SuperValid: Capability-Aligned OOD Validation for Generalizable Downstream Scaling
Pith reviewed 2026-06-29 12:54 UTC · model grok-4.3
The pith
SuperValid creates capability-aligned out-of-distribution validation data whose loss tracks downstream performance across models and training distributions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
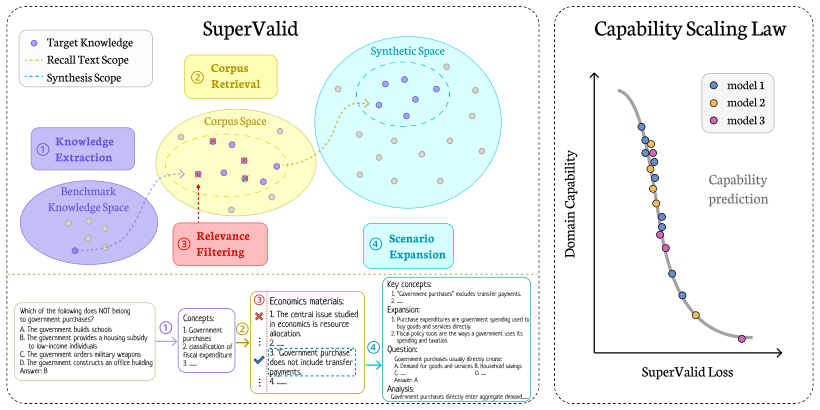
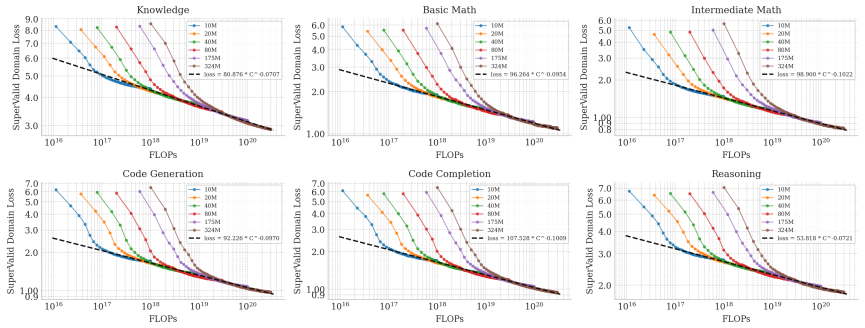
SuperValid synthesizes OOD capability-aligned validation data by distilling core concepts from benchmarks within a capability domain and expanding them into diverse, knowledge-rich texts. Extensive experiments across 17 benchmarks in 6 domains show that the resulting SuperValid loss exhibits strong and stable correlation with downstream performance across models of different architectures, scales, and training data distributions. As a training-free metric, it enables effective model selection, early stopping, and scaling decisions without benchmark evaluation.
What carries the argument
SuperValid framework that generates capability-aligned OOD validation data via concept distillation and text expansion.
If this is right
- Model selection during training can rely on SuperValid loss instead of benchmark runs.
- Early stopping decisions become feasible using the capability-aligned metric.
- Scaling laws can be applied at the capability domain level for more general predictions.
- The metric remains effective when training data distributions differ from evaluation data.
Where Pith is reading between the lines
- The synthesis process could be adapted to define capabilities in non-language domains.
- Capability-level validation might reduce the need for ever-growing suites of fixed benchmarks.
- The approach suggests that shared factors across tasks are more stable predictors than task-specific scores.
Load-bearing premise
Distilling core concepts from benchmarks within a capability domain and expanding them into diverse texts produces validation data that captures shared skill factors while abstracting away benchmark-specific noise.
What would settle it
A new set of models or training runs where SuperValid loss shows no reliable correlation with measured downstream performance on the grouped benchmarks.
