Primitive Subspaces Mediate Few-Shot Transfer in VLAs
Pith reviewed 2026-06-28 22:43 UTC · model grok-4.3
The pith
Primitive-aware training of VLAs produces subspaces that mediate few-shot transfer to new tasks with three demonstrations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
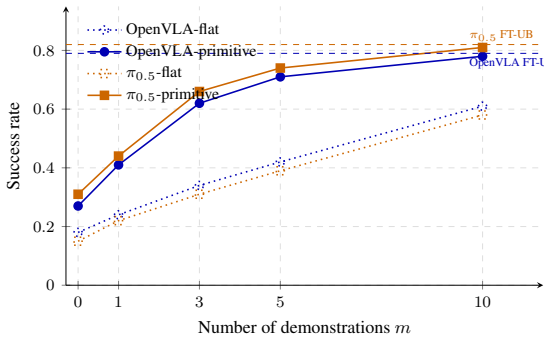
By training two VLA architectures on primitive-segmented episodes rather than flat trajectories, the resulting models exhibit a primitive-decodable subspace that enables them to compose sub-skills for unseen tasks, reaching 78% of fine-tuned performance with m=3 demonstrations compared to m=10 for flat-trained models, with the subspace's causal role confirmed by targeted ablation that degrades transfer while random ablation does not.
What carries the argument
The primitive-decodable subspace of hidden states, which arises from training on segmented trajectories with primitive-specific prompts and encodes composable sub-skills for inference-time composition.
If this is right
- Primitive training produces a 3 times sample efficiency advantage in few-shot transfer that holds across training seeds, model architectures, and two datasets.
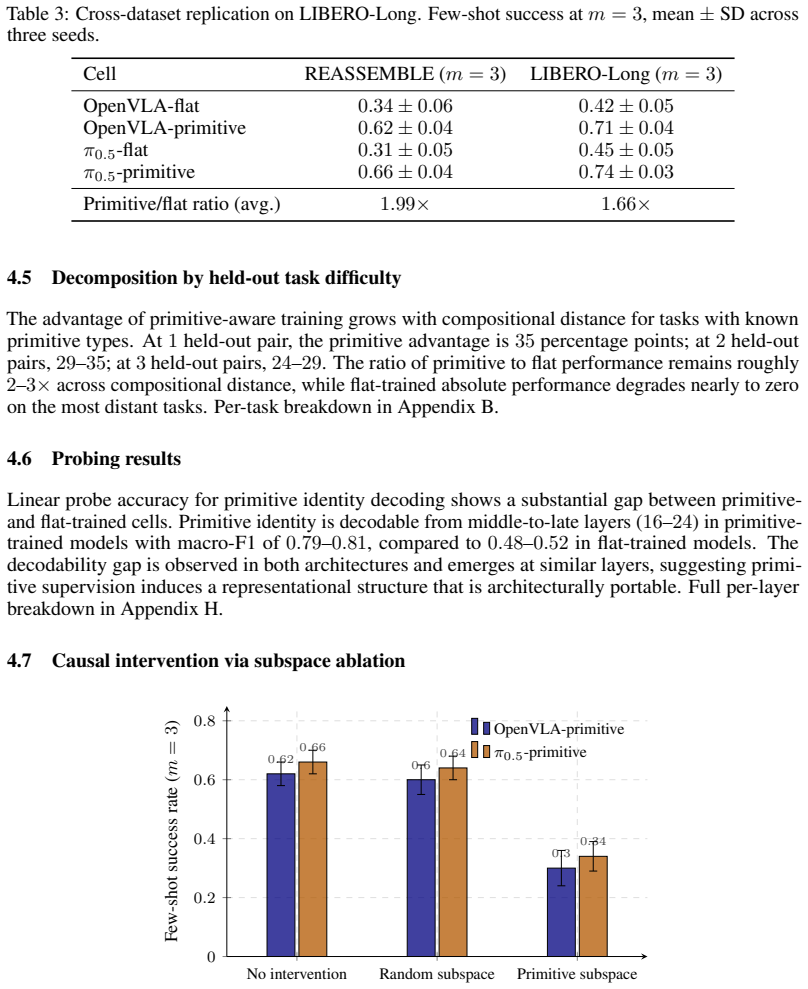
- Ablating the primitive subspace reduces few-shot performance by 32 percentage points while equal-sized random ablations do not.
