Knowledge Graph-Enhanced Zero-Shot Topic Classification: A Multi-Strategy Comparative Study
Pith reviewed 2026-06-29 07:45 UTC · model grok-4.3
The pith
Knowledge graph augmentation improves zero-shot topic classification for small language models but reduces performance for large ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
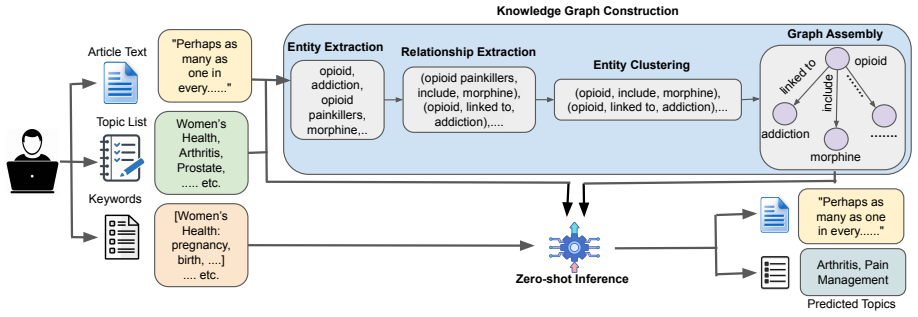
The paper establishes that per-article knowledge graph augmentation, extracted via subject-predicate-object triples, produces positive performance effects on small LLMs and negative effects on large LLMs in zero-shot multi-label topic classification. This pattern holds across the tested models and datasets and indicates that larger models already contain enough relational information from pretraining. Among base methods, keyword-enhanced classification outperforms article-only and self-consistency variants, with six of fifteen LLMs exceeding the sentence-encoder baseline.
What carries the argument
Per-article knowledge graph augmentation built from subject-predicate-object triples extracted from the input document, applied to base variants of article-only classification, keyword-enhanced classification, and their self-consistency versions.
If this is right
- Smaller models gain accuracy when document-specific knowledge graphs are added to the zero-shot pipeline.
- Larger models achieve higher accuracy when classification uses only the original article text or keywords.
- Keyword-enhanced classification is the strongest base method across the tested LLMs.
- Self-consistency decoding raises compute cost by a factor of five without improving results in any setting.
- Six of the fifteen evaluated LLMs already exceed a sentence-encoder baseline without any graph augmentation.
Where Pith is reading between the lines
- The same size-dependent pattern may appear in other zero-shot tasks that require relational reasoning.
- Small-model pipelines could systematically incorporate document-level graphs while large-model pipelines could omit them.
- The findings point to a saturation point in pretraining where additional explicit relational data becomes redundant or noisy.
Load-bearing premise
The pipeline that extracts subject-predicate-object triples from each document produces accurate and relevant relational information that augments classification without adding noise.
What would settle it
A controlled experiment in which the same large models are tested with knowledge graphs generated from an independent external source rather than the input document itself, checking whether the negative impact on large models disappears.
Figures
read the original abstract
Multi-label topic classification without labeled training data is a challenging task, specially when documents contain complex relational information. We present a zero-shot multi-label topic classification framework and systematically investigate how per-article knowledge graph augmentation affects its performance. The base framework classifies topics in documents without labeled training data and has four variants: article-only classification, keyword-enhanced classification, and self-consistency decoding variants of both. Then, we augment each base variant with per article knowledge graph. This graph is extracted from the input document through a pipeline similar to KGGen based on subject-predicate-object triples. We test all eight methods, four base and four graph augmented on fifteen LLMs and eight multi-label datasets across different domains. For the base framework, keyword-enhanced classification (AK) is the best performing method, and six out of fifteen LLMs surpass the sentence-encoder baseline. Graph augmentation has positive and negative impacts on small and large models, respectively. This shows that larger models already contain enough relational information from pretraining. Furthermore, the self-consistency decoding variant does not show performance improvements in any experiment while increasing computation costs about fivefold.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a zero-shot multi-label topic classification framework with four base variants (article-only classification, keyword-enhanced classification, and self-consistency decoding versions of both) and augments each with per-article knowledge graphs extracted from the input document via a subject-predicate-object triple pipeline similar to KGGen. It evaluates all eight methods across fifteen LLMs and eight multi-label datasets from different domains. Among base methods, keyword-enhanced classification performs best, and six of fifteen LLMs surpass a sentence-encoder baseline. Graph augmentation yields positive effects on small models and negative effects on large models, interpreted as evidence that larger models already encode sufficient relational information from pretraining. Self-consistency decoding shows no performance gains while increasing computation costs approximately fivefold.
