Self-Prophetic Decoding to Unlock Visual Search in LVLMs
Pith reviewed 2026-06-29 12:50 UTC · model grok-4.3
The pith
Self-prophetic decoding lets post-trained vision-language models recover coherent visual search by accepting tokens from their pre-trained counterparts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
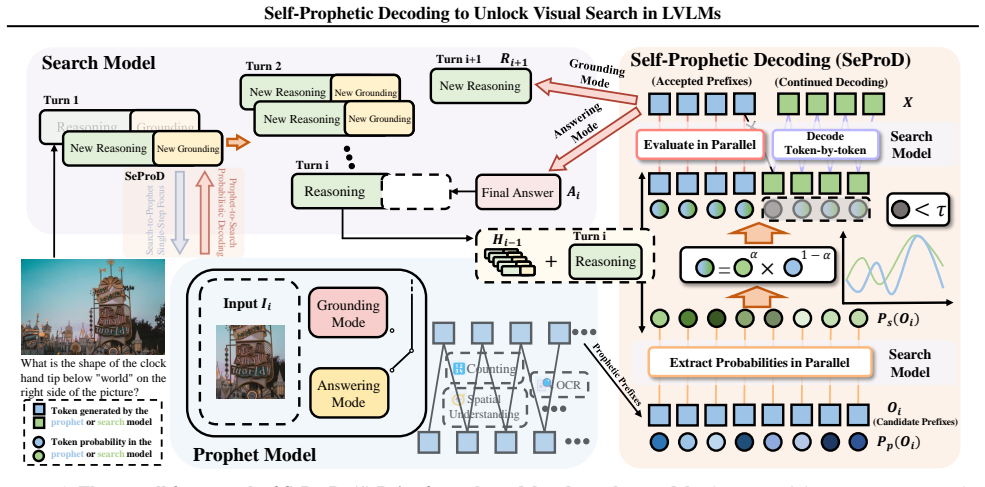
SeProD is a self-prophetic decoding framework that uses probability-based prophetic sampling so the pre-training LVLM acts as a prophet while the post-training LVLM selectively accepts prophetic tokens under its own output distribution; this self-regulation between pre- and post-training stages mitigates capability deterioration and long-context interference, enabling coherent multi-step visual search in a plug-and-play manner.
What carries the argument
The parallel prophetic acceptance mechanism, in which the post-training model draws tokens from the pre-training model's distribution and accepts them only if they stay within its own probability mass.
If this is right
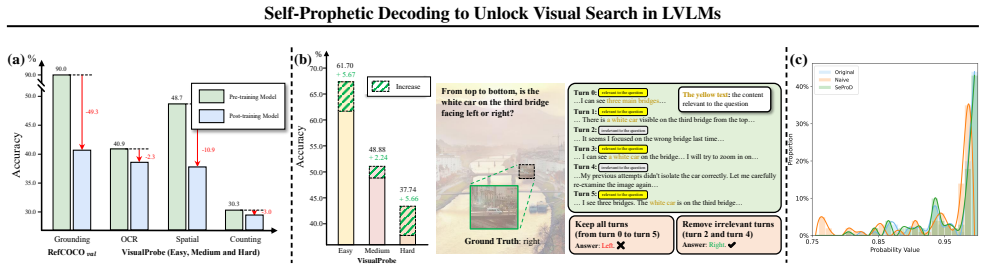
- SeProD raises performance of multiple visual-search LVLMs on all twelve splits of four visual-search benchmarks.
- The same gains appear on general VQA benchmarks.
- The method adds no computational overhead because prophetic acceptance runs in parallel with ordinary decoding.
- SeProD requires no additional training and works as a plug-and-play replacement for standard decoding.
Where Pith is reading between the lines
- The same self-regulation pattern could be tested on other long-horizon multimodal tasks such as diagram-based reasoning or video question answering.
- If the pre-training model is replaced by a smaller distilled version, the overhead of maintaining two models at inference time could be measured directly.
- The approach suggests that post-training alignment need not erase earlier capabilities if runtime acceptance can restore them selectively.
