On the Construction and Implications of Low-Loss Valleys in LoRA-based Bayesian Inference
Pith reviewed 2026-06-29 08:33 UTC · model grok-4.3
The pith
Anchored multi-segment Bézier curves connect independent LoRA optima through continuous low-loss valleys, raising predictive mutual information.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
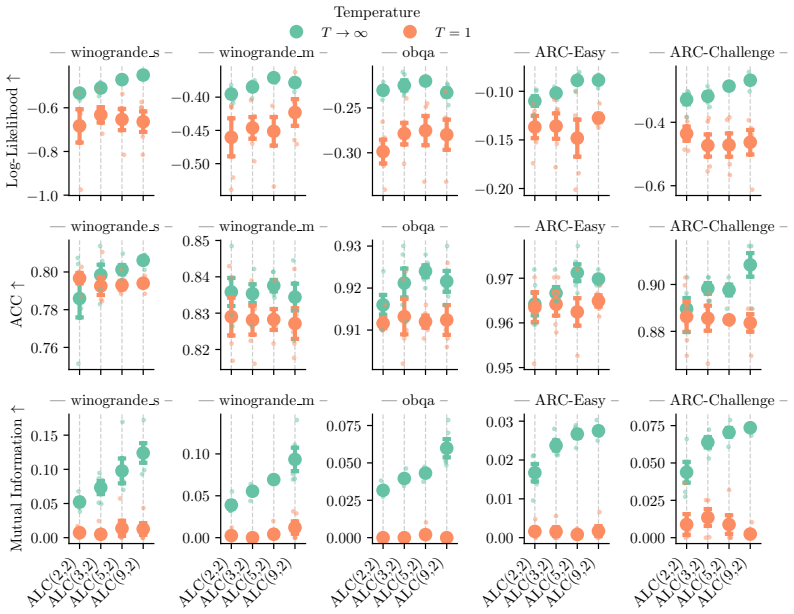
Anchored multi-segment curves connect independent optima through continuous low-loss valleys. Combined with flat-minima perturbations and a Jensen-Shannon divergence regularizer, LoRA-Curve yields measurably higher mutual information of the predictive distribution without sacrificing performance, and links continuous parameter-space traversal to functional diversity.
What carries the argument
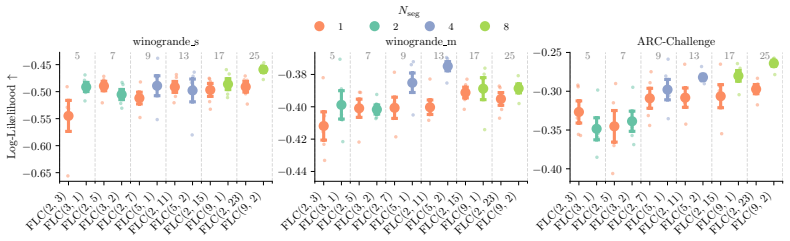
Anchored segmented Bézier curve parameterization in LoRA space that connects independently fine-tuned optima with pathwise continuity and Lipschitz regularity of the loss.
