Enhancing Multi-Agent Communication through Attention Steering with Context Relevance
Pith reviewed 2026-06-29 07:40 UTC · model grok-4.3
The pith
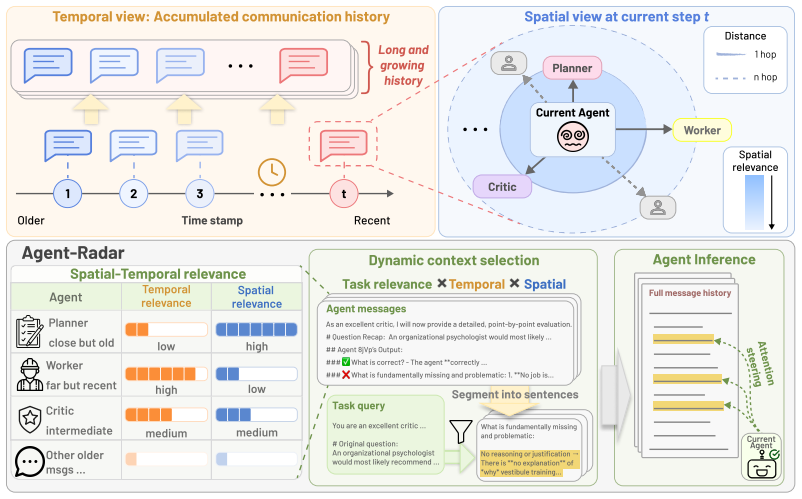
Agent-Radar applies temporal and spatial decay to steer multi-agent attention toward relevant context in long histories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
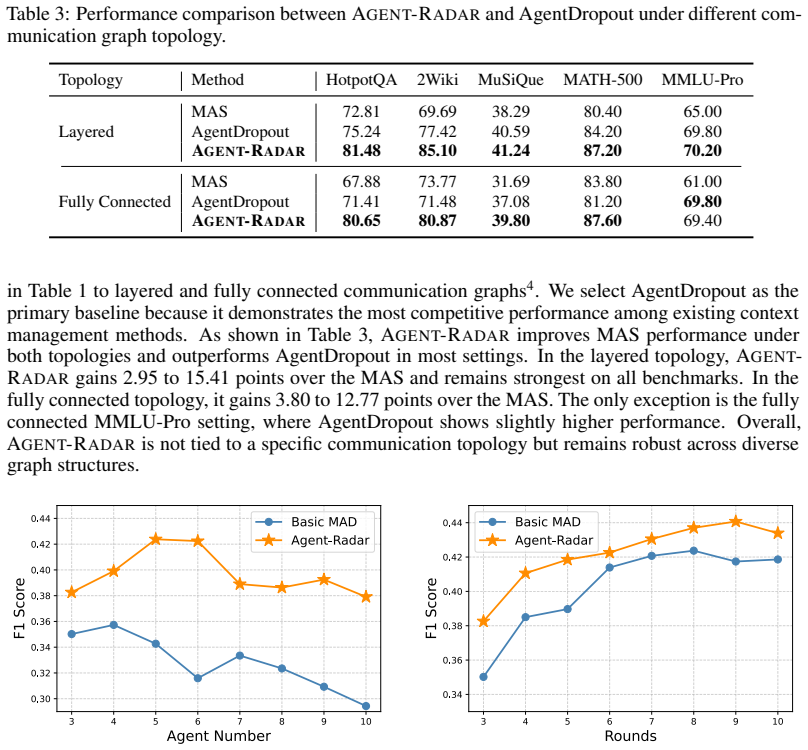
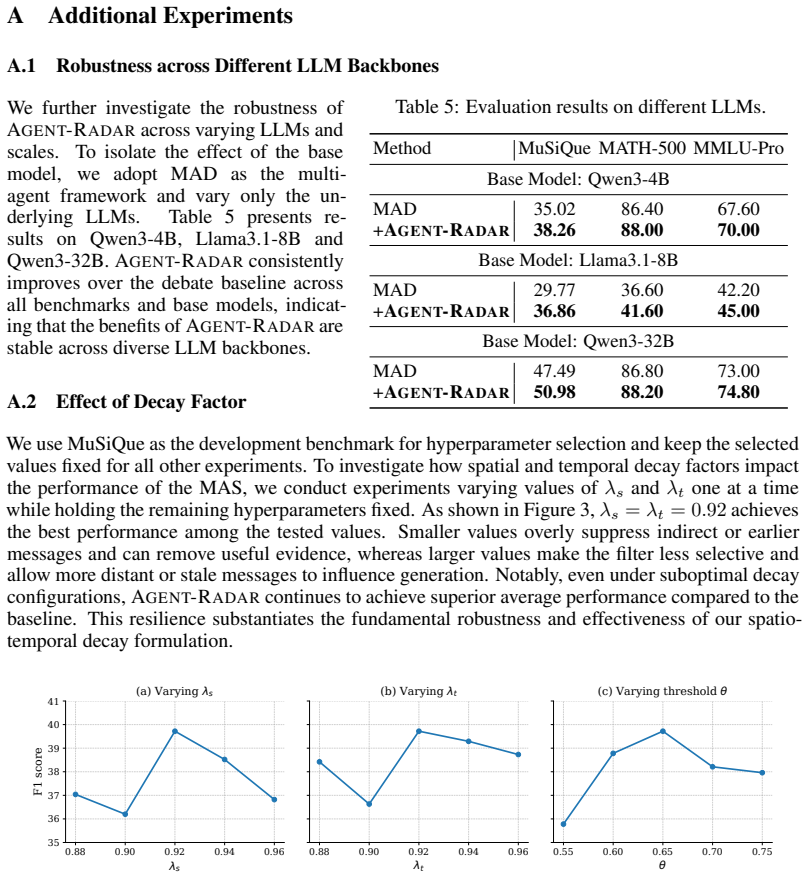
Agent-Radar is a training-free context management method that dynamically steers each agent's attention toward relevant context with a novel temporal and spatial decay mechanism. Experiments demonstrate that Agent-Radar outperforms state-of-the-art methods across five different benchmarks, yielding gains of up to 7.64 absolute points. Analysis shows that Agent-Radar remains effective and robust as the number of agents and interaction rounds increases, and ablation confirms that its core components are crucial to performance and generalizable across settings.
What carries the argument
The temporal and spatial decay mechanism that prioritizes relevant context within growing multi-agent conversation histories.
If this is right
- Outperforms state-of-the-art methods across five benchmarks with gains of up to 7.64 absolute points.
- Remains effective and robust as the number of agents and interaction rounds increases.
- Core components prove crucial to performance through ablation and generalize across different settings.
Where Pith is reading between the lines
- The training-free design could lower the barrier to deploying multi-agent systems at larger scales by avoiding the need for additional fine-tuning.
- Decay-based prioritization may reduce the computational load of processing full histories in each agent turn.
- The same mechanism could be tested for single-agent long-context tasks where history dilution occurs.
Load-bearing premise
A training-free temporal and spatial decay mechanism can reliably identify and prioritize relevant context in growing multi-agent conversation histories without introducing systematic errors or requiring task-specific tuning.
What would settle it
Running Agent-Radar on any of the five benchmarks and observing no gain or outright underperformance relative to the strongest baseline would falsify the central performance claim.