Load-bearing premise
The pre-training model's single-step visual capabilities remain intact enough that the post-training model can selectively borrow them at inference time to offset post-training damage.
What would settle it
Running SeProD on the same visual-search benchmarks and observing no accuracy lift or added latency on any of the twelve splits would falsify the central claim.
Figures

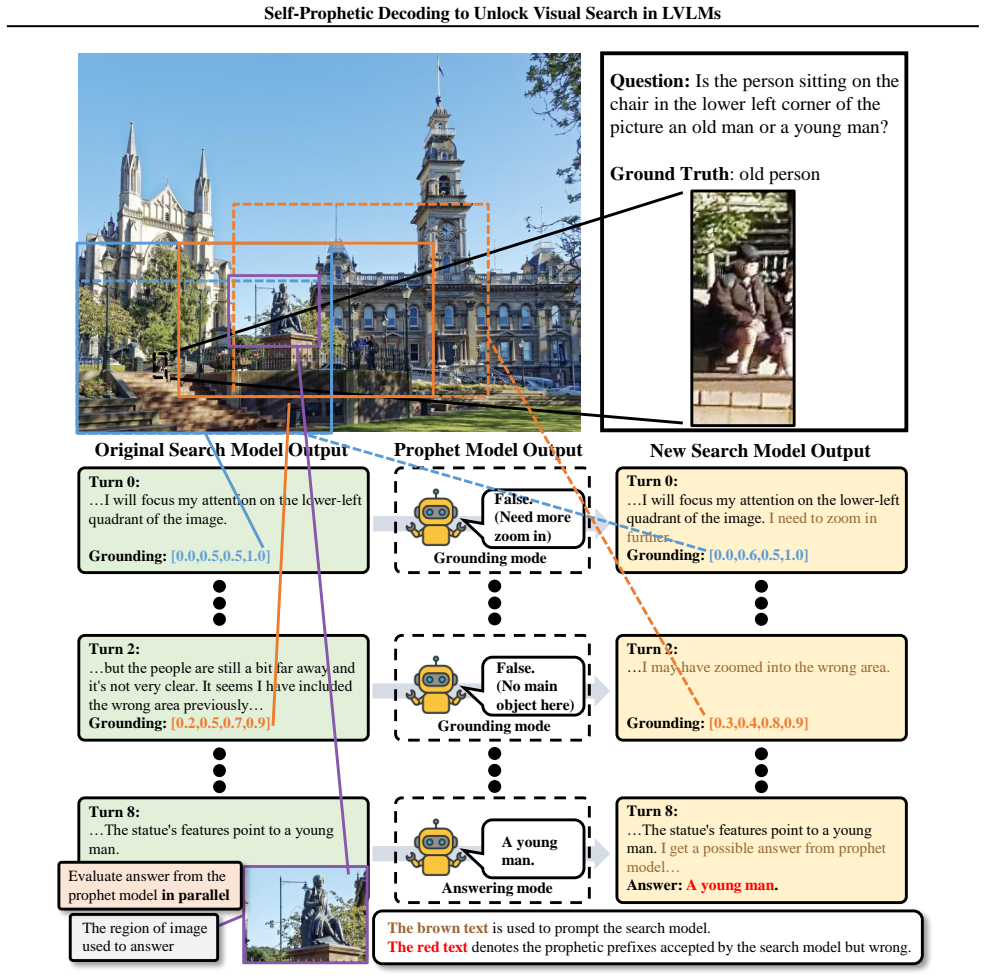
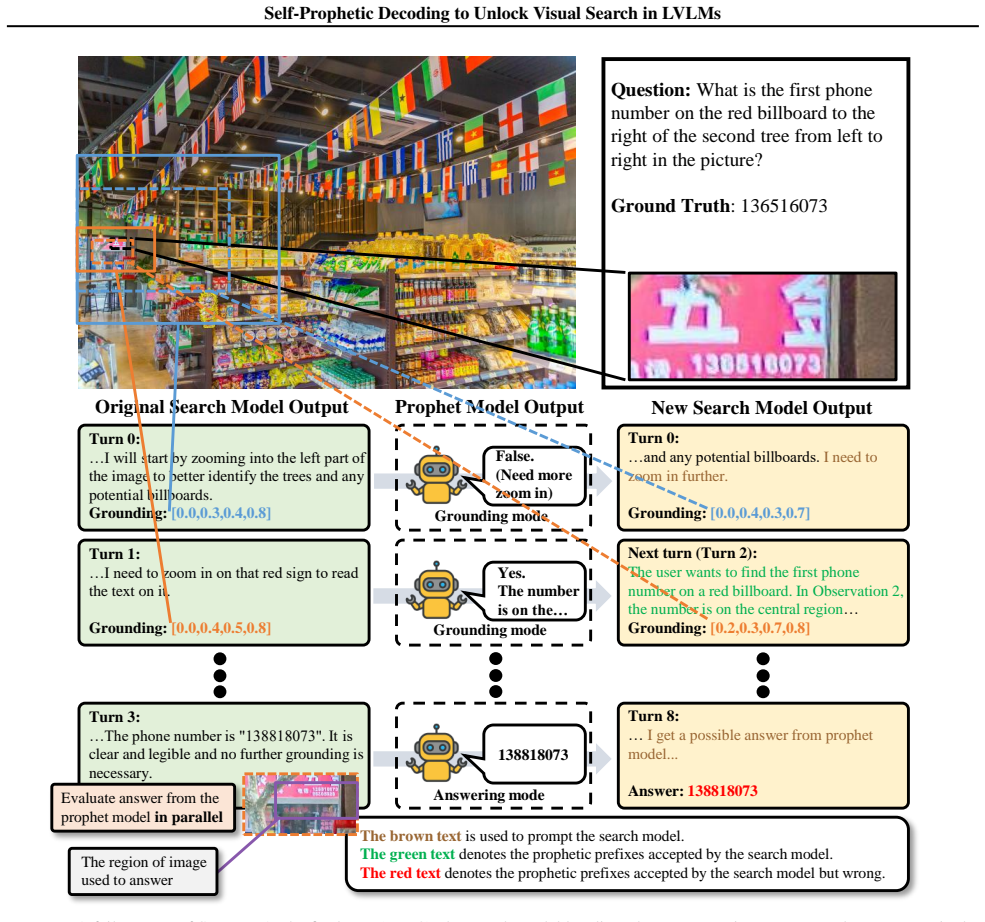
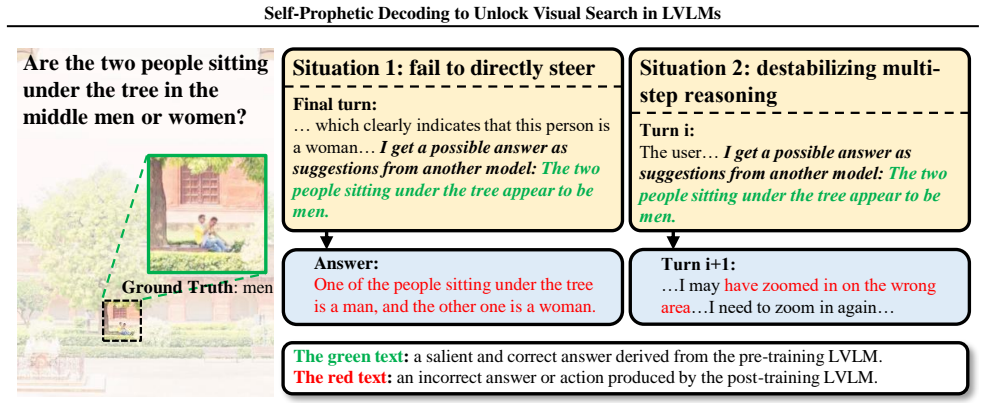
read the original abstract
Large Vision-Language Models (LVLMs) are rapidly evolving toward true multimodal reasoning, with visual search representing a concrete instantiation of the thinking-with-images paradigm. However, LVLM visual search faces two key challenges: incompatibility among intrinsic capabilities after post-training, and interference in long multi-step reasoning contexts. To address these, we identify two novel insights. First, self-regulation between pre- and post-training LVLMs leverages the intrinsic single-step capabilities of the pre-training model to mitigate capability deterioration and long-context interference. Second, probability-based prophetic sampling, replacing naive prompting, provides a probabilistic interface where the pre-training model acts as a prophet and the post-training model selectively accepts prophetic tokens under its output distribution, preserving coherent multi-step reasoning. Building on these insights, we introduce SeProD, a self-prophetic decoding framework that leverages intrinsic single-step capabilities to enable coherent multi-step reasoning in a training-free, plug-and-play manner. Experiments show that SeProD consistently improves multiple visual-search LVLMs across all 12 splits of 4 visual search benchmarks, as well as across general VQA benchmarks, without added computational overhead, thanks to its parallel prophetic acceptance mechanism.