Figures




read the original abstract
Scaling laws guide large language model training by relating compute to cross-entropy loss, and recent work further extends them to predict downstream benchmark performance. However, prior approaches face generalization limitations from two aspects: focusing on benchmark-level performance introduces scenario-specific artifacts, while relying on IID validation loss fails to track capability improvements when training distributions vary. In this work, we argue that downstream scaling should be studied at the capability level, which captures shared skill factors across related tasks while abstracting away benchmark-specific noise. We propose SuperValid, a framework that synthesizes OOD (out-of-distribution), capability-aligned validation data by distilling core concepts from benchmarks within a capability domain and expanding them into diverse, knowledge-rich texts. Extensive experiments spanning 17 benchmarks grouped into 6 capability domains show that SuperValid loss exhibits strong and stable correlation with downstream performance across models of different architectures, scales, and training data distributions. As a training-free metric computable during training without benchmark evaluation, SuperValid enables effective model selection, early stopping, and scaling decisions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SuperValid, a framework that distills core concepts from 17 benchmarks grouped into 6 capability domains and expands them into diverse OOD texts to create capability-aligned validation data. It claims that the resulting SuperValid loss exhibits strong and stable correlation with downstream benchmark performance across models differing in architecture, scale, and training distributions, outperforming IID validation loss and enabling training-free decisions for model selection, early stopping, and scaling.
Significance. If the reported correlations are robust and the synthesis isolates shared capability factors rather than benchmark artifacts, the work would meaningfully extend scaling-law research by supplying a generalizable, training-free validation signal that addresses limitations of both benchmark-specific and IID approaches. The experiments spanning multiple architectures and distributions would constitute a useful empirical contribution if properly quantified and controlled.
major comments (2)
- [Methods / Experiments (synthesis pipeline and correlation analysis)] The central empirical claim (strong, stable correlation with downstream performance) rests on the assertion that the synthesis pipeline abstracts away benchmark-specific noise while retaining shared skill factors. However, no ablation or verification is described that tests whether correlations persist after removing benchmark-derived phrases or surface patterns from the generated texts; without such controls, the results across architectures and scales remain consistent with retention of task-specific artifacts.
- [Abstract and Experiments] The abstract states that SuperValid loss 'exhibits strong and stable correlation' but supplies no quantitative values (Pearson r, Spearman ρ, confidence intervals, or per-domain breakdowns). The experiments section must report these metrics together with error analysis and exclusion criteria for the 17 benchmarks; absent such numbers, the strength of evidence for generalizability cannot be evaluated.
minor comments (2)
- [§3] Clarify the exact procedure for grouping the 17 benchmarks into the 6 capability domains and state whether this grouping was determined a priori or post hoc.
- [Introduction / Methods] The term 'capability-aligned' is used repeatedly; provide an explicit operational definition or metric for alignment in the methods section.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and indicate planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Methods / Experiments (synthesis pipeline and correlation analysis)] The central empirical claim (strong, stable correlation with downstream performance) rests on the assertion that the synthesis pipeline abstracts away benchmark-specific noise while retaining shared skill factors. However, no ablation or verification is described that tests whether correlations persist after removing benchmark-derived phrases or surface patterns from the generated texts; without such controls, the results across architectures and scales remain consistent with retention of task-specific artifacts.
Authors: We agree that explicit ablations removing benchmark-derived phrases would provide stronger verification that correlations arise from shared capability factors. The synthesis distills core concepts and expands into diverse texts to reduce surface patterns, but such targeted controls were not included originally. We will add these ablations, reporting correlation changes before and after phrase removal, in the revision. revision: yes
-
Referee: [Abstract and Experiments] The abstract states that SuperValid loss 'exhibits strong and stable correlation' but supplies no quantitative values (Pearson r, Spearman ρ, confidence intervals, or per-domain breakdowns). The experiments section must report these metrics together with error analysis and exclusion criteria for the 17 benchmarks; absent such numbers, the strength of evidence for generalizability cannot be evaluated.
Authors: We agree that quantitative metrics, error analysis, and exclusion criteria should be reported explicitly. While experiments contain correlation results, we will revise the abstract to include key values (e.g., Pearson r, Spearman ρ with intervals and per-domain breakdowns) and expand the experiments section with full metrics, error analysis, and benchmark exclusion criteria. revision: yes
Circularity Check
No significant circularity; empirical correlation claim is independent of inputs.