- The benefit requires both the segmentation and the matching language prompts to induce the transferable representations.
- Standard evaluation of chunked policies can inflate false failure rates due to family-wise error in action gates, which the paper corrects.
Where Pith is reading between the lines
- This suggests that explicit decomposition into primitives during training could be applied to build modular skill representations in other embodied AI settings.
- If the subspace can be identified without labeled primitives, it might allow similar transfer benefits from unsupervised trajectory analysis.
- The approach may reduce the need for full fine-tuning in industrial robot deployment by enabling rapid adaptation through demonstration-based composition.
Load-bearing premise
The primitive segmentation and language prompts must identify generalizable composable sub-skills rather than patterns specific to the training dataset.
What would settle it
If ablating the primitive-decodable subspace produced no greater degradation in few-shot transfer than ablating a random subspace, the claim that the subspace mediates the transfer would be falsified.
Figures

read the original abstract
Deploying vision-language-action (VLA) policies in industrial environments requires the ability to teach new tasks at low cost, a property current VLAs lack, since each new task requires fine-tuning. We investigate whether primitive-aware training produces a transferable artifact: a learned library of sub-skills that can be composed at inference time, conditioned on a small number of demonstrations, to perform tasks the policy was never trained on. We train two VLA architectures with different inductive biases, OpenVLA and $\pi_{0.5}$, on the REASSEMBLE contact-rich assembly dataset under matched LoRA fine-tuning recipes and locked hyperparameters, varying training between flat trajectories and primitive-segmented episodes with primitive-specific language prompts. We hold out 6 object-task combinations from training and evaluate few-shot transfer: models receive $m \in \{0, 1, 3, 5, 10\}$ demonstrations of a held-out task and attempt execution without weight updates. We replicate across three training seeds and validate on a second dataset (LIBERO-Long). Primitive-trained models reach 78% of fine-tuned upper-bound performance with only m=3 demonstrations, while flat-trained models require m=10 demonstrations to reach the same level -- a $3\times$ sample efficiency gap that replicates across seeds, architectures, and datasets. To establish causation, we ablate the primitive-decodable subspace of hidden states and show few-shot transfer degrades by 32 percentage points while ablating a random subspace of equal dimensionality has no effect, indicating primitive representations are causally necessary rather than incidentally correlated with transfer. We identify and correct a methodological pitfall in evaluating chunked policies: family-wise inflation of single-step action-range gates produces order-of-magnitude higher false-failure rates against ground-truth human demonstrations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that training VLAs (OpenVLA and π0.5) on primitive-segmented trajectories with associated language prompts on the REASSEMBLE dataset induces a primitive-decodable subspace in hidden states that mediates few-shot transfer; primitive-trained models reach 78% of the fine-tuned upper bound with m=3 demonstrations while flat-trained models require m=10 (a 3× gap), with the effect replicating across seeds, architectures, and the LIBERO-Long dataset. Causality is supported by an ablation showing a 32-point drop when the primitive subspace is removed versus no effect for a random subspace of equal size. The work also corrects a methodological issue in evaluating chunked policies.
Significance. If the result holds, the work identifies a concrete representational mechanism (primitive subspace) for improving sample efficiency in VLAs without weight updates at test time, which is directly relevant to low-cost deployment in industrial settings. The multi-seed, multi-architecture, and cross-dataset replication plus the targeted ablation (with random-subspace control) are notable strengths that make the empirical finding more robust than typical single-run robotics transfer studies.
major comments (2)
- [Experiments section] Held-out evaluation (Experiments section): the 6 held-out object-task combinations and LIBERO-Long validation demonstrate the sample-efficiency gap, but the manuscript does not report quantitative measures of distributional similarity (e.g., action histogram overlap or prompt embedding distance) between held-out tasks and training primitives; without this, the 3× gap and 32-point ablation effect could reflect improved fitting to shared low-level statistics rather than composition of generalizable sub-skills.