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SeProD, a training-free, plug-and-play decoding framework for large vision-language models (LVLMs) that addresses incompatibility among intrinsic capabilities after post-training and interference in long multi-step reasoning contexts. It proposes two insights: self-regulation between pre- and post-training LVLMs to leverage single-step capabilities, and probability-based prophetic sampling where the pre-training model acts as a 'prophet' and the post-training model selectively accepts tokens. The central empirical claim is that SeProD yields consistent improvements on all 12 splits of 4 visual search benchmarks plus general VQA tasks, with zero added computational overhead via its parallel prophetic acceptance mechanism.
Significance. If the reported gains hold under rigorous evaluation, the result would be significant for the field of multimodal reasoning in LVLMs. The training-free nature and lack of overhead represent a practical strength that could enable immediate adoption for visual search tasks without retraining. The approach of bridging pre- and post-training checkpoints via self-regulation is a coherent way to recover single-step capabilities while preserving multi-step coherence, and the probabilistic interface for token acceptance is a novel interface that avoids naive prompting.
minor comments (3)
- [Abstract] Abstract: the statement that SeProD 'consistently improves' across benchmarks would be strengthened by including at least one concrete performance delta or reference to a main-text table (e.g., average accuracy lift on the visual-search splits).
- [§3 (method)] The invented term 'prophetic tokens' and the 'parallel prophetic acceptance mechanism' are introduced without an early, self-contained definition or pseudocode; a short formal definition or algorithm box in §3 would improve accessibility.
- The manuscript should explicitly state the exact pre- and post-training model pairs used in the self-regulation experiments and confirm that the same tokenizer and vocabulary are shared, to allow direct reproduction.