: Fine-Grained Eye-Region Control in Portrait Animation via Hierarchical Agent Planning MM ’26, November 10–14, 2026, Rio de Janeiro, Brazil InCVPR. 8652–8661
2023
-
[69]
Zhimeng Zhang, Lincheng Li, et al . 2021. Flow-guided one-shot talking face generation with a high-resolution audio-visual dataset. InCVPR. 3661–3670
2021
-
[70]
Ziqi Zhou, Weize Quan, et al. 2025. GoHD: Gaze-oriented and highly disentangled portrait animation with rhythmic poses and realistic expressions. InAAAI, Vol. 39. 10914–10922
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.