Opt-Verifier: Unleashing the Power of LLMs for Optimization Modeling via Dual-Side Verification
Pith reviewed 2026-06-29 07:04 UTC · model grok-4.3
The pith
Adding structure-side and solution-side verification to LLMs raises optimization modeling accuracy by more than 20 percent on benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
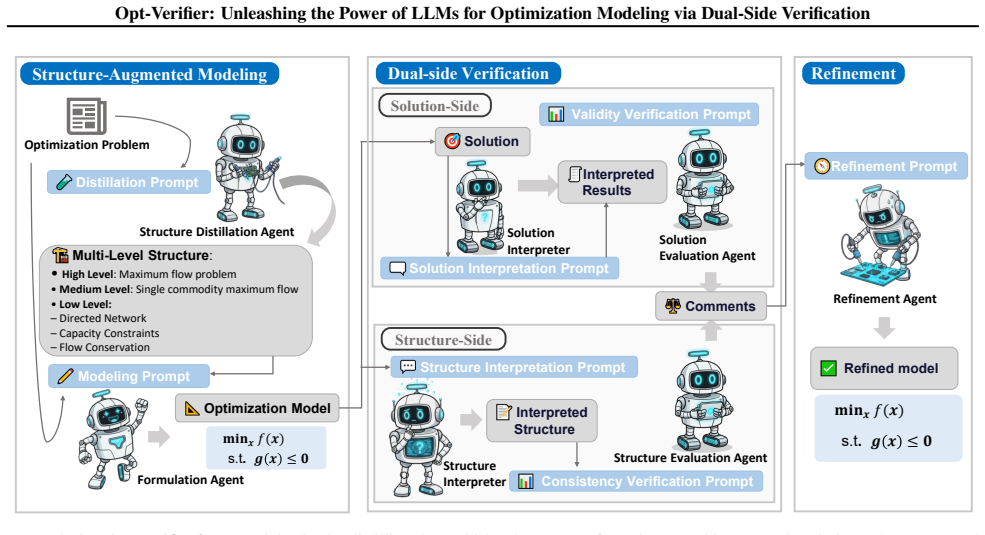
The authors claim that dual-side verification, performed after an LLM produces an optimization model, corrects errors that single-pass generation misses. Structure-side verification confirms that the model structure matches the problem description; solution-side verification confirms that feasible and optimal solutions exist and satisfy the stated constraints. Experiments on popular benchmarks show this combined verification yields more than 20 percent higher modeling accuracy than prior LLM methods.
What carries the argument
Dual-side verification consisting of a structure-side verifier that aligns model elements with the problem description and a solution-side verifier that evaluates solution validity.
If this is right
- Verification steps allow the LLM to iterate and correct the model rather than accepting the first output.
- Both structure alignment and solution validity must hold before a model is considered usable.
- The approach separates the generation step from the checking step, making each easier to improve independently.
- Accuracy gains appear on standard OR benchmarks that test constraint capture and solution correctness.
Where Pith is reading between the lines
- The same dual-check pattern could be applied to LLM generation of other formal artifacts such as scheduling programs or simulation scripts.
- Feeding solver output back into the solution-side verifier creates a closed loop that might further reduce undetected infeasibilities.
- If the verifiers themselves are implemented with smaller specialized models, the overall system cost could drop while keeping the accuracy benefit.
Load-bearing premise
The two verifiers detect modeling errors reliably without systematically missing certain classes of mistakes or introducing false positives that hurt overall performance.
What would settle it
Running the method on a benchmark where a common modeling error such as an omitted non-negativity constraint is repeatedly missed by both verifiers would show the accuracy gain disappears.
Figures


read the original abstract
Building mathematical optimization models is critical in operations research (OR), while it requires substantial human expertise. Recent advancements have utilized large language models (LLMs) to automate this modeling process. However, existing works often struggle to verify the correctness of the generated optimization models, without checking the rationality of the constraints and variables or the validity of solutions to the generated models. This hampers the subsequent verification and correction steps, and thus it severely hurts the modeling accuracy. To address this challenge, we propose a novel LLM-based framework with Dual-side Verification (Opt-Verifier) from both structure and solution perspectives, thereby improving the modeling accuracy. The structure-side verification ensures that the modeling structure of the generated optimization models aligns with the original problem description, accurately capturing the problem's constraints and requirements. Meanwhile, the solution-side verification interprets and evaluates the solutions' validity, confirming that the optimization models are logically and mathematically sound. Experiments on popular benchmarks demonstrate that our approach achieves over 20\% improvement in accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Opt-Verifier, an LLM-based framework for automating mathematical optimization model construction in operations research. It introduces dual-side verification consisting of a structure-side verifier that checks alignment between the generated model and the original problem description (constraints and variables) and a solution-side verifier that interprets and validates the solutions produced by the model. The central claim is that this framework yields over 20% accuracy improvement on popular benchmarks relative to prior LLM-based modeling approaches.