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of SeProD, the recognition of its practical strengths (training-free, zero overhead), and the recommendation for minor revision. We are encouraged that the self-regulation insight and probabilistic prophetic sampling are viewed as coherent and novel. Since no specific major comments were raised, we interpret the minor_revision recommendation as an invitation to polish presentation or add minor clarifications if any arise during production.
Circularity Check
No significant circularity
full rationale
The paper presents SeProD as a training-free procedural framework that combines pre- and post-training LVLMs via self-regulation and prophetic sampling. All load-bearing claims are empirical performance gains on fixed benchmarks, which are directly testable and do not reduce to any fitted parameter, self-defined quantity, or self-citation chain. No equations or derivations appear that equate a prediction to its own inputs by construction; the method description remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pre-training LVLMs retain intrinsic single-step capabilities that can counteract post-training deterioration.
invented entities (1)
-
prophetic tokens
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Bai, S., Cai, Y ., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y ., Liu, D., Liu, S., Lu, D., Luo, R., Lv, C., Men, R., Meng, L., Ren, X., Ren, X., Song, S., Sun, Y ., Tan...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1609/aaai.v38i2
-
[2]
Fan, Y ., He, X., Yang, D., Zheng, K., Kuo, C.-C., Zheng, Y ., Narayanaraju, S
URL https:// arxiv.org/abs/2505.15510. Fan, Y ., He, X., Yang, D., Zheng, K., Kuo, C.-C., Zheng, Y ., Narayanaraju, S. J., Guan, X., and Wang, X. E. Grit: Teaching mllms to think with images,
-
[3]
GRIT: Teaching MLLMs to Think with Images
URL https://arxiv.org/abs/2505.15879. Gao, Z., Chen, Z., Cui, E., Ren, Y ., Wang, W., Zhu, J., Tian, H., Ye, S., He, J., Zhu, X., Lu, L., Lu, T., Qiao, Y ., Dai, J., and Wang, W. Mini-internvl: A flexible- transfer pocket multimodal model with 5 URL https: //arxiv.org/abs/2410.16261. Gu, S., Lugmayr, A., Danelljan, M., Fritsche, M., Lamour, J., and Timoft...
