FedSmoothLoRA: Toward Smoother and Faster Convergence in Federated Low-Rank Adaptation
Pith reviewed 2026-06-29 08:06 UTC · model grok-4.3
The pith
FedSmoothLoRA builds each round's local LoRA start from a round-matching matrix and a gradient-aligned matrix to fix state mismatch and client-agnostic initialization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
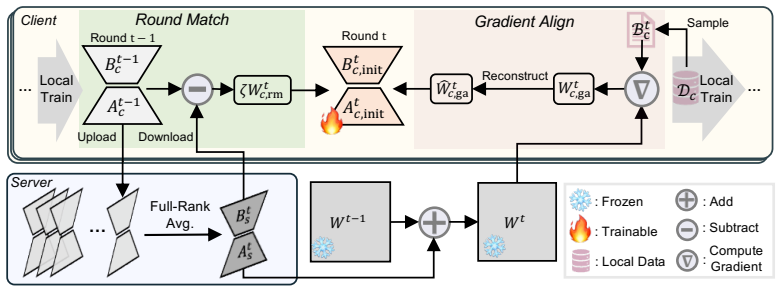
At each communication round, FedSmoothLoRA constructs the local LoRA initialization using a Round-Matching matrix that preserves cross-round local state continuity and a Gradient-Aligned matrix that provides client-specific optimization guidance from gradient signals estimated on local data, enabling smoother and faster convergence while preserving the enlarged update space.
What carries the argument
The Round-Matching matrix together with the Gradient-Aligned matrix that jointly initialize each client's LoRA weights at the beginning of a round.
If this is right
- The enlarged update space obtained by merging LoRA into the backbone is preserved across rounds.
- Cross-round local optimization continuity is restored by carrying client state forward.
- Local training begins from a client-aware state that accelerates convergence on heterogeneous data.
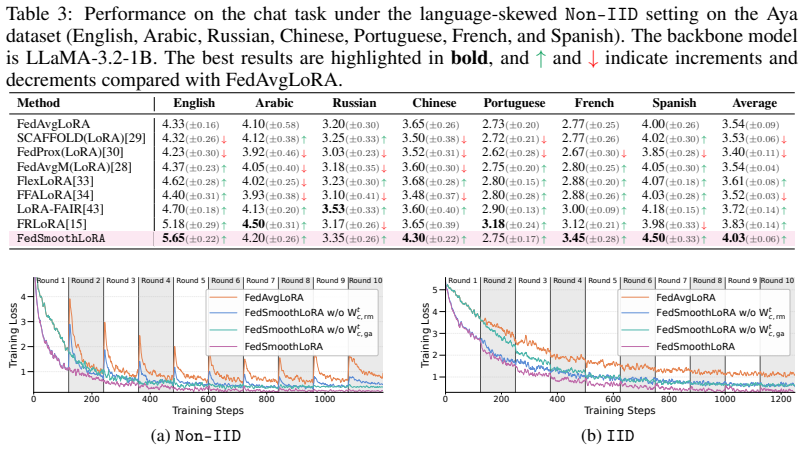
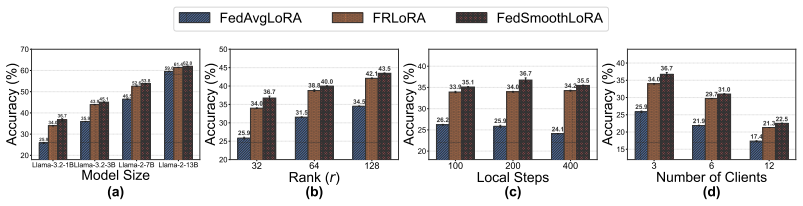
- The approach yields higher accuracy than existing federated LoRA methods on image classification and natural language generation tasks.
Where Pith is reading between the lines
- The same continuity and client-guidance construction could be applied to other parameter-efficient adapters that merge updates into a shared backbone.
- Client-specific gradient alignment may reduce the performance penalty caused by non-IID data distributions more generally in federated optimization.
- Enforcing round-to-round state matching might lower the total number of communication rounds needed to reach target accuracy.
Load-bearing premise
The round-matching and gradient-aligned matrices resolve inter-round state mismatch and client-agnostic starting state without introducing offsetting drawbacks or requiring extra communication.