- [Methods] Primitive segmentation procedure (Methods): the abstract and main text provide insufficient detail on the exact segmentation algorithm, criteria for boundary detection, and how primitive-specific prompts are generated; this information is load-bearing for interpreting the flat-vs-primitive contrast as evidence of transferable sub-skills rather than dataset-specific artifacts.
minor comments (2)
- [Evaluation methodology] The correction to the chunked-policy evaluation pitfall is mentioned in the abstract; the main text should include a dedicated subsection or appendix quantifying the false-failure rate before and after the correction and confirming it does not alter the reported transfer gaps.
- [Figures] Figure captions and axis labels for the ablation results should explicitly state the dimensionality of the ablated subspace and the exact method used to identify the primitive-decodable directions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The two major comments identify areas where additional detail and analysis can strengthen the manuscript. We address each below and will revise accordingly.
read point-by-point responses
-
Referee: [Experiments section] Held-out evaluation (Experiments section): the 6 held-out object-task combinations and LIBERO-Long validation demonstrate the sample-efficiency gap, but the manuscript does not report quantitative measures of distributional similarity (e.g., action histogram overlap or prompt embedding distance) between held-out tasks and training primitives; without this, the 3× gap and 32-point ablation effect could reflect improved fitting to shared low-level statistics rather than composition of generalizable sub-skills.
Authors: We agree that explicit distributional similarity metrics would further strengthen the claim that the observed gap reflects sub-skill composition rather than low-level statistics. The existing random-subspace ablation (32-point drop vs. no effect) and cross-architecture/dataset replication already provide evidence against a purely incidental low-level account, but we will add quantitative measures—action histogram overlap and prompt embedding cosine distances—between the held-out tasks and training primitives to the revised Experiments section. revision: yes
-
Referee: [Methods] Primitive segmentation procedure (Methods): the abstract and main text provide insufficient detail on the exact segmentation algorithm, criteria for boundary detection, and how primitive-specific prompts are generated; this information is load-bearing for interpreting the flat-vs-primitive contrast as evidence of transferable sub-skills rather than dataset-specific artifacts.
Authors: We agree that the current description is insufficient for full reproducibility and interpretation. In the revised Methods section we will expand the description to include the precise segmentation algorithm, boundary-detection criteria, and the procedure used to generate primitive-specific language prompts, thereby clarifying how the primitive-aware condition differs from flat training. revision: yes
Circularity Check
No circularity: empirical results from held-out tasks and controlled ablations
full rationale
The paper's claims rest on training VLAs under flat vs. primitive-segmented regimes, measuring few-shot transfer success on explicitly held-out object-task combinations (m=0..10 demonstrations, no weight updates), replicating across seeds/architectures/datasets, and performing subspace ablation vs. random control. These are direct empirical measurements against external ground truth (human demonstrations, held-out tasks), not quantities defined in terms of fitted parameters, self-referential equations, or self-citations. No load-bearing steps reduce by construction to inputs; the derivation chain is self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The REASSEMBLE contact-rich assembly dataset and LIBERO-Long are representative of tasks that would appear in industrial environments.
- domain assumption Primitive segmentation of trajectories produces sub-skills that are both identifiable by language prompts and composable at inference time.