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Hu, Y ., Shi, W., Fu, X., Roth, D., Ostendorf, M., Zettle- moyer, L., Smith, N
doi: 10.1109/ICCVW.2019.00435. Hu, Y ., Shi, W., Fu, X., Roth, D., Ostendorf, M., Zettle- moyer, L., Smith, N. A., and Krishna, R. Visual sketch- pad: Sketching as a visual chain of thought for multi- modal language models,
-
[5]
URL https://arxiv. org/abs/2406.09403. Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A. C., 9 Self-Prophetic Decoding to Unlock Visual Search in LVLMs Lo, W.-Y ., Doll ´ar, P., and Girshick, R. Segment anything,
-
[6]
URL https://arxiv.org/abs/ 2304.02643. Lai, X., Li, J., Li, W., Liu, T., Li, T., and Zhao, H. Mini- o3: Scaling up reasoning patterns and interaction turns for visual search,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Mini-o3: Scaling Up Reasoning Patterns and Interaction Turns for Visual Search
URL https://arxiv.org/ abs/2509.07969. Leviathan, Y ., Kalman, M., and Matias, Y . Fast inference from transformers via speculative decoding,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Fast Inference from Transformers via Speculative Decoding
URL https://arxiv.org/abs/2211.17192. Li, B., Zhang, Y ., Guo, D., Zhang, R., Li, F., Zhang, H., Zhang, K., Zhang, P., Li, Y ., Liu, Z., and Li, C. Llava- onevision: Easy visual task transfer,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
LLaVA-OneVision: Easy Visual Task Transfer
URL https: //arxiv.org/abs/2408.03326. Li, G., Xu, J., Zhao, Y ., and Peng, Y . Dyfo: A training- free dynamic focus visual search for enhancing lmms in fine-grained visual understanding,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Li, J., Li, D., Savarese, S., and Hoi, S
URL https: //arxiv.org/abs/2504.14920. Li, J., Li, D., Savarese, S., and Hoi, S. Blip-2: Boot- strapping language-image pre-training with frozen im- age encoders and large language models,
-
[11]
URL https://arxiv.org/abs/2301.12597. Liang, X., Guo, X., Jin, Z., Pan, W., Shang, P., Cai, D., Lin, B., and Ye, J. Enhancing spatial reasoning through visual and textual thinking,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
URL https://arxiv. org/abs/2507.20529. Liu, H., Li, C., Wu, Q., and Lee, Y . J. Visual instruction tun- ing,
-
[13]
HiDe: Rethinking The Zoom-IN method in High Resolution MLLMs via Hierarchical Decoupling
URL https: //arxiv.org/abs/2510.00054. Liu, Y ., Li, Z., Huang, M., Yang, B., Yu, W., Li, C., Yin, X.-C., Liu, C.-L., Jin, L., and Bai, X. Ocr- bench: on the hidden mystery of ocr in large multi- modal models.Science China Information Sciences, 67 (12), December
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
doi: 10.1007/ s11432-024-4235-6
ISSN 1869-1919. doi: 10.1007/ s11432-024-4235-6. URL http://dx.doi.org/ 10.1007/s11432-024-4235-6. Lu, P., Mishra, S., Xia, T., Qiu, L., Chang, K.-W., Zhu, S.-C., Tafjord, O., Clark, P., and Kalyan, A. Learn to explain: Multimodal reasoning via thought chains for science question answering,
-
[15]
arXiv:2209.09513 [cs.CL] NeurIPS 2022
URL https: //arxiv.org/abs/2209.09513. Mitra, C., Huang, B., Darrell, T., and Herzig, R. Com- positional chain-of-thought prompting for large multi- modal models,
-
[16]
Shao, H., Qian, S., Xiao, H., Song, G., Zong, Z., Wang, L., Liu, Y ., and Li, H
URL https://arxiv.org/ abs/2311.17076. Shao, H., Qian, S., Xiao, H., Song, G., Zong, Z., Wang, L., Liu, Y ., and Li, H. Visual cot: Advancing multi- modal language models with a comprehensive dataset and benchmark for chain-of-thought reasoning,
-
[17]
URL https://arxiv.org/abs/2403.16999. Shen, H., Liu, P., Li, J., Fang, C., Ma, Y ., Liao, J., Shen, Q., Zhang, Z., Zhao, K., Zhang, Q., Xu, R., and Zhao, T. Vlm-r1: A stable and generalizable r1-style large vision- language model, 2025a. URL https://arxiv.org/ abs/2504.07615. Shen, H., Zhao, K., Zhao, T., Xu, R., Zhang, Z., Zhu, M., and Yin, J. Zoomeye: E...
