Casual as an Anchor: Resolving Supervision Misalignment in Formality Transfer Dataset
Pith reviewed 2026-06-29 08:19 UTC · model grok-4.3
The pith
Binary labels in formality benchmarks capture relative shifts rather than absolute formality, causing models to output pseudo-formal text.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Binary human rewrites in current formality transfer benchmarks encode relative stylistic shifts rather than absolute human notions of formality. This design produces supervision that trains models to generate pseudo-formal outputs satisfying the labels while failing to match genuine formality. Reconceptualizing the task as a graded dimension with an explicit casual intermediate state, and supplying the 3LF dataset of parallel informal-casual-formal triples, supplies clearer signals that reduce informal-to-formal failures and raise agreement with human perception.
What carries the argument
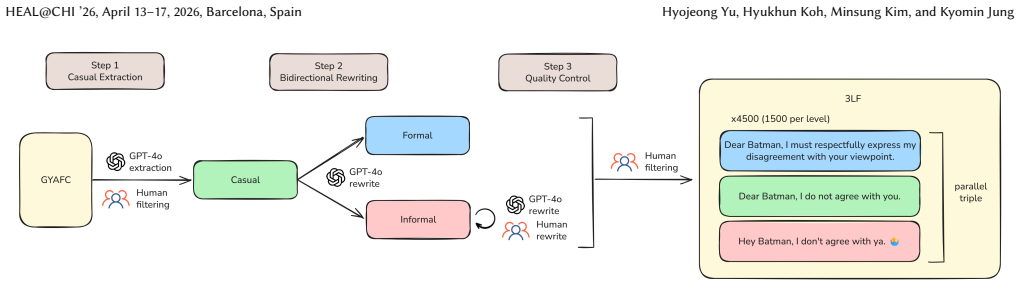
The three-level formality spectrum (informal, casual, formal) in which casual serves as an explicit intermediate state that clarifies supervision signals for the model.
If this is right
- Models trained on 3LF show large gains in informal-to-formal F1, for instance raising GPT-4.1-nano from 0.06 to 0.88 despite using far less data than GYAFC.
- The performance lift cannot be matched by in-context learning with the same three-level examples.
- Qualitative errors shift from ambiguity-driven meaning distortions toward fewer cases of under- or over-formalization.
Where Pith is reading between the lines
- The same graded-anchor approach could be tested on other controllable generation tasks such as politeness or sentiment transfer where binary labels may hide relative-shift artifacts.
- If the misalignment pattern appears in other style-transfer benchmarks, dataset construction should routinely include an explicit intermediate register rather than assuming binary symmetry.
Load-bearing premise
Re-evaluating existing binary labels against a human-aligned definition of formality accurately measures misalignment and the three-level spectrum corrects it without adding new labeling artifacts.
What would settle it
A blind human evaluation in which raters score the absolute formality of outputs from models trained on GYAFC versus 3LF on identical test inputs; if 3LF outputs do not receive reliably higher formality ratings, the central claim does not hold.
Figures

read the original abstract
Formality transfer is commonly framed as a symmetric bidirectional task between informal and formal registers. We argue that this framing conceals a supervision design flaw in existing benchmarks such as GYAFC: binary human rewrites encode relative stylistic shifts rather than absolute human notions of formality. Consequently, models learn to generate pseudo-formal outputs that satisfy benchmark labels while failing to produce genuinely formal language. We quantify this misalignment by re-evaluating benchmark formal labels under a human-aligned definition of formality, revealing substantial discrepancies that propagate to consistent informal-to-formal failures across model families. To address this issue, we reconceptualize formality transfer as a graded dimension rather than a binary attribute. We introduce a three-level spectrum: informal, casual, and formal, where casual serves as an explicit intermediate state that clarifies supervision signals. Based on this framework, we introduce 3LF, a dataset providing parallel supervision across all three levels. Training on 3LF substantially reduces informal-to-formal failures and improves alignment with human perception. For example, GPT-4.1-nano improves from 0.06 to 0.88 F1 in the informal-to-formal direction despite 3LF being significantly smaller than GYAFC. We further demonstrate that these gains cannot be reproduced through in-context learning alone and provide qualitative analyses of ambiguity-driven errors and meaning distortions. Overall, our findings demonstrate how supervision design shapes stylistic alignment and highlight the importance of alignment-aware benchmark construction in controllable text generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that binary labels in formality transfer benchmarks such as GYAFC encode relative stylistic shifts rather than absolute human notions of formality, causing models to produce pseudo-formal outputs that fail on genuine formality. It reconceptualizes the task as a graded three-level spectrum (informal, casual, formal) with casual as an explicit intermediate anchor, introduces the 3LF parallel dataset, and reports that training on 3LF yields large gains (e.g., GPT-4.1-nano informal-to-formal F1 rising from 0.06 to 0.88) while improving alignment with human perception; these gains are not reproducible via in-context learning alone.