Significance. If the reported accuracy gains prove robust under controlled evaluation, the dual-verification design could meaningfully improve the reliability of LLM-generated optimization models and reduce downstream correction effort in OR applications. The work is presented as an empirical framework whose value rests on benchmark performance rather than parameter-free derivations or machine-checked proofs.
major comments (2)
- [Experimental Evaluation] Experimental Evaluation: the abstract asserts a 20% accuracy gain but supplies no information on baselines, dataset splits, statistical significance, or how verification failures are counted; without these details the central empirical claim cannot be evaluated.
- [Method and Experiments] Method and Experiments: no quantitative validation (precision/recall) or ablation isolating the contribution of the structure-side versus solution-side verifiers is reported, leaving open whether the verifiers systematically miss error classes or introduce false positives that degrade overall performance.
minor comments (1)
- [Abstract] Abstract: the benchmarks and exact accuracy metric (e.g., model correctness rate, solution feasibility) are not named, which would aid immediate assessment of the claimed improvement.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below with clarifications drawn from the full paper and indicate planned revisions where appropriate.
read point-by-point responses
-
Referee: [Experimental Evaluation] Experimental Evaluation: the abstract asserts a 20% accuracy gain but supplies no information on baselines, dataset splits, statistical significance, or how verification failures are counted; without these details the central empirical claim cannot be evaluated.
Authors: The abstract is intentionally concise, but the full manuscript (Experiments section) specifies the baselines (direct LLM prompting, Chain-of-Thought, and prior LLM modeling methods), the standard benchmark datasets with their train/test splits, statistical significance assessed via 5 independent runs with mean and standard deviation reported, and verification failures counted as incorrect models in the accuracy metric. We will revise the abstract to include a brief clause referencing these evaluation details for improved self-containment. revision: yes
-
Referee: [Method and Experiments] Method and Experiments: no quantitative validation (precision/recall) or ablation isolating the contribution of the structure-side versus solution-side verifiers is reported, leaving open whether the verifiers systematically miss error classes or introduce false positives that degrade overall performance.
Authors: We agree that the current version lacks explicit precision/recall metrics for the individual verifiers and an ablation study. In the revision we will add a new subsection reporting precision and recall for both verifiers on annotated error cases, together with an ablation comparing the full dual-verifier framework against structure-only and solution-only variants, including analysis of false-positive rates and missed error classes. revision: yes
Circularity Check
No significant circularity; empirical framework evaluated on external benchmarks
full rationale
The paper presents an LLM-based framework (Opt-Verifier) with dual-side verification for optimization modeling. Its central claim is an empirical accuracy improvement (>20%) on popular benchmarks. No equations, derivations, fitted parameters, or self-citation chains are described in the provided text that reduce any result to its own inputs by construction. The structure-side and solution-side verifiers are defined as mechanisms whose performance is measured externally rather than derived tautologically. This is the most common honest finding for applied empirical work without internal mathematical claims.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Large language models can be prompted to produce syntactically valid optimization models from natural-language problem statements.
- domain assumption Existing optimization benchmarks contain well-defined ground-truth models against which generated models can be compared.
Reference graph
Works this paper leans on
-
[1]
URL https://www.sciencedirect.com/ science/article/pii/S1755581710000131
doi: https://doi.org/10.1016/j.cirpj.2010.03.006. URL https://www.sciencedirect.com/ science/article/pii/S1755581710000131. Sustainable Development of Manufacturing Systems. Yin, Y . Multiobjective bilevel optimization for trans- portation planning and management problems.Journal of Advanced Transportation, 36(1):93–105, 2002. doi: https://doi.org/10.1002...
-
[2]
URL https://proceedings.mlr.press/ v235/ahmaditeshnizi24a.html. OpenAI. GPT-4 technical report.CoRR, abs/2303.08774, 2023. OpenAI. Gpt-4o system card, 2024. URL https:// arxiv.org/abs/2410.21276. Xiao, Z., Zhang, D., Wu, Y ., Xu, L., Wang, Y . J., Han, X., Fu, X., Zhong, T., Zeng, J., Song, M., and Chen, G. Chain-of-experts: When LLMs meet complex operati...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1287/opre.2024.1233 2023
-
[3]
findings-emnlp.691/
URL https://aclanthology.org/2025. findings-emnlp.691/. Jiang, C., Shu, X., Qian, H., Lu, X., Zhou, J., Zhou, A., and Yu, Y . LLMOPT: Learning to define and solve general optimization problems from scratch. InThe Thirteenth International Conference on Learning Representations,
2025
-
[4]
Chen, Y ., Xia, J., Shao, S., Ge, D., and Ye, Y
URL https://openreview.net/forum? id=9OMvtboTJg. Chen, Y ., Xia, J., Shao, S., Ge, D., and Ye, Y . Solver- informed RL: Grounding large language models for authentic optimization modeling. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https://openreview.net/ forum?id=80L235oVBe. Lu, H., Xie, Z., Wu, Y ., Ren, C.,...
