Metric-Dependent Annotation Saturation for Learning from Label Distributions
Pith reviewed 2026-06-29 08:03 UTC · model grok-4.3
The pith
The annotator count needed to learn from label distributions depends on the evaluation metric.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
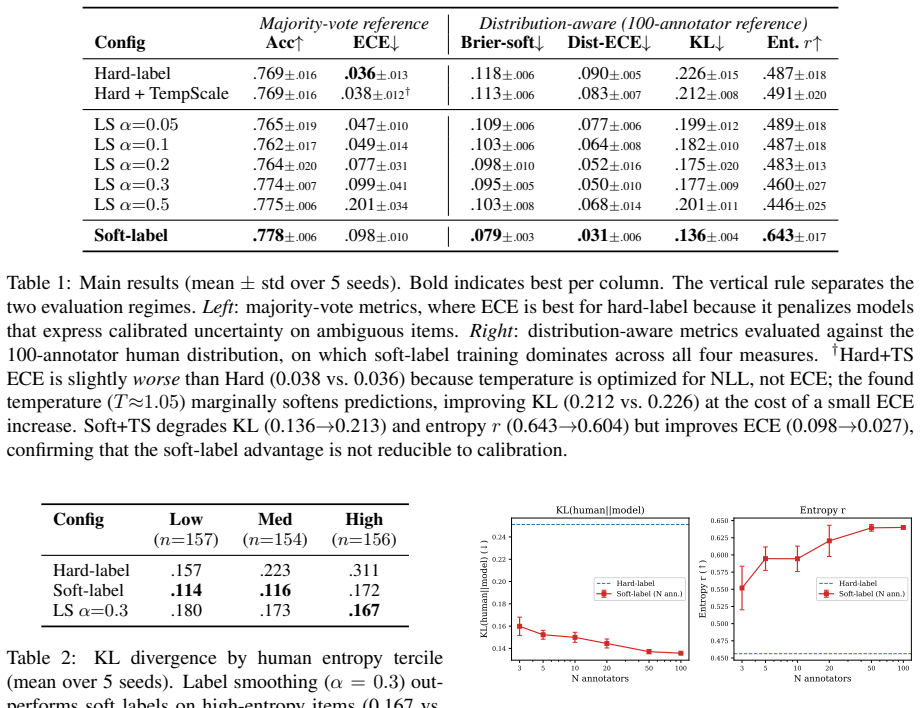
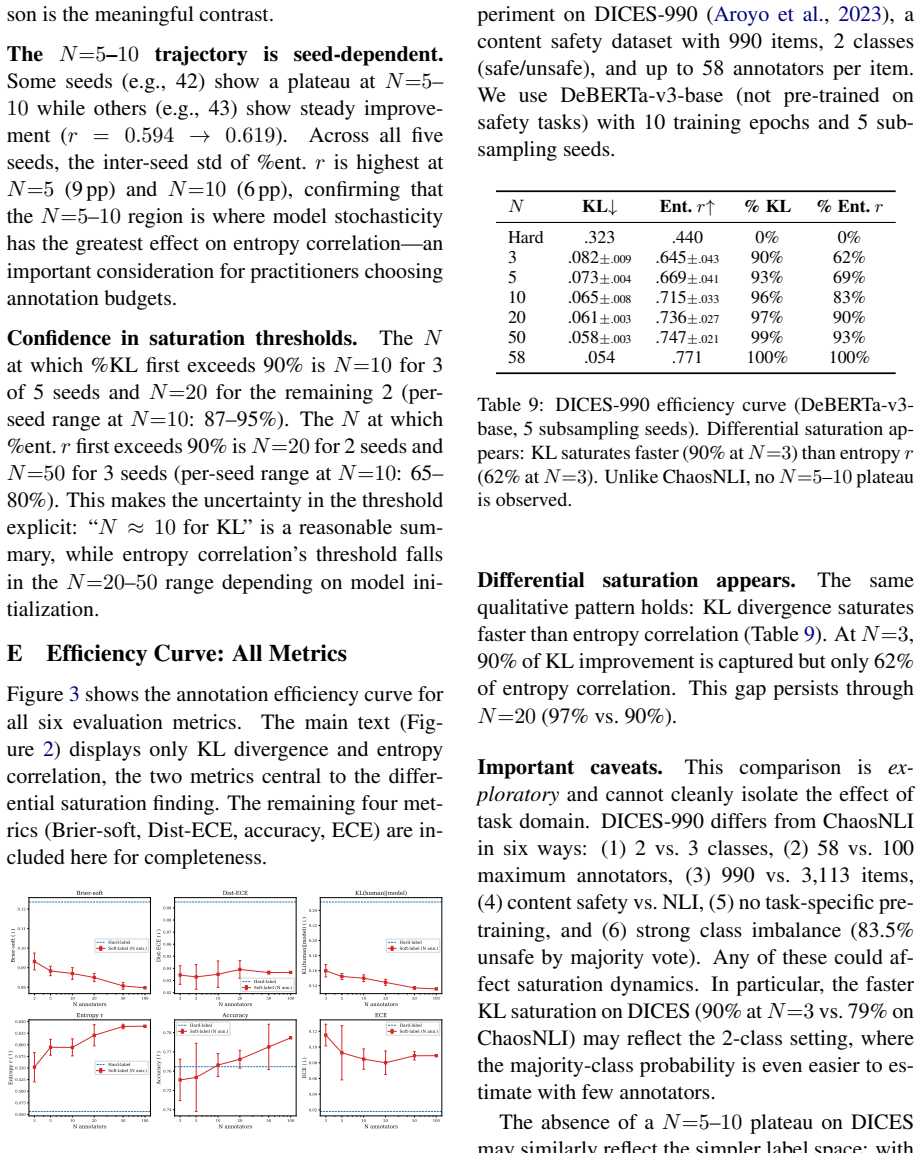
In experiments that subsample label distributions from the 100-annotator ChaosNLI corpus, KL divergence between model outputs and true distributions saturates by N approximately 10, capturing 87-95 percent of total improvement, whereas correlation between predicted and true per-item entropy requires N in the 20-50 range to converge. Soft labels achieve higher entropy correlation (r = 0.643) than any of five label-smoothing intensities (r clustered at 0.45-0.49), because smoothing cannot separate ambiguous items from clear ones on a per-item basis.
What carries the argument
Subsampling of per-item label distributions from a fixed 100-annotator pool, evaluated separately by KL divergence for distributional fidelity and by entropy correlation for disagreement identification.
If this is right
- Annotation budgets can be set lower when the target metric is distributional match than when it is disagreement identification.
- Soft labels must be retained rather than replaced by smoothing if the goal includes recovering item-level ambiguity signals.
- Models trained on limited annotations can still produce accurate distribution predictions even when they cannot yet rank disagreement items correctly.
- The same metric-dependent pattern appears across DeBERTa, RoBERTa, a non-NLI baseline, and at least one cross-domain setting.
Where Pith is reading between the lines
- Annotation planning tools could include metric-specific cost curves rather than a single recommended N.
- The same subsampling method could be applied to other tasks that already possess large multi-annotator corpora to check whether saturation points differ by domain.
- If real-time collection of new annotations produces different curves, the field would need separate guidelines for incremental versus retrospective annotation design.
Load-bearing premise
Subsampling from one large fixed pool of annotations produces the same saturation curves that would appear if smaller numbers of new independent annotations were collected for each item.
What would settle it
Collect fresh independent annotations in successive batches of 5, 10, 20, and 50 on a new set of NLI items and test whether the KL saturation point remains near 10 while entropy correlation saturation remains near 20-50.
