Beyond Consensus: Trace-Level Synthesis in Mixture of Agents
Pith reviewed 2026-06-29 11:47 UTC · model grok-4.3
The pith
An LLM aggregator recovers correct answers from unanimous agent errors by synthesizing full reasoning traces.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
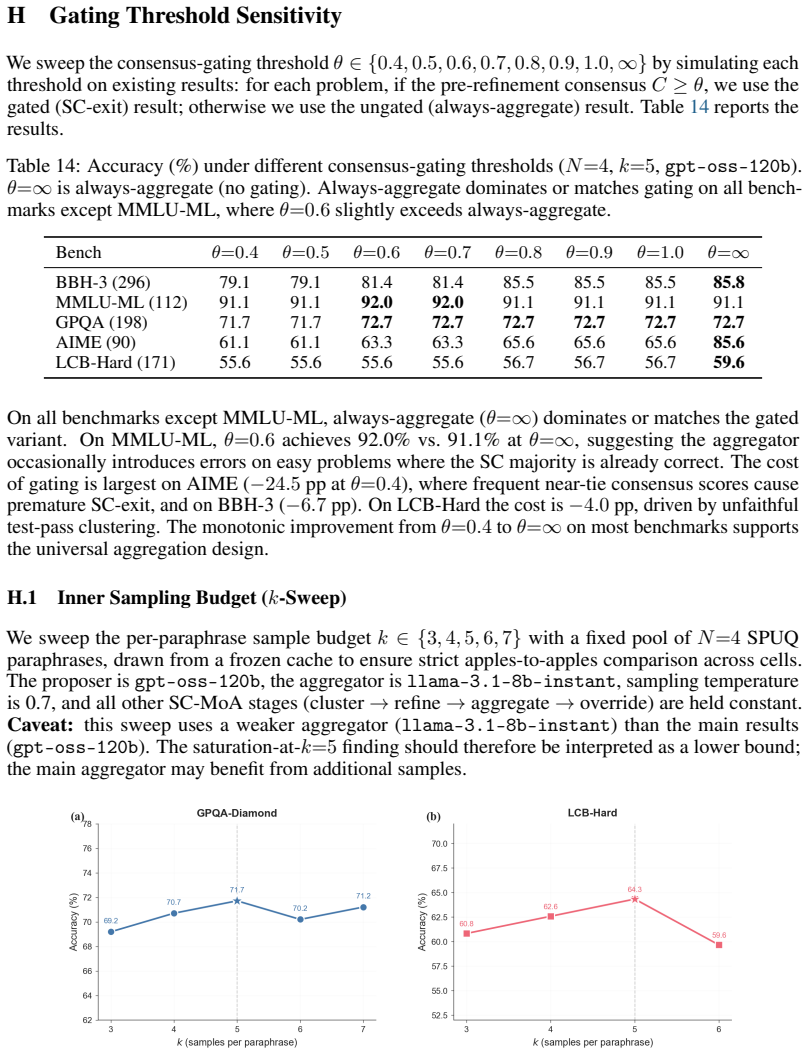
When multiple LLM agents solve the same problem, an aggregator that reads their complete reasoning traces recovers correct solutions even under unanimous agreement because beneficial corrections from trace-level complementarity consistently outweigh harmful ones. Majority voting reaches a performance ceiling since error correlations stay identical regardless of input perturbations. The gain arises from assembling correct intermediate steps from minority chains that voting discards. These observations motivate always synthesizing from traces rather than gating on consensus.
What carries the argument
The aggregation paradox: the empirical observation that an LLM aggregator produces net-beneficial corrections when synthesizing full reasoning traces, even when all agents agree on the wrong answer.
If this is right
- Majority voting has a fixed performance ceiling because error correlations remain unchanged by input perturbations.
- Trace-level synthesis assembles correct intermediate steps from minority chains that consensus methods discard.
- Anchored refinement supplies provable non-degradation guarantees when always synthesizing instead of gating on agreement.
- A single model with perturbation-induced trace variation outperforms heterogeneous model pools on structured reasoning, science, math, and programming tasks.
Where Pith is reading between the lines
- Perturbation-induced trace diversity within one model may substitute for the cost of maintaining multiple distinct models.
- The same trace-complementarity principle could apply to iterative agent systems where synthesis feeds back into new trace generation.
- If the aggregator reliably filters steps, the approach suggests that error detection along reasoning chains is a learnable capability worth isolating and improving.
Load-bearing premise
The aggregator LLM can reliably detect and retain correct intermediate steps from minority traces while discarding errors.
