Continual Model Routing in Evolving Model Hubs
Pith reviewed 2026-06-29 11:54 UTC · model grok-4.3
The pith
CARvE uses contrastive embeddings with checkpoint anchoring and structured replay to route among thousands of models as hubs expand.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
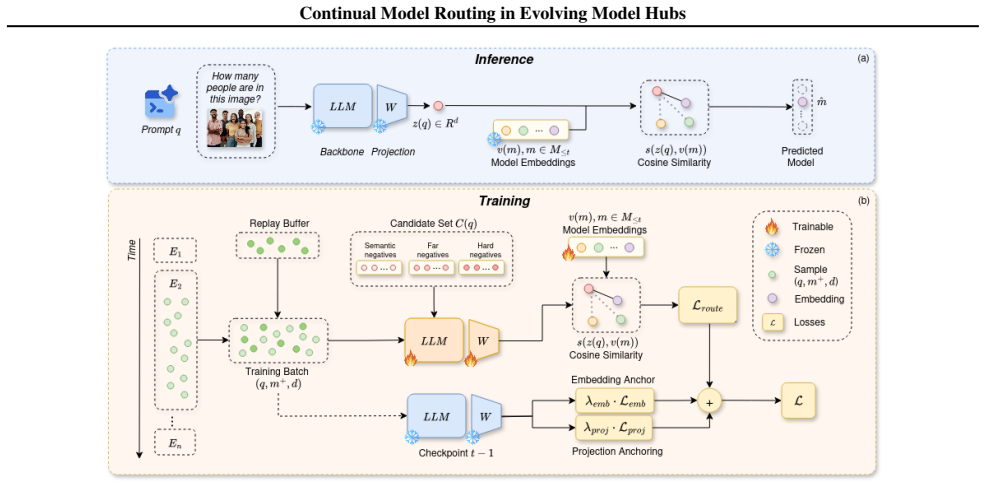
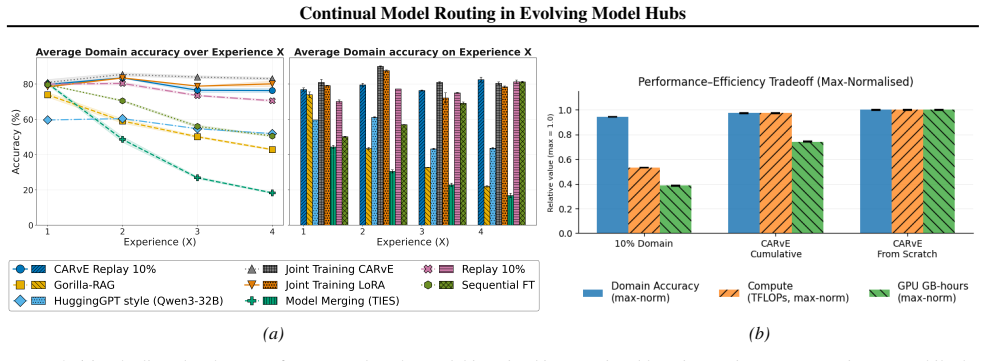
CARvE is a contrastive embedding method for continual model routing that anchors representations to model checkpoints and applies structured replay; when evaluated on CMRBench it records higher model-level, family-level, and domain-level accuracy than zero-shot retrieval, fine-tuning, and adapter-merging baselines.
What carries the argument
CARvE: contrastive embedding trained with checkpoint-based anchoring and structured replay to update routing decisions as the set of available models grows.
If this is right
- CARvE scales routing decisions across thousands of experts without requiring exhaustive evaluation for each query.
- Routing mechanisms can be updated continually without full retraining when new models or tasks appear.
- Accuracy gains hold at the individual model, model-family, and domain levels.
- The method reduces reliance on zero-shot retrieval or repeated fine-tuning in evolving hubs.
Where Pith is reading between the lines
- Deployed systems could keep a single router active for longer periods between major updates, lowering total compute spent on adaptation.
- Contrastive anchoring may prove useful in other continual-selection settings where the candidate pool changes gradually rather than all at once.
- The benchmark construction itself could be reused to test routing methods on different modalities or larger model counts.
Load-bearing premise
The patterns of model and task arrival built into CMRBench match the way real model hubs expand after deployment.
