DiscoForcing: A Unified Framework for Real-Time Audio-Driven Character Control with Diffusion Forcing
Pith reviewed 2026-06-29 13:47 UTC · model grok-4.3
The pith
DiscoForcing enables stable real-time full-body motion generation from abruptly changing streaming audio using causal diffusion forcing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
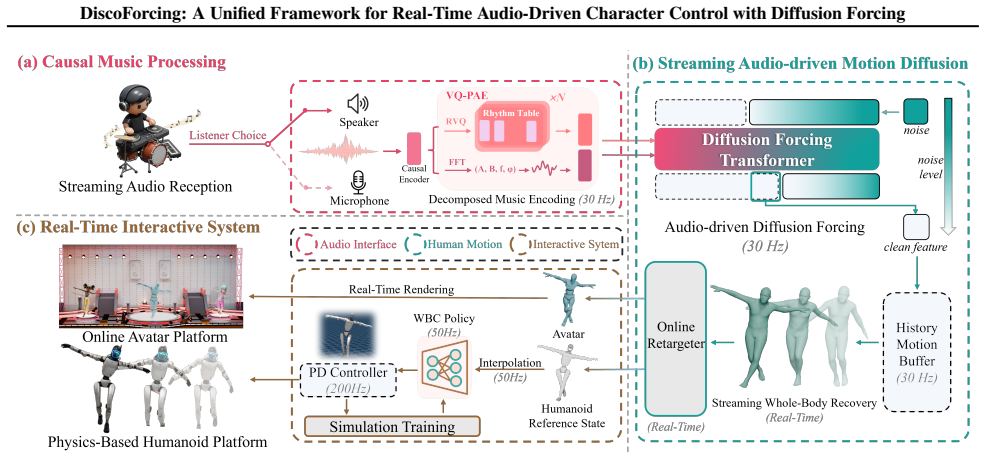
DiscoForcing combines a causal music encoder that captures rhythmic structure and phase dynamics with a diffusion-forcing sequence model trained under heterogeneous noise levels across the temporal horizon, together with a hybrid temporal schedule and history-guided streaming sampler, to generate coherent full-body motion at interactive frame rates while the audio condition changes abruptly.
What carries the argument
The diffusion-forcing sequence model trained under heterogeneous noise levels across the temporal horizon, which supports the hybrid temporal schedule and history-guided sampler in trading responsiveness for long-horizon consistency under non-stationary audio.
If this is right
- Delivers more stable long-horizon rollouts than prior baselines under matched causality and latency constraints.
- Produces sharper audio-motion alignment in streaming conditions.
- Maintains real-time throughput in an end-to-end interactive system with online avatar playback.
- Handles humanoid deployment workflows without degradation from stale conditioning history.
Where Pith is reading between the lines
- Similar heterogeneous noise training might improve other causal sequence models facing non-stationary inputs like live video or sensor data.
- Deployment on physical robots could test whether the generated motions satisfy additional physical constraints not present in avatar simulation.
- The method suggests a path for extending offline music-to-motion techniques to fully online, user-interactive settings.
Load-bearing premise
That a causal music encoder plus diffusion training under heterogeneous noise levels across time, with a hybrid schedule and history-guided sampler, will keep motions coherent when audio changes abruptly in streaming rollouts.
What would settle it
Run the system on a long audio sequence that includes sudden tempo shifts or complete drops at unpredictable times and measure whether beat alignment and motion smoothness degrade compared to steady audio segments.
Figures

read the original abstract
We study real-time audio-responsive character control as a deployment-faithful problem: strictly causal, bounded-latency streaming that must generate coherent full-body motion at interactive frame rates while the audio condition can change abruptly, including tempo shifts, drops, or user edits. Prior music-to-motion systems are largely optimized for offline generation with global context, and degrade in streaming rollouts where conditioning history becomes stale or unreliable. We introduce DiscoForcing, a streaming audio-driven diffusion framework that combines a causal music encoder that captures rhythmic structure and phase dynamics with a diffusion-forcing sequence model trained under heterogeneous noise levels across the temporal horizon. Building on this, we design a hybrid temporal schedule and a history-guided streaming sampler to explicitly trade off responsiveness against long-horizon consistency under non-stationary audio. Implemented in an end-to-end real-time interactive system with online avatar playback and humanoid deployment workflows, DiscoForcing delivers more stable long-horizon rollouts and sharper audio-motion alignment than prior baselines under matched causality and latency constraints while maintaining real-time throughput.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DiscoForcing, a streaming audio-driven diffusion framework for real-time character control. It combines a causal music encoder capturing rhythmic structure and phase, diffusion forcing trained with heterogeneous noise levels across the temporal horizon, a hybrid temporal schedule, and a history-guided streaming sampler. The central claim is that this yields more stable long-horizon rollouts and sharper audio-motion alignment than prior baselines under strictly causal, bounded-latency constraints while preserving real-time throughput, addressing degradation in streaming settings with abrupt audio changes.