Significance. If the reported differential effects of graph augmentation hold after validation, the work offers empirical guidance on when KG augmentation is beneficial versus detrimental in zero-shot LLM classification, particularly highlighting model-scale interactions. The multi-LLM, multi-dataset comparison is a positive aspect of the experimental design.
major comments (2)
- [Abstract] Abstract: The claim that negative graph-augmentation impacts on large models demonstrate they 'already contain enough relational information from pretraining' is load-bearing for the central interpretation but rests on the unverified assumption that the per-article KG extraction (subject-predicate-object triples similar to KGGen) supplies accurate, relevant facts without introducing noise. No validation, error analysis, or human inspection of the generated triples is described, leaving open the alternative that larger models are simply more sensitive to extraction errors or irrelevant triples.
- [Abstract] Abstract: The abstract states directional findings such as 'six out of fifteen LLMs surpass the sentence-encoder baseline' and the sign flip in graph-augmentation effects, yet supplies no information on the evaluation metrics used, statistical significance testing, dataset sizes, baseline implementations, or error analysis. These omissions directly affect assessment of whether the reported performance differences support the claims.
minor comments (1)
- [Abstract] Abstract: The statement that self-consistency 'does not show performance improvements in any experiment while increasing computation costs about fivefold' would benefit from a brief quantitative breakdown of the cost increase or per-variant runtime figures.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which highlight important limitations in the presentation and interpretation of our results. We address each major comment below and indicate the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that negative graph-augmentation impacts on large models demonstrate they 'already contain enough relational information from pretraining' is load-bearing for the central interpretation but rests on the unverified assumption that the per-article KG extraction (subject-predicate-object triples similar to KGGen) supplies accurate, relevant facts without introducing noise. No validation, error analysis, or human inspection of the generated triples is described, leaving open the alternative that larger models are simply more sensitive to extraction errors or irrelevant triples.
Authors: We agree that the interpretive claim in the abstract is not supported by direct validation of the extracted triples. The study did not include error analysis, human inspection, or quality assessment of the subject-predicate-object triples generated by the KG extraction pipeline. This leaves open the possibility that differential sensitivity to noise explains the observed sign flip rather than differences in pretraining knowledge. We will revise the abstract to report the empirical pattern (positive effects on small models, negative on large) without the causal interpretation regarding pretraining. We will also add a limitations paragraph acknowledging the lack of KG quality validation and the alternative explanation. revision: yes
-
Referee: [Abstract] Abstract: The abstract states directional findings such as 'six out of fifteen LLMs surpass the sentence-encoder baseline' and the sign flip in graph-augmentation effects, yet supplies no information on the evaluation metrics used, statistical significance testing, dataset sizes, baseline implementations, or error analysis. These omissions directly affect assessment of whether the reported performance differences support the claims.
Authors: The abstract was written for brevity and therefore omitted key experimental details that appear in the Methods and Results sections of the full manuscript. We accept that this reduces the abstract's standalone informativeness. We will revise the abstract to specify the primary evaluation metric, note the multi-dataset and multi-LLM scope, and indicate that statistical comparisons were performed, while keeping the abstract within length limits. revision: yes
Circularity Check
Empirical comparison study with no mathematical derivations or self-referential reductions
full rationale
The paper conducts direct experiments comparing eight classification variants (base and graph-augmented) across 15 LLMs and 8 datasets. All reported performance numbers are measured outcomes from external benchmarks, not outputs of equations or fitted parameters within the paper. No self-definitional steps, fitted-input predictions, or load-bearing self-citations appear in the derivation chain; the central interpretation follows from the observed experimental sign flip rather than reducing to the method by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Large language models contain sufficient relational knowledge from pretraining for zero-shot tasks
- domain assumption The KG extraction pipeline produces useful triples without significant noise
Reference graph
Works this paper leans on
-
[1]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D
Latent Dirichlet allocation.Journal of Ma- chine Learning Research, 3:993–1022. Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D. Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, and 1 others. 2020. Language models are few-shot learners.Advances in Neural Information Processing Systems, 33:1877–1901....