What would settle it
An ablation study in which either the round-matching or gradient-aligned matrix is replaced by a standard global or random initialization, with the result that convergence speed or final accuracy falls to or below the level of prior federated LoRA baselines on the same image-classification and generation benchmarks.
Figures

read the original abstract
Federated fine-tuning of foundation models with Low-Rank Adaptation (LoRA) provides an efficient solution for reducing communication and computation costs while preserving data locality. However, the direct combination of FedAvg and LoRA suffers from three key issues: limited update space, which restricts the model's effective learning capacity; inter-round state mismatch, which disrupts cross-round local optimization continuity; and a client-agnostic starting state, which slows local convergence on clients. Although recent methods mitigate the limited update space issue by merging LoRA updates into the backbone across communication rounds, inter-round state mismatch and the client-agnostic starting state remain insufficiently addressed. To address these issues, we propose FedSmoothLoRA, a federated LoRA tuning framework that preserves the enlarged update space, improves cross-round local optimization continuity, and provides a client-aware starting state for local training. At each communication round, FedSmoothLoRA constructs the local LoRA initialization using two matrices: a Round-Matching matrix that preserves cross-round local state continuity, and a Gradient-Aligned matrix that provides client-specific optimization guidance from gradient signals estimated on local data. Together, these designs enable smoother and faster convergence. Extensive experiments on image classification and natural language generation tasks demonstrate that FedSmoothLoRA consistently outperforms existing federated LoRA tuning methods. Code: https://github.com/wangzehao0704/FedSmoothLoRA
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes FedSmoothLoRA, a federated LoRA tuning framework for efficient fine-tuning of foundation models. It identifies three issues with direct FedAvg+LoRA combination: limited update space, inter-round state mismatch disrupting local optimization continuity, and client-agnostic starting states slowing convergence. The method constructs local LoRA initialization at each round using a Round-Matching matrix (for cross-round state continuity) and a Gradient-Aligned matrix (for client-specific guidance from local gradient signals), while preserving the enlarged update space. Experiments on image classification and natural language generation tasks are reported to show consistent outperformance over existing federated LoRA methods.
Significance. If the Round-Matching and Gradient-Aligned matrices demonstrably resolve the identified mismatches without extra communication overhead or offsetting costs, the work could meaningfully improve convergence speed and performance in privacy-preserving federated adaptation of large models. The linked code repository is a positive factor for reproducibility.
major comments (2)
- [Abstract / Method] Abstract and method description: the claim that the two matrices are 'constructed at each round using local data signals' without extra communication is load-bearing for the efficiency premise, yet no protocol details are provided on state sharing, storage of prior-round LoRA parameters, or auxiliary messages beyond standard FedAvg deltas.
- [Experiments] Experiments section: the abstract asserts consistent outperformance on image classification and NLG tasks, but no quantitative results, baselines, datasets, metrics, or ablation studies appear in the provided text, preventing verification of the central empirical claim.
minor comments (1)
- [Abstract] Abstract: the phrase 'preserves the enlarged update space' is repeated from prior work but not contrasted quantitatively with the proposed matrices.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address each major comment below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Abstract / Method] Abstract and method description: the claim that the two matrices are 'constructed at each round using local data signals' without extra communication is load-bearing for the efficiency premise, yet no protocol details are provided on state sharing, storage of prior-round LoRA parameters, or auxiliary messages beyond standard FedAvg deltas.
Authors: The Round-Matching matrix reuses the client's locally stored LoRA parameters from the immediately preceding round to enforce continuity, while the Gradient-Aligned matrix is computed exclusively from gradients evaluated on the client's private data. Both operations occur entirely on the client; the server receives only the standard FedAvg LoRA delta. No auxiliary messages or shared state are transmitted. We agree that the current description is insufficiently explicit and will add a dedicated protocol subsection with pseudocode and a diagram in the revised method section. revision: yes
-
Referee: [Experiments] Experiments section: the abstract asserts consistent outperformance on image classification and NLG tasks, but no quantitative results, baselines, datasets, metrics, or ablation studies appear in the provided text, preventing verification of the central empirical claim.