Significance. If the empirical superiority holds under matched causality and latency, the work would be significant for deployment-faithful real-time systems in avatar animation and humanoid control, filling a gap between offline global-context methods and interactive streaming requirements.
major comments (2)
- [Abstract] Abstract: the central empirical claim ('delivers more stable long-horizon rollouts and sharper audio-motion alignment than prior baselines under matched causality and latency constraints') is stated without any metrics, baseline names, ablation results, or references to tables/figures; this is load-bearing because the contribution is defined by these performance advantages.
- [Introduction / Problem Formulation] The weakest assumption (coherence under abrupt audio changes such as tempo shifts or drops) is identified in the problem statement but the manuscript provides no explicit test protocol, dataset splits, or metrics for this regime; without such controls the robustness claim cannot be verified.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and the evaluation of robustness under abrupt audio changes. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central empirical claim ('delivers more stable long-horizon rollouts and sharper audio-motion alignment than prior baselines under matched causality and latency constraints') is stated without any metrics, baseline names, ablation results, or references to tables/figures; this is load-bearing because the contribution is defined by these performance advantages.
Authors: We agree that the abstract would benefit from greater specificity. In the revised manuscript we will update the abstract to reference the primary quantitative metrics, name the key baselines, and point to the relevant tables and figures that substantiate the reported gains in stability and alignment. revision: yes
-
Referee: [Introduction / Problem Formulation] The weakest assumption (coherence under abrupt audio changes such as tempo shifts or drops) is identified in the problem statement but the manuscript provides no explicit test protocol, dataset splits, or metrics for this regime; without such controls the robustness claim cannot be verified.
Authors: While the experiments section already includes streaming rollouts with non-stationary audio and reports both quantitative and qualitative results, we acknowledge that a dedicated test protocol (including explicit dataset splits and simulation procedures for tempo shifts and drops) is not separately detailed. We will add a concise subsection describing the evaluation protocol for this regime together with the metrics employed. revision: yes
Circularity Check
No significant circularity
full rationale
The provided abstract and description introduce DiscoForcing via independent architectural choices (causal music encoder, heterogeneous-noise diffusion forcing, hybrid temporal schedule, history-guided sampler) whose combination is presented as solving a streaming problem. No equations, fitted parameters renamed as predictions, self-citations, or uniqueness theorems appear in the text. The central claim of empirical superiority under matched constraints is an external performance assertion rather than a derivation that reduces to its own inputs by construction. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Retargeting matters: General motion retargeting for humanoid motion tracking,
Araujo, J. P., Ze, Y ., Xu, P., Wu, J., and Liu, C. K. Retar- geting matters: General motion retargeting for humanoid motion tracking.arXiv preprint arXiv:2510.02252,
-
[2]
Cai, Y ., Wu, Y ., Li, K., Zhou, Y ., Zheng, B., and Liu, H. Flooddiffusion: Tailored diffusion forcing for streaming motion generation.arXiv preprint arXiv:2512.03520,
-
[3]
Diffusion forcing: Next- token prediction meets full-sequence diffusion.Advances in Neural Information Processing Systems, 37:24081– 24125, 2024a
Chen, B., Mart ´ı Mons´o, D., Du, Y ., Simchowitz, M., Tedrake, R., and Sitzmann, V . Diffusion forcing: Next- token prediction meets full-sequence diffusion.Advances in Neural Information Processing Systems, 37:24081– 24125, 2024a. Chen, R., Shi, M., Huang, S., Tan, P., Komura, T., and Chen, X. Taming diffusion probabilistic models for character control....