2020
-
[2]
Jianguang Du, Jing Jiang, Dandan Song, and Lejian Liao
Zero-shot text classification via knowledge graph embedding for social media data.IEEE Inter- net of Things Journal, 9(12):9205–9213. Jianguang Du, Jing Jiang, Dandan Song, and Lejian Liao. 2015. Topic modeling with document relative similarities. InIJCAI. Christian Engels, Koen Deschacht, and Marie-Francine Moens. 2010. Automatic categorization of videos...
2015
-
[3]
InProceedings of the International AAAI Conference on Web and Social Media, volume 14, pages 250–259
Towards automated sexual violence report tracking. InProceedings of the International AAAI Conference on Web and Social Media, volume 14, pages 250–259. Swapnil Hingmire and Sutanu Chakraborti. 2014. Topic labeled text classification: A weakly supervised ap- proach. InSIGIR. Thomas Hofmann. 1999. Probabilistic latent semantic indexing. InProceedings of th...
2014
-
[4]
Tomoharu Iwata, Takeshi Yamada, and Naonori Ueda
Can llms effectively leverage graph structural information through prompts, and why?Preprint, arXiv:2309.16595. Tomoharu Iwata, Takeshi Yamada, and Naonori Ueda
-
[5]
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines
Modeling social annotation data with content relevance using a topic model. InNeurIPS. Joel Jang, Seonghyeon Ye, and Minjoon Seo. 2023. Can large language models truly understand prompts? a case study with negated prompts. InTransfer Learning for Natural Language Processing Work- shop, pages 52–62. Shaoxiong Ji, Shirui Pan, Erik Cambria, Pekka Martti- nen...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
InProceedings of the 25th ACM International on Conference on Information and Knowledge Management, pages 85– 94
Effective document labeling with very few seed words: A topic model approach. InProceedings of the 25th ACM International on Conference on Information and Knowledge Management, pages 85– 94. Ye Liu, Kai Zhang, Zhenya Huang, Kehang Wang, Yang- hai Zhang, Qi Liu, and Enhong Chen. 2023. Enhanc- ing hierarchical text classification through knowledge graph int...
2023
-
[7]
Weakly-supervised neural text classification. InCIKM. Belinda Mo, Kyssen Yu, Joshua Kazdan, Joan Cabezas, Proud Mpala, Lisa Yu, Chris Cundy, Charilaos Kanat- soulis, and Sanmi Koyejo. 2025. KGGen: Extracting knowledge graphs from plain text with language mod- els.arXiv preprint arXiv:2502.09956. Saif Mohammad, Felipe Bravo-Marquez, Mohammad Salameh, and S...
-
[8]
Speeding document annotation with topic mod- els. InNAACL. Raul Puri and Bryan Catanzaro. 2019. Zero-shot text classification with generative language models. arXiv preprint arXiv:1912.10165. Pushpankar Kumar Pushp and Muktabh Mayank Sri- vastava. 2017. Train once, test anywhere: Zero- shot learning for text classification.arXiv preprint arXiv:1712.05972....
-
[9]
A Systematic Survey of Prompt Engineering in Large Language Models: Techniques and Applications
A systematic survey of prompt engineering in large language models: Techniques and applications. arXiv:2402.07927. Shubhra Kanti Karmaker Santu, Saad Syed, and James Foulds. 2016. Generalized topic modeling.JMLR, 17(1):1–39. Souvika Sarkar, Dongji Feng, and Shubhra Kanti Kar- maker Santu. 2023. Zero-shot multi-label topic infer- ence with sentence encoder...
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[10]
ChatGraph: Interpretable text classification by converting ChatGPT knowledge to graphs. In ICDMW, pages 515–520. Fabian M Suchanek, Gjergji Kasneci, and Gerhard Weikum. 2007. Yago: a core of semantic knowledge. InProceedings of the 16th international conference on World Wide Web, pages 697–706. Suppawong Tuarob, Conrad S. Tucker, Marcel Salathe, and Nilam...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.