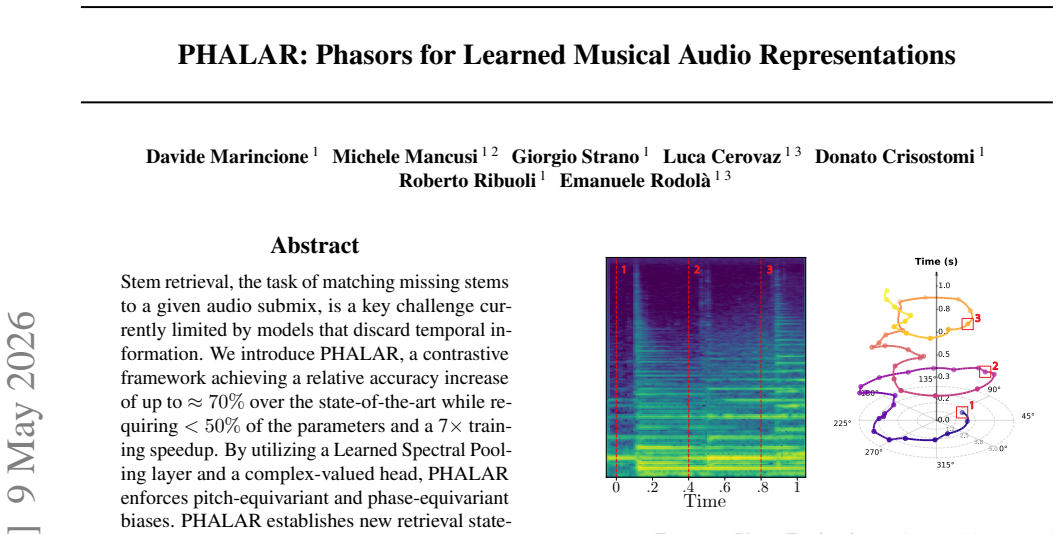
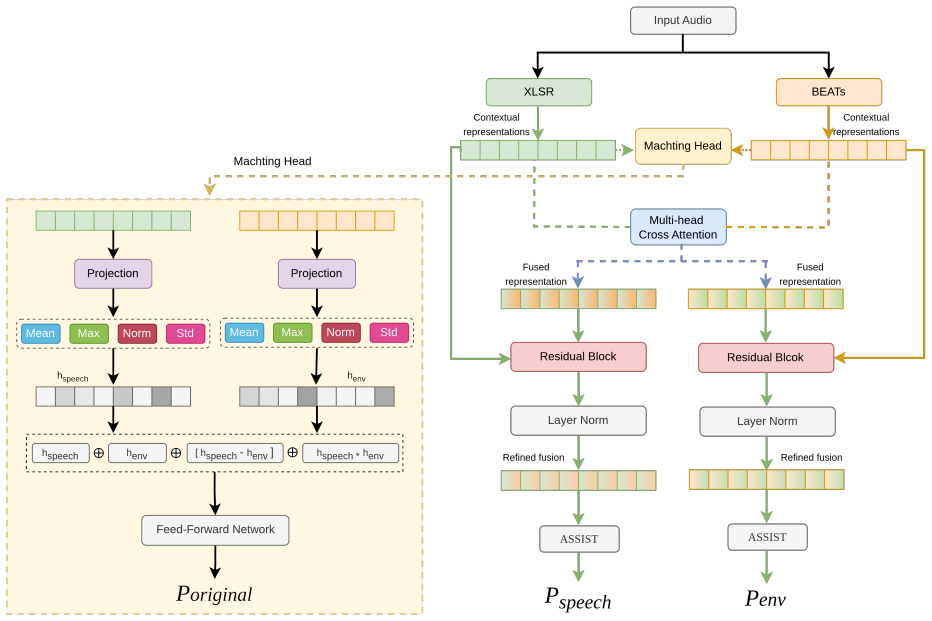
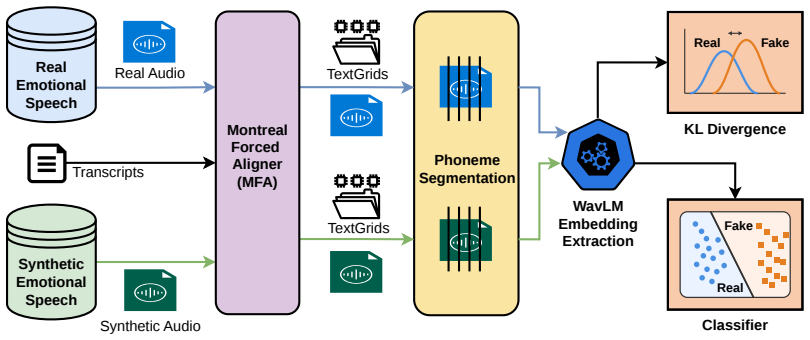
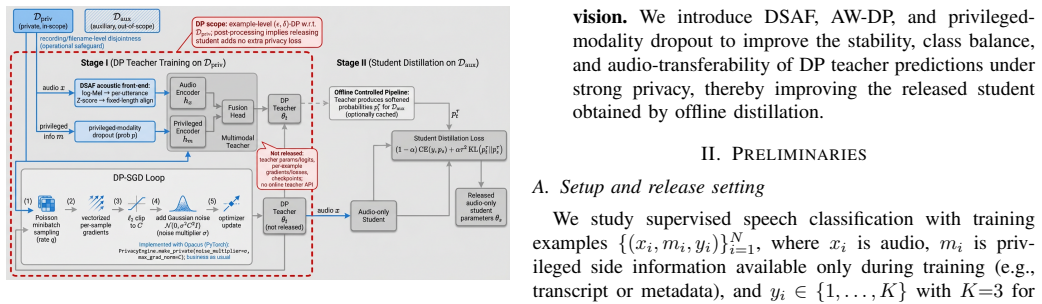
0
Hybrid Whisper model detects speaker confidence at 0.75 Macro-F1
A Semi-Supervised Framework for Speech Confidence Detection using Whisper
Adding prosodic features and careful pseudo-labels beats pure self-supervised audio models on scarce labelled data.
 full image
full image
abstract click to expand
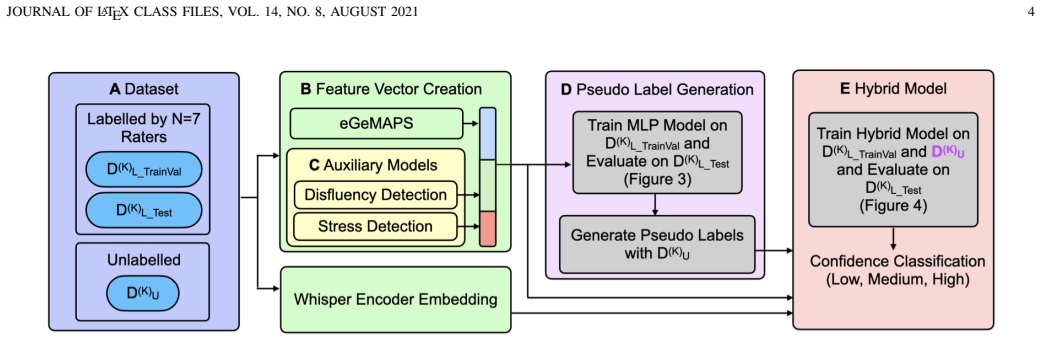
Automatic detection of speaker confidence is critical for adaptive computing but remains constrained by limited labelled data and the subjectivity of paralinguistic annotations. This paper proposes a semi-supervised hybrid framework that fuses deep semantic embeddings from the Whisper encoder with an interpretable acoustic feature vector composed of eGeMAPS descriptors and auxiliary probability estimates of vocal stress and disfluency. To mitigate reliance on scarce ground truth data, we introduce an Uncertainty-Aware Pseudo-Labelling strategy where a model generates labels for unlabelled data, retaining only high-quality samples for training. Experimental results demonstrate that the proposed approach achieves a Macro-F1 score of 0.751, outperforming self-supervised baselines, including WavLM, HuBERT, and Wav2Vec 2.0. The hybrid architecture also surpasses the unimodal Whisper baseline, yielding a 3\% improvement in the minority class, confirming that explicit prosodic and auxiliary features provide necessary corrective signals which are otherwise lost in deep semantic representations. Ablation studies further show that a curated set of high confidence pseudo-labels outperforms indiscriminate large scale augmentation, confirming that data quality outweighs quantity for perceived confidence detection.