Figures
read the original abstract
LLM-based multi-agent systems have demonstrated remarkable performance on complex tasks through collaborative reasoning. However, these systems tend to rapidly accumulate extremely long conversation histories during interaction. As conversations lengthen, relevant information is increasingly diluted by irrelevant context, leading to degraded performance. In this work, we present Agent-Radar, a training-free context management method that dynamically steers each agent's attention toward relevant context with a novel temporal and spatial decay mechanism. Our experiments demonstrate that Agent-Radar outperforms state-of-the-art methods across five different benchmarks, yielding gains of up to 7.64 absolute points. Furthermore, our analysis shows that Agent-Radar remains effective and robust as the number of agents and interaction rounds increases. Finally, the ablation study shows that core components in Agent-Radar are crucial to performance and generalizable in different settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Agent-Radar, a training-free context management technique for LLM-based multi-agent systems that uses a novel temporal and spatial decay mechanism to steer each agent's attention toward relevant messages in lengthening conversation histories. It reports that this approach outperforms state-of-the-art methods on five benchmarks (gains up to 7.64 absolute points), remains effective as the number of agents and interaction rounds grows, and that ablations confirm the necessity of its core components.
Significance. If the decay mechanism reliably isolates relevant context rather than acting as a generic length-reduction heuristic, the method could address a practical scalability bottleneck in multi-agent LLM systems. The training-free nature and reported robustness to scale are potentially useful strengths, though the absence of isolated relevance metrics limits the strength of the supporting evidence.
major comments (1)
- [Experimental evaluation and ablation study (as summarized in the abstract)] The central performance claim (outperformance on five benchmarks) rests on the assumption that the temporal/spatial decay correctly prioritizes relevant messages. However, the reported results consist only of end-task scores and an ablation that removes the decay components; no separate evaluation (e.g., precision@K or AUC against human relevance labels on selected context) is provided to verify that the chosen subsets are actually the relevant ones rather than any truncation heuristic producing similar gains.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our experimental evaluation. We address the major comment point by point below.
read point-by-point responses
-
Referee: The central performance claim (outperformance on five benchmarks) rests on the assumption that the temporal/spatial decay correctly prioritizes relevant messages. However, the reported results consist only of end-task scores and an ablation that removes the decay components; no separate evaluation (e.g., precision@K or AUC against human relevance labels on selected context) is provided to verify that the chosen subsets are actually the relevant ones rather than any truncation heuristic producing similar gains.
Authors: We acknowledge the validity of this observation. Our evaluation centers on end-task performance because that is the ultimate objective for context management in multi-agent LLM systems; the ablation demonstrates that removing the temporal and spatial decay components eliminates the reported gains, and the method outperforms multiple existing context-management baselines that also perform truncation or selection. These results provide indirect support that the decay prioritizes task-relevant messages. However, we agree that an explicit relevance metric (e.g., against human annotations) would strengthen the mechanistic claim. In the revised manuscript we will add a dedicated limitations paragraph discussing this point and include any available proxy statistics from the existing experiments (such as overlap between selected context and ground-truth task entities) to partially address the concern. revision: partial
Circularity Check
No circularity: new method evaluated on external benchmarks
full rationale
The paper introduces Agent-Radar as a novel training-free temporal/spatial decay mechanism for multi-agent context management and reports performance gains on five external benchmarks. No derivation chain, equations, or claims reduce by construction to the paper's own inputs or fitted parameters. No self-citations are load-bearing for uniqueness, ansatz, or central results. The evaluation uses independent benchmarks and ablations without renaming known results or calling fitted quantities predictions. This is the standard case of a self-contained empirical method paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URL https://aclanthology.org/2025.acl-long.1170/. Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022. Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, ...
-
[2]
The conversation ends only when all agents output the answer in this format
On finding the final answer, ensure to conclude your communication with boxedanswer, where änswerïs the determined solution. The conversation ends only when all agents output the answer in this format
-
[3]
Reason through the problem step-by-step
-
[4]
Field1",
You are communicating with a very limited token budget, so you must use a very very concise communication format. Natural language is suitable for human, but not for you. Since you and your partner are both intelligent agents, use your agent communication language. Consider using efficient formats instead of natural language such as structured format, cod...
-
[5]
A mathematician may understand simulation and risk modeling, but lacks **psychological theory, human factors, or training design principles** central to organizational psychology
**Misalignment of role**: The agent is labeled a *Mathematician*, yet the task is clearly rooted in **organizational psychology**. A mathematician may understand simulation and risk modeling, but lacks **psychological theory, human factors, or training design principles** central to organizational psychology. This raises a red flag: **the reasoning lacks ...