What would settle it
Running CARvE on a live model hub that adds new models and tasks according to actual usage logs and measuring whether its accuracy advantage over the three baselines disappears.
Figures


read the original abstract
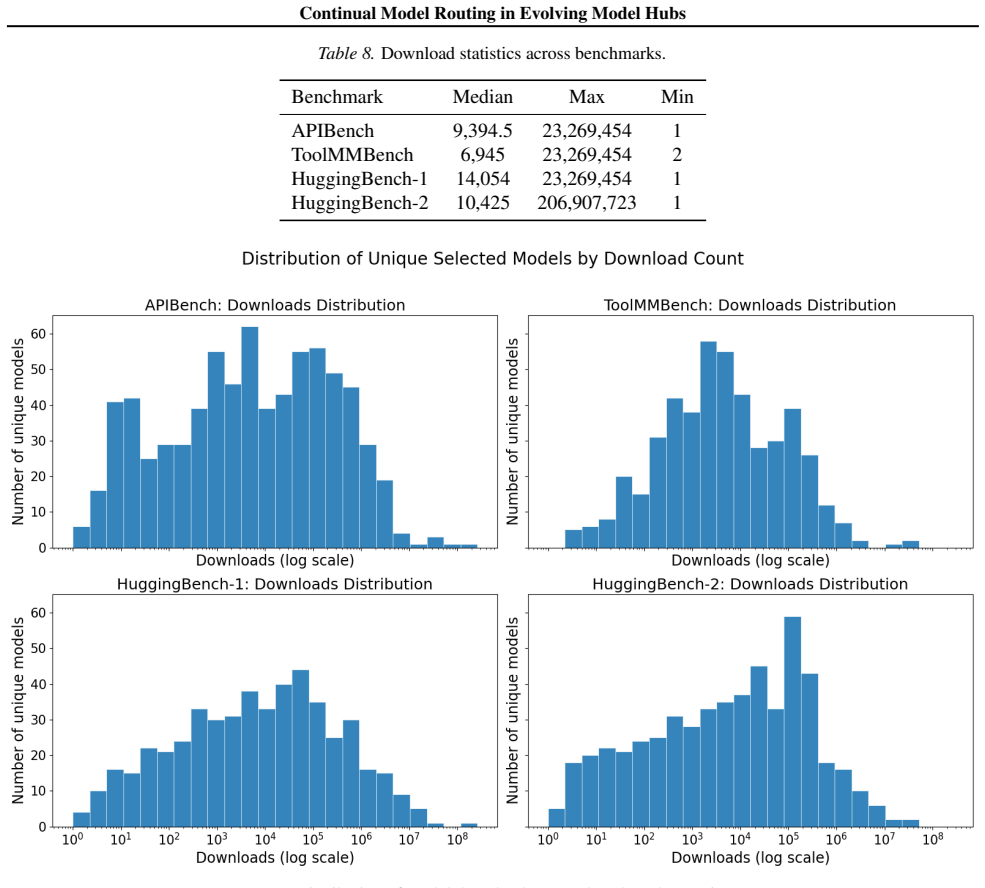
AI model hubs provide access to a rapidly growing collection of powerful pre-trained models, enabling off-the-shelf mixture-of-experts systems with different routing strategies. However, this rapid growth poses two fundamental challenges: scaling model selection across thousands of experts and continually updating routing mechanisms as new models and tasks are introduced. In this paper, we formalise this setting as Continual Model Routing (CMR) and propose CMRBench, a new large-scale benchmark simulating realistic hub expansion and including over 2,000 candidate models. Finally, we introduce CARvE, a contrastive embedding approach for efficient continual model routing via checkpoint-based anchoring and structured replay. Extensive empirical results and ablations show that CARvE significantly outperforms zero-shot retrieval, fine-tuning, and adapter-merging baselines in model, family, and domain-level accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes the Continual Model Routing (CMR) setting for evolving AI model hubs, introduces CMRBench as a large-scale benchmark simulating realistic hub expansion with over 2,000 candidate models, and proposes CARvE, a contrastive embedding approach for continual routing that uses checkpoint-based anchoring and structured replay. It claims that CARvE significantly outperforms zero-shot retrieval, fine-tuning, and adapter-merging baselines across model-, family-, and domain-level accuracy metrics, supported by extensive empirical results and ablations.
