Model Merging by Output-Space Projection
Pith reviewed 2026-06-29 13:37 UTC · model grok-4.3
The pith
Model merging reduces to solving a convex quadratic program that matches fine-tuned outputs on calibration inputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
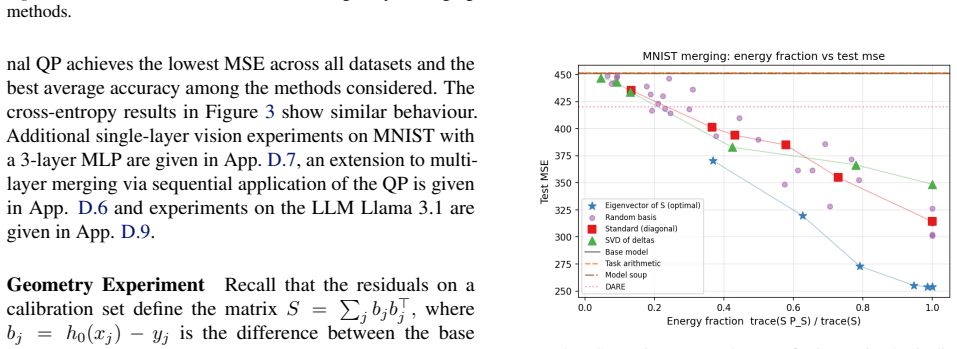
Merging can be formulated as a convex quadratic programme over residual updates, yielding weights that minimise a squared-output calibration objective using calibration inputs and fine-tuned model outputs, and subsuming existing methods as special cases. The framework yields a closed-form diagnostic—the fraction of residual energy captured by a chosen basis—that predicts downstream merge quality using only the calibration set.
