OmniMem: Scalable and Adaptive Memory Retrieval for Long Video Generation
Pith reviewed 2026-06-29 07:54 UTC · model grok-4.3
The pith
OmniMem performs sparse retrieval over the full historical KV cache to generate longer videos without the detail loss from truncation or compression.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
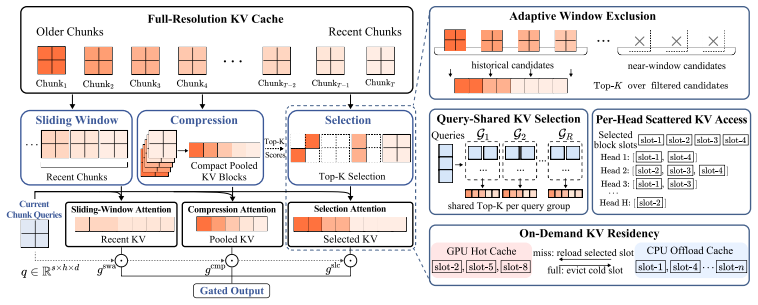
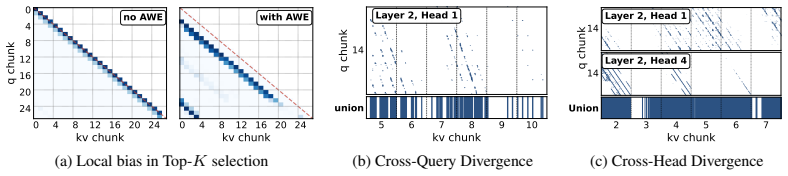
OmniMem is an explicit full-range memory retrieval framework that performs sparse KV retrieval over the historical cache. Adaptive Window Exclusion removes local-window blocks from selection candidates once sufficient long-range history exists. Query-Shared KV Selection reduces cross-query diversity. Per-Head Scattered KV Access lets each attention head retrieve non-contiguous KV blocks according to its own pattern, avoiding union explosion in the selected buffer.
What carries the argument
Sparse KV retrieval over the full historical cache, implemented through Adaptive Window Exclusion, Query-Shared KV Selection, and Per-Head Scattered KV Access.
If this is right
- Longer video sequences become feasible at fixed memory budget because the full explicit history remains available.
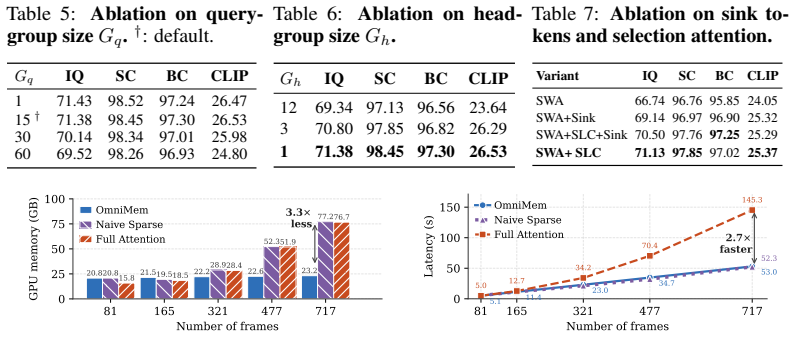
- Dynamic degree improves by 52.3 percent while consistency metrics stay strong.
- Memory usage remains comparable to truncation or compression baselines.
- Each attention head can follow its own non-contiguous retrieval pattern without expanding the selected buffer size.
Where Pith is reading between the lines
- The same sparse-retrieval pattern could be tested on autoregressive models for long text or audio to check whether explicit memory access outperforms compression there as well.
- If retrieval accuracy holds, training runs could avoid the need to lengthen context windows solely to capture distant dependencies.
- Per-head scattered access suggests that hardware kernels optimized for irregular sparse loads may become performance-critical for scaling this style of generation.
Load-bearing premise
The three sparse-selection techniques can reliably locate and fetch the query-relevant historical details that truncation or compression would otherwise discard.
What would settle it
A controlled video sequence in which an early event required for later consistency is never selected by the retrieval mechanism, producing measurable drops in temporal coherence or dynamic degree.