Significance. If the results hold under realistic conditions, the work addresses a practically important problem in scaling mixture-of-experts systems to thousands of models under continual arrival of new models and tasks; the introduction of CMRBench could serve as a reusable testbed, and the contrastive embedding method offers an efficient alternative to repeated fine-tuning or merging.
major comments (2)
- [CMRBench section] Benchmark construction (CMRBench section): the load-bearing assumption that the simulated arrival process, ordering, task distribution shifts, and model family clustering accurately reflect deployed hub dynamics is not independently validated; without evidence that deviations from real dynamics do not inflate the reported gains, the outperformance claims on model/family/domain accuracy cannot be taken as establishing utility for the stated CMR setting.
- [Results and ablations] Experimental details (throughout results and ablations): the manuscript provides no information on data splits, statistical significance testing, exact baseline implementations, or variance across runs, which is required to determine whether the accuracy improvements are robust or could be artifacts of the benchmark construction.
minor comments (2)
- [CARvE method] Clarify notation for the contrastive loss and replay mechanism to ensure the method description is self-contained without reference to external contrastive embedding literature.
- [Efficiency analysis] Add explicit discussion of computational overhead for checkpoint anchoring and replay relative to the zero-shot and merging baselines.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on benchmark validation and experimental reporting. We address each major comment below with proposed revisions to strengthen the paper while remaining faithful to the work performed.
read point-by-point responses
-
Referee: [CMRBench section] Benchmark construction (CMRBench section): the load-bearing assumption that the simulated arrival process, ordering, task distribution shifts, and model family clustering accurately reflect deployed hub dynamics is not independently validated; without evidence that deviations from real dynamics do not inflate the reported gains, the outperformance claims on model/family/domain accuracy cannot be taken as establishing utility for the stated CMR setting.
Authors: We agree that the simulation is a modeling choice rather than a direct replication of proprietary deployment traces. CMRBench is built from public Hugging Face metadata (release dates, model cards, task tags) and standard dataset shifts; the arrival ordering follows observed exponential growth in model uploads. We cannot provide independent validation against closed-source hub logs. In revision we will (a) expand the benchmark construction subsection with explicit justification and citations to public trends, (b) add a limitations paragraph acknowledging possible mismatches, and (c) include sensitivity experiments under randomized and reversed arrival orders to test robustness of the reported gains. revision: partial
-
Referee: [Results and ablations] Experimental details (throughout results and ablations): the manuscript provides no information on data splits, statistical significance testing, exact baseline implementations, or variance across runs, which is required to determine whether the accuracy improvements are robust or could be artifacts of the benchmark construction.
Authors: We accept this criticism. The original submission omitted these details for brevity. The revised version will add: (1) explicit train/validation/test splits on the query-model pairs (70/15/15), (2) precise baseline reproduction details including learning rates, epochs, and merging hyperparameters, (3) results reported as mean ± standard deviation over five random seeds, and (4) statistical significance via paired Wilcoxon tests (p < 0.05). These changes will appear in the experimental setup and results sections. revision: yes
Circularity Check
No significant circularity; method and benchmark rely on established techniques without self-referential reduction
full rationale
The paper introduces the CMR setting, CMRBench for simulating hub expansion, and CARvE as a contrastive embedding method with anchoring and replay. These draw from standard contrastive learning and continual learning practices without any equations or derivations that reduce outputs to inputs by construction. No fitted parameters are renamed as predictions, no self-citation chains justify uniqueness theorems, and the benchmark construction does not create self-definitional loops in the method itself. The central empirical claims rest on external baselines and the new benchmark, which is a standard (non-circular) practice for novel settings.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
API - BLEND : A Comprehensive Corpora for Training and Benchmarking API LLMs
Basu, K., Abdelaziz, I., Chaudhury, S., Dan, S., Crouse, M., Munawar, A., Austel, V., Kumaravel, S., Muthusamy, V., Kapanipathi, P., and Lastras, L. API - BLEND : A Comprehensive Corpora for Training and Benchmarking API LLMs . In Ku, L.-W., Martins, A., and Srikumar, V. (eds.), Proceedings of the 62nd Annual Meeting of the Association for Computational L...