Significance. If the F1 gains and alignment improvements hold under independent evaluation, the work would provide a concrete demonstration that supervision design choices in style transfer can induce systematic misalignment, along with a practical graded framework and dataset that future controllable generation research could adopt. The explicit anchoring role assigned to the casual level is a clear conceptual contribution.
major comments (1)
- [Abstract] Abstract: the central claim that 3LF training resolves misalignment and improves human alignment rests on the reported F1 increase (0.06 o 0.88) for GPT-4.1-nano; because this metric is computed under the new three-level human-aligned definition used to construct 3LF itself, the result is at risk of circularity and does not yet demonstrate improvement on the original GYAFC binary labels or on an independent human formality judgment.
Simulated Author's Rebuttal
We thank the referee for identifying a potential circularity concern in our evaluation. We address this directly below, clarifying that our design measures performance against an independently motivated human-aligned definition while separately documenting misalignment in the original GYAFC labels.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that 3LF training resolves misalignment and improves human alignment rests on the reported F1 increase (0.06 to 0.88) for GPT-4.1-nano; because this metric is computed under the new three-level human-aligned definition used to construct 3LF itself, the result is at risk of circularity and does not yet demonstrate improvement on the original GYAFC binary labels or on an independent human formality judgment.
Authors: The F1 scores compare two training regimes evaluated on the same 3LF test set whose labels follow the human-aligned three-level definition. The 0.06 score is obtained by models trained on GYAFC binary labels; the 0.88 score is obtained by models trained on 3LF. This contrast directly illustrates that binary supervision produces outputs misaligned with human formality notions. We separately quantify the original misalignment by re-evaluating GYAFC formal labels under the human-aligned definition, revealing systematic discrepancies that explain the low F1. The paper also reports qualitative and quantitative human judgments confirming improved perceived formality. We do not claim gains on the original GYAFC binary labels, as those labels are the source of the misalignment we diagnose. We can add explicit results on the original GYAFC test set if the referee considers it necessary. revision: partial
Circularity Check
No significant circularity; results are empirical evaluations on newly introduced data
full rationale
The paper introduces a new three-level formality spectrum and the 3LF dataset, then reports empirical F1 improvements (e.g., 0.06 to 0.88) when training models on 3LF versus GYAFC. These are presented as experimental outcomes from re-labeled data and model training, not as derivations, fitted parameters renamed as predictions, or results forced by self-citation chains. No equations, self-definitional steps, or load-bearing prior citations appear in the abstract or provided text that would reduce the central claims to tautologies. The evaluation metrics are applied to the new framework in a standard, falsifiable manner.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human notions of formality are better captured by a graded three-level spectrum than by binary labels.