Figures

read the original abstract
When annotators disagree on a label, the disagreement itself carries signal -- and the number of annotators needed to capture it depends on the evaluation metric. We fine-tune NLI models on label distributions subsampled from ChaosNLI, a dataset providing 100 independent annotator judgments per item, and identify metric-dependent saturation. In our 3-class NLI setting, entropy correlation -- whether the model identifies which items elicit disagreement -- requires N ~ 20-50 annotators to converge, while distributional match (KL divergence) saturates by N ~ 10 (87-95% of improvement across five model seeds). This finding rests on a prior observation: soft labels carry item-specific signal that label smoothing cannot replicate. Across five smoothing intensities, entropy correlation clusters at r ~ 0.45-0.49, while soft labels reach r = 0.643 (p < 0.001); per-item analysis traces this gap to smoothing's inability to distinguish ambiguous items from clear ones. The soft-label advantage replicates across two architectures (DeBERTa, RoBERTa), a non-NLI-pretrained baseline, and an exploratory cross-domain evaluation on content safety. These results suggest that annotation budgets should be informed by the target evaluation metric rather than set uniformly.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that in 3-class NLI, annotation saturation is metric-dependent: KL divergence for distributional match reaches 87-95% of its improvement by N~10 annotators, while entropy correlation (identifying disagreement-eliciting items) requires N~20-50 to converge. This is shown via subsampling from the 100-annotator ChaosNLI dataset, with soft labels outperforming label smoothing (r=0.643 vs. 0.45-0.49) across DeBERTa, RoBERTa, and other models; the authors conclude that annotation budgets should be metric-dependent.
Significance. If the central empirical results are robust, the work provides actionable guidance for efficient annotation allocation in disagreement-heavy NLP tasks, distinguishing signal capture for different metrics. The replication across architectures and seeds, plus the soft-label vs. smoothing comparison, adds empirical value; the finding that soft labels distinguish ambiguous items where smoothing cannot is a useful observation for label-distribution learning.
major comments (2)
- [Methods (subsampling procedure)] Subsampling procedure (Methods section): The headline saturation results (KL at N~10; entropy correlation at N~20-50) are obtained by repeatedly drawing k annotations per item from the fixed 100-annotator ChaosNLI pool. This procedure assumes the 100 judgments are i.i.d. draws equivalent to independent collection of k fresh annotations; potential annotator-pool selection effects, fatigue, or item-specific expertise variation are not tested, leaving the metric-dependent budget recommendation dependent on an unvalidated equivalence.
- [Results] Statistical reporting (Results section): Saturation points and percentage improvements (87-95%) are reported across five seeds without accompanying error bars, confidence intervals, or formal tests for convergence; the reader's note on unverifiable statistical methods indicates this detail is needed to support the precise N thresholds claimed.
minor comments (2)
- The abstract and text would benefit from explicit discussion of how the subsampling procedure could be validated (e.g., via comparison to a smaller independent collection) to address the i.i.d. assumption.
- Notation for the entropy correlation metric and KL divergence should be defined with equations in the main text rather than assumed from prior work.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond point-by-point to the major comments on the subsampling procedure and statistical reporting, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Methods (subsampling procedure)] Subsampling procedure (Methods section): The headline saturation results (KL at N~10; entropy correlation at N~20-50) are obtained by repeatedly drawing k annotations per item from the fixed 100-annotator ChaosNLI pool. This procedure assumes the 100 judgments are i.i.d. draws equivalent to independent collection of k fresh annotations; potential annotator-pool selection effects, fatigue, or item-specific expertise variation are not tested, leaving the metric-dependent budget recommendation dependent on an unvalidated equivalence.
Authors: We agree this is a valid methodological caveat. The subsampling approach is standard for leveraging fixed large annotation pools such as ChaosNLI, but it does rest on an untested equivalence to fresh independent annotations. In revision we will add explicit discussion of this assumption (including potential effects from annotator selection or fatigue) to the Methods and Limitations sections, clarifying that the metric-dependent budget guidance should be interpreted with this caveat in mind. revision: yes
-
Referee: [Results] Statistical reporting (Results section): Saturation points and percentage improvements (87-95%) are reported across five seeds without accompanying error bars, confidence intervals, or formal tests for convergence; the reader's note on unverifiable statistical methods indicates this detail is needed to support the precise N thresholds claimed.