-
[18]
OpenThinkIMG: Learning to Think with Images via Visual Tool Reinforcement Learning
URL https://arxiv.org/ abs/2505.08617. Sur´ıs, D., Menon, S., and V ondrick, C. Vipergpt: Visual inference via python execution for reasoning,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
ViperGPT: Visual Inference via Python Execution for Reasoning
URL https://arxiv.org/abs/2303.08128. Tong, S., Brown, E., Wu, P., Woo, S., Middepogu, M., Akula, S. C., Yang, J., Yang, S., Iyer, A., Pan, X., Wang, Z., Fergus, R., LeCun, Y ., and Xie, S. Cambrian- 1: A fully open, vision-centric exploration of multi- modal llms,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Cambrian-1: A Fully Open, Vision-Centric Exploration of Multimodal LLMs
URL https://arxiv.org/abs/ 2406.16860. Wang, H., Su, A., Ren, W., Lin, F., and Chen, W. Pixel rea- soner: Incentivizing pixel-space reasoning with curiosity- driven reinforcement learning, 2025a. URL https: //arxiv.org/abs/2505.15966. Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., et al. Qwen2-vl: Enhancing vi...
work page internal anchor Pith review Pith/arXiv arXiv
- [21]
-
[22]
Xu, R., Yao, Y ., Guo, Z., Cui, J., Ni, Z., Ge, C., Chua, T.-S., Liu, Z., Sun, M., and Huang, G
URL https: //arxiv.org/abs/2312.14135. Xu, R., Yao, Y ., Guo, Z., Cui, J., Ni, Z., Ge, C., Chua, T.-S., Liu, Z., Sun, M., and Huang, G. Llava-uhd: an lmm per- ceiving any aspect ratio and high-resolution images,
-
[23]
URLhttps://arxiv.org/abs/2403.11703. Xu, Y ., Li, C., Zhou, H., Wan, X., Zhang, C., Korhonen, A., and Vuli´c, I. Visual planning: Let’s think only with images,
-
[24]
Visual planning: Let’s think only with images.arXiv preprint arXiv:2505.11409, 2025
URL https://arxiv.org/abs/ 2505.11409. Yang, S., Li, G., and Yu, Y . Dynamic graph attention for referring expression comprehension,
-
[25]
Yu, L., Poirson, P., Yang, S., Berg, A
URL https: //arxiv.org/abs/1909.08164. Yu, L., Poirson, P., Yang, S., Berg, A. C., and Berg, T. L. Modeling context in referring expressions. InEuro- pean conference on computer vision, pp. 69–85. Springer,
-
[26]
Zhang, J., Khayatkhoei, M., Chhikara, P., and Ilievski, F. Mllms know where to look: Training-free perception of small visual details with multimodal llms, 2025a. URL https://arxiv.org/abs/2502.17422. Zhang, X., Gao, Z., Zhang, B., Li, P., Zhang, X., Liu, Y ., Yuan, T., Wu, Y ., Jia, Y ., Zhu, S.-C., and Li, Q. Adaptive chain-of-focus reasoning via dynami...