-
[6]
high-risk
**Overgeneralization of "high-risk" without nuance**: - While pilots are high-risk, the agent treats "high-risk" as a binary criterion without considering **training context or job complexity**. - For instance, bus drivers also face high-risk scenarios (e.g., sudden stops, road hazards), and their training *can* involve simulators but this is less emphasi...
-
[7]
situational awareness
**Lack of citation of evidence or theory**: - No reference to established models (e.g., **Bandura’s social learning theory**, **Gagné’s nine events of instruction**, or **Kolb’s experiential learning**) that underpin why simulation-based training works best in certain roles. This makes the argument feel more like a heuristic than a psychologically grounde...
-
[8]
gold standard
**Overstatement of "gold standard" without evidence**: - The claim that "pilot training is the most established, widely recognized, and scientifically validated application" is **strong but unsubstantiated**. - While flight simulators are common, **vestibule training is not exclusively or primarily used for pilots**. - For example, **air traffic controlle...
-
[9]
less common
**Mischaracterization of other roles**: - The agent dismisses bus drivers as having "less common" simulator use but **bus driver training in many countries (e.g., UK, Canada) includes driving simulators**, especially for new drivers or in high-risk zones. - This suggests a **bias toward pilots** without acknowledging **equivalent applications** in other t...
-
[10]
low-stakes
**Underestimates the role of social and interpersonal skills**: - For example, salespeople and restaurant waiters require **empathy, communication, and customer management** all of which can be developed through **simulated role-playing** (a form of vestibule training). - The agent dismisses these roles too quickly, implying they are "low-stakes" which ma...
-
[11]
vestibule
** Lack of attention to job entry level**: - Vestibule training is often used for **highly specialized, entry-level roles** where competence must be proven before real-world exposure. - But the agent doesn’t consider whether **pilots are entry-level or require years of experience** a nuance that matters 4Pgq: Great question! Let’s approach this from a **p...
-
[12]
Guidelines: • The answer [N/A] means that the abstract and introduction do not include the claims made in the paper
Claims Question: Do the main claims made in the abstract and introduction accurately reflect the paper’s contributions and scope? Answer: [Y es] Justification: Section Abstract, and Section 1. Guidelines: • The answer [N/A] means that the abstract and introduction do not include the claims made in the paper. • The abstract and/or introduction should clearly...
-
[13]
Limitations
Limitations Question: Does the paper discuss the limitations of the work performed by the authors? Answer: [Y es] Justification: Section Appendix. 6 Guidelines: • The answer [N/A] means that the paper has no limitation while the answer [No] means that the paper has limitations, but those are not discussed in the paper. • The authors are encouraged to creat...
-
[14]
• All the theorems, formulas, and proofs in the paper should be numbered and cross- referenced
Theory assumptions and proofs Question: For each theoretical result, does the paper provide the full set of assumptions and a complete (and correct) proof? Answer: [Y es] 30 Justification: Section 2 and 3 Guidelines: • The answer [N/A] means that the paper does not include theoretical results. • All the theorems, formulas, and proofs in the paper should be...
-
[15]
Guidelines: • The answer [N/A] means that the paper does not include experiments
Experimental result reproducibility Question: Does the paper fully disclose all the information needed to reproduce the main experimental results of the paper to the extent that it affects the main claims and/or conclu- sions of the paper (regardless of whether the code and data are provided or not)? Answer: [Y es] Justification: Section 4.1 and Appendix.C...
-
[16]
Guidelines: • The answer [N/A] means that paper does not include experiments requiring code
Open access to data and code Question: Does the paper provide open access to the data and code, with sufficient instruc- tions to faithfully reproduce the main experimental results, as described in supplemental material? 31 Answer: [No] Justification: We will release data and code once the paper is accepted. Guidelines: • The answer [N/A] means that paper d...