Figures


read the original abstract
Autoregressive (AR) video generation extends videos by producing latent chunks sequentially, but scaling to long videos requires repeated access to a growing historical KV cache. Existing methods reduce this cost by truncating the KV cache or compressing it into implicit memory, but both lose explicit access to query-relevant historical details. We propose OmniMem, an explicit full-range memory retrieval framework that performs sparse KV retrieval over the historical cache. To make this practical for chunk-based AR video generation, OmniMem addresses two issues: (i) local bias in sparse KV selection and (ii) Union Explosion in memory access. Adaptive Window Exclusion removes local-window blocks from the selection candidates when sufficient long-range history is available, preserving the sparse budget for informative long-range retrieval. Query-Shared KV Selection reduces cross-query diversity, while Per-Head Scattered KV Access avoids expanding head-specific selections into a large selected KV buffer. This allows each attention head to retrieve non-contiguous KV blocks according to its own selection pattern. Experiments on long-video generation show that OmniMem improves Dynamic Degree by 52.3% and preserves strong consistency over strong baselines, while maintaining comparable memory usage.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes OmniMem, an explicit full-range memory retrieval framework for autoregressive chunk-based long video generation. It introduces three sparse KV retrieval mechanisms—Adaptive Window Exclusion (to counter local bias when long-range history is available), Query-Shared KV Selection (to reduce cross-query diversity), and Per-Head Scattered KV Access (to avoid union explosion by allowing per-head non-contiguous block selection)—that together enable query-relevant historical KV access without truncation or compression. Experiments report a 52.3% gain in Dynamic Degree over strong baselines while preserving consistency and comparable memory usage.
Significance. If the empirical results and the claim that the three mechanisms recover relevant historical details without information loss hold under scrutiny, the work would meaningfully advance scalable AR video generation by retaining explicit long-range access at manageable cost. This addresses a core scaling bottleneck and could influence subsequent memory-efficient video and multimodal generation systems.
major comments (2)
- [Abstract] Abstract: the central claim of a 52.3% Dynamic Degree improvement is presented without any description of the baseline methods, dataset, number of videos or frames evaluated, variance across runs, or statistical significance; this single quantitative result is load-bearing for the paper's contribution and cannot be assessed from the given information.
- [Abstract / Method] The manuscript's core assumption—that Adaptive Window Exclusion, Query-Shared KV Selection, and Per-Head Scattered KV Access together surface query-relevant historical KV without the loss incurred by truncation or compression—requires explicit supporting evidence (e.g., ablation tables isolating each component, attention visualizations, or retrieval-precision metrics) to be load-bearing; the abstract alone does not supply this verification.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and the need for stronger verification of our core claims. We address each major comment below and will revise the manuscript to improve self-containment and evidence presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of a 52.3% Dynamic Degree improvement is presented without any description of the baseline methods, dataset, number of videos or frames evaluated, variance across runs, or statistical significance; this single quantitative result is load-bearing for the paper's contribution and cannot be assessed from the given information.
Authors: We agree the abstract should be more self-contained for the load-bearing quantitative claim. The experimental section details the baselines (strong AR video generation methods with KV cache management), the long-video dataset, evaluation scale (multiple videos with extended frame counts), and reports averaged results with variance. In revision we will expand the abstract to concisely include these elements (baselines, dataset, scale, and note on averaging/variance) while preserving length limits. revision: yes
-
Referee: [Abstract / Method] The manuscript's core assumption—that Adaptive Window Exclusion, Query-Shared KV Selection, and Per-Head Scattered KV Access together surface query-relevant historical KV without the loss incurred by truncation or compression—requires explicit supporting evidence (e.g., ablation tables isolating each component, attention visualizations, or retrieval-precision metrics) to be load-bearing; the abstract alone does not supply this verification.