What would settle it
Measure whether the aggregator's synthesized answers on problems where all agents agree on an incorrect solution show higher accuracy than majority vote, with the rate of beneficial corrections exceeding harmful ones across a held-out benchmark.
Figures







read the original abstract
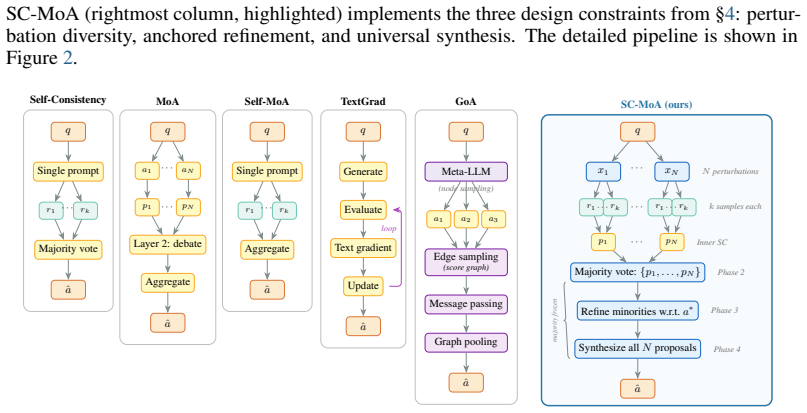
When multiple LLM agents solve the same problem, standard practice compresses each agent's reasoning into a majority vote or layered synthesis, treating agreement as the finish line. We show this is unnecessarily lossy: an LLM aggregator that reads complete reasoning traces recovers correct solutions even when agents unanimously agree, with beneficial corrections consistently outweighing harmful ones -- the \emph{aggregation paradox}. Majority voting has a ceiling that perturbation diversity does not raise (error correlations are identical); the aggregator's gain comes from trace-level complementarity, assembling correct intermediate steps from minority chains that voting discards. These findings motivate Self-Consistent Mixture of Agents which generates trace diversity through semantic-preserving input perturbations, safeguards the majority via anchored refinement with provable non-degradation guarantees, and always synthesizes -- never gates on consensus. A single model with perturbation-induced trace variation outperforms heterogeneous model pools across structured reasoning, PhD-level science, competition mathematics, and competitive programming. The unit of aggregation should be the reasoning trace, not the answer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that majority-vote or consensus-based aggregation in LLM mixtures is lossy because it discards reasoning traces; an LLM aggregator reading full traces can recover correct solutions even under unanimous agent agreement on an incorrect final answer by assembling correct intermediate steps from minority traces (the 'aggregation paradox'). It proposes Self-Consistent Mixture of Agents, which generates trace diversity via semantic-preserving input perturbations, applies anchored refinement with provable non-degradation guarantees, and always performs trace synthesis rather than gating on consensus. A single model with perturbation-induced trace variation is claimed to outperform heterogeneous model pools on structured reasoning, PhD-level science, competition mathematics, and competitive programming.
Significance. If the central claims hold with proper controls, the work could shift multi-agent LLM design from answer-level consensus to trace-level synthesis, offering a route to higher reliability on reasoning tasks without requiring model heterogeneity. The emphasis on provable non-degradation guarantees for anchored refinement and the empirical claim of single-model superiority are potential strengths if supported by rigorous ablations and verification procedures.
major comments (3)
- [Abstract / Method] Abstract and method description: the aggregation paradox claim requires that the aggregator performs reliable step-level selection and retention of correct intermediates from minority traces while discarding errors. No formal mechanism, verification procedure for step correctness, or ablation (e.g., full traces vs. answers-only input to the aggregator) is provided to isolate trace complementarity from the aggregator model's independent reasoning capability.
- [Abstract] Abstract: the 'provable non-degradation guarantees' for anchored refinement are invoked to safeguard the majority, but the assumptions under which these guarantees hold are not shown to cover the unanimous-wrong case that is central to the aggregation paradox.
- [Experiments] Experiments section (implied by claims of outperformance): no error bars, statistical tests, or ablations are described that would demonstrate beneficial corrections consistently outweigh harmful ones or rule out that observed gains derive from the aggregator solving the problem better on its own rather than from trace synthesis.
minor comments (1)
- [Abstract] The term 'aggregation paradox' is introduced without a concise formal statement or mathematical characterization that distinguishes it from standard ensemble effects.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to strengthen the empirical and formal support for our claims.
read point-by-point responses
-
Referee: [Abstract / Method] Abstract and method description: the aggregation paradox claim requires that the aggregator performs reliable step-level selection and retention of correct intermediates from minority traces while discarding errors. No formal mechanism, verification procedure for step correctness, or ablation (e.g., full traces vs. answers-only input to the aggregator) is provided to isolate trace complementarity from the aggregator model's independent reasoning capability.