Authors: We accept that variability measures and clearer convergence criteria would improve transparency. The original submission reported trends across seeds but omitted error bars. In the revised manuscript we will add standard deviations across the five seeds to the relevant figures and tables, and include a short description of the convergence heuristic (percentage of total improvement achieved) used to identify the reported N thresholds. revision: yes
Circularity Check
No circularity: empirical results from external dataset subsampling
full rationale
The paper derives its saturation findings (KL divergence saturating at N~10 vs. entropy correlation at N~20-50) solely through repeated subsampling of the external ChaosNLI dataset (100 annotations per item) followed by standard fine-tuning and metric evaluation across model seeds. No equations define a quantity in terms of itself, no fitted parameters are relabeled as predictions, and no self-citations supply load-bearing uniqueness theorems or ansatzes. The central claims rest on direct comparison of empirical curves rather than any reduction to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Subsampling from a fixed set of 100 annotations per item is representative of varying annotation counts
- standard math Standard fine-tuning procedures and loss functions for NLI models on label distributions
Reference graph
Works this paper leans on
-
[1]
InProceedings of the 2021 Conference of the North American Chapter of the Association for Compu- tational Linguistics: Human Language Technolo- gies, pages 2591–2597
Beyond black & white: Leveraging annota- tor disagreement via soft-label multi-task learning. InProceedings of the 2021 Conference of the North American Chapter of the Association for Compu- tational Linguistics: Human Language Technolo- gies, pages 2591–2597. Association for Computa- tional Linguistics. Tilmann Gneiting and Adrian E. Raftery. 2007. Stric...
2021
-
[2]
InInternational Conference on Learning Representations (ICLR)
DeBERTaV3: Improving DeBERTa us- ing ELECTRA-style pre-training with gradient- disentangled embedding sharing. InInternational Conference on Learning Representations (ICLR). Urja Khurana, Eric Nalisnick, Antske Fokkens, and Swabha Swayamdipta. 2024. Crowd-calibrator: Can annotator disagreement inform calibration in subjective tasks? InProceedings of the C...
2024
-
[3]
When does label smoothing help? InAd- vances in Neural Information Processing Systems, volume 32, pages 4696–4705. Allan H. Murphy. 1973. A new vector partition of the probability score.Journal of Applied Meteorology, 12(4):595–600. Yixin Nie, Xiang Zhou, and Mohit Bansal. 2020. What can we learn from collective human opinions on nat- ural language infere...
-
[4]
Tharindu Cyril Weerasooriya, Sarah Luger, Saloni Poddar, Ashiqur KhudaBukhsh, and Christopher Homan
Learning from disagreement: A survey.Jour- nal of Artificial Intelligence Research, 72:1385– 1470. Tharindu Cyril Weerasooriya, Sarah Luger, Saloni Poddar, Ashiqur KhudaBukhsh, and Christopher Homan. 2023. Subjective crowd disagreements for subjective data: Uncovering meaningful Crow- dOpinion with population-level learning. InPro- ceedings of the 61st An...
2023
-
[5]
A broad-coverage challenge corpus for sen- tence understanding through inference. InProceed- ings of the 2018 Conference of the North American Chapter of the Association for Computational Lin- guistics: Human Language Technologies, Volume 1 (Long Papers), pages 1112–1122. Association for Computational Linguistics. Thomas Wolf, Lysandre Debut, Victor Sanh,...
2018
-
[6]
Capturing label distribution: A case study in NLI.arXiv preprint arXiv:2102.06859. Xiang Zhou, Yixin Nie, and Mohit Bansal. 2022. Dis- tributed NLI: Learning to predict human opinion dis- tributions for language reasoning. InFindings of the Association for Computational Linguistics: ACL 2022, pages 972–987, Dublin, Ireland. Association for Computational L...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.