Authors: The overall experimental results (52.3% Dynamic Degree gain with preserved consistency and comparable memory) provide empirical support for the combined mechanisms recovering relevant history without truncation/compression loss. Component-wise ablations, attention visualizations, and retrieval analysis appear in the experiments and supplementary sections. To make this verification more explicit and tied to the abstract claim, we will add or highlight ablation tables isolating each mechanism, plus attention/retrieval-precision figures in the main paper during revision. revision: yes
Circularity Check
No significant circularity identified
full rationale
The manuscript describes an explicit sparse-retrieval framework (Adaptive Window Exclusion, Query-Shared KV Selection, Per-Head Scattered KV Access) whose design choices are stated directly and whose performance is reported solely as empirical outcomes on long-video generation benchmarks. No equations, fitted parameters renamed as predictions, self-citations used as load-bearing uniqueness theorems, or ansatzes smuggled via prior work appear in the supplied text. The central claim therefore rests on observable experimental deltas rather than any definitional or self-referential reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Open-Sora: Democratizing Efficient Video Production for All
Zangwei Zheng, Xiangyu Peng, Tianji Yang, Chenhui Shen, Shenggui Li, Hongxin Liu, Yukun Zhou, Tianyi Li, and Yang You. Open-sora: Democratizing efficient video production for all.arXiv preprint arXiv:2412.20404, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Open-Sora Plan: Open-Source Large Video Generation Model
Bin Lin, Yunyang Ge, Xinhua Cheng, Zongjian Li, Bin Zhu, Shaodong Wang, Xianyi He, Yang Ye, Shenghai Yuan, Liuhan Chen, et al. Open-sora plan: Open-source large video generation model.arXiv preprint arXiv:2412.00131, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Fastcar: Cache attentive replay for fast auto-regressive video generation on the edge
Xuan Shen, Weize Ma, Yufa Zhou, Enhao Tang, Yanyue Xie, Zhengang Li, Yifan Gong, Quanyi Wang, Henghui Ding, Yiwei Wang, Pu Zhao, Jun Lin, and Jiuxiang Gu. Fastcar: Cache attentive replay for fast auto-regressive video generation on the edge. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[5]
Draftattention: Fast video diffusion via low-resolution attention guidance
Xuan Shen, Chenxia Han, Yufa Zhou, Yanyue Xie, Yifan Gong, Quanyi Wang, Yiwei Wang, Yanzhi Wang, Pu Zhao, and Jiuxiang Gu. Draftattention: Fast video diffusion via low-resolution attention guidance. arXiv preprint arXiv:2505.14708, 2025
-
[6]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Movie Gen: A Cast of Media Foundation Models
Adam Polyak, Amit Zohar, Andrew Brown, Andros Tjandra, Animesh Sinha, Ann Lee, Apoorv Vyas, et al. Movie gen: A cast of media foundation models.arXiv preprint arXiv:2410.13720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Lin Zhao, Yushu Wu, Aleksei Lebedev, Dishani Lahiri, Meng Dong, Arpit Sahni, Michael Vasilkovsky, Hao Chen, Ju Hu, Aliaksandr Siarohin, et al. S2dit: Sandwich diffusion transformer for mobile streaming video generation.arXiv preprint arXiv:2601.12719, 2026
-
[9]
Yuqing Wang, Tianwei Xiong, Daquan Zhou, Zhijie Lin, Yang Zhao, Bingyi Kang, Jiashi Feng, and Xihui Liu. Loong: Generating minute-level long videos with autoregressive language models.arXiv preprint arXiv:2410.02757, 2024
-
[11]
Pyramidal flow matching for efficient video generative modeling,
Yang Jin, Zhicheng Sun, Ningyuan Li, Kun Xu, Kun Xu, Hao Jiang, Nan Zhuang, Quzhe Huang, Yang Song, Yadong Mu, and Zhouchen Lin. Pyramidal flow matching for efficient video generative modeling. arXiv preprint arXiv:2410.05954, 2024
-
[12]
From slow bidirectional to fast autoregressive video diffusion models
Tianwei Yin, Qiang Zhang, Richard Zhang, William T Freeman, Fredo Durand, Eli Shechtman, and Xun Huang. From slow bidirectional to fast autoregressive video diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22963–22974, 2025
2025
-
[13]
Gamegen-x: Interactive open-world game video generation
Haoxuan Che, Xuanhua He, Quande Liu, Cheng Jin, and Hao Chen. Gamegen-x: Interactive open-world game video generation. InInternational Conference on Learning Representations, 2025
2025
-
[14]
Causal diffusion transformers for generative modeling.arXiv preprint arXiv:2412.12095, 2024
Chaorui Deng, Deyao Zhu, Kunchang Li, Shi Guang, and Haoqi Fan. Causal diffusion transformers for generative modeling.arXiv preprint arXiv:2412.12095, 2024
-
[15]
Yushu Wu, Yanyu Li, Anil Kag, Ivan Skorokhodov, Willi Menapace, Ke Ma, Arpit Sahni, Ju Hu, Aliaksandr Siarohin, Dhritiman Sagar, et al. Taming diffusion transformer for efficient mobile video generation in seconds.arXiv preprint arXiv:2507.13343, 2025
-
[16]
Causal World Modeling for Robot Control
Lin Li, Qihang Zhang, Yiming Luo, Shuai Yang, Ruilin Wang, Fei Han, Mingrui Yu, Zelin Gao, Nan Xue, Xing Zhu, Yujun Shen, and Yinghao Xu. Causal world modeling for robot control.arXiv preprint arXiv:2601.21998, 2026. 10
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
Genie: Generative interactive environments.Forty-first International Conference on Machine Learning, 2024
Jake Bruce, Michael Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, Yusuf Aytar, Sarah Bechtle, Feryal Behbahani, Stephanie Chan, Nicolas Heess, Lucy Gonzalez, Simon Osindero, Sherjil Ozair, Scott Reed, Jingwei Zhang, Konrad Zolna, Jeff Clune, Nando de Freitas, Satinder Si...