What carries the argument
Convex quadratic program over coefficients of residual updates that minimizes squared output discrepancy on calibration inputs.
If this is right
- Existing methods such as task arithmetic, model soups, TIES and DARE arise as particular choices of basis or regularization inside the same quadratic program.
- The residual-energy diagnostic computed from calibration data alone ranks candidate merges by expected downstream performance.
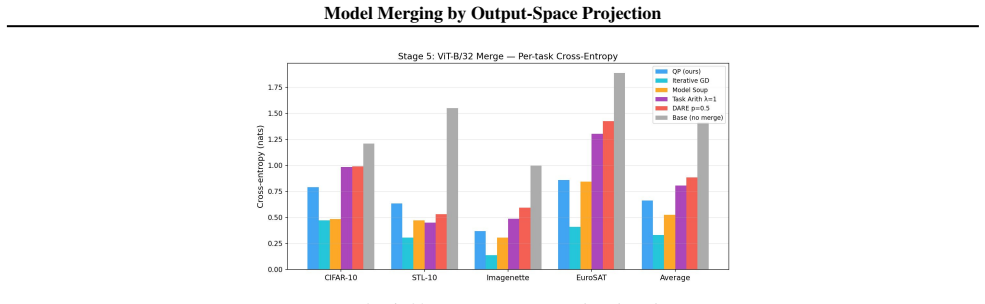
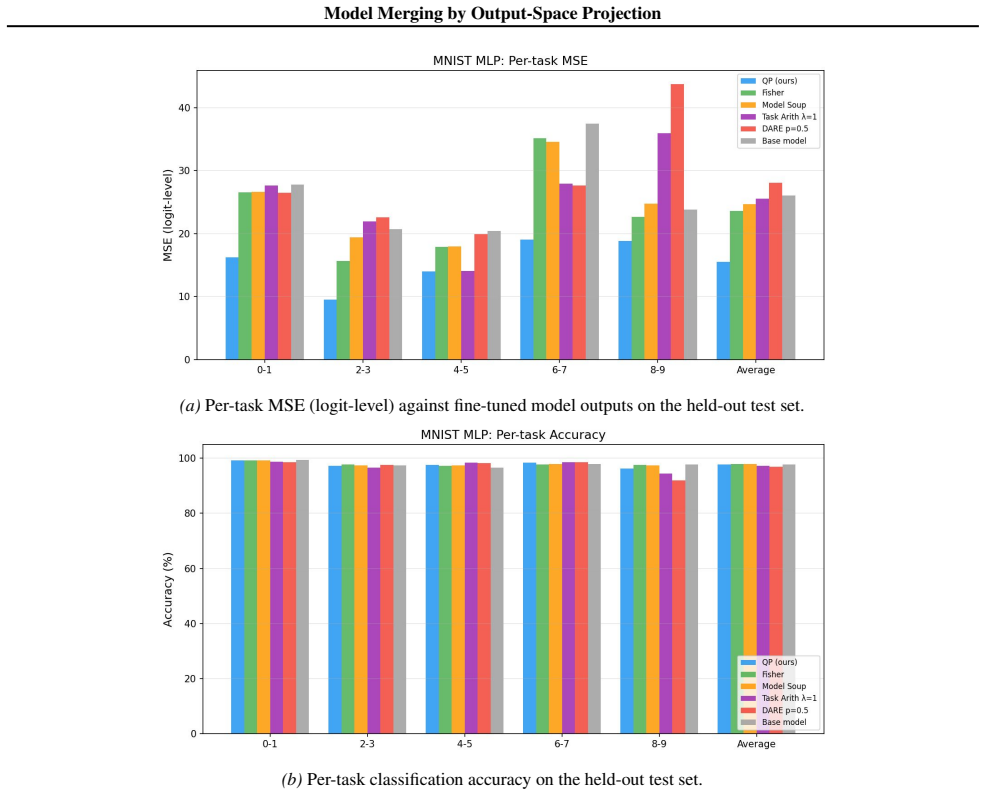
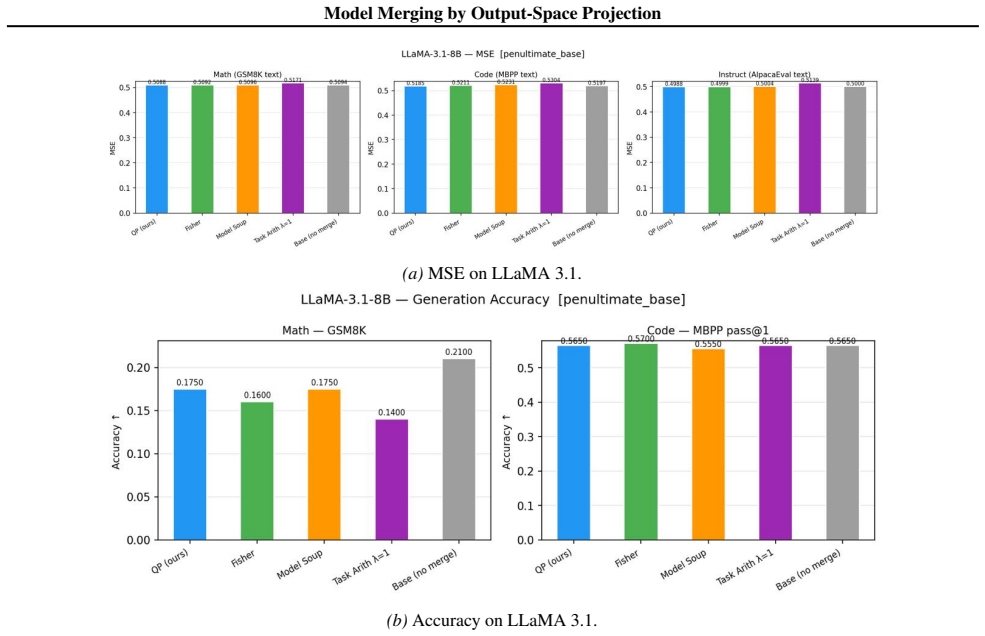
- In the single-layer case the quadratic-program solution matches or exceeds the accuracy of prior heuristics.