Authors: We agree that the manuscript would benefit from an explicit ablation comparing aggregator performance on full traces versus answers-only inputs to isolate trace complementarity. The current description relies on the aggregator synthesizing from complete traces as motivated by the aggregation paradox, but we will add this ablation along with further detail on the synthesis prompting procedure in the revised method section. revision: yes
-
Referee: [Abstract] Abstract: the 'provable non-degradation guarantees' for anchored refinement are invoked to safeguard the majority, but the assumptions under which these guarantees hold are not shown to cover the unanimous-wrong case that is central to the aggregation paradox.
Authors: The anchored refinement provides non-degradation by construction when the anchor is retained, but we acknowledge that explicit coverage of the unanimous-wrong case is not detailed in the current text. We will add a formal statement of assumptions and an argument demonstrating applicability to this case in the revised manuscript. revision: yes
-
Referee: [Experiments] Experiments section (implied by claims of outperformance): no error bars, statistical tests, or ablations are described that would demonstrate beneficial corrections consistently outweigh harmful ones or rule out that observed gains derive from the aggregator solving the problem better on its own rather than from trace synthesis.
Authors: We will revise the experiments section to report error bars across runs, include statistical tests, and add ablations (including aggregator-only baselines) to show that beneficial corrections outweigh harmful ones and that gains stem from trace synthesis rather than independent solving by the aggregator. revision: yes
Circularity Check
No circularity detected; claims rest on empirical observations without self-referential reduction
full rationale
The abstract and described method present the aggregation paradox and trace-level synthesis as empirical results from experiments across multiple domains, with no equations, fitted parameters, or self-citations provided that would reduce any central claim to its inputs by construction. Mentions of 'provable non-degradation guarantees' and 'anchored refinement' are stated without details showing definitional equivalence or load-bearing self-citation. The derivation chain is self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Applying the correlated Hoeffding inequality [Ladha, 1992] with t=N ε yields the stated bound
Therefore Var(S)≤ N 4 1 + (N−1)¯ρ . Applying the correlated Hoeffding inequality [Ladha, 1992] with t=N ε yields the stated bound. When ¯ρ= 0, this reduces to the classical Condorcet–Hoeffding bound 1−exp(−2N ε 2); when ¯ρ→1, the bound becomes vacuous. .2 Hierarchical Marginalization (Proposition 5) This result instantiates classical stratified sampling [...
1992
-
[2]
independence
Under a faithful clustering function Φ, the consensus fidelity at thresholdc=k 0/Nsatisfies: F(c; Φ)≥1− N ⌈N c⌉ 1−p min pmin ⌈N c⌉ .(5) Under an unfaithful Φ, the bound does not hold: observed consensus may be inflated by spurious agreement. 13 When consensus gating is applied at threshold θ, the accuracy loss relative to always-aggregating is bounded by:...
-
[3]
Google-Proof
In this case Phase 5 (override) provides the safety net: if a′ scores worse, the system reverts. Empirically, the 14 bare-majority edge case accounts for <5% of problems; the override mechanism handles it correctly in all observed instances (Appendix N). .5 Synthesis Advantage Decomposition (Proposition 1) Statement.Let VOTEand SYNTHbe two aggregation pro...
2004
-
[4]
You are an intuitive problem solver. Start with your best guess, then verify it against the constraints. If verification fails, try the next most likely answer
show that MoA is a special case of GoA (GoA Proposition 1), SC-MoA’s phases can replace graph pooling in any GoA-family pipeline. Head-to-head on GPQA-Diamond, GoAMax and SC-MoA solve largely non-overlapping problem subsets (union ceiling: 79.8%), confirming their complementarity. SC-GoA: full composition experiment.To validate this composability claim em...
2023
-
[5]
2.Surface variation: vary word choice, sentence structure, and notation style
Semantic equivalence: each rephrasing must ask the same question and require the same answer. 2.Surface variation: vary word choice, sentence structure, and notation style. 3.Preserve numbers verbatim: all numerical values must appear exactly as in the original
-
[6]
Google-proof
Preserve code verbatim: all code blocks, variable names, and function signatures must be identical. 5.Preserve units: physical units (eV , m/s, kg, etc.) must appear exactly. 6.Produce exactlyNrephrasings: output as a JSON list. Validation.A regex-based check verifies that allprotected tokens—numbers, code blocks, and physical units—appear verbatim in eac...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.