-
[3]
N., Li, L., Li, M., Madeddu, M., Piccoli, E., and Lomonaco, V
Bell, J., Quarantiello, L., Coleman, E. N., Li, L., Li, M., Madeddu, M., Piccoli, E., and Lomonaco, V. The Future of Continual Learning in the Era of Foundation Models : Three Key Directions . In Dell'Anna, D., Gezici, G., and Rossetti, G. (eds.), Proceedings of the Workshops at the Fourth International Conference on Hybrid Human - Artificial Intelligence...
2025
-
[4]
Chen, J., Xiao, S., Zhang, P., Luo, K., Lian, D., and Liu, Z. M3- Embedding : Multi - Linguality , Multi - Functionality , Multi - Granularity Text Embeddings Through Self - Knowledge Distillation . In Ku, L.-W., Martins, A., and Srikumar, V. (eds.), Findings of the Association for Computational Linguistics : ACL 2024 , pp.\ 2318--2335, Bangkok, Thailand,...
-
[5]
FrugalGPT : How to Use Large Language Models While Reducing Cost and Improving Performance
Chen, L., Zaharia, M., and Zou, J. FrugalGPT : How to Use Large Language Models While Reducing Cost and Improving Performance . Trans. Mach. Learn. Res., 2024, 2024 b . URL https://openreview.net/forum?id=cSimKw5p6R
2024
-
[6]
Chronopoulou, A., Peters, M. E., Fraser, A., and Dodge, J. AdapterSoup : Weight Averaging to Improve Generalization of Pretrained Language Models . In Vlachos, A. and Augenstein, I. (eds.), Findings of the Association for Computational Linguistics : EACL 2023, Dubrovnik , Croatia , May 2-6, 2023 , Findings of ACL , pp.\ 2009--2018. Association for Computa...
-
[7]
Switch Transformers : Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
Fedus, W., Zoph, B., and Shazeer, N. Switch Transformers : Scaling to Trillion Parameter Models with Simple and Efficient Sparsity . Journal of Machine Learning Research, 23 0 (120): 0 1--39, 2022. ISSN 1533-7928. URL http://jmlr.org/papers/v23/21-0998.html
2022
-
[8]
SPLADE : Sparse Lexical and Expansion Model for First Stage Ranking
Formal, T., Piwowarski, B., and Clinchant, S. SPLADE : Sparse Lexical and Expansion Model for First Stage Ranking . In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval , SIGIR '21, pp.\ 2288--2292, New York, NY, USA, July 2021. Association for Computing Machinery. ISBN 978-1-4503-8037-9. doi:1...
-
[9]
F., Chow, T., Khare, I
Guha, N., Chen, M. F., Chow, T., Khare, I. S., and Re, C. Smoothie: Label Free Language Model Routing . November 2024. URL https://openreview.net/forum?id=pPSWHsgqRp
2024
-
[10]
J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., and Chen, W
Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., and Chen, W. LoRA : Low - Rank Adaptation of Large Language Models . In The Tenth International Conference on Learning Representations , ICLR 2022, Virtual Event , April 25-29, 2022 . OpenReview.net, 2022. URL https://openreview.net/forum?id=nZeVKeeFYf9
2022
-
[11]
J., Bieker, J., Li, X., Jiang, N., Keigwin, B., Ranganath, G., Keutzer, K., and Upadhyay, S
Hu, Q. J., Bieker, J., Li, X., Jiang, N., Keigwin, B., Ranganath, G., Keutzer, K., and Upadhyay, S. K. RouterBench : A Benchmark for Multi - LLM Routing System . July 2024. URL https://openreview.net/forum?id=IVXmV8Uxwh
2024
-
[12]
Y., Pang, T., Du, C., and Lin, M
Huang, C., Liu, Q., Lin, B. Y., Pang, T., Du, C., and Lin, M. LoraHub : Efficient Cross - Task Generalization via Dynamic LoRA Composition . August 2024. URL https://openreview.net/forum?id=TrloAXEJ2B
2024
-
[13]
Jacobs, R. A., Jordan, M. I., Nowlan, S. J., and Hinton, G. E. Adaptive Mixtures of Local Experts . Neural Computation, 3 0 (1): 0 79--87, March 1991. ISSN 0899-7667. doi:10.1162/neco.1991.3.1.79. URL https://ieeexplore.ieee.org/abstract/document/6797059
-
[14]
Jiang, D., Ren, X., and Lin, B. Y. LLM - Blender : Ensembling Large Language Models with Pairwise Ranking and Generative Fusion . In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics ( Volume 1: Long Papers ) , pp.\ 14165--14178, Toronto, Canada, 2023. Association for Computational Linguistics. doi:10.18653/v1/2023.ac...