full rationale
The paper presents an empirical method (SuperValid synthesis from benchmark concepts) followed by reported correlations across models, scales, and distributions. No mathematical derivation, fitted parameter renamed as prediction, or self-citation chain is described that reduces the central claim to its own construction. The synthesis pipeline and downstream correlation measurements remain separable; any retained benchmark artifacts would be a validity issue rather than a definitional reduction. This is the common case of a self-contained empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Program Synthesis with Large Language Models
Proxylm: Predicting language model perfor- mance on multilingual tasks via proxy models. In Findings of the Association for Computational Lin- guistics: NAACL 2025, pages 1981–2011. Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and 1 others. 2021. Program synthes...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Amir Feder, Yoav Wald, Claudia Shi, Suchi Saria, and David Blei
Understanding emergent abilities of language models from the loss perspective.Advances in neural information processing systems, 37:53138–53167. Amir Feder, Yoav Wald, Claudia Shi, Suchi Saria, and David Blei. 2023. Data augmentations for improved (large) language model generalization.Advances in Neural Information Processing Systems, 36:70638– 70653. Sam...
2023
-
[3]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language under- standing.arXiv preprint arXiv:2009.03300. Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Ja- cob Steinhardt. 2021. Measuring mathematical prob- lem solving with the math dataset.arXiv preprint arXiv:2103.03874. Jordan Hoffmann, Sebastian Borgeaud, Arthur Men- s...
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[4]
C-eval: A multi-level multi-discipline chinese evaluation suite for foundation models.Advances in neural information processing systems, 36:62991– 63010. Berivan Isik, Natalia Ponomareva, Hussein Hazimeh, Dimitris Paparas, Sergei Vassilvitskii, and Sanmi Koyejo. 2024. Scaling laws for downstream task per- formance of large language models. InICLR 2024 Wor...
-
[5]
Challenges and applications of large language models.arXiv preprint arXiv:2307.10169. Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361. Pang Wei Koh, Shiori Sagawa, Henrik Mark- lund, Sa...
-
[6]
InInternational conference on machine learning, pages 5637–5664
Wilds: A benchmark of in-the-wild distribu- tion shifts. InInternational conference on machine learning, pages 5637–5664. PMLR. Woosung Koh, Juyoung Suk, Sungjun Han, Se-Young Yun, and Jamin Shin. 2025. Predicting llm reasoning performance with small proxy model.arXiv preprint arXiv:2509.21013. Ang Li, Ben Liu, Binbin Hu, Bing Li, Bingwei Zeng, Borui Ye, ...
-
[7]
Oodbench: Out-of-distribution benchmark for large vision-language models.arXiv preprint arXiv:2602.18094. Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, and 1 others
-
[8]
Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437. Hong Liu, Sang Michael Xie, Zhiyuan Li, and Tengyu Ma. 2023a. Same pre-training loss, better down- stream: Implicit bias matters for language models. InInternational Conference on Machine Learning, pages 22188–22214. PMLR. Jiacheng Liu, Taylor Blanton, Yanai Elazar, Sewon Min, Yen-Sung Chen, Ar...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Advances in Neural Information Processing Systems, 36:50358–50376
Scaling data-constrained language models. Advances in Neural Information Processing Systems, 36:50358–50376. David Owen. 2024. How predictable is language model benchmark performance?arXiv preprint arXiv:2401.04757. Guilherme Penedo, Hynek Kydlíˇcek, Anton Lozhkov, Margaret Mitchell, Colin Raffel, Leandro V on Werra, Thomas Wolf, and 1 others. 2024. The f...
-
[10]
Language Models are Multilingual Chain-of-Thought Reasoners
Language models are multilingual chain-of- thought reasoners.arXiv preprint arXiv:2210.03057. Lakpa Tamang, Mohamed Reda Bouadjenek, Richard Dazeley, and Sunil Aryal. 2025. Handling out-of- distribution data: A survey.IEEE Transactions on Knowledge and Data Engineering. Zhengyang Tang, Xingxing Zhang, Benyou Wang, and Furu Wei. 2024. Mathscale: Scaling in...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Jingkang Yang, Kaiyang Zhou, Yixuan Li, and Ziwei Liu. 2024. Generalized out-of-distribution detection: A survey.International Journal of Computer Vision, 132(12):5635–5662. Linyi Yang, Yaoxian Song, Xuan Ren, Chenyang Lyu, Yidong Wang, Jingming Zhuo, Lingqiao Liu, Jindong Wang, Jennifer Foster, and ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
InProceedings of the 2024 Con- ference on Empirical Methods in Natural Language Processing, pages 2576–2596
Collaborative performance prediction for large language models. InProceedings of the 2024 Con- ference on Empirical Methods in Natural Language Processing, pages 2576–2596. Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody H Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, and 1 oth- ers. 2024. Sglang: Efficient ex...