2024
-
[18]
LongLive: Real-time Interactive Long Video Generation
Shuai Yang, Wei Huang, Ruihang Chu, Yicheng Xiao, Yuyang Zhao, Xianbang Wang, Muyang Li, Enze Xie, Yingcong Chen, Yao Lu, Song Han, and Yukang Chen. Longlive: Real-time interactive long video generation.arXiv preprint arXiv:2509.22622, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Rolling Forcing: Autoregressive Long Video Diffusion in Real Time
Kunhao Liu, Wenbo Hu, Jiale Xu, Ying Shan, and Shijian Lu. Rolling forcing: Autoregressive long video diffusion in real time.arXiv preprint arXiv:2509.25161, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Sihui Ji, Xi Chen, Shuai Yang, Xin Tao, Pengfei Wan, and Hengshuang Zhao. Memflow: Flowing adaptive memory for consistent and efficient long video narratives.arXiv preprint arXiv:2512.14699, 2025
-
[21]
arXiv preprint arXiv:2512.04519 , year=
Yifei Yu, Xiaoshan Wu, Xinting Hu, Tao Hu, Yangtian Sun, Xiaoyang Lyu, Bo Wang, Lin Ma, Yuewen Ma, Zhongrui Wang, et al. Videossm: Autoregressive long video generation with hybrid state-space memory. arXiv preprint arXiv:2512.04519, 2025
-
[22]
TinyHistory: Lightweight Video History Embeddings via Two-Stage Context Learning
Lvmin Zhang, Shengqu Cai, Muyang Li, Chong Zeng, Beijia Lu, Anyi Rao, Song Han, Gordon Wetzstein, and Maneesh Agrawala. Pretraining frame preservation in autoregressive video memory compression. arXiv preprint arXiv:2512.23851, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Native sparse attention: Hardware-aligned and natively trainable sparse attention
Jingyang Yuan, Huazuo Gao, Damai Dai, Junyu Luo, Liang Zhao, Zhengyan Zhang, Zhenda Xie, Yuxing Wei, Lean Wang, Zhiping Xiao, et al. Native sparse attention: Hardware-aligned and natively trainable sparse attention. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 23078–23097, 2025
2025
-
[24]
ai, Hansi Teng, Hongyu Jia, Lei Sun, Lingzhi Li, Maolin Li, Mingqiu Tang, Shuai Han, Tianning Zhang, W
Sand. ai, Hansi Teng, Hongyu Jia, Lei Sun, Lingzhi Li, Maolin Li, Mingqiu Tang, Shuai Han, Tianning Zhang, W. Q. Zhang, Weifeng Luo, Xiaoyang Kang, Yuchen Sun, Yue Cao, Yunpeng Huang, Yutong Lin, Yuxin Fang, Zewei Tao, Zheng Zhang, Zhongshu Wang, Zixun Liu, Dai Shi, Guoli Su, Hanwen Sun, Hong Pan, Jie Wang, Jiexin Sheng, Min Cui, Min Hu, Ming Yan, Shuchen...
2025
-
[25]
Skyreels-v2: Infinite-length film generative model, 2025
Guibin Chen, Dixuan Lin, Jiangping Yang, Chunze Lin, Junchen Zhu, Mingyuan Fan, Hao Zhang, Sheng Chen, Zheng Chen, Chengcheng Ma, Weiming Xiong, Wei Wang, Nuo Pang, Kang Kang, Zhiheng Xu, Yuzhe Jin, Yupeng Liang, Yubing Song, Peng Zhao, Boyuan Xu, Di Qiu, Debang Li, Zhengcong Fei, Yang Li, and Yahui Zhou. Skyreels-v2: Infinite-length film generative model, 2025
2025
-
[26]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion.arXiv preprint arXiv:2506.08009, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Self-Forcing++: Towards Minute-Scale High-Quality Video Generation
Justin Cui, Jie Wu, Ming Li, Tao Yang, Xiaojie Li, Rui Wang, Andrew Bai, Yuanhao Ban, and Cho-Jui Hsieh. Self-forcing++: Towards minute-scale high-quality video generation.arXiv preprint arXiv:2510.02283, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Mode seeking meets mean seeking for fast long video generation
Shengqu Cai, Weili Nie, Chao Liu, Julius Berner, Lvmin Zhang, Nanye Ma, Hansheng Chen, Maneesh Agrawala, Leonidas Guibas, Gordon Wetzstein, and Arash Vahdat. Mode seeking meets mean seeking for fast long video generation. InarXiv, 2026
2026
-
[29]
H2o: Heavy-hitter oracle for efficient generative inference of large language models.Advances in Neural Information Processing Systems, 36:34661–34710, 2023
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Ré, Clark Barrett, et al. H2o: Heavy-hitter oracle for efficient generative inference of large language models.Advances in Neural Information Processing Systems, 36:34661–34710, 2023
2023
-
[30]
SnapKV: LLM Knows What You are Looking for Before Generation
Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen. Snapkv: Llm knows what you are looking for before generation.arXiv preprint arXiv:2404.14469, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Mahoney, Yakun Sophia Shao, Kurt Keutzer, and Amir Gholami
Coleman Hooper, Sehoon Kim, Hiva Mohammadzadeh, Michael W. Mahoney, Yakun Sophia Shao, Kurt Keutzer, and Amir Gholami. Kvquant: Towards 10 million context length llm inference with kv cache quantization.Advances in Neural Information Processing Systems, 37, 2024
2024
-
[32]
Efficient Streaming Language Models with Attention Sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks.arXiv preprint arXiv:2309.17453, 2023. 11
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Quant VideoGen: Auto-Regressive Long Video Generation via 2-Bit KV-Cache Quantization
Haocheng Xi, Shuo Yang, Yilong Zhao, Muyang Li, Han Cai, Xingyang Li, Yujun Lin, Zhuoyang Zhang, Jintao Zhang, Xiuyu Li, et al. Quant videogen: Auto-regressive long video generation via 2-bit kv-cache quantization.arXiv preprint arXiv:2602.02958, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[34]
BIFE: Better Interaction, Fewer Errors for Minute-Long Video Generation
Zeyu Zhang, Shuning Chang, Yuanyu He, Yizeng Han, Jiasheng Tang, Fan Wang, and Bohan Zhuang. Blockvid: Block diffusion for high-quality and consistent minute-long video generation.arXiv preprint arXiv:2511.22973, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Efficient autoregressive video diffusion with dummy head
Hang Guo, Zhaoyang Jia, Jiahao Li, Bin Li, Yuanhao Cai, Jiangshan Wang, Yawei Li, and Yan Lu. Efficient autoregressive video diffusion with dummy head.arXiv preprint arXiv:2601.20499, 2026
-
[36]
Past-and future-informed kv cache policy with salience estimation in autoregressive video diffusion
Xu Yang et al. Past- and future-informed kv cache policy with salience estimation in autoregressive video diffusion.arXiv preprint arXiv:2601.21896, 2026
-
[37]
LTX-Video: Realtime Video Latent Diffusion
Yoav HaCohen, Nisan Chiprut, Benny Brazowski, Daniel Shalem, Dudu Moshe, Eitan Richardson, Eran Levin, Guy Shiran, Nir Zabari, Ori Gordon, et al. Ltx-video: Realtime video latent diffusion.arXiv preprint arXiv:2501.00103, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Wan: Open and advanced large-scale video generative models, 2025
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jingren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fang, T...
2025
-
[39]
Vidprom: A million-scale real prompt-gallery dataset for text-to-video diffusion models.Advances in Neural Information Processing Systems, 37:65618–65642, 2024
Wenhao Wang and Yi Yang. Vidprom: A million-scale real prompt-gallery dataset for text-to-video diffusion models.Advances in Neural Information Processing Systems, 37:65618–65642, 2024
2024
-
[40]
VBench++: Comprehensive and versatile benchmark suite for video generative models.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025
Ziqi Huang, Fan Zhang, Xiaojie Xu, Yinan He, Jiashuo Yu, Ziyue Dong, Qianli Ma, Nattapol Chanpaisit, Chenyang Si, Yuming Jiang, Yaohui Wang, Xinyuan Chen, Ying-Cong Chen, Limin Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. VBench++: Comprehensive and versatile benchmark suite for video generative models.IEEE Transactions on Pattern Analysis and Machine Intelli...
2025
-
[41]
Vbench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive benchmark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21807–21818, 2024
2024
-
[42]
Autoregressive Video Generation without Vector Quantization
Haoge Deng, Ting Pan, Haiwen Diao, Zhengxiong Luo, Yufeng Cui, Huchuan Lu, Shiguang Shan, Yonggang Qi, and Xinlong Wang. Autoregressive video generation without vector quantization.arXiv preprint arXiv:2412.14169, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024. 12 Limitation and Broader Impact OmniMem is evaluated on a single open-sourced DiT backbone, Wan2.1-T2V-1.3B, aligned with recent works. This controlled setting helps isolate the effect ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.