If this is right
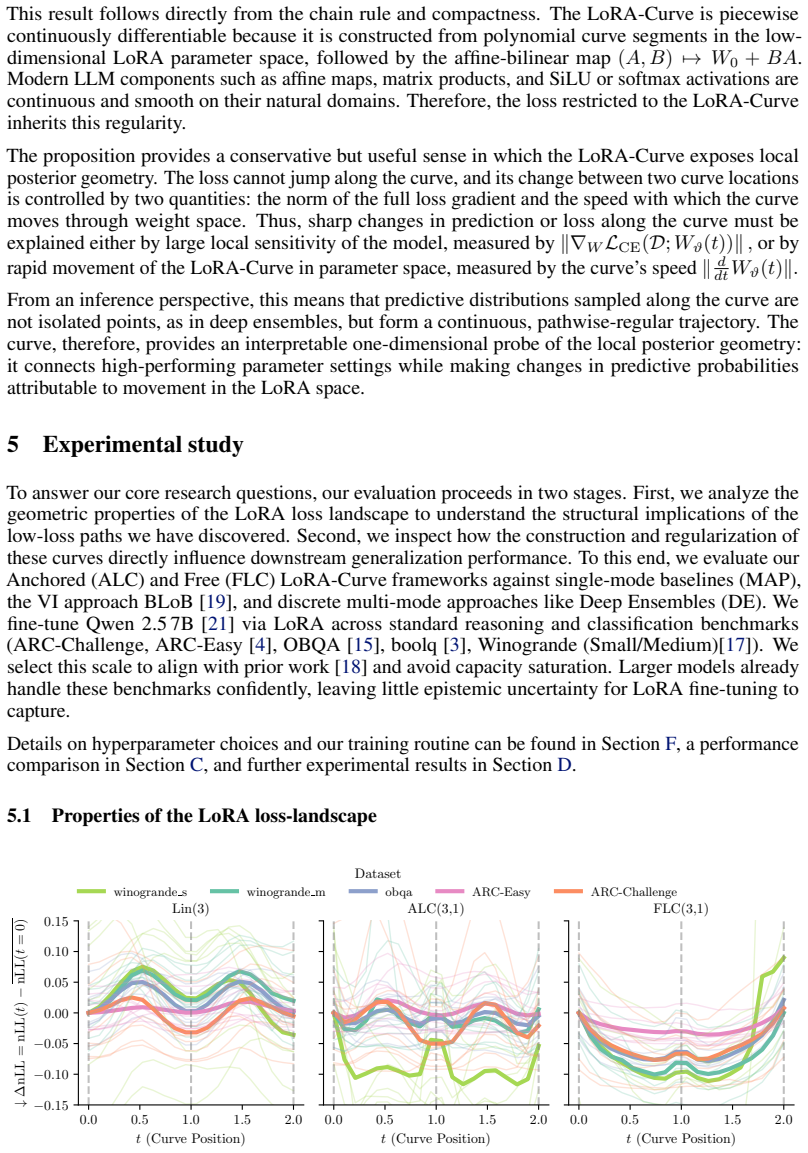
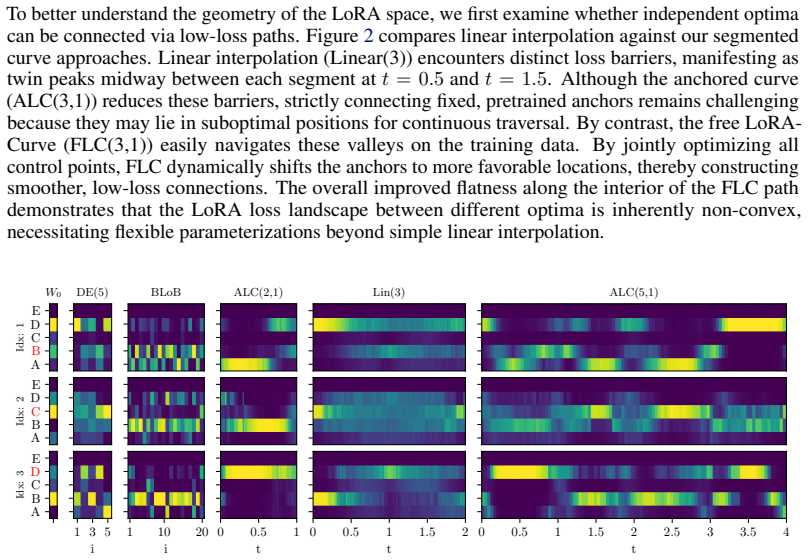
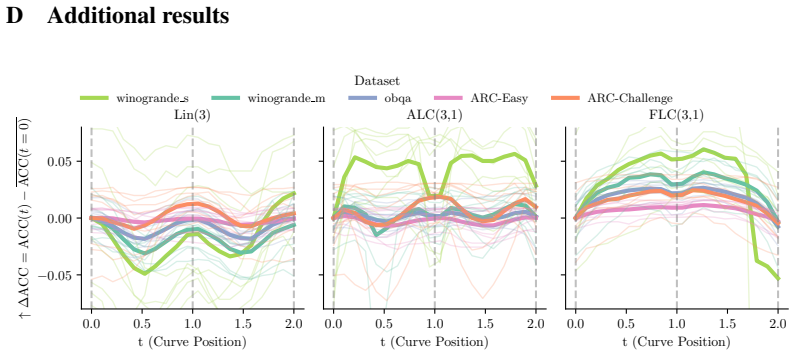
- Linear interpolation between independent LoRA optima encounters loss barriers.
