0
SMC dataset exposes tempo bias in state-of-the-art beat tracking models
The SMC Blind Spot: A Failure Mode Analysis of State-of-the-Art Beat Tracking
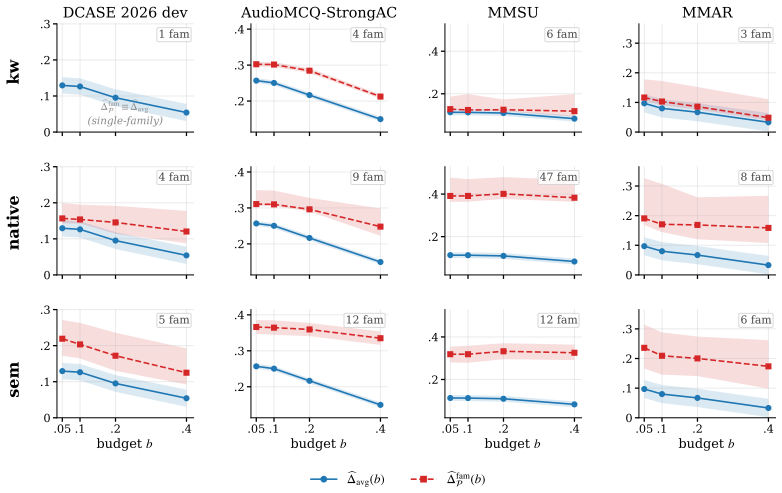
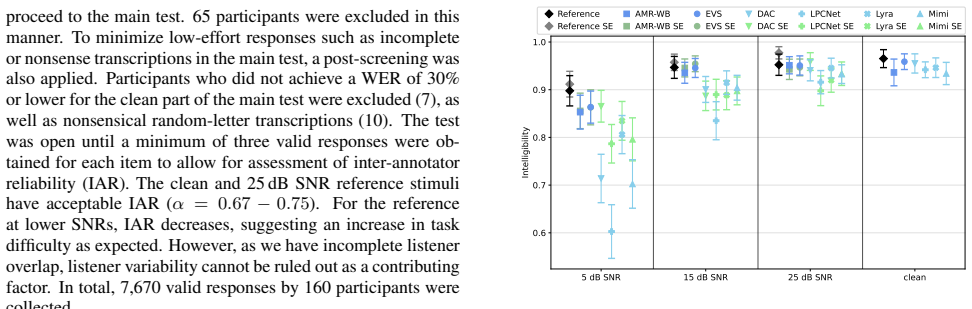
Default 55 BPM floor forces double-tempo output on 21% of slow tracks, plus octave and continuity errors.
abstract click to expand
Over the past two decades, the task of musical beat tracking has transitioned from heuristic onset detection algorithms to highly capable deep neural networks (DNN). Although DNN-based beat tracking models achieve near-perfect performance on mainstream, percussive datasets, the SMC dataset has stubbornly yielded low F-measure scores. By testing how well state-of-the-art models detect beats on individual tracks in the SMC dataset, we identify three distinct failure modes: octave errors, continuity errors, and complete tracking failure where all metrics fall below 0.3. We reveal that state-of-the-art models tend to generate "confident-but-wrong" activations. Furthermore, we show that the standard DBN's default minimum tempo of 55 BPM prevents it from inferring the correct tempo for 21\% of SMC tracks, forcing double-tempo predictions on slow music. By exposing such fundamental oversights, we provide concrete directions for improving beat and downbeat detection, specifically emphasizing training data diversification and multi-hypothesis tempo estimation.