-
[15]
Kirkpatrick, J., Pascanu, R., Rabinowitz, N., Veness, J., Desjardins, G., Rusu, A. A., Milan, K., Quan, J., Ramalho, T., Grabska-Barwinska, A., Hassabis, D., Clopath, C., Kumaran, D., and Hadsell, R. Overcoming catastrophic forgetting in neural networks. Proceedings of the National Academy of Sciences, 114 0 (13): 0 3521--3526, March 2017. doi:10.1073/pna...
-
[16]
Retrieval- Augmented Generation for Knowledge - Intensive NLP Tasks
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W.-t., Rocktäschel, T., Riedel, S., and Kiela, D. Retrieval- Augmented Generation for Knowledge - Intensive NLP Tasks . In Advances in Neural Information Processing Systems , volume 33, pp.\ 9459--9474. Curran Associates, Inc., 2020. URL https://proceedin...
2020
-
[17]
Api-bank: A comprehensive benchmark for tool-augmented llms
Li, M., Zhao, Y., Yu, B., Song, F., Li, H., Yu, H., Li, Z., Huang, F., and Li, Y. API - Bank : A Comprehensive Benchmark for Tool - Augmented LLMs . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pp.\ 3102--3116, Singapore, 2023. Association for Computational Linguistics. doi:10.18653/v1/2023.emnlp-main.187. UR...
-
[18]
Li, Z. and Hoiem, D. Learning without Forgetting . IEEE Trans. Pattern Anal. Mach. Intell., 40 0 (12): 0 2935--2947, December 2018. ISSN 0162-8828. doi:10.1109/TPAMI.2017.2773081. URL https://doi.org/10.1109/TPAMI.2017.2773081
-
[19]
Olympus: A Universal Task Router for Computer Vision Tasks
Lin, Y., Li, Y., Chen, D., Xu, W., Clark, R., and Torr, P. Olympus: A Universal Task Router for Computer Vision Tasks . pp.\ 14235--14246, 2025. URL https://openaccess.thecvf.com/content/CVPR2025/html/Lin_Olympus_A_Universal_Task_Router_for_Computer_Vision_Tasks_CVPR_2025_paper.html
2025
-
[20]
COLT : Enhancing Video Large Language Models with Continual Tool Usage
Liu, Y., Cao, M., Shi, X., and Liang, X. COLT : Enhancing Video Large Language Models with Continual Tool Usage . Transactions on Machine Learning Research, November 2025. ISSN 2835-8856. URL https://openreview.net/forum?id=NT9tHHTlXn
2025
-
[21]
L., De Lange, M., Masana, M., Pomponi, J., van de Ven, G
Lomonaco, V., Pellegrini, L., Cossu, A., Carta, A., Graffieti, G., Hayes, T. L., De Lange, M., Masana, M., Pomponi, J., van de Ven, G. M., Mundt, M., She, Q., Cooper, K., Forest, J., Belouadah, E., Calderara, S., Parisi, G. I., Cuzzolin, F., Tolias, A. S., Scardapane, S., Antiga, L., Ahmad, S., Popescu, A., Kanan, C., van de Weijer, J., Tuytelaars, T., Ba...
