ChildVox: A Speech, Audio, and Large Audio-Language Model Benchmark in Understanding and Characterizing Sound across Childhood
Pith reviewed 2026-06-29 06:06 UTC · model grok-4.3
The pith
ChildVox benchmark shows audio models achieve high performance on recognizing sounds made by children from birth to school age.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
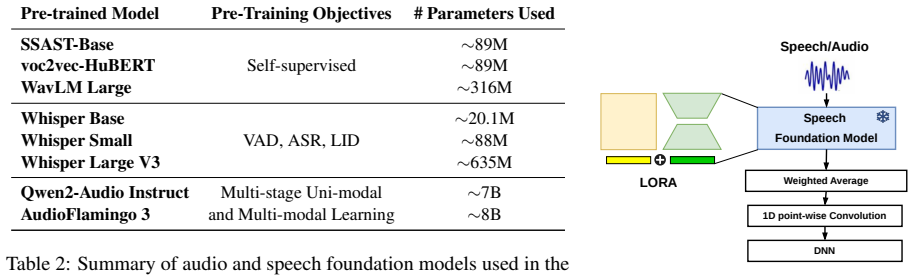
ChildVox follows the full developmental trajectory from birth through school age, covering physiological sounds, non-linguistic vocalizations, canonical syllables, and spoken language. It integrates more than 20 sub-tasks across 17 child-centered audio and speech datasets to enable systematic cross-corpus and cross-domain comparison. Evaluation of self-supervised, ASR-oriented, and large audio-language models on physiological sound classification, vocalization and canonical syllables modeling, and speech quality assessment and recognition shows high performance in recognizing acoustic signals from children.
What carries the argument
ChildVox benchmark, which unifies 17 datasets and over 20 sub-tasks along the developmental trajectory from physiological sounds to spoken language.
If this is right
- High-performance models from the benchmark can be applied to characterize children's language levels.
- The same models can track changes in speech production as children grow older.
- Systematic comparisons across different child audio datasets and task domains become feasible.
- The benchmark identifies models suitable for pediatric audio analysis applications.
Where Pith is reading between the lines
- The benchmark could support development of clinical tools that flag early speech production differences.
- Adding datasets from more varied cultural or linguistic backgrounds would test whether current results hold more broadly.
- Pairing the audio tasks with age-matched language milestone data might strengthen links to developmental assessment.
Load-bearing premise
The 17 selected datasets together cover the full developmental trajectory from birth through school age in a representative way without major gaps in physiological sounds, non-linguistic vocalizations, or spoken language.
What would settle it
A new collection of infant physiological sounds where models fine-tuned on the ChildVox tasks show low accuracy would indicate that the selected datasets leave significant gaps.
Figures




read the original abstract
We present ChildVox, a novel benchmark for characterizing the diverse acoustic signals through which children communicate. Specifically, ChildVox follows the full developmental trajectory from birth through school age, covering physiological sounds, non-linguistic vocalizations, canonical syllables, and spoken language. ChildVox integrates more than 20 sub-tasks across 17 child-centered audio and speech datasets, enabling systematic cross-corpus and cross-domain comparison. We evaluate a representative range of audio and speech foundation models, including self-supervised, ASR-oriented, and large audio-language models, on tasks including physiological sound classification, vocalization and canonical syllables modeling, and speech quality assessment and recognition. Benchmark results show that ChildVox provides a suite of high-performance models in recognizing a wide range of acoustic signals from children, supporting downstream applications such as characterizing children's language levels and tracking speech production with age.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ChildVox, a benchmark integrating 17 child-centered audio and speech datasets spanning more than 20 sub-tasks across the developmental trajectory from birth to school age. It covers physiological sounds, non-linguistic vocalizations, canonical syllables, and spoken language, and evaluates self-supervised, ASR-oriented, and large audio-language models on tasks including physiological sound classification, vocalization modeling, and speech quality assessment. The central claim is that the benchmark yields high-performance models for recognizing child acoustic signals, thereby supporting downstream applications such as characterizing children's language levels and tracking speech production with age.
Significance. If the datasets provide representative coverage without major gaps or biases, ChildVox would fill an important gap by enabling systematic cross-corpus evaluation of audio models on pediatric signals, where existing benchmarks are limited. The multi-domain evaluation across foundation model families is a constructive contribution that could guide model selection for child-specific applications. No machine-checked proofs or parameter-free derivations are present, as expected for an empirical benchmark paper.
major comments (1)
- [Abstract and dataset integration section] Abstract and dataset integration section: The claim that the 17 datasets together provide representative, unbiased coverage of the full birth-to-school-age trajectory (including physiological sounds and non-linguistic vocalizations) is load-bearing for the downstream-application assertions. No explicit analysis of age sampling density, demographic balance, or gaps in early-infancy physiological data is referenced, so the generalization to 'characterizing children's language levels' does not automatically follow from per-task performance numbers.
minor comments (1)
- [Abstract] Abstract: the phrase 'more than 20 sub-tasks' is used without enumeration; a summary table listing task names, dataset sources, and metrics would improve immediate readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the need for explicit coverage analysis. We address the major comment below and will revise the manuscript to incorporate additional analysis of dataset demographics and age distributions.
read point-by-point responses
-
Referee: [Abstract and dataset integration section] Abstract and dataset integration section: The claim that the 17 datasets together provide representative, unbiased coverage of the full birth-to-school-age trajectory (including physiological sounds and non-linguistic vocalizations) is load-bearing for the downstream-application assertions. No explicit analysis of age sampling density, demographic balance, or gaps in early-infancy physiological data is referenced, so the generalization to 'characterizing children's language levels' does not automatically follow from per-task performance numbers.
Authors: We agree that an explicit analysis of age sampling density, demographic balance, and gaps (particularly in early-infancy physiological data) would strengthen the load-bearing claims about representative coverage and better support assertions regarding downstream applications. In the revised manuscript, we will add a new subsection in the dataset integration section that provides: aggregated and per-dataset age histograms or summary statistics spanning birth to school age; available demographic metadata (e.g., gender or other reported attributes); and an explicit discussion of limitations and gaps. This will be derived from the source dataset metadata and will clarify the basis for generalizations to tasks such as characterizing language levels and tracking speech production with age. revision: yes
Circularity Check
Empirical benchmark evaluation with no derivations or fitted predictions
full rationale
The paper aggregates 17 existing child audio datasets into >20 sub-tasks and evaluates off-the-shelf audio/speech/LALM models on them. No equations, parameter fitting, or first-principles derivations are claimed; results are direct empirical measurements. The central claim (high-performance models support downstream uses) rests on the benchmark numbers themselves rather than any reduction to inputs by construction. No self-citation load-bearing steps or ansatz smuggling appear in the provided text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existing child audio datasets from separate studies can be aggregated into a coherent benchmark without significant labeling inconsistencies or selection effects.
Reference graph
Works this paper leans on
-
[1]
Gama: A large audio-language model with ad- vanced audio understanding and complex reasoning abilities. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 6288–6313. Christina E Gildersleeve-Neumann, Ellen S Kester, Bar- bara L Davis, and Elizabeth D Peña. 2008. English speech sound development in preschool-age...
-
[2]
Nonie K Lesaux and Linda S Siegel
Babar: from phoneme recognition to develop- mental measures of young children’s speech produc- tion.arXiv preprint arXiv:2603.05213. Nonie K Lesaux and Linda S Siegel. 2003. The de- velopment of reading in children who speak english as a second language.Developmental psychology, 39(6):1005. Jialu Li, Mark Hasegawa-Johnson, and Nancy L McEl- wain. 2021. An...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.