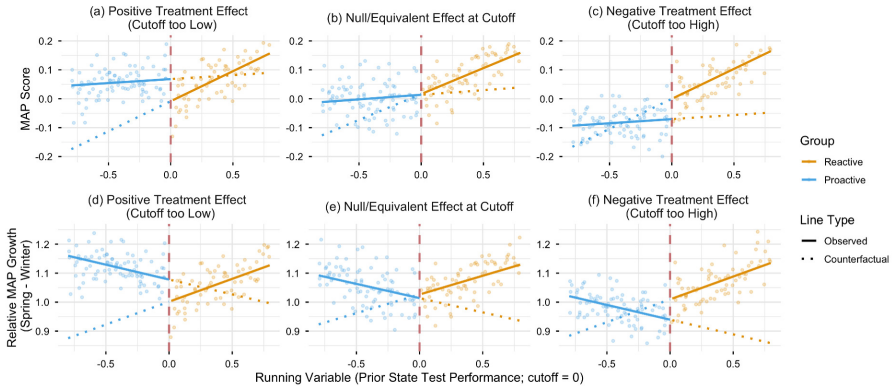
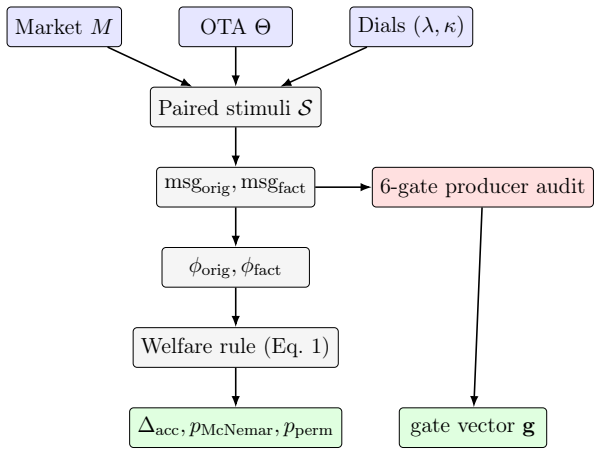
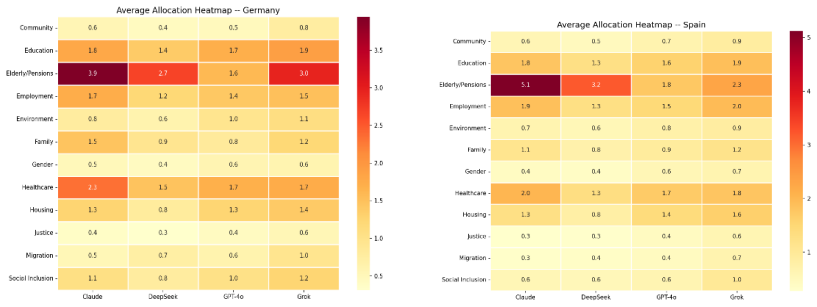
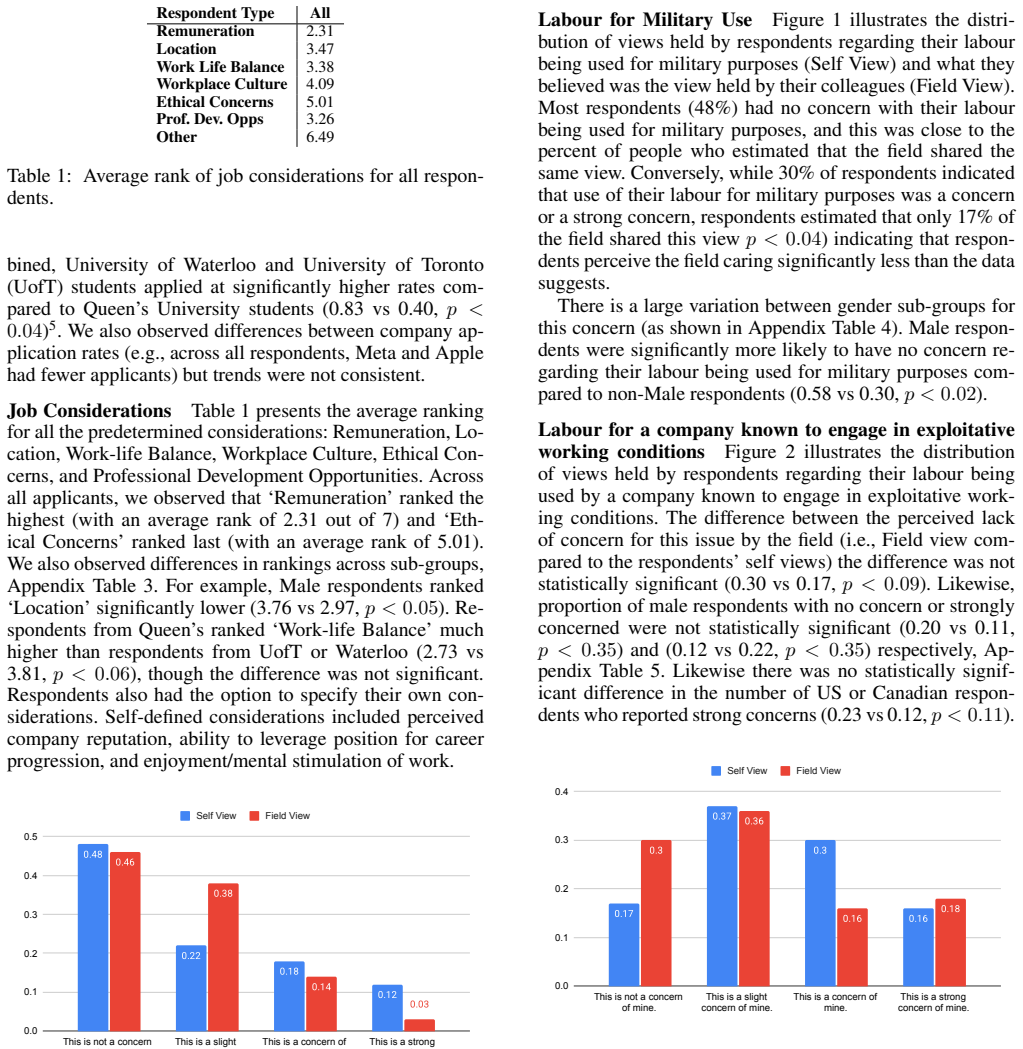
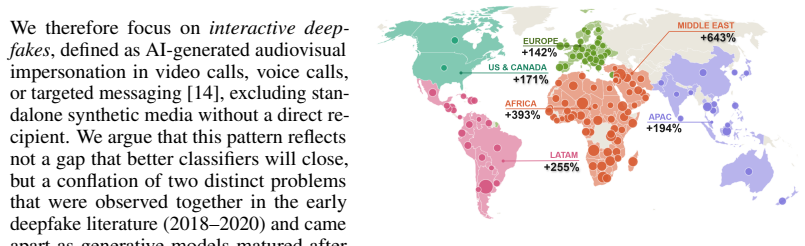
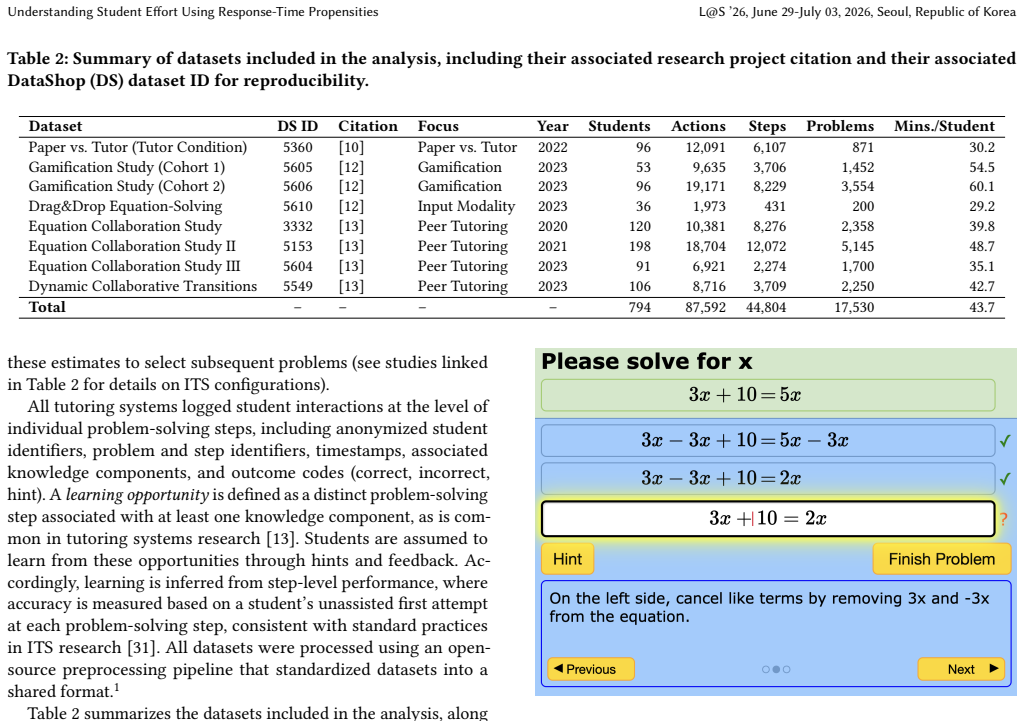
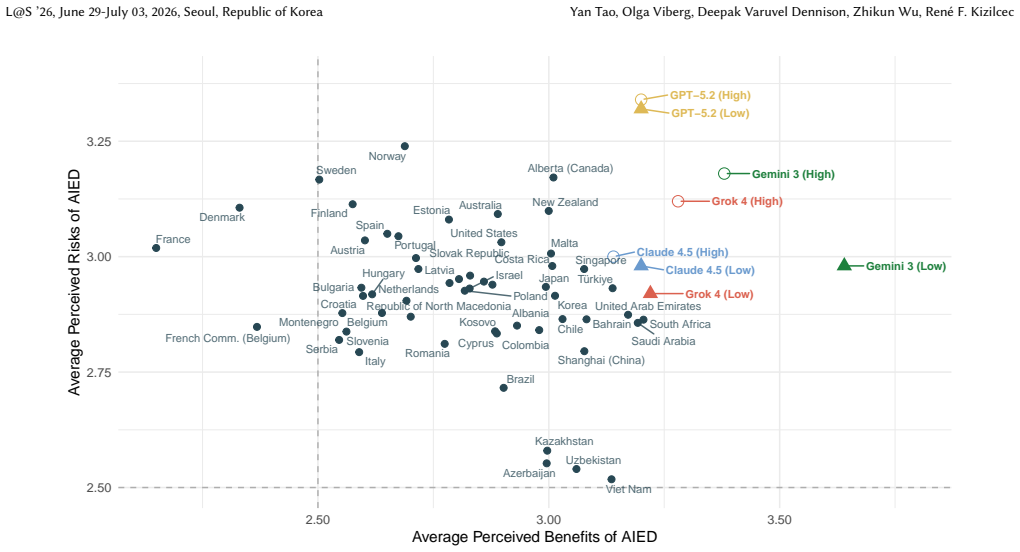
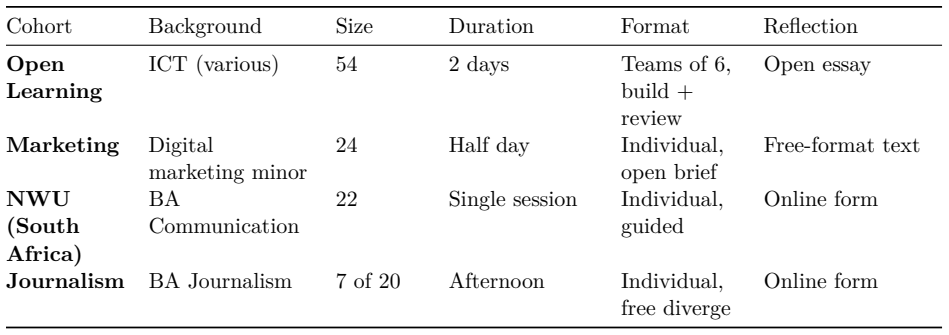
0
AI in exams makes judging solutions the new measure of learning
Reimagining Assessment in the Age of Generative AI: Lessons from Open-Book Exams with ChatGPT
Transcripts from ChatGPT use reveal three patterns, showing that verification skills now matter more than unaided answer production.
abstract click to expand
Generative AI systems such as ChatGPT challenge traditional assumptions about academic assessment by enabling students to generate explanations, code, and solutions in real time. Rather than attempting to restrict AI use, this study investigates how students actually interact with such systems during formal evaluation. Engineering students were permitted to use ChatGPT during take-home open-book exams and were required to submit interaction transcripts alongside exam solutions. This provided direct observational evidence of reasoning processes rather than relying on self-reported behavior. Qualitative analysis revealed three progressive patterns of use: answer retrieval, guided collaboration, and critical verification. While some students initially copied questions verbatim and received generic responses, many refined prompts iteratively and tested outputs. Some of the strongest evidence of reasoning appeared when students evaluated incorrect or incomplete AI responses, revealing evaluative reasoning through debugging, comparison, and justification. The presence of generative AI shifted the cognitive task of assessment from producing solutions to assessing solution validity. The findings suggest that, in AI-mediated assessment environments, correctness of final answers alone may no longer provide sufficient evidence of comprehension. Instead, competencies such as prompt formulation, verification, and judgment become visible indicators of learning. Transparent integration of AI appeared to reduce focus on rule avoidance and promote self-regulation. Assessments should evolve to evaluate reasoning about solutions rather than independent solution production. Generative AI therefore does not invalidate assessment but has the potential to expose deeper forms of understanding aligned with professional practice.