-
[27]
Zheng, Z., Yang, M., Hong, J., Zhao, C., Xu, G., Yang, L., Shen, C., and Yu, X
URL https://arxiv.org/abs/2310.16436. Zheng, Z., Yang, M., Hong, J., Zhao, C., Xu, G., Yang, L., Shen, C., and Yu, X. Deepeyes: Incentivizing ”thinking with images” via reinforcement learning,
-
[28]
DeepEyes: Incentivizing "Thinking with Images" via Reinforcement Learning
URL https://arxiv.org/abs/2505.14362. Zhong, L., Rosenthal, F., Sicking, J., H¨uger, F., Bagdonat, T., Gottschalk, H., and Schwinn, L. Focus: Internal mllm representations for efficient fine-grained visual question answering,
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
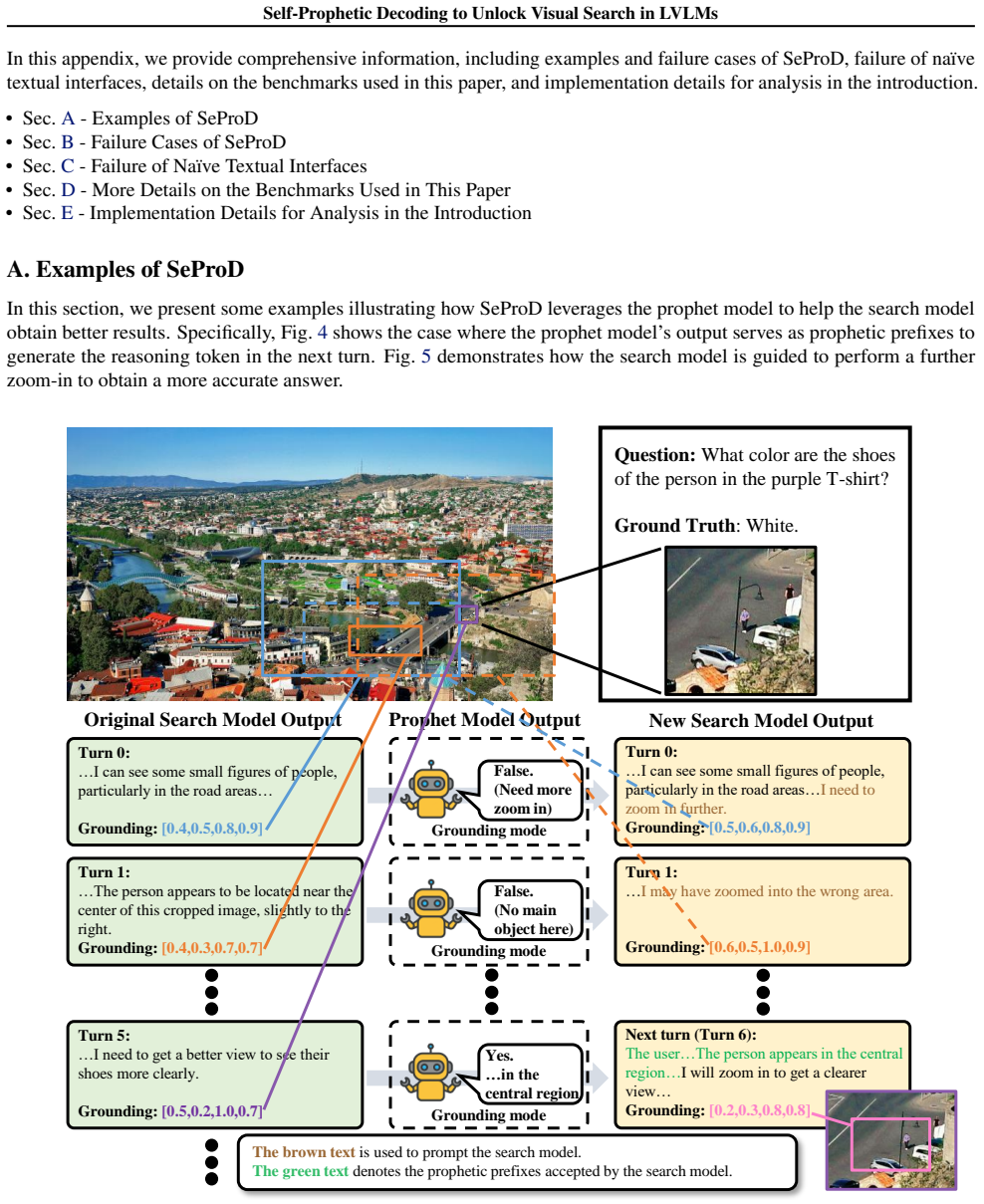
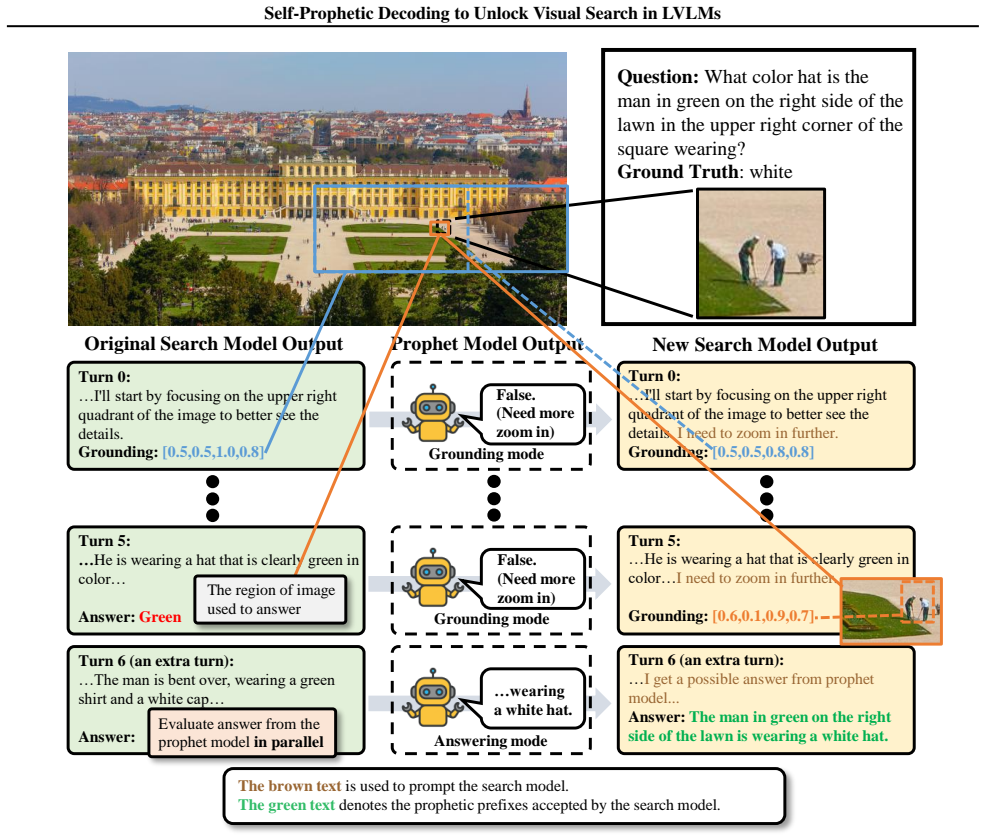
URL https://arxiv.org/abs/ 2506.21710. 11 Self-Prophetic Decoding to Unlock Visual Search in LVLMs In this appendix, we provide comprehensive information, including examples and failure cases of SeProD, failure of na¨ıve textual interfaces, details on the benchmarks used in this paper, and implementation details for analysis in the introduction. • Sec. A ...
-
[30]
138818073
is a benchmark constructed on 191 high-resolution images sampled from the SA-1B dataset (Kirillov et al., 2023). For each image, a multiple-choice question is provided, where exactly one option is correct. 14 Self-Prophetic Decoding to Unlock Visual Search in LVLMs Original Search Model Output Prophet Model Output New Search Model Output Question: What is...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.