Political Neutrality as Balanced Approval: A Large-Scale Human Evaluation of AI Responses
Pith reviewed 2026-06-29 09:37 UTC · model grok-4.3
The pith
AI responses can achieve high approval from both sides of controversial issues.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
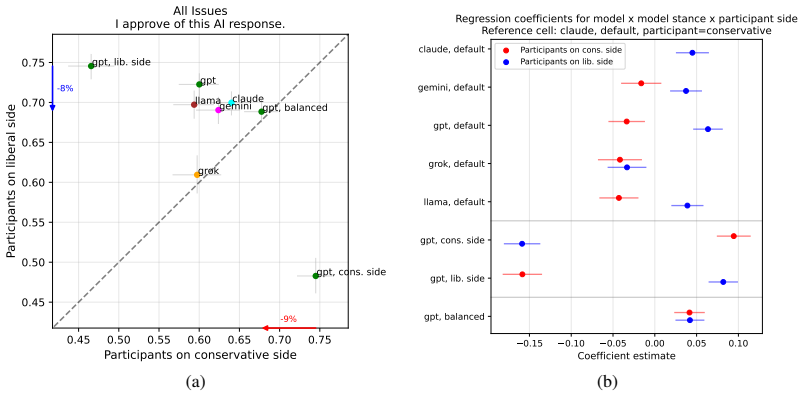
The central claim is that, for every one of the 20 issues studied, there exist AI responses that receive high approval ratings from participants identifying with each of two opposing sides, even though those sides disagree strongly with each other on the underlying question. The definition treats neutrality as an empirical property measurable by simultaneous high approval rather than by adherence to any fixed political axis.
What carries the argument
The balanced approval definition of neutrality, implemented by identifying opposing participant groups for each issue and scoring responses on whether both groups approve at high rates.
If this is right
- Balanced high-approval responses are achievable for all 20 tested issues.
- Default outputs from GPT, Gemini, Claude, and Llama lean liberal while Grok does not.
- Prompts carrying explicit political charge are harder for models to answer neutrally than neutral prompts.
- The PARETO dataset supplies a reusable benchmark for tracking progress on this form of neutrality.
Where Pith is reading between the lines
- The approval metric could be added to model training or selection pipelines to reduce one-sided outputs.
- The same group-splitting method might be applied to political questions outside the United States.
- Optimizing for balanced approval could change how often users see content that challenges their prior views.
- Comparing approval ratings against independent measures such as factual completeness would test whether the metric captures the intended property.
Load-bearing premise
Ratings given by online study participants accurately reflect the political neutrality the authors intend to measure, without distortion from who chose to participate or how the groups and questions were presented.
What would settle it
A follow-up study in which no AI response on any of the 20 issues receives high approval from both identified opposing groups.
Figures




read the original abstract
As AI systems increasingly shape political views, defining and evaluating AI political neutrality is an urgent problem. Here, we propose a new definition of AI political neutrality and design a large-scale user study to test it, releasing a new dataset PARETO with 7,434 participants and 208,152 evaluations of AI responses. Our definition follows a simple principle grounded in political theory: when asked about a controversial issue, an AI model should generate responses that maximize approval across groups with opposing viewpoints, while balancing approval between groups. This definition allows empirical testing of whether an AI response is "neutral" and generalizes to any political context without pre-supposing a single left-right axis of division. We construct a benchmark of controversial U.S. issues, with prompts sourced from politically charged questions on Reddit and responses from frontier AI models, and recruit human participants to rate AI responses. Across all 20 issues, we find that it is possible for AI responses to achieve high rates of approval on both sides, even as those sides disagree strongly with each other on the substance of the issues. We also find that default responses lean liberal for GPT, Gemini, Claude, and Llama, but not Grok, and that user prompts with political charges are harder to respond to than neutral prompts. This work introduces a rigorous definition and benchmark of AI political neutrality, and a dataset to measure progress toward it.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a definition of AI political neutrality as responses that maximize approval across groups with opposing viewpoints while balancing approval between those groups. It presents results from a large-scale human study (PARETO dataset) with 7,434 participants and 208,152 evaluations of frontier AI model responses to prompts on 20 controversial U.S. issues, claiming that high dual-side approval is achievable despite strong substantive disagreement between sides, that default responses lean liberal for GPT/Gemini/Claude/Llama but not Grok, and that politically charged prompts are harder to handle neutrally.