2021
-
[22]
R., and Yazdani, M
Mohammadshahi, A., Shaikh, A. R., and Yazdani, M. Routoo: Learning to Route to Large Language Models Effectively . October 2024. URL https://openreview.net/forum?id=RQ9fQLEajC
2024
-
[23]
E., Kadous, M
Ong, I., Almahairi, A., Wu, V., Chiang, W.-L., Wu, T., Gonzalez, J. E., Kadous, M. W., and Stoica, I. RouteLLM : Learning to Route LLMs from Preference Data . October 2024. URL https://openreview.net/forum?id=8sSqNntaMr
2024
-
[24]
Parisi, G. I., Kemker, R., Part, J. L., Kanan, C., and Wermter, S. Continual lifelong learning with neural networks: A review. Neural Networks, 113: 0 54--71, May 2019. ISSN 0893-6080. doi:10.1016/j.neunet.2019.01.012. URL https://www.sciencedirect.com/science/article/pii/S0893608019300231
-
[25]
G., Zhang, T., Wang, X., and Gonzalez, J
Patil, S. G., Zhang, T., Wang, X., and Gonzalez, J. E. Gorilla: Large Language Model Connected with Massive APIs . Advances in Neural Information Processing Systems, 37: 0 126544--126565, December 2024. doi:10.52202/079017-4020. URL https://proceedings.neurips.cc/paper_files/paper/2024/hash/e4c61f578ff07830f5c37378dd3ecb0d-Abstract-Conference.html
-
[26]
Reimers, N. and Gurevych, I. Sentence- BERT : Sentence Embeddings using Siamese BERT - Networks . In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing ( EMNLP - IJCNLP ) , pp.\ 3980--3990, Hong Kong, China, 2019. Association for Computational Lin...
-
[27]
Robertson, S. and Zaragoza, H. The Probabilistic Relevance Framework : BM25 and Beyond . Foundations and Trends® in Information Retrieval, 3 0 (4): 0 333--389, 2009. ISSN 1554-0669, 1554-0677. doi:10.1561/1500000019. URL http://www.nowpublishers.com/article/Details/INR-019
-
[28]
Don't forget, there is more than forgetting: new metrics for Continual Learning
Rodríguez, N. D., Lomonaco, V., Filliat, D., and Maltoni, D. Don't forget, there is more than forgetting: new metrics for Continual Learning . CoRR, abs/1810.13166, 2018. URL http://arxiv.org/abs/1810.13166. arXiv: 1810.13166
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[29]
V., Hinton, G
Shazeer, N., Mirhoseini, A., Maziarz, K., Davis, A., Le, Q. V., Hinton, G. E., and Dean, J. Outrageously Large Neural Networks : The Sparsely - Gated Mixture -of- Experts Layer . In 5th International Conference on Learning Representations , ICLR 2017, Toulon , France , April 24-26, 2017, Conference Track Proceedings . OpenReview.net, 2017. URL https://ope...
2017
-
[30]
HuggingGPT : Solving AI Tasks with ChatGPT and its Friends in Hugging Face
Shen, Y., Song, K., Tan, X., Li, D., Lu, W., and Zhuang, Y. HuggingGPT : Solving AI Tasks with ChatGPT and its Friends in Hugging Face . In Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., and Levine, S. (eds.), Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, Ne...
2023
-
[31]
TaskBench : Benchmarking Large Language Models for Task Automation
Shen, Y., Song, K., Tan, X., Zhang, W., Ren, K., Yuan, S., Lu, W., Li, D., and Zhuang, Y. TaskBench : Benchmarking Large Language Models for Task Automation . Advances in Neural Information Processing Systems, 37: 0 4540--4574, December 2024. doi:10.52202/079017-0148. URL https://proceedings.neurips.cc/paper_files/paper/2024/hash/085185ea97db31ae6dcac7497...
-
[32]
Shu, Q., Chen, S., Lu, W., You, Z., and Liu, C. UniRoute : Unified Routing Mixture -of- Experts for Modality - Adaptive Remote Sensing Change Detection , January 2026. URL http://arxiv.org/abs/2601.14797. arXiv:2601.14797 [cs]
-
[33]
Su, H., Diao, S., Lu, X., Liu, M., Xu, J., Dong, X., Fu, Y., Belcak, P., Ye, H., Yin, H., Dong, Y., Bakhturina, E., Yu, T., Choi, Y., Kautz, J., and Molchanov, P. ToolOrchestra : Elevating Intelligence via Efficient Model and Tool Orchestration , November 2025. URL https://arxiv.org/abs/2511.21689v1
-
[34]
F., Ilhan, F., Huang, T., Hu, S., and Liu, L
Tekin, S. F., Ilhan, F., Huang, T., Hu, S., and Liu, L. LLM - TOPLA : Efficient LLM Ensemble by Maximising Diversity . In Al-Onaizan, Y., Bansal, M., and Chen, Y.-N. (eds.), Findings of the Association for Computational Linguistics : EMNLP 2024 , pp.\ 11951--11966, Miami, Florida, USA, November 2024. Association for Computational Linguistics. doi:10.18653...