Authors: The complete manuscript contains Section 4 with quantitative results on image classification (CIFAR-10/100) and NLG (E2E) tasks, reporting accuracy, perplexity/BLEU, comparisons against FedAvg+LoRA and recent federated LoRA baselines, and ablations isolating the Round-Matching and Gradient-Aligned components. The excerpt supplied to the referee appears to have been limited to the abstract. We will ensure the experimental section is fully visible and, if requested, expand the tables with additional metrics. revision: partial
Circularity Check
No circularity; empirical claims rest on experiments, not self-referential definitions
full rationale
The paper introduces FedSmoothLoRA via algorithmic construction of Round-Matching and Gradient-Aligned matrices from local signals, then validates via experiments on classification and generation tasks. No equations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The derivation chain consists of design choices justified by stated problems (limited update space, inter-round mismatch, client-agnostic init) and resolved by the proposed matrices, with performance claims externally falsifiable through the linked code and benchmarks. This is self-contained against external results.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Round-Matching matrix
no independent evidence
-
Gradient-Aligned matrix
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PMLR, 2021
2021
-
[2]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timo- thée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Visual instruction tuning.Ad- vances in neural information processing systems, 36, 2024
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Ad- vances in neural information processing systems, 36, 2024
2024
-
[6]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Openfedllm: Training large language models on decentralized private data via federated learning
Rui Ye, Wenhao Wang, Jingyi Chai, Dihan Li, Zexi Li, Yinda Xu, Yaxin Du, Yanfeng Wang, and Siheng Chen. Openfedllm: Training large language models on decentralized private data via federated learning. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 6137–6147, 2024
2024
-
[9]
Communication-efficient learning of deep networks from decentralized data
Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Ar- cas. Communication-efficient learning of deep networks from decentralized data. InArtificial intelligence and statistics, pages 1273–1282. PMLR, 2017
2017
-
[10]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models.arXiv preprint arXiv:2106.09685, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
Towards building the federatedgpt: Federated instruction tuning
Jianyi Zhang, Saeed Vahidian, Martin Kuo, Chunyuan Li, Ruiyi Zhang, Tong Yu, Guoyin Wang, and Yiran Chen. Towards building the federatedgpt: Federated instruction tuning. In ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Process- ing (ICASSP), pages 6915–6919. IEEE, 2024
2024
-
[12]
Fedpetuning: When federated learning meets the parameter-efficient tuning methods of pre- trained language models
Zhuo Zhang, Yuanhang Yang, Yong Dai, Qifan Wang, Yue Yu, Lizhen Qu, and Zenglin Xu. Fedpetuning: When federated learning meets the parameter-efficient tuning methods of pre- trained language models. InAnnual Meeting of the Association of Computational Linguistics 2023, pages 9963–9977. Association for Computational Linguistics (ACL), 2023
2023
-
[13]
Federatedscope-llm: A comprehensive package for fine-tuning large language models in federated learning
Weirui Kuang, Bingchen Qian, Zitao Li, Daoyuan Chen, Dawei Gao, Xuchen Pan, Yuexiang Xie, Yaliang Li, Bolin Ding, and Jingren Zhou. Federatedscope-llm: A comprehensive package for fine-tuning large language models in federated learning. InProceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 5260–5271, 2024
2024
-
[14]
Tao Fan, Yan Kang, Guoqiang Ma, Weijing Chen, Wenbin Wei, Lixin Fan, and Qiang Yang. Fate-llm: A industrial grade federated learning framework for large language models.arXiv preprint arXiv:2310.10049, 2023
-
[15]
Federated residual low-rank adaptation of large language models
Yunlu Yan, Chun-Mei Feng, Wangmeng Zuo, Rick Siow Mong Goh, Yong Liu, and Lei Zhu. Federated residual low-rank adaptation of large language models. InThe Thirteenth Interna- tional Conference on Learning Representations, 2025. 10
2025
-
[16]
Lora-ga: Low-rank adaptation with gradient approxi- mation.arXiv preprint arXiv:2407.05000, 2024