-
[17]
Guidelines: • The answer [N/A] means that the paper does not include experiments
Experimental setting/details Question: Does the paper specify all the training and test details (e.g., data splits, hyperpa- rameters, how they were chosen, type of optimizer) necessary to understand the results? Answer: [Y es] Justification: Section 4.1 and Appendix.C. Guidelines: • The answer [N/A] means that the paper does not include experiments. • The...
-
[18]
Guidelines: • The answer [N/A] means that the paper does not include experiments
Experiment statistical significance Question: Does the paper report error bars suitably and correctly defined or other appropri- ate information about the statistical significance of the experiments? Answer: [No] Justification: We report results on standard benchmarks using their commonly adopted eval- uation metrics, including F1 for open-ended question answ...
-
[19]
Guidelines: • The answer [N/A] means that the paper does not include experiments
Experiments compute resources Question: For each experiment, does the paper provide sufficient information on the com- puter resources (type of compute workers, memory, time of execution) needed to reproduce the experiments? Answer: [Y es] Justification: Section 4.1. Guidelines: • The answer [N/A] means that the paper does not include experiments. • The pap...
-
[20]
Guidelines: • The answer [N/A] means that the authors have not reviewed the NeurIPS Code of Ethics
Code of ethics Question: Does the research conducted in the paper conform, in every respect, with the NeurIPS Code of Ethics https://neurips.cc/public/EthicsGuidelines? Answer: [Y es] Justification: Our research conforms, in every respect, with the NeurIPS Code of Ethics. Guidelines: • The answer [N/A] means that the authors have not reviewed the NeurIPS C...
-
[21]
Guidelines: • The answer [N/A] means that there is no societal impact of the work performed
Broader impacts Question: Does the paper discuss both potential positive societal impacts and negative societal impacts of the work performed? Answer: [N/A] Justification: This work focuses on aligning agents’ attention in multi-agent systems, which has no societal impact. Guidelines: • The answer [N/A] means that there is no societal impact of the work pe...
-
[22]
Guidelines: • The answer [N/A] means that the paper poses no such risks
Safeguards Question: Does the paper describe safeguards that have been put in place for responsible release of data or models that have a high risk for misuse (e.g., pre-trained language models, image generators, or scraped datasets)? Answer: [N/A] Justification: The paper poses no such risks. Guidelines: • The answer [N/A] means that the paper poses no su...
-
[23]
• The authors should cite the original paper that produced the code package or dataset
Licenses for existing assets Question: Are the creators or original owners of assets (e.g., code, data, models), used in the paper, properly credited and are the license and terms of use explicitly mentioned and properly respected? Answer: [Y es] Justification: Section 4.1 Guidelines: • The answer [N/A] means that the paper does not use existing assets. • ...
-
[24]
Guidelines: • The answer [N/A] means that the paper does not release new assets
New assets Question: Are new assets introduced in the paper well documented and is the documenta- tion provided alongside the assets? Answer: [N/A] Justification: The paper does not release new assets. Guidelines: • The answer [N/A] means that the paper does not release new assets. • Researchers should communicate the details of the dataset/code/model as p...
-
[25]
Guidelines: • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects
Crowdsourcing and research with human subjects Question: For crowdsourcing experiments and research with human subjects, does the pa- per include the full text of instructions given to participants and screenshots, if applicable, as well as details about compensation (if any)? Answer: [N/A] Justification: This paper does not involve crowdsourcing nor resea...
-
[26]
Guidelines: • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
-
[27]
Answer: [N/A] Justification: The core method development in this research does not involve LLMs as any important, original, or non-standard components
Declaration of LLM usage 35 Question: Does the paper describe the usage of LLMs if it is an important, original, or non-standard component of the core methods in this research? Note that if the LLM is used only for writing, editing, or formatting purposes and does not impact the core methodology, scientific rigor, or originality of the research, declaratio...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.