2026
-
[5]
URL https://openreview.net/forum? id=mFY0tPDWK8. Chen, H., Constante-Flores, G. E., and Li, C. Diagnosing in- feasible optimization problems using large language mod- els, 2023. URL https://arxiv.org/abs/2308. 12923. Li, B., Mellou, K., Zhang, B., Pathuri, J., and Menache, I. Large language models for supply chain optimiza- tion, 2023. URL https://arxiv.o...
-
[6]
Wang, Z., Zhu, Z., Han, Y ., Lin, Y ., Lin, Z., Sun, R., and Ding, T
URL https://openreview.net/forum? id=fsDZwS49uY. Wang, Z., Zhu, Z., Han, Y ., Lin, Y ., Lin, Z., Sun, R., and Ding, T. Optibench: Benchmarking large language mod- els in optimization modeling with equivalence-detection evaluation, 2024. URL https://openreview. net/forum?id=KD9F5Ap878. Mao, W., Liu, H., Tan, H., Shi, Y ., Wu, J., Zhang, A., and Wang, X. Jo...
2024
-
[7]
URL https://openreview.net/forum? id=IdF6JqXWzx. Zhang, K., Tian, K., Liu, R., Zeng, S., Zhu, X., Jia, G., Fan, Y ., Lv, X., Zuo, Y ., Jiang, C., wang, Y ., Wang, J., Hua, E., Long, X., Gao, J., Sun, Y ., Ma, Z., Cui, G., Ding, N., Qi, B., and Zhou, B. MARTI: A framework for multi- agent LLM systems reinforced training and inference. In The Fourteenth Int...
-
[8]
URL https://proceedings.neurips. cc/paper_files/paper/2016/file/ 5b69b9cb83065d403869739ae7f0995e-Paper. pdf. Wei, J., Wang, X., Schuurmans, D., Bosma, M., ichter, b., Xia, F., Chi, E., Le, Q. V ., and Zhou, D. Chain-of-thought prompting elicits reasoning in large language models. In Advances in Neural Information Processing Systems 35, pp. 24824–24837, N...
-
[9]
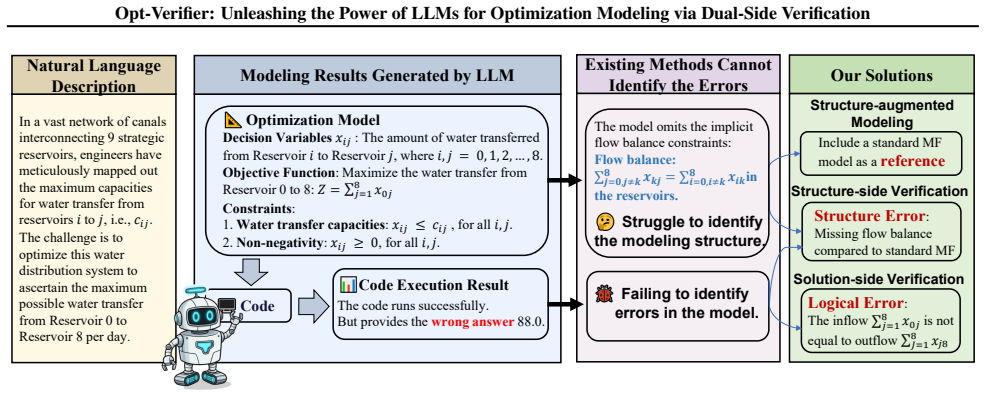
Water transfer capacities:x ij ≤c ij, for alli, j
-
[10]
This model is incorrect due to missing flow balance constraints
Non-negativity:x ij ≥0, for alli, j. This model is incorrect due to missing flow balance constraints. The verification process is outlined as follows: • Structure-Augmented Modeling:The model references a maximum flow problem. It correctly formulates the flow balance constraint when recalling the standard model. • Structure-Side Verification:The model int...
-
[11]
Directed Network: The flow is directed from one reservoir to another
-
[12]
Capacity Constraints: Each edge has a maximum capacity
-
[13]
•Decision Variables:x ij: The amount of water transferred from Reservoirito Reservoirj
Flow Conservation: The amount of water entering any intermediate reservoir must equal the amount leaving. •Decision Variables:x ij: The amount of water transferred from Reservoirito Reservoirj. •Objective Function:Maximize the water transfer: Z= 8X j=1 x0j •Constraints: 1.x ij ≤c ij, for alli, j. 2.x ij ≥0, for alli, j
-
[14]
"" 3You are a mathematical formulator working with a team of optimization experts. The ,→objective is to tackle a complex optimization problem. 4
Flow Conservation: P8 j=0 j̸=k xkj =P8 i=0 i̸=k xik forkin the reservoirs AnalysisThe modeling structures are proposed to address the challenges of missing constraints. The core of structure- augmented modeling is to identify a similar standard optimization model, and identify the implicit constraints using the standard optimization model as a reference. ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.