Reference graph
Works this paper leans on
-
[1]
(2022) Do as I can, not as I say: Grounding language in robotic affordances
Ahn, M., Brohan, A., Brown, N., Chebotar, Y ., Cortes, O., David, B., Finn, C., Fu, C., Gopalakrishnan, K., Hausman, K., et al. (2022) Do as I can, not as I say: Grounding language in robotic affordances. Conference on Robot Learning (CoRL)
2022
-
[2]
(2017) Understanding intermediate layers using linear classifier probes.Interna- tional Conference on Learning Representations (ICLR) Workshop
Alain, G., & Bengio, Y . (2017) Understanding intermediate layers using linear classifier probes.Interna- tional Conference on Learning Representations (ICLR) Workshop
2017
-
[3]
(2022) Probing classifiers: Promises, shortcomings, and advances.Computational Linguistics 48(1):207–219
Belinkov, Y . (2022) Probing classifiers: Promises, shortcomings, and advances.Computational Linguistics 48(1):207–219
2022
-
[4]
(2023) HYDRA: Hybrid robot actions for imitation learning.Conference on Robot Learning (CoRL)
Belkhale, S., Cui, Y ., & Sadigh, D. (2023) HYDRA: Hybrid robot actions for imitation learning.Conference on Robot Learning (CoRL)
2023
-
[5]
(2024) RT-H: Action hierarchies using language.Robotics: Science and Systems (RSS)
Belkhale, S., Ding, T., Xiao, T., Sermanet, P., Vuong, Q., Tompson, J., Chebotar, Y ., Dwibedi, D., & Sadigh, D. (2024) RT-H: Action hierarchies using language.Robotics: Science and Systems (RSS)
2024
-
[6]
(2023) LEACE: Perfect linear concept erasure in closed form.Advances in Neural Information Processing Systems (NeurIPS)
Belrose, N., Schneider-Joseph, D., Ravfogel, S., Cotterell, R., Raff, E., & Biderman, S. (2023) LEACE: Perfect linear concept erasure in closed form.Advances in Neural Information Processing Systems (NeurIPS)
2023
-
[7]
(2024) PaliGemma: A versatile 3B VLM for transfer
Beyer, L., Steiner, A., Pinto, A.S., Kolesnikov, A., Wang, X., Salz, D., Neumann, M., Alabdul- mohsin, I., Tschannen, M., Bugliarello, E., et al. (2024) PaliGemma: A versatile 3B VLM for transfer. arXiv:2407.07726
Pith/arXiv arXiv 2024
-
[8]
(2025) π0.5: A vision-language-action model with open-world generalization
Black, K., Brown, N., Darpinian, J., Dhabalia, K., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., Galliker, M.Y ., Ghosh, D., Groom, L., Hausman, K., Ichter, B., Jakubczak, S., Jones, T., Ke, L., LeBlanc, D., Levine, S., et al. (2025) π0.5: A vision-language-action model with open-world generalization. Conference on Robot Learning (CoRL). arXiv:2504.16054
Pith/arXiv arXiv 2025
-
[9]
(2023) RT-2: Vision-language-action models transfer web knowledge to robotic control
Brohan, A., Brown, N., Carbajal, J., Chebotar, Y ., Chen, X., Choromanski, K., Ding, T., Driess, D., Dubey, A., Finn, C., et al. (2023) RT-2: Vision-language-action models transfer web knowledge to robotic control. Conference on Robot Learning (CoRL)
2023
-
[10]
(2024) LeRobot: State- of-the-art machine learning for real-world robotics in PyTorch
Cadene, R., Alibert, S., Soare, A., Gallouedec, Q., Zouitine, A., & Wolf, T. (2024) LeRobot: State- of-the-art machine learning for real-world robotics in PyTorch. https://github.com/huggingface/ lerobot
2024
-
[11]
(2023) Diffusion policy: Visuomotor policy learning via action diffusion.Robotics: Science and Systems (RSS)
Chi, C., Feng, S., Du, Y ., Xu, Z., Cousineau, E., Burchfiel, B., & Song, S. (2023) Diffusion policy: Visuomotor policy learning via action diffusion.Robotics: Science and Systems (RSS)
2023
-
[12]
(2022) LoRA: Low-rank adaptation of large language models.International Conference on Learning Representations (ICLR)