- Anchored multi-segment curves avoid these barriers and connect the optima continuously.
- The method produces higher mutual information in the predictive distribution.
- Performance on reasoning and classification benchmarks is maintained.
- Continuous traversal in parameter space corresponds to functional diversity in predictions.
Where Pith is reading between the lines
- This suggests similar low-loss structures may exist in other parameter-efficient fine-tuning methods.
- The increased mutual information could lead to improved uncertainty calibration on downstream tasks.
- Testing the approach on larger models or different tasks would show if the effect scales.
- Comparing the diversity to that from standard deep ensembles could quantify the efficiency gain.
Load-bearing premise
The low-loss valleys captured by the anchored Bézier curves add predictive information beyond what is available from the independent optima or local perturbations alone.
What would settle it
Finding that the mutual information of the predictive distribution does not increase when including points sampled along the low-loss curves compared to using only the endpoint models would falsify the benefit of the continuous traversal.
Figures




read the original abstract
While parameter-efficient fine-tuning methods like low-rank adaptation (LoRA) are standard for large language models, principled estimation of epistemic uncertainty remains challenging. Recent results in the LoRA regime suggest that discrete multi-mode approaches such as deep ensembles offer little benefit over single-mode methods. This contradicts broader observations in deep learning, where ensembling independent optima typically improves generalization, and linking these modes through continuous low-loss valleys further enhances Bayesian model averaging (BMA). Whether such structure exists in the LoRA space and whether it yields functional diversity missed by local or discrete methods has not been studied. We introduce LoRA-Curve, a segmented B\'ezier curve parameterization in the LoRA space, with two variants: a free configuration that jointly optimizes all control points, and an anchored configuration that connects independently fine-tuned LoRA optima. We prove pathwise continuity and Lipschitz regularity of the loss along the curve and empirically show, across reasoning and classification benchmarks with Qwen2.5 7B, that linear interpolation encounters loss barriers, while our anchored multi-segment curves connect independent optima through continuous low-loss valleys. Combined with flat-minima perturbations and a Jensen-Shannon divergence regularizer, LoRA-Curve yields measurably higher mutual information of the predictive distribution without sacrificing performance, and links continuous parameter-space traversal to functional diversity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LoRA-Curve, a segmented Bézier curve parameterization in LoRA space with free and anchored variants. The anchored version connects independently fine-tuned LoRA optima. It proves pathwise continuity and Lipschitz regularity of the loss along the curve. Empirically on Qwen2.5 7B across reasoning and classification benchmarks, linear interpolation encounters loss barriers while anchored multi-segment curves connect optima through continuous low-loss valleys. Combined with flat-minima perturbations and a Jensen-Shannon divergence regularizer, the method yields higher mutual information of the predictive distribution without sacrificing performance, linking continuous parameter-space traversal to functional diversity in LoRA-based Bayesian inference.