invented entities (1)
-
Casual as explicit intermediate state
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Pavlick, Ellie and Tetreault, Joel. 2016. An Empirical Analysis of Formality in Online Communication. Transactions of the Association for Computational Lin- guistics. https://doi.org/10.1162/tacl_a_00083
-
[2]
Rao, Sudha and Tetreault, Joel. 2018. Dear Sir or Madam, May I Introduce the GYAFC Dataset: Corpus, Benchmarks and Metrics for Formality Style Transfer. Proceedings of the 2018 Conference of the North American Chapter of the Asso- ciation for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). https://doi.org/10.18653/v1/N18-1012
-
[3]
Briakou, Eleftheria and Lu, Di and Zhang, Ke and Tetreault, Joel. 2021. Olá, Bonjour, Salve! XFORMAL: A Benchmark for Multilingual Formality Style Trans- fer. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. https://doi.org/10.18653/v1/2021.naacl-main.256
- [4]
-
[5]
Liu, Pusheng and Wu, Lianwei and Wang, Linyong and Guo, Sensen and Liu, Yang
-
[6]
Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024)
Step-by-Step: Controlling Arbitrary Style in Text with Large Language Models. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024). https: //aclanthology.org/2024.lrec-main.1328/
2024
-
[7]
Wen Lai and Viktor Hangya and Alexander Fraser. 2024. Style-Specific Neurons for Steering LLMs in Text Style Transfer. ArXiv. https://api.semanticscholar.org/ CorpusID:273023003
2024
-
[8]
Saakyan, Arkadiy and Muresan, Smaranda. 2024. ICLEF: In-Context Learning with Expert Feedback for Explainable Style Transfer. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). https://doi.org/10.18653/v1/2024.acl-long.854
-
[9]
Toshevska, Martina and Kalajdziski, Slobodan and Gievska, Sonja. 2025. Style Knowledge Graph: Augmenting Text Style Transfer with Knowledge Graphs. Proceedings of the Workshop on Generative AI and Knowledge Graphs (GenAIK). https://aclanthology.org/2025.genaik-1.13/
2025
-
[10]
Heylighen, Francis. 1970. Formality of Language: definition, measurement and behavioral determinants
1970
-
[11]
Biber, Douglas. 1988. Variation across Speech and Writing. Cambridge University Press
1988
-
[12]
Biber, Douglas and Conrad, Susan. 2009. Register, Genre, and Style. Cambridge University Press
2009
-
[13]
Lai, Wen and Hangya, Viktor and Fraser, Alexander. 2024. Style-Specific Neurons for Steering LLMs in Text Style Transfer. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. https://doi.org/10.18653/v1/ 2024.emnlp-main.745
-
[14]
and McCrae, John Philip and Dusek, Ondrej
Mukherjee, Sourabrata and Ojha, Atul Kr. and McCrae, John Philip and Dusek, Ondrej. 2025. Evaluating Text Style Transfer Evaluation: Are There Any Reliable Metrics?. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 4: Student Research Workshop). ...
2025
-
[15]
Xinchen Yang and Marine Carpuat. 2025. Steering Large Language Models with Register Analysis for Arbitrary Style Transfer. arXiv. https://arxiv.org/abs/2505. 00679
2025
-
[16]
Dementieva, Daryna and Babakov, Nikolay and Panchenko, Alexander. 2023. Detecting Text Formality: A Study of Text Classification Approaches. Proceedings of the 14th International Conference on Recent Advances in Natural Language Processing. https://aclanthology.org/2023.ranlp-1.31/
2023
- [17]
-
[18]
Kong, Chaona and Liu, Jianyi and Tang, Yifan and Zhang, Ru. 2025. Neuron Activation Modulation for Text Style Transfer: Guiding Large Language Models. Findings of the Association for Computational Linguistics: ACL 2025. https: //doi.org/10.18653/v1/2025.findings-acl.403
-
[19]
Koh, Hyukhun and Kim, Dohyung and Lee, Minwoo and Jung, Kyomin. 2024. Can LLMs Recognize Toxicity? A Structured Investigation Framework and Toxicity Metric. Findings of the Association for Computational Linguistics: EMNLP 2024. https://doi.org/10.18653/v1/2024.findings-emnlp.353
-
[20]