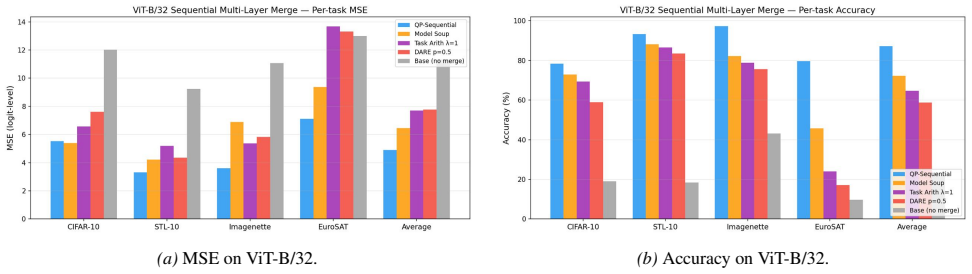
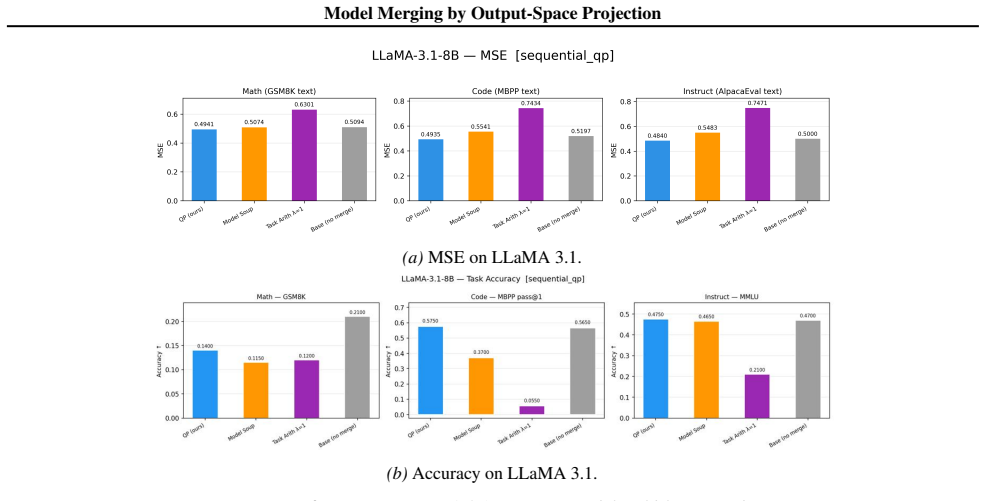
- Sequential layer-wise application of the program produces merged models that improve over single-layer baselines on language and vision benchmarks.
Where Pith is reading between the lines
- The same output-space projection could be applied when merging models whose fine-tuning distributions differ markedly from the calibration inputs.
- Enlarging the residual basis to include updates from more than two fine-tuned models would yield a direct multi-model extension of the current two-model formulation.
- For very large models an approximate solver for the quadratic program could still be validated by checking whether the energy diagnostic remains predictive of final accuracy.
Load-bearing premise
A calibration set of inputs together with the outputs of the fine-tuned models is sufficient to determine a merge whose performance on downstream tasks can be reliably predicted by the residual-energy diagnostic.
What would settle it
Compute the residual-energy fraction on the calibration set and check whether it fails to correlate with measured accuracy of the resulting merged model on held-out downstream tasks across multiple benchmarks.
Figures


read the original abstract
Model merging combines fine-tuned checkpoints into a single multi-task model without retraining. Existing methods - such as task arithmetic, model soups, TIES, and DARE - are computationally efficient and empirically successful, but rely on heuristic design choices and lack formal optimality guarantees. We show that merging can be formulated as a convex quadratic programme over residual updates, yielding weights that minimise a squared-output calibration objective using calibration inputs and fine-tuned model outputs, and subsuming existing methods as special cases. Our framework yields a closed-form diagnostic - the fraction of residual energy captured by a chosen basis - that predicts downstream merge quality using only the calibration set. Empirically, the QP matches or outperforms existing methods in the single-layer setting, and we characterise when the optimal basis provides significant gains over the cheaper diagonal QP. We extend to multi-layer merging via a sequential layer-wise algorithm and demonstrate consistent gains across language and vision benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that model merging can be cast as a convex quadratic program (QP) over residual updates that exactly minimizes a squared-output calibration objective given inputs and fine-tuned model outputs; this formulation subsumes task arithmetic, TIES, DARE and model soups as special cases, supplies a closed-form residual-energy diagnostic that predicts downstream quality from the calibration set alone, matches or exceeds prior methods in the single-layer case, and extends to multi-layer merging via a sequential layer-wise procedure with empirical gains on language and vision benchmarks.