Significance. If the claims hold, the work would be significant for epistemic uncertainty estimation under parameter-efficient fine-tuning. It provides a concrete parameterization with theoretical regularity guarantees that enables continuous mode connectivity in LoRA space, where discrete ensembles have previously shown limited benefit. The proofs of continuity and Lipschitz regularity along the paths are a strength, as is the empirical demonstration on a 7B-scale model that ties the low-loss structure to measurable gains in mutual information.
major comments (2)
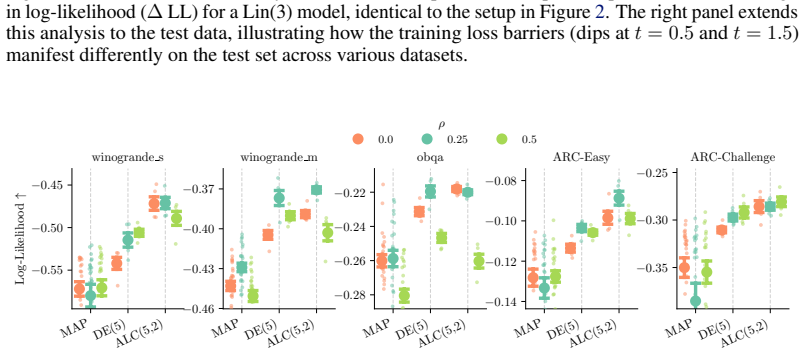
- [Empirical results on Qwen2.5 7B] Empirical results on Qwen2.5 7B: the central claim that anchored multi-segment curves provide functional diversity missed by discrete methods rests on higher mutual information from the full pipeline (curves + perturbations + JS regularizer). No ablation is reported that applies the same JS regularizer to a discrete ensemble of the independent LoRA optima without curve interpolation. This leaves open whether the continuous low-loss valley traversal itself adds predictive information beyond the regularizer.
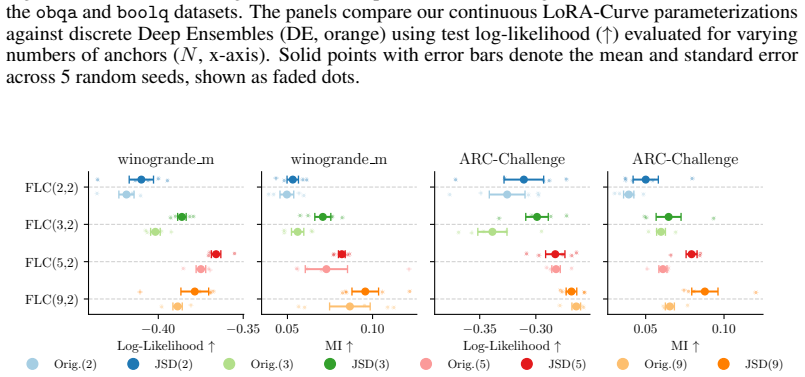
- [Experimental evaluation] Experimental evaluation: reported mutual information gains lack statistical tests, multiple random seeds with error bars, or controls for the number of function evaluations, which weakens the strength of the claim that the method yields measurably higher mutual information.
minor comments (2)
- The abstract and introduction would benefit from an explicit equation defining the anchored Bézier parameterization and the loss along the curve before stating the continuity and Lipschitz results.
- Notation for the Jensen-Shannon regularizer and its weighting relative to the task loss should be introduced with a single equation in the methods to avoid ambiguity when comparing variants.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that strengthen the empirical claims.
read point-by-point responses
-
Referee: [Empirical results on Qwen2.5 7B] Empirical results on Qwen2.5 7B: the central claim that anchored multi-segment curves provide functional diversity missed by discrete methods rests on higher mutual information from the full pipeline (curves + perturbations + JS regularizer). No ablation is reported that applies the same JS regularizer to a discrete ensemble of the independent LoRA optima without curve interpolation. This leaves open whether the continuous low-loss valley traversal itself adds predictive information beyond the regularizer.
Authors: We agree that the requested ablation is required to isolate the contribution of continuous low-loss valley traversal. In the revised manuscript we will add results applying the identical Jensen-Shannon regularizer to a discrete ensemble of the independent LoRA optima (no curve interpolation). This will directly test whether the anchored multi-segment parameterization supplies additional predictive mutual information beyond the regularizer alone. revision: yes
-
Referee: [Experimental evaluation] Experimental evaluation: reported mutual information gains lack statistical tests, multiple random seeds with error bars, or controls for the number of function evaluations, which weakens the strength of the claim that the method yields measurably higher mutual information.