2024
-
[4]
Fan, C., Guan, J., Zhao, X., Xu, D., Lin, Y ., Ye, T., Feng, P., and Pan, H. Align your rhythm: Generating highly aligned dance poses with gating-enhanced rhythm-aware feature representation.arXiv preprint arXiv:2503.17340,
-
[5]
Action2motion: Conditioned generation of 3d human motions
Guo, C., Zuo, X., Wang, S., Zou, S., Sun, Q., Deng, A., Gong, M., and Cheng, L. Action2motion: Conditioned generation of 3d human motions. InProceedings of the 28th ACM international conference on multimedia, pp. 2021–2029,
2021
-
[6]
and Salimans, T
Ho, J. and Salimans, T. Classifier-free diffusion guidance. InNeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications,
2021
-
[7]
Juravsky, J., Guo, Y ., Fidler, S., and Peng, X. B. Padl: Language-directed physics-based character control. In SIGGRAPH Asia 2022 Conference Papers, pp. 1–9,
2022
-
[8]
Walk- thedog: Cross-morphology motion alignment via phase manifolds
Li, P., Starke, S., Ye, Y ., and Sorkine-Hornung, O. Walk- thedog: Cross-morphology motion alignment via phase manifolds. InACM SIGGRAPH 2024 Conference Papers, pp. 1–10, 2024a. Li, R., Yang, S., Ross, D. A., and Kanazawa, A. Ai chore- ographer: Music conditioned 3d dance generation with aist++. InProceedings of the IEEE/CVF international conference on co...
2024
-
[9]
Back to Basics: Let Denoising Generative Models Denoise
Li, R., Zhang, Y ., Zhang, Y ., Zhang, H., Guo, J., Zhang, Y ., Liu, Y ., and Li, X. Lodge: A coarse to fine diffu- sion network for long dance generation guided by the characteristic dance primitives. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 1524–1534, 2024b. Li, T. and He, K. Back to basics: Let denoising ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
BeyondMimic: From Motion Tracking to Versatile Humanoid Control via Guided Diffusion
Liao, Q., Truong, T. E., Huang, X., Gao, Y ., Tevet, G., Sreenath, K., and Liu, C. K. Beyondmimic: From mo- tion tracking to versatile humanoid control via guided diffusion.arXiv preprint arXiv:2508.08241,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Rolling Forcing: Autoregressive Long Video Diffusion in Real Time
Liu, K., Hu, W., Xu, J., Shan, Y ., and Lu, S. Rolling forcing: Autoregressive long video diffusion in real time.arXiv preprint arXiv:2509.25161, 2025a. Liu, Z., Ji, K., Yang, K., Yu, J., Shi, Y ., and Wang, J. Com- manding humanoid by free-form language: A large lan- guage action model with unified motion vocabulary.arXiv preprint arXiv:2511.22963, 2025b...
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
P., McVicar, M., Battenberg, E., and Nieto, O
McFee, B., Raffel, C., Liang, D., Ellis, D. P., McVicar, M., Battenberg, E., and Nieto, O. librosa: Audio and music signal analysis in python.SciPy, 2015:18–24,
2015
-
[13]
Wu, Y ., Karunratanakul, K., Luo, Z., and Tang, S. Uni- phys: Unified planner and controller with diffusion for flexible physics-based character control.arXiv preprint arXiv:2504.12540,
-
[14]
FlowerDance: MeanFlow for Efficient and Refined 3D Dance Generation
Yang, K., Tang, X., Peng, Z., Hu, Y ., He, J., and Liu, H. MEGADance: Mixture-of-experts architecture for genre- aware 3d dance generation. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025a. Yang, K., Tang, X., Peng, Z., Zhang, X., Wang, P., He, J., and Liu, H. Flowerdance: Meanflow for effi- cient and refined 3d dance g...
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Tedi: Temporally-entangled diffusion for long-term motion syn- thesis
Zhang, Z., Liu, R., Hanocka, R., and Aberman, K. Tedi: Temporally-entangled diffusion for long-term motion syn- thesis. InACM SIGGRAPH 2024 Conference Papers, pp. 1–11, 2024b. Zhao, K., Li, G., and Tang, S. Dartcontrol: A diffusion- based autoregressive motion model for real-time text- driven motion control. InThe Thirteenth International Conference on Le...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.