Significance. If the optimality and subsumption claims hold, the work supplies the first convex optimization framing of output-space model merging together with an algebraic diagnostic that is computable from the same calibration data used for the merge. The explicit recovery of prior heuristics as special cases of basis or regularization choices, the convexity guarantee, and the layer-wise extension constitute concrete technical contributions that could replace ad-hoc design choices with a principled procedure.
major comments (1)
- [Abstract] The residual-energy diagnostic is obtained directly from the quadratic objective of the QP (see abstract statement of the diagnostic). Because it is a monotonic function of the same calibration loss that the QP minimizes, its reported correlation with downstream quality on held-out tasks may be an in-sample artifact rather than an independent predictor; the manuscript should either derive a generalization bound or report the diagnostic's correlation on a calibration set disjoint from the one used to solve the QP.
minor comments (2)
- The abstract states that the QP 'subsumes existing methods as special cases' but does not list the precise basis or regularization settings that recover each cited method (task arithmetic, TIES, DARE). Adding an explicit table or corollary would make the subsumption claim immediately verifiable.
- The free parameter 'calibration set selection' is listed in the axiom ledger; the experimental section should report sensitivity of both the merged model and the energy diagnostic to different choices of calibration inputs.
Simulated Author's Rebuttal
We thank the referee for the careful review, positive assessment of the contributions, and recommendation of minor revision. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] The residual-energy diagnostic is obtained directly from the quadratic objective of the QP (see abstract statement of the diagnostic). Because it is a monotonic function of the same calibration loss that the QP minimizes, its reported correlation with downstream quality on held-out tasks may be an in-sample artifact rather than an independent predictor; the manuscript should either derive a generalization bound or report the diagnostic's correlation on a calibration set disjoint from the one used to solve the QP.
Authors: We agree that the residual-energy diagnostic is a direct (monotonic) function of the QP objective evaluated on the calibration data used to solve for the merge, so the reported correlations with held-out downstream performance could in principle reflect an in-sample artifact. Deriving a non-vacuous generalization bound that accounts for the data-dependent basis selection and the specific form of the diagnostic appears difficult without strong distributional assumptions that would not hold across the language and vision settings considered. We will therefore revise the manuscript to include an additional experiment in which the diagnostic is computed on a calibration set held disjoint from the data used to solve the QP, and its correlation with held-out task performance is re-reported under this protocol. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper's core step is to define a convex QP whose objective is exactly the squared-output calibration loss on the given inputs and fine-tuned outputs; optimality therefore holds by construction of the program, which is the intended formulation rather than a hidden reduction. Subsumption of prior methods follows from algebraic substitution of basis/regularization choices into the same QP and requires no external theorem. The residual-energy diagnostic is the normalized value of the same quadratic objective evaluated on the calibration set, so it is tautological on that set, but the paper presents its correlation with downstream task performance as an empirical finding validated on benchmarks rather than a definitional claim. No load-bearing self-citation, imported uniqueness result, or smuggled ansatz appears in the derivation; the argument remains a self-contained re-formulation whose internal statements are algebraically verifiable.
Axiom & Free-Parameter Ledger
free parameters (1)
- calibration set selection
axioms (1)
- domain assumption Merging can be expressed as a linear combination of residual updates between fine-tuned models
Reference graph
Works this paper leans on
-
[1]
Evaluating Large Language Models Trained on Code
ISBN 978-0-521-83378-3. Google-Books-ID: mYm0bLd3fcoC. Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brock- man, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhai...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/cvpr 2021
-
[2]
IfH≻0, the minimiser is unique and given byd ∗ =−H −1f
-
[3]
The general-basis QP defines a single global optimisation over all merge coefficients
IfH⪰0is singular andf∈Range(H), then the set of minimisers is the affine subspace {d ∗ =−H +f+w:w∈ker(H)}. The general-basis QP defines a single global optimisation over all merge coefficients. The Hessian H contains cross-terms between models and basis directions, reflecting the fact that their contributions to the output are coupled through shared input...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.