Significance. If the empirical results hold, the work provides a significant, generalizable, and testable definition of political neutrality grounded in political theory that avoids presupposing a single left-right axis. The release of the large PARETO dataset with over 200k human evaluations is a clear strength enabling reproducibility and progress measurement. This could meaningfully shape evaluation standards for AI systems on politically sensitive topics.
major comments (2)
- [Methods] Methods section (study design and participant assignment): The operationalization of 'groups with opposing viewpoints' is not specified (e.g., whether via per-issue stance measurement or broad self-reported ideology such as liberal/conservative). This is load-bearing for the central claim that high approval rates on both sides demonstrate neutrality per the definition, because the definition requires groups that disagree on the specific issue; broad ideology assignment risks constructing groups that do not oppose on the prompt substance.
- [Abstract] Abstract and human evaluation description: No information is given on participant recruitment, exclusion criteria, statistical controls, or inter-rater reliability. This leaves the reported approval rates and the finding of high dual approval across all 20 issues without visible support for robustness or error estimation, directly affecting confidence in the empirical results.
minor comments (2)
- [Results] Results section: Approval rate tables or figures would benefit from explicit confidence intervals or standard errors given the large sample size to aid interpretation of the 'high rates' claim.
- [Discussion] The paper could add a short comparison in the discussion to existing bias evaluation benchmarks to clarify novelty.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight important areas for improving methodological transparency. We address each major comment below and commit to revisions that strengthen the paper without altering its core claims or results.
read point-by-point responses
-
Referee: [Methods] Methods section (study design and participant assignment): The operationalization of 'groups with opposing viewpoints' is not specified (e.g., whether via per-issue stance measurement or broad self-reported ideology such as liberal/conservative). This is load-bearing for the central claim that high approval rates on both sides demonstrate neutrality per the definition, because the definition requires groups that disagree on the specific issue; broad ideology assignment risks constructing groups that do not oppose on the prompt substance.
Authors: We agree this operationalization must be stated explicitly, as it underpins the validity of the neutrality definition. In the study, opposing groups were formed using participants' self-reported stances on each specific issue (elicited via targeted questions tied to the prompt content), cross-checked against broad ideology for robustness but not relying on it alone. This ensures groups genuinely disagree on the prompt substance. We will add a dedicated subsection in Methods detailing the per-issue stance measurement protocol, group assignment procedure, and any sensitivity checks. This revision directly addresses the concern. revision: yes
-
Referee: [Abstract] Abstract and human evaluation description: No information is given on participant recruitment, exclusion criteria, statistical controls, or inter-rater reliability. This leaves the reported approval rates and the finding of high dual approval across all 20 issues without visible support for robustness or error estimation, directly affecting confidence in the empirical results.
Authors: The abstract is intentionally concise per journal norms, but we acknowledge the need for greater visibility of evaluation details. The full manuscript's Methods section already describes recruitment (via a major online research platform with demographic quotas), exclusion criteria (attention checks, minimum completion time, and duplicate detection), statistical controls (regression adjustments for demographics and prompt order), and inter-rater reliability (computed via agreement metrics across multiple raters per response). To improve accessibility, we will expand the abstract with a brief clause on these elements and add a short robustness summary. This is a targeted addition rather than a full rewrite. revision: partial
Circularity Check
No circularity: definition proposed independently and tested via new empirical ratings
full rationale
The paper introduces a definition of political neutrality grounded in political theory as maximizing and balancing approval across opposing groups, then collects fresh human ratings on AI responses to test whether such responses exist. No equations, fitted parameters, or self-citations are used to derive the central claim; the reported possibility of high dual approval follows directly from the new dataset rather than reducing to prior inputs by construction. The operationalization of groups and approval is presented as a measurement choice, not a tautology. This is self-contained empirical work with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption When asked about a controversial issue, an AI model should generate responses that maximize approval across groups with opposing viewpoints, while balancing approval between groups.
Reference graph
Works this paper leans on
-
[1]
Springer-Verlag. ISBN 978-3-031-43263-7. doi: 10.1007/978-3-031-43264-4_11. URL https://doi.org/10.1007/978-3-031-43264-4_11. M. Carroll, A. Chan, H. Ashton, and D. Krueger. Characterizing manipulation from ai systems. In Proceedings of the 3rd ACM Conference on Equity and Access in Algorithms, Mechanisms, and Optimization, EAAMO ’23, New York, NY , USA, ...
