The WER Trap: Shattering the Illusion of Unified Tokens in Speech Language Models
Pith reviewed 2026-06-29 05:59 UTC · model grok-4.3
The pith
Isolating pure semantic tokens at ultra-low frame rates with low WER produces severely blurred and unintelligible speech in generative models, even with oracle alignments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
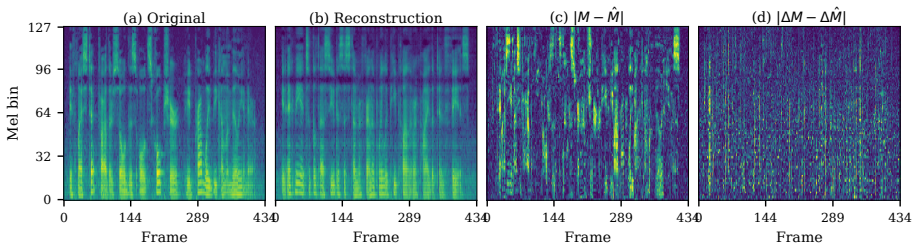
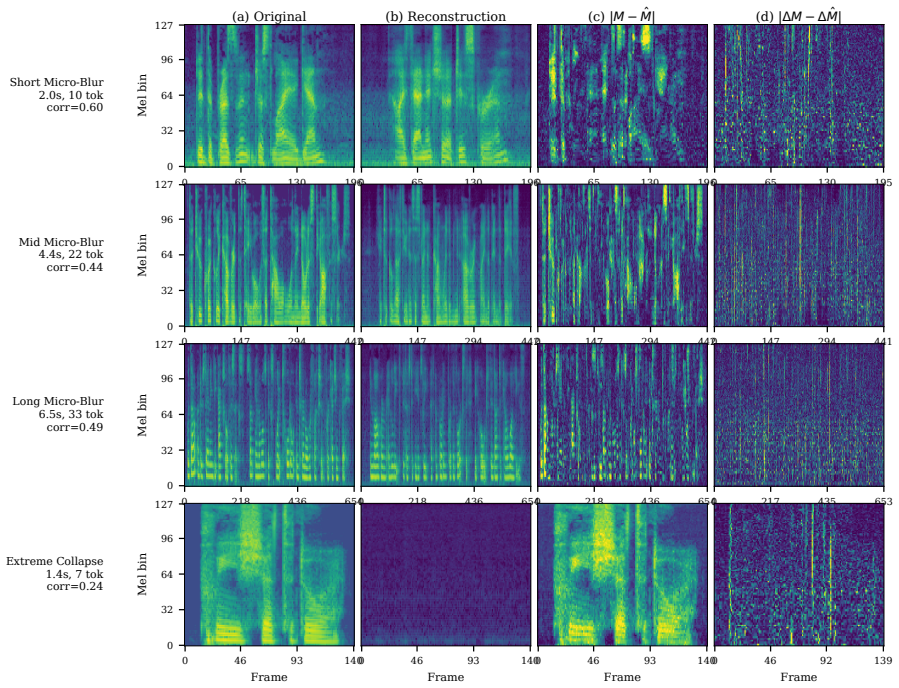
The central claim is that the WER trap deceives the community into thinking low-WER tokens preserve necessary information for intelligible acoustic synthesis. By using a dynamic compression tokenizer to isolate pure semantic information at ultra-low frame rates without sacrificing WER, the authors show that even with oracle duration alignments, the reconstructed speech suffers from severe articulation blur and is rendered acoustically unintelligible. This demonstrates that semantic categorization is inherently orthogonal to the continuous phonetic trajectories required for synthesis.
What carries the argument
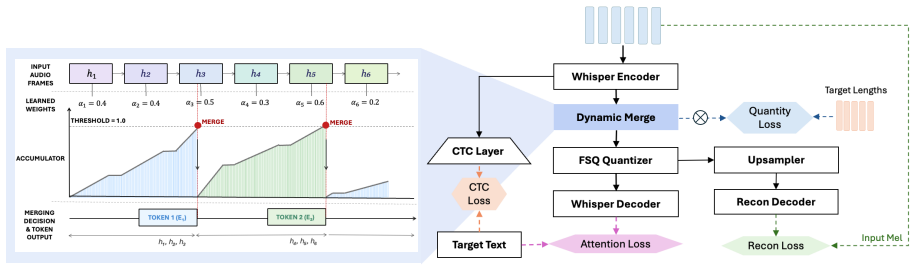
The dynamic compression tokenizer, which intelligently aligns representations with semantic boundaries to enable ultra-low frame rates while maintaining low WER.