Pauli, Amalie Brogaard and Augenstein, Isabelle and Assent, Ira. 2025. Mind the Style Gap: Meta-Evaluation of Style and Attribute Transfer Metrics. Findings of the Association for Computational Linguistics: EMNLP 2025. https://doi.org/10. 18653/v1/2025.findings-emnlp.1175
2025
-
[21]
La Quatra, Moreno and Gallipoli, Giuseppe and Cagliero, Luca. 2024. Self- supervised Text Style Transfer Using Cycle-Consistent Adversarial Networks. ACM Trans. Intell. Syst. Technol.. https://doi.org/10.1145/3678179
-
[22]
Hartmann, Jochen and Heitmann, Mark and Siebert, Christian and Schamp, Christina. 2023. More than a Feeling: Accuracy and Application of Sentiment Analysis. International Journal of Research in Marketing
2023
-
[23]
Sun, Zhewei and Hu, Qian and Gupta, Rahul and Zemel, Richard and Xu, Yang
-
[24]
Toward Informal Language Processing: Knowledge of Slang in Large Lan- guage Models. Proceedings of the 2024 Conference of the North American Chap- ter of the Association for Computational Linguistics: Human Language Technolo- gies (Volume 1: Long Papers). https://doi.org/10.18653/v1/2024.naacl-long.94
-
[25]
Joshua R. Tyler and Dennis M. Wilkinson and Bernardo A. Huberman. 2005. E- Mail as Spectroscopy: Automated Discovery of Community Structure within Or- ganizations. The Information Society. https://doi.org/10.1080/01972240590925348
-
[26]
Peterson, Kelly and Hohensee, Matt and Xia, Fei. 2011. Email formality in the workplace: a case study on the Enron corpus
2011
-
[27]
Guerra, Pedro Calais and Meira, Wagner and Cardie, Claire. 2014. Sentiment analysis on evolving social streams: how self-report imbalances can help. Pro- ceedings of the 7th ACM International Conference on Web Search and Data Mining. https://doi.org/10.1145/2556195.2556261
-
[28]
Deng, Zheye and Chan, Chunkit and Wang, Weiqi and Sun, Yuxi and Fan, Wei and Zheng, Tianshi and Yim, Yauwai and Song, Yangqiu. 2024. Text-Tuple-Table: Towards Information Integration in Text-to-Table Generation via Global Tuple Extraction. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. https://doi.org/10.18653/v1/2...
-
[29]
Jochen Hartmann and Mark Heitmann and Christian Siebert and Christina Schamp. 2023. More than a Feeling: Accuracy and Application of Sentiment Analysis. International Journal of Research in Marketing. https://doi.org/https: //doi.org/10.1016/j.ijresmar.2022.05.005
-
[30]
Brown, Penelope and Levinson, Stephen C.. 1987. Politeness: Some Universals in Language Usage. Cambridge University Press
1987
-
[31]
Aithal, Madhusudhan and Tan, Chenhao. 2021. On Positivity Bias in Negative Reviews. Proceedings of the 59th Annual Meeting of the Association for Compu- tational Linguistics and the 11th International Joint Conference on Natural Lan- guage Processing (Volume 2: Short Papers). https://doi.org/10.18653/v1/2021.acl- short.39
-
[32]
Culpeper, Jonathan. 2011. Impoliteness: Using Language to Cause Offence. Cam- bridge University Press
2011
-
[33]
Tom B. Brown and Benjamin Mann and Nick Ryder and Melanie Subbiah and Jared Kaplan and Prafulla Dhariwal and Arvind Neelakantan and Pranav Shyam and Girish Sastry and Amanda Askell and Sandhini Agarwal and Ariel Herbert-Voss and Gretchen Krueger and Tom Henighan and Rewon Child and Aditya Ramesh and Daniel M. Ziegler and Jeffrey Wu and Clemens Winter and ...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[34]
Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell
Bender, Emily M. and Gebru, Timnit and McMillan-Major, Angelina and Shmitchell, Shmargaret. 2021. On the Dangers of Stochastic Parrots: Can Lan- guage Models Be Too Big?. Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency. https://doi.org/10.1145/3442188.3445922
- [35]
-
[36]
Han, Xudong and Baldwin, Timothy and Cohn, Trevor. 2022. Balancing out Bias: Achieving Fairness Through Balanced Training. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. https://doi. org/10.18653/v1/2022.emnlp-main.779. HEAL@CHI ’26, April 13–17, 2026, Barcelona, Spain Hyojeong Yu, Hyukhun Koh, Minsung Kim, and Kyo...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.