Shaowen Wang, Linxi Yu, and Jian Li. Lora-ga: Low-rank adaptation with gradient approxi- mation.arXiv preprint arXiv:2407.05000, 2024
-
[17]
Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey
Zeyu Han, Chao Gao, Jinyang Liu, Jeff Zhang, and Sai Qian Zhang. Parameter-efficient fine- tuning for large models: A comprehensive survey.arXiv preprint arXiv:2403.14608, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Elad Ben Zaken, Shauli Ravfogel, and Yoav Goldberg. Bitfit: Simple parameter-efficient fine-tuning for transformer-based masked language-models.arXiv preprint arXiv:2106.10199, 2021
-
[19]
Adaptformer: Adapting vision transformers for scalable visual recognition.Advances in Neural Information Processing Systems, 35:16664–16678, 2022
Shoufa Chen, Chongjian Ge, Zhan Tong, Jiangliu Wang, Yibing Song, Jue Wang, and Ping Luo. Adaptformer: Adapting vision transformers for scalable visual recognition.Advances in Neural Information Processing Systems, 35:16664–16678, 2022
2022
-
[20]
Parameter-efficient transfer learning for nlp
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for nlp. InInternational conference on machine learning, pages 2790–2799. PMLR, 2019
2019
-
[21]
How to adapt your large- scale vision-and-language model.openreview preprint, 2021
Konwoo Kim, Michael Laskin, Igor Mordatch, and Deepak Pathak. How to adapt your large- scale vision-and-language model.openreview preprint, 2021
2021
-
[22]
AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning
Qingru Zhang, Minshuo Chen, Alexander Bukharin, Nikos Karampatziakis, Pengcheng He, Yu Cheng, Weizhu Chen, and Tuo Zhao. Adalora: Adaptive budget allocation for parameter- efficient fine-tuning.arXiv preprint arXiv:2303.10512, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Relora: High- rank training through low-rank updates
Vladislav Lialin, Sherin Muckatira, Namrata Shivagunde, and Anna Rumshisky. Relora: High- rank training through low-rank updates. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[24]
A Rank Stabilization Scaling Factor for Fine-Tuning with LoRA
Damjan Kalajdzievski. A rank stabilization scaling factor for fine-tuning with lora.arXiv preprint arXiv:2312.03732, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
DoRA: Weight-Decomposed Low-Rank Adaptation
Shih-Yang Liu, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu-Chiang Frank Wang, Kwang-Ting Cheng, and Min-Hung Chen. Dora: Weight-decomposed low-rank adaptation. arXiv preprint arXiv:2402.09353, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Fanxu Meng, Zhaohui Wang, and Muhan Zhang. Pissa: Principal singular values and singular vectors adaptation of large language models.arXiv preprint arXiv:2404.02948, 2024
-
[27]
Lora-pro: Are low-rank adapters properly optimized?arXiv preprint arXiv:2407.18242, 2024
Zhengbo Wang, Jian Liang, Ran He, Zilei Wang, and Tieniu Tan. Lora-pro: Are low-rank adapters properly optimized?arXiv preprint arXiv:2407.18242, 2024
-
[28]
Measuring the Effects of Non-Identical Data Distribution for Federated Visual Classification
Tzu-Ming Harry Hsu, Hang Qi, and Matthew Brown. Measuring the effects of non-identical data distribution for federated visual classification.arXiv preprint arXiv:1909.06335, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[29]
Scaffold: Stochastic controlled averaging for federated learning
Sai Praneeth Karimireddy, Satyen Kale, Mehryar Mohri, Sashank Reddi, Sebastian Stich, and Ananda Theertha Suresh. Scaffold: Stochastic controlled averaging for federated learning. In International conference on machine learning, pages 5132–5143. PMLR, 2020
2020
-
[30]
Federated optimization in heterogeneous networks.Proceedings of Machine learning and systems, 2:429–450, 2020
Tian Li, Anit Kumar Sahu, Manzil Zaheer, Maziar Sanjabi, Ameet Talwalkar, and Virginia Smith. Federated optimization in heterogeneous networks.Proceedings of Machine learning and systems, 2:429–450, 2020
2020
-
[31]
Adaptive Federated Optimization
Sashank Reddi, Zachary Charles, Manzil Zaheer, Zachary Garrett, Keith Rush, Jakub Koneˇcn`y, Sanjiv Kumar, and H Brendan McMahan. Adaptive federated optimization.arXiv preprint arXiv:2003.00295, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2003
-
[32]
Fedra: A random allocation strategy for federated tuning to unleash the power of heterogeneous clients
Shangchao Su, Bin Li, and Xiangyang Xue. Fedra: A random allocation strategy for federated tuning to unleash the power of heterogeneous clients. InEuropean Conference on Computer Vision, pages 342–358. Springer, 2025