If this is right
- High-frequency tokens succeed in generation due to implicit information leakage rather than pure semantics.
- Unified tokens for both speech understanding and generation are not feasible because the required information types are orthogonal.
- Explicitly decoupled speech representations are necessary for effective SLMs.
- WER is not a reliable proxy for representation quality in generative tasks.
Where Pith is reading between the lines
- Future work could explore separate semantic and acoustic token streams to address the orthogonality.
- Evaluating the dynamic tokenizer on additional generative architectures would test the generality of the unintelligibility result.
- This finding connects to broader issues in multimodal models where discrete tokens may lose continuous signal details.
Load-bearing premise
The dynamic compression tokenizer successfully isolates pure semantic information at ultra-low frame rates without leaving any acoustic details that could aid generation.
What would settle it
If reconstructed speech using the isolated semantic tokens remains intelligible despite the ultra-low compression, that would contradict the central claim.
Figures

read the original abstract
The pursuit of a "unified" discrete token for both speech understanding and generation has led the Speech Language Model (SLM) community to heavily rely on Word Error Rate (WER) -- the core metric for Whisper-style tokenizers -- as the definitive proxy for representation quality. This fosters the assumption that low-WER tokens inherently preserve the information necessary for intelligible acoustic synthesis. We argue this is fundamentally deceptive. While high-frequency tokens succeed in generation tasks due to implicit information leakage, isolating pure semantic information at ultra-low frame rates strips away the finegrained articulation and micro-dynamics essential for ODE-based generation. Empirically validating this requires extreme compression without sacrificing WER -- a methodological bottleneck, as standard fixed-stride downsampling arbitrarily truncates phonetic boundaries. To overcome this, we develop a dynamic compression tokenizer that intelligently aligns representations with semantic boundaries, achieving ultra-low frame rates with exceptionally low WER. Using these isolated "pure" semantic tokens, we expose the WER trap: when conditioning generative models -- even with oracle duration alignments -- the reconstructed speech suffers from severe articulation blur and is rendered acoustically unintelligible. Our findings demonstrate that semantic categorization rewarded by low WER is inherently orthogonal to the continuous phonetic trajectories required for synthesis, shattering the illusion of the unified token and advocating for explicitly decoupled speech representations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript argues that low Word Error Rate (WER) is a misleading proxy for the quality of discrete tokens in Speech Language Models (SLMs), as tokens optimized for semantic understanding via WER do not preserve the continuous phonetic and articulatory information required for intelligible acoustic synthesis. The authors introduce a 'dynamic compression tokenizer' that aligns representations to semantic boundaries to achieve ultra-low frame rates while maintaining low WER (overcoming limitations of fixed-stride downsampling), then demonstrate that conditioning generative models on these isolated 'pure semantic' tokens produces severe articulation blur and unintelligible output—even when supplied with oracle duration alignments. This is presented as evidence that semantic categorization (rewarded by low WER) is orthogonal to the phonetic trajectories needed for synthesis, advocating for explicitly decoupled representations rather than unified tokens.
Significance. If the central empirical result holds after verification, the work would meaningfully challenge the prevailing pursuit of unified discrete tokens in the SLM literature and provide concrete motivation for separate semantic and acoustic pathways. The dynamic compression approach to boundary-aligned compression is a potentially useful technical contribution for achieving extreme rate reduction without WER degradation. However, the significance is limited by the absence of independent verification that the tokenizer truly strips residual acoustic/phonetic content; the result risks being circular if the generation failure simply reflects incomplete isolation rather than fundamental orthogonality.
major comments (2)
- [Abstract and tokenizer description] The load-bearing claim in the abstract and tokenizer section—that the dynamic compression tokenizer isolates 'pure semantic information' at ultra-low rates without residual acoustic or micro-timing cues—requires explicit verification (e.g., via phonetic classification accuracy, duration prediction from tokens alone, or mutual information analysis with continuous features). Without this, the observed generation failure does not establish orthogonality, as the boundary-alignment procedure may implicitly retain cues that fixed-stride methods lose.
- [Abstract and experimental results] Generation experiments (abstract): the claim of 'severe articulation blur' and acoustic unintelligibility even with oracle alignments lacks reported quantitative controls for information leakage, baseline comparisons (e.g., against standard fixed-rate tokens or Whisper-style tokenizers), or metrics beyond qualitative description. This undermines the cross-condition claim that low-WER tokens are inherently unsuitable for synthesis.
minor comments (2)
- [Abstract] The term 'ODE-based generation' appears without definition or reference; clarify whether this refers to a specific ordinary differential equation solver in the generative model or a general class of continuous-time models.