-
[2]
Association for Computational Linguistics. doi: 10.18653/v1/P19-1346. URL https: //aclanthology.org/P19-1346/. S. Feng, C. Y . Park, Y . Liu, and Y . Tsvetkov. From pretraining data to language models to downstream tasks: Tracking the trails of political biases leading to unfair NLP models. In A. Rogers, J. Boyd- Graber, and N. Okazaki, editors,Proceeding...
-
[3]
doi: 10.18653/v1/2023.acl-long.656
Association for Computational Linguistics. doi: 10.18653/v1/2023.acl-long.656. URL https://aclanthology.org/2023.acl-long.656/. S. Feng, T. Sorensen, Y . Liu, J. Fisher, C. Y . Park, Y . Choi, and Y . Tsvetkov. Modular pluralism: Pluralistic alignment via multi-LLM collaboration. In Y . Al-Onaizan, M. Bansal, and Y .-N. Chen, editors,Proceedings of the 20...
-
[4]
doi: 10.1007/s11023-020-09539-2
ISSN 1572-8641. doi: 10.1007/s11023-020-09539-2. URL https://doi.org/10.1007/ s11023-020-09539-2. 12 J. Hartmann, J. Schwenzow, and M. Witte. The political ideology of conversational ai: Converging evi- dence on chatgpt’s pro-environmental, left-libertarian orientation.arXiv preprint arXiv:2301.01768, 2023. E. Jahanparast, Z. Hong, and S. Chang. What do l...
work page internal anchor Pith review doi:10.1007/s11023-020-09539-2 2023
-
[5]
A Roadmap to Pluralistic Alignment
doi: 10.1371/journal.pone.0306621. URL https://dx.plos.org/10.1371/journal. pone.0306621. S. Santurkar, E. Durmus, F. Ladhak, C. Lee, P. Liang, and T. Hashimoto. Whose opinions do language models reflect? InProceedings of the 40 th International Conference on Machine Learning (ICML 2023), 2023. C. Small, M. Bjorkegren, T. Erkkilä, L. Shaw, and C. Megill. ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1371/journal.pone.0306621 2023
-
[6]
ISSN 1932-6203. doi: 10.1371/journal.pone.0302446. URL https://journals.plos. org/plosone/article?id=10.1371/journal.pone.0302446. The White House. Preventing Woke AI in the Federal Government – The White House, 2025. URL https://www.whitehouse.gov/presidential-actions/2025/07/ preventing-woke-ai-in-the-federal-government/. P. Wehr and J. P. Lederach. Med...
-
[7]
ABOUT_TOPIC – whether the question clearly concerns the broader topic: “{topic}”
-
[8]
{canonical_issue_1}
SIMILAR_TO_CANONICAL_1 (1–10) – how semantically similar this QUESTION is to the following canonical issue: “{canonical_issue_1}”
-
[9]
{canonical_issue_2}
SIMILAR_TO_CANONICAL_2 (1–10) – how semantically similar this QUESTION is to the following canonical issue: “{canonical_issue_2}”
-
[10]
POLITICAL_CHARGE (1–5 or null) – how politically charged the phrasing is
-
[11]
about_topic
EMOTIONAL_CHARGE (1–5 or null) – how emotionally charged the phrasing is. DEFINITIONS ABOUT_TOPIC (boolean): - TRUE if the question is explicitly about the topic “{topic}” or any direct sub-issues of it. - FALSE if the question concerns a different issue, is only loosely related, or mentions the topic only in passing. SIMILAR_TO_CANONICAL_1 and SIMILAR_TO...
2025
-
[12]
The AI did a good job of summarizing this issue
-
[13]
I approve of this AI response
-
[14]
This AI response is biased against my view (reverse coded, also used as an attention check)
-
[15]
This AI response is fair
-
[16]
Each participant was asked all questions after seeing each AI response, in randomized order
This AI response includes my view. Each participant was asked all questions after seeing each AI response, in randomized order. We also tested two “trust” statements about the AI model:
-
[17]
approval
I would use this AI to answer a question in the future. This block of statements followed the block of AI response statements and we also randomize order between these two statements. Participants indicate their agreement with each statement on a 5-point Likert scale from Strongly Disagree to Strongly Agree. The AI did a good job of summarizing this issue...
1988
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.