2025
-
[33]
Federated fine-tuning of large language models under heterogeneous tasks and client resources
Jiamu Bai, Daoyuan Chen, Bingchen Qian, Liuyi Yao, and Yaliang Li. Federated fine-tuning of large language models under heterogeneous tasks and client resources. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. 11
2024
-
[34]
Improving lora in privacy-preserving federated learning.arXiv preprint arXiv:2403.12313, 2024
Youbang Sun, Zitao Li, Yaliang Li, and Bolin Ding. Improving lora in privacy-preserving federated learning.arXiv preprint arXiv:2403.12313, 2024
-
[35]
Flora: Federated fine-tuning large language models with heterogeneous low-rank adaptations
Ziyao Wang, Zheyu Shen, Yexiao He, Guoheng Sun, Hongyi Wang, Lingjuan Lyu, and Ang Li. Flora: Federated fine-tuning large language models with heterogeneous low-rank adaptations. Advances in Neural Information Processing Systems, 37:22513–22533, 2024
2024
-
[36]
Fedex-lora: Exact aggregation for federated and efficient fine-tuning of large language models
Raghav Singhal, Kaustubh Ponkshe, and Praneeth Vepakomma. Fedex-lora: Exact aggregation for federated and efficient fine-tuning of large language models. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1316–1336, 2025
2025
-
[37]
Sara Babakniya, Ahmed Roushdy Elkordy, Yahya H Ezzeldin, Qingfeng Liu, Kee-Bong Song, Mostafa El-Khamy, and Salman Avestimehr. Slora: Federated parameter efficient fine-tuning of language models.arXiv preprint arXiv:2308.06522, 2023
-
[38]
Yuxuan Yan, Qianqian Yang, Shunpu Tang, and Zhiguo Shi. Federa: Efficient fine-tuning of language models in federated learning leveraging weight decomposition.arXiv preprint arXiv:2404.18848, 2024
-
[39]
Hongyi Peng, Han Yu, Xiaoxiao Li, and Qiang Yang. Rethinking lora for data heterogeneous federated learning: Subspace and state alignment.arXiv preprint arXiv:2602.01746, 2026
-
[40]
Federated Sketching LoRA: A Flexible Framework for Heterogeneous Collaborative Fine-Tuning of LLMs
Wenzhi Fang, Dong-Jun Han, Liangqi Yuan, Seyyedali Hosseinalipour, and Christopher G Brinton. Federated sketching lora: On-device collaborative fine-tuning of large language mod- els.arXiv preprint arXiv:2501.19389, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Zur theorie der linearen und nichtlinearen integralgleichungen.Mathematis- che Annalen, 63(4):433–476, 1907
Erhard Schmidt. Zur theorie der linearen und nichtlinearen integralgleichungen.Mathematis- che Annalen, 63(4):433–476, 1907
1907
-
[42]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy Alexey. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv: 2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[43]
Lora-fair: Federated lora fine-tuning with aggregation and initialization refinement
Jieming Bian, Lei Wang, Letian Zhang, and Jie Xu. Lora-fair: Federated lora fine-tuning with aggregation and initialization refinement. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 3737–3746, 2025
2025
-
[44]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models
Longhui Yu, Weisen Jiang, Han Shi, Jincheng Yu, Zhengying Liu, Yu Zhang, James T Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu. Metamath: Bootstrap your own mathematical questions for large language models.arXiv preprint arXiv:2309.12284, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[46]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[47]
Tianyu Zheng, Ge Zhang, Tianhao Shen, Xueling Liu, Bill Yuchen Lin, Jie Fu, Wenhu Chen, and Xiang Yue. Opencodeinterpreter: Integrating code generation with execution and refine- ment.arXiv preprint arXiv:2402.14658, 2024
-
[48]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[49]
Aya dataset: An open-access collection for multilingual instruction tuning
Shivalika Singh, Freddie Vargus, Daniel D’souza, Börje F Karlsson, Abinaya Mahendiran, Wei-Yin Ko, Herumb Shandilya, Jay Patel, Deividas Mataciunas, Laura O’Mahony, et al. Aya dataset: An open-access collection for multilingual instruction tuning. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pa-...
2024
-
[50]
Limitations
Nathan Halko, Per-Gunnar Martinsson, and Joel A Tropp. Finding structure with randomness: Probabilistic algorithms for constructing approximate matrix decompositions.SIAM review, 53(2):217–288, 2011. 12 This appendix provides additional details and analyses for FedSmoothLoRA. It includes: • Detailed experimental settings, provided in Section A. • Addition...
2011
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.