-
[35]
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., Bikel, D., Blecher, L., Ferrer, C. C., Chen, M., Cucurull, G., Esiobu, D., Fernandes, J., Fu, J., Fu, W., Fuller, B., Gao, C., Goswami, V., Goyal, N., Hartshorn, A., Hosseini, S., Hou, R., Inan, H., Kardas, M., Kerkez, V., Khabsa...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
M., Tuytelaars, T., and Tolias, A
van de Ven, G. M., Tuytelaars, T., and Tolias, A. S. Three types of incremental learning. Nature Machine Intelligence, 4 0 (12): 0 1185--1197, December 2022. ISSN 2522-5839. doi:10.1038/s42256-022-00568-3. URL https://www.nature.com/articles/s42256-022-00568-3
-
[37]
MLLM - Tool : A Multimodal Large Language Model for Tool Agent Learning
Wang, C., Luo, W., Dong, S., Xuan, X., Li, Z., Ma, L., and Gao, S. MLLM - Tool : A Multimodal Large Language Model for Tool Agent Learning . In 2025 IEEE / CVF Winter Conference on Applications of Computer Vision ( WACV ) , pp.\ 6678--6687, February 2025. doi:10.1109/WACV61041.2025.00650. URL https://ieeexplore.ieee.org/abstract/document/10943671
-
[38]
Smith, Daniel Khashabi, and Hannaneh Hajishirzi
Wang, Y., Kordi, Y., Mishra, S., Liu, A., Smith, N. A., Khashabi, D., and Hajishirzi, H. Self- Instruct : Aligning Language Models with Self - Generated Instructions . In Rogers, A., Boyd-Graber, J., and Okazaki, N. (eds.), Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics ( Volume 1: Long Papers ) , pp.\ 13484--13508...
-
[39]
On the Tool Manipulation Capability of Open -source Large Language Models , May 2023
Xu, Q., Hong, F., Li, B., Hu, C., Chen, Z., and Zhang, J. On the Tool Manipulation Capability of Open -source Large Language Models , May 2023. URL http://arxiv.org/abs/2305.16504
-
[40]
A., and Bansal, M
Yadav, P., Tam, D., Choshen, L., Raffel, C. A., and Bansal, M. TIES - Merging : Resolving Interference When Merging Models . In Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., and Levine, S. (eds.), Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans , ...
2023
-
[41]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., Zheng, C., Liu, D., Zhou, F., Huang, F., Hu, F., Ge, H., Wei, H., Lin, H., Tang, J., Yang, J., Tu, J., Zhang, J., Yang, J., Yang, J., Zhou, J., Zhou, J., Lin, J., Dang, K., Bao, K., Yang, K., Yu, L., Deng, L., Li, M., Xue, M., Li, M., Zhang, P., Wang, P., Zhu, Q...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Language models are super mario: absorbing abilities from homologous models as a free lunch
Yu, L., Yu, B., Yu, H., Huang, F., and Li, Y. Language models are super mario: absorbing abilities from homologous models as a free lunch. In Proceedings of the 41st International Conference on Machine Learning , volume 235 of ICML '24 , pp.\ 57755--57775, Vienna, Austria, 2024. JMLR.org
2024
-
[43]
Model Spider : Learning to Rank Pre - Trained Models Efficiently
Zhang, Y.-K., Huang, T.-J., Ding, Y.-X., Zhan, D.-C., and Ye, H.-J. Model Spider : Learning to Rank Pre - Trained Models Efficiently . Advances in Neural Information Processing Systems, 36: 0 13692--13719, December 2023. URL https://proceedings.neurips.cc/paper_files/paper/2023/hash/2c71b14637802ed08eaa3cf50342b2b9-Abstract-Conference.html
2023
-
[44]
LoraRetriever : Input - Aware LoRA Retrieval and Composition for Mixed Tasks in the Wild
Zhao, Z., Gan, L., Wang, G., Zhou, W., Yang, H., Kuang, K., and Wu, F. LoraRetriever : Input - Aware LoRA Retrieval and Composition for Mixed Tasks in the Wild . In Ku, L.-W., Martins, A., and Srikumar, V. (eds.), Findings of the Association for Computational Linguistics , ACL 2024, Bangkok , Thailand and virtual meeting, August 11-16, 2024 , Findings of ...
- [45]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.