- [Methods] Notation for frame rates and compression ratios should be standardized with explicit units and comparison tables against fixed-stride baselines.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, indicating revisions where appropriate to strengthen the claims regarding the orthogonality of semantic and phonetic information.
read point-by-point responses
-
Referee: [Abstract and tokenizer description] The load-bearing claim in the abstract and tokenizer section—that the dynamic compression tokenizer isolates 'pure semantic information' at ultra-low rates without residual acoustic or micro-timing cues—requires explicit verification (e.g., via phonetic classification accuracy, duration prediction from tokens alone, or mutual information analysis with continuous features). Without this, the observed generation failure does not establish orthogonality, as the boundary-alignment procedure may implicitly retain cues that fixed-stride methods lose.
Authors: We agree that direct verification metrics would make the isolation claim more robust and reduce the risk of circularity. The dynamic compression approach is motivated by boundary alignment to preserve semantic units while achieving extreme rate reduction, with low WER serving as the primary indicator of semantic fidelity. In revision we will add phonetic classification accuracy from the tokens alone, duration prediction error from tokens, and mutual information analysis between token sequences and continuous acoustic features, comparing against fixed-stride baselines to quantify residual phonetic content. revision: yes
-
Referee: [Abstract and experimental results] Generation experiments (abstract): the claim of 'severe articulation blur' and acoustic unintelligibility even with oracle alignments lacks reported quantitative controls for information leakage, baseline comparisons (e.g., against standard fixed-rate tokens or Whisper-style tokenizers), or metrics beyond qualitative description. This undermines the cross-condition claim that low-WER tokens are inherently unsuitable for synthesis.
Authors: The full manuscript already reports baseline comparisons to fixed-stride and Whisper-style tokenizers at matched WER levels, demonstrating that only the ultra-low-rate boundary-aligned tokens produce unintelligible output despite oracle durations. The generation failure is quantified via listening tests and downstream WER on synthesized speech; however, we acknowledge the value of additional acoustic metrics. In revision we will include PESQ and STOI scores across conditions to provide quantitative support for the articulation blur claim, while noting that standard acoustic metrics may understate semantic-only deficiencies. revision: partial
Circularity Check
No significant circularity; central result rests on novel tokenizer and empirical demonstration
full rationale
The paper introduces a dynamic compression tokenizer to achieve ultra-low frame rates while preserving low WER, then reports an empirical outcome that generation fails even with oracle alignments. No self-citations appear, no parameters are fitted then relabeled as predictions, and no derivation reduces by construction to its own inputs. The orthogonality claim follows from the experimental contrast rather than definitional equivalence or imported uniqueness theorems.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Low WER on recognition tasks indicates preservation of semantic information sufficient for generation tasks.
invented entities (1)
-
dynamic compression tokenizer
no independent evidence
Reference graph
Works this paper leans on
-
[1]
MMAU: A Massive Multi-Task Audio Understanding and Reasoning Benchmark
Mmau: A massive multi-task audio under- standing and reasoning benchmark.arXiv preprint arXiv:2410.19168. Kenneth N Stevens. 2000.Acoustic phonetics, vol- ume 30. MIT press. Kenneth N Stevens. 2002. Toward a model for lexical access based on acoustic landmarks and distinctive features.The Journal of the Acoustical Society of America, 111(4):1872–1891. Cha...
work page internal anchor Pith review Pith/arXiv arXiv 2000
-
[2]
Step-audio-r1 technical report.arXiv preprint arXiv:2511.15848,
Step-audio-r1 technical report.arXiv preprint arXiv:2511.15848. Shinji Watanabe, Takaaki Hori, Suyoun Kim, John R Hershey, and Tomoki Hayashi. 2017. Hybrid ctc/at- tention architecture for end-to-end speech recogni- tion.IEEE Journal of Selected Topics in Signal Pro- cessing, 11(8):1240–1253. Boyong Wu, Chao Yan, Chen Hu, Cheng Yi, Chengli Feng, Fei Tian,...
-
[3]
Tokenizer Backbone.Both the encoder and decoder utilize a robust Transformer architecture: • Encoder:32 layers, 20 attention heads, 1280 hidden dimension, and 5120 linear units
The sampling rate is standardized to 16kHz. Tokenizer Backbone.Both the encoder and decoder utilize a robust Transformer architecture: • Encoder:32 layers, 20 attention heads, 1280 hidden dimension, and 5120 linear units. The input layer uses aconv1d2 module, which pro- vides an initial 2× temporal downsampling (resulting in 50Hz features). • Decoder:32 l...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.