Authors: We acknowledge the absence of these statistical controls in the current version. The revised manuscript will report results over multiple random seeds with error bars, include statistical significance tests (e.g., paired t-tests) on the mutual-information differences, and ensure that all method comparisons are performed under matched numbers of function evaluations. revision: yes
Circularity Check
No significant circularity; derivation self-contained
full rationale
The paper introduces novel constructs (anchored segmented Bézier parameterization in LoRA space, flat-minima perturbations, and JS divergence regularizer) and proves pathwise continuity/Lipschitz regularity of the loss along the curve. The empirical claim of higher mutual information is tied to these new elements plus benchmarks, without any quoted reduction of the central result to a fitted quantity defined by the method itself or to a self-citation chain. The derivation chain therefore remains independent of its own outputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- Bézier control points
axioms (1)
- standard math Pathwise continuity and Lipschitz regularity of the loss along the curve
invented entities (1)
-
LoRA-Curve
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Uncertainty quantification in fine-tuned LLMs using LoRA ensembles
Oleksandr Balabanov and Hampus Linander. Uncertainty quantification in fine-tuned LLMs using LoRA ensembles. InICLR Workshop: Quantify Uncertainty and Hallucination in Foundation Models: The Next Frontier in Reliable AI, 2025
2025
-
[2]
Weight Uncertainty in Neural Network
Charles Blundell, Julien Cornebise, Koray Kavukcuoglu, and Daan Wierstra. Weight Uncertainty in Neural Network. InProceedings of the 32nd International Conference on Machine Learning, pages 1613–1622. PMLR, June 2015
2015
-
[3]
Boolq: Exploring the surprising difficulty of natural yes/no questions
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. Boolq: Exploring the surprising difficulty of natural yes/no questions. InProceedings of the 2019 conference of the north American chapter of the association for computational linguistics: Human language technologies, volume 1 (long and short papers), ...
2019
-
[4]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge.arXiv preprint arXiv:1803.05457, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[5]
Laplace Redux - Effortless Bayesian Deep Learning
Erik Daxberger, Agustinus Kristiadi, Alexander Immer, Runa Eschenhagen, Matthias Bauer, and Philipp Hennig. Laplace Redux - Effortless Bayesian Deep Learning. InAdvances in Neural Information Processing Systems, volume 34, pages 20089–20103. Curran Associates, Inc., 2021
2021
-
[6]
Paths and Ambient Spaces in Neural Loss Landscapes
Daniel Dold, Julius Kobialka, Nicolai Palm, Emanuel Sommer, David Rügamer, and Oliver Dürr. Paths and Ambient Spaces in Neural Loss Landscapes. InProceedings of The 28th International Conference on Artificial Intelligence and Statistics, pages 10–18. PMLR, April 2025
2025
-
[7]
Essentially no barriers in neural network energy landscape
Felix Draxler, Kambis Veschgini, Manfred Salmhofer, and Fred Hamprecht. Essentially no barriers in neural network energy landscape. InInternational conference on machine learning, pages 1309–1318. PMLR, 2018
2018
-
[8]
Loss Surfaces, Mode Connectivity, and Fast Ensembling of DNNs
Timur Garipov, Pavel Izmailov, Dmitrii Podoprikhin, Dmitry P Vetrov, and Andrew G Wilson. Loss Surfaces, Mode Connectivity, and Fast Ensembling of DNNs. InAdvances in Neural Information Processing Systems, volume 31. Curran Associates, Inc., 2018
2018
-
[9]
Bayesian Active Learning for Classification and Preference Learning
Neil Houlsby, Ferenc Huszár, Zoubin Ghahramani, and Máté Lengyel. Bayesian active learning for classification and preference learning.arXiv preprint arXiv:1112.5745, 2011