2024
-
[13]
This can be a summary of the question’s knowledge or the extraction of key knowledge keywords from it
Core Intent Knowledge Extraction: Capture the core knowledge of the question. This can be a summary of the question’s knowledge or the extraction of key knowledge keywords from it. You must ignore redundant, descriptive, colloquial modifiers and purely numerical descriptions
-
[14]
Newton’s Second Law,
Concept Decomposition: Break down composite concepts into more fundamental keywords that are more likely to appear as titles in knowledge documents, making them suitable as **search knowledge keywords**. 3.Output Format: • Knowledge keywords should use precise and concise terminology, e.g., "Newton’s Second Law," "Ideal Gas Equation of State," "Law of Dim...
1990
-
[15]
Example: Lesson Plan Question: "Chemistry is closely related to daily life
xxx ...... Example: Lesson Plan Question: "Chemistry is closely related to daily life. Which of the following statements is incorrect? A. Using fluoride toothpaste can prevent dental caries B. The main component of baking soda is Na2CO3 C. Vinegar can be used to remove calcium carbonate scale Answer: B" Output: Extraction of key knowledge words:
-
[16]
Chemistry in daily life
-
[17]
prevention of dental caries
-
[18]
dissolving calcium carbonate Lesson Plan Question: ${raw_exam} Prompts for Relevance Filtering Please carefully read, understand, and reason step by step based on the knowledge concept and knowledge learning text provided below, anddetermine whether the knowledge learning text is strictly related to the knowledge concept. Strict relevance criteria: Either...
-
[19]
xxx ...... Step 2. Knowledge Expansion: Based on the extracted key knowledge concepts, combined with the original material and your in-depth knowledge, expand the breadth and depth of the knowledge concepts and output related expanded knowledge in the following format: Related Knowledge Expansion
-
[20]
Prompts for Scenario Expansion Step 3
xxx ...... Prompts for Scenario Expansion Step 3. Practice Generation: Based on the core paragraphs of the knowledge material and combined with the key concepts, design and generate training questions in a targeted manner. The question type is limited to multiple-choice questions only. Note that the question design must follow the specifications below: Qu...
-
[21]
Obstructive sleep apnea (OSA) is a sleep disorder characterized by recurrent pauses in breathing during sleep, primarily caused by mechanical obstruction of the airway due to relaxation of the muscles at the back of the throat
-
[22]
Narcolepsy is a condition that makes people very sleepy during the day and can cause them to fall asleep suddenly. ...... Retrieved Content Depression, Anxiety, and Obstructive Sleep Apnea. Sleep problems are a common reason that people see their doctor ...... Up to 20% of people coming to their doctor with abreathing-related sleep disorderor a major depr...
-
[23]
OSA Definition and Mechanism: Sleep apnea lasting ≥ 10 seconds, caused by relaxation of the pharyngeal muscles leading to mechanical airway obstruction
-
[24]
The three main clinical signs of OSA are: nocturnal wheezing/breath-holding, snoring, and daytime sleepiness
-
[25]
OSA by gender and age distribution: More prevalent in males, but present in all populations. ...... Questions <Question_1_Start>
-
[26]
Nighttime chest pain, palpitations, daytime anxiety B
Which of the following combinations of signs most typically suggests that a patient may have obstructive sleep apnea (OSA)? A. Nighttime chest pain, palpitations, daytime anxiety B. Snoring, nighttime awakenings, daytime sleepiness C. Persistent headache, blurred vision, agitation D. Insomnia, early awakening, decreased appetite Answer: B Analysis: Key kn...
-
[27]
OSA is more common in men, but exists in all sexes and age groups,
Which of the following statements about the epidemiology of OSA is accurate? A. OSA only occurs in obese men over 40 years of age. B. OSA is extremely rare in women, and clinical screening of female patients is unnecessary. C. OSA can occur in any sex and age, but the incidence is higher in men. D. Childhood OSA is mainly caused by psychological stress an...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.