Hu, E.J., Shen, Y ., Wallis, P., Allen-Zhu, Z., Li, Y ., Wang, S., Wang, L., & Chen, W. (2022) LoRA: Low-rank adaptation of large language models.International Conference on Learning Representations (ICLR)
2022
-
[13]
(2024) OpenVLA: An open-source vision-language-action model.Conference on Robot Learning (CoRL)
Kim, M.J., Pertsch, K., Karamcheti, S., Xiao, T., Balakrishna, A., Nair, S., Rafailov, R., Foster, E., Lam, G., Sanketi, P., Vuong, Q., Kollar, T., Burchfiel, B., Tedrake, R., Sadigh, D., Levine, S., Liang, P., & Finn, C. (2024) OpenVLA: An open-source vision-language-action model.Conference on Robot Learning (CoRL). arXiv:2406.09246
Pith/arXiv arXiv 2024
-
[14]
(2023) Code as policies: Language model programs for embodied control.IEEE International Conference on Robotics and Automation (ICRA)
Liang, J., Huang, W., Xia, F., Xu, P., Hausman, K., Ichter, B., Florence, P., & Zeng, A. (2023) Code as policies: Language model programs for embodied control.IEEE International Conference on Robotics and Automation (ICRA)
2023
-
[15]
(2023) Flow matching for generative modeling.International Conference on Learning Representations (ICLR)
Lipman, Y ., Chen, R.T.Q., Ben-Hamu, H., Nickel, M., & Le, M. (2023) Flow matching for generative modeling.International Conference on Learning Representations (ICLR)
2023
-
[16]
(2023) LIBERO: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track
Liu, B., Zhu, Y ., Gao, C., Feng, Y ., Liu, Q., Zhu, Y ., & Stone, P. (2023) LIBERO: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems (NeurIPS) Datasets and Benchmarks Track. 10
2023
-
[17]
(2024) Octo: An open-source generalist robot policy.Robotics: Science and Systems (RSS)
Octo Model Team, Ghosh, D., Walke, H., Pertsch, K., Black, K., Mees, O., Dasari, S., Hejna, J., Kreiman, T., Xu, C., Luo, J., Tan, Y .L., Sanketi, P., Vuong, Q., Xiao, T., Sadigh, D., Finn, C., & Levine, S. (2024) Octo: An open-source generalist robot policy.Robotics: Science and Systems (RSS)
2024
-
[18]
(2023) Open X-Embodiment: Robotic learning datasets and RT-X models
Padalkar, A., Pooley, A., Jain, A., Bewley, A., Herzog, A., Irpan, A., Khazatsky, A., Rai, A., Singh, A., Bro- han, A., et al. (2023) Open X-Embodiment: Robotic learning datasets and RT-X models. arXiv:2310.08864
Pith/arXiv arXiv 2023
-
[19]
(2020) Null it out: Guarding protected at- tributes by iterative nullspace projection.Annual Meeting of the Association for Computational Linguistics (ACL)
Ravfogel, S., Elazar, Y ., Gonen, H., Twiton, M., & Goldberg, Y . (2020) Null it out: Guarding protected at- tributes by iterative nullspace projection.Annual Meeting of the Association for Computational Linguistics (ACL)
2020
-
[20]
(2025) Demonstrating REASSEMBLE: A multimodal dataset for contact-rich robotic assembly and disassembly.Robotics: Science and Systems (RSS)
Sliwowski, D., Jadav, S., Stanovcic, S., Orbik, J., Heidersberger, J., & Lee, D. (2025) Demonstrating REASSEMBLE: A multimodal dataset for contact-rich robotic assembly and disassembly.Robotics: Science and Systems (RSS)
2025
-
[21]
(1999) Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning.Artificial Intelligence112(1–2):181–211
Sutton, R.S., Precup, D., & Singh, S. (1999) Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning.Artificial Intelligence112(1–2):181–211
1999
-
[22]
(2023) Llama 2: Open foundation and fine-tuned chat models
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y ., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al. (2023) Llama 2: Open foundation and fine-tuned chat models. arXiv:2307.09288. A Held-out task definitions The REASSEMBLE training set contains 17 objects across the four primitives (pick, insert, remove, place). Held-out ...
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.