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[10]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-Rank Adaptation of Large Language Models. In ICLR 2022, April 2022
2022
-
[11]
Maddox, Polina Kirichenko, Timur Garipov, Dmitry Vetrov, and Andrew Gordon Wilson
Pavel Izmailov, Wesley J. Maddox, Polina Kirichenko, Timur Garipov, Dmitry Vetrov, and Andrew Gordon Wilson. Subspace Inference for Bayesian Deep Learning. InProceedings of The 35th Uncertainty in Artificial Intelligence Conference, pages 1169–1179. PMLR, August 2020
2020
-
[12]
Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles
Balaji Lakshminarayanan, Alexander Pritzel, and Charles Blundell. Simple and Scalable Predictive Uncertainty Estimation using Deep Ensembles. InAdvances in Neural Information Processing Systems, volume 30. Curran Associates, Inc., 2017
2017
-
[13]
Flat-LoRA: Low-Rank Adaptation over a Flat Loss Landscape
Tao Li, Zhengbao He, Yujun Li, Yasheng Wang, Lifeng Shang, and Xiaolin Huang. Flat-LoRA: Low-Rank Adaptation over a Flat Loss Landscape. InProceedings of the 42nd International Conference on Machine Learning, pages 34549–34563. PMLR, October 2025
2025
-
[14]
Calibrating LLMs with information- theoretic evidential deep learning
Yawei Li, David Rügamer, Bernd Bischl, and Mina Rezaei. Calibrating LLMs with information- theoretic evidential deep learning. InThe Thirteenth International Conference on Learning Representations, 2025. 10
2025
-
[15]
Can a suit of armor conduct electricity? a new dataset for open book question answering
Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering. InProceedings of the 2018 conference on empirical methods in natural language processing, pages 2381–2391, 2018
2018
-
[16]
Black Box Variational Inference
Rajesh Ranganath, Sean Gerrish, and David Blei. Black Box Variational Inference. InProceed- ings of the Seventeenth International Conference on Artificial Intelligence and Statistics, pages 814–822. PMLR, April 2014
2014
-
[17]
Winogrande: An adversarial winograd schema challenge at scale.Communications of the ACM, 64(9):99–106, 2021
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale.Communications of the ACM, 64(9):99–106, 2021
2021
-
[18]
Scalable Bayesian Low-Rank Adaptation of Large Language Models via Stochastic Variational Subspace Inference
Colin Samplawski, Adam D Cobb, Manoj Acharya, Ramneet Kaur, and Susmit Jha. Scalable Bayesian Low-Rank Adaptation of Large Language Models via Stochastic Variational Subspace Inference. InConference on Uncertainty in Artificial Intelligence, pages 3587–3604. PMLR, 2025
2025
-
[19]
Yibin Wang, Haizhou Shi, Ligong Han, Dimitris Metaxas, and Hao Wang. BLoB: Bayesian Low-Rank Adaptation by Backpropagation for Large Language Models.Advances in Neural In- formation Processing Systems, 37:67758–67794, December 2024. doi: 10.52202/079017-2164
-
[20]
Yang, Maxime Robeyns, Xi Wang, and Laurence Aitchison
Adam X. Yang, Maxime Robeyns, Xi Wang, and Laurence Aitchison. Bayesian Low-rank Adaptation for Large Language Models. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[21]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2. 5 technical report.arXiv preprint arXiv:2412.15115, 2024. 11 A Mutual information (MI) To quantify epistemic uncertainty as a measure of functional diversity within our LoRA-Curve framework, we compute the Mutual Informat...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
D Answer: label: 2 - id: 2 prompt: Return the label of the correct answer for the question below. Question: Which of the following are renewable energy sources? Choices: solar power) A wind power) B coal) C hydroelectric power) D Answer: label: [0, 1, 3] - id: 3 prompt: Return the label of the correct answer for the question below. Question: Which of the ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.