Efficient Diffusion LLMs via Temporal-Spatial Parallel Decoding and Confidence Extrapolation
Pith reviewed 2026-06-28 22:49 UTC · model grok-4.3
The pith
A trajectory-based controller lets diffusion language models stop refining tokens early, reducing steps without hurting quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
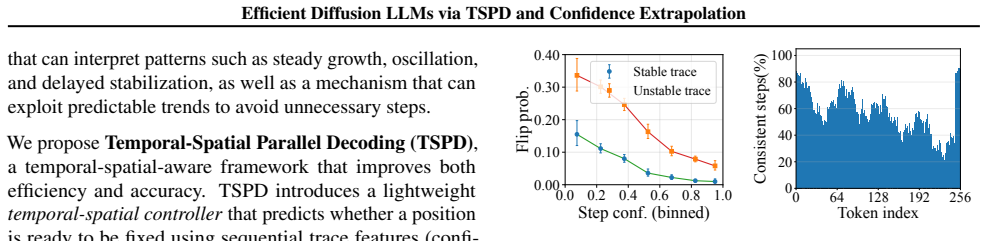
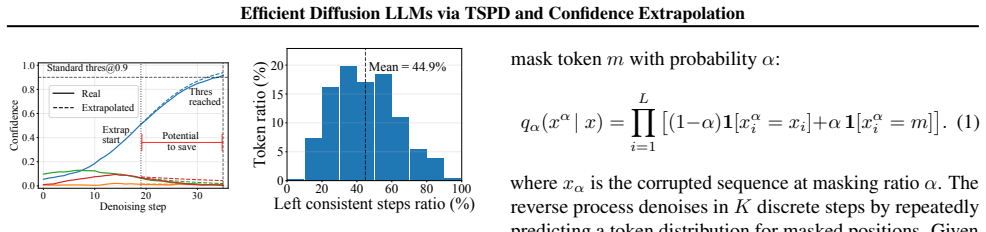
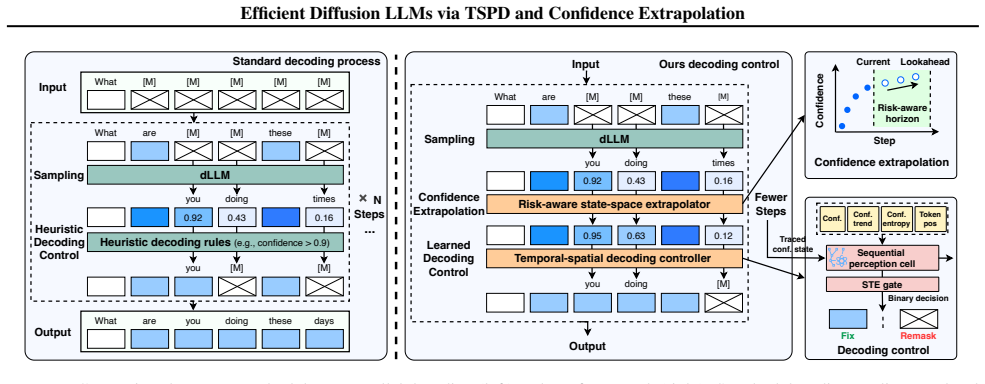
By casting diffusion decoding as a dynamic control problem, the trace-aware decoding framework with Temporal-Spatial Parallel Decoding (TSPD) and Confidence Extrapolation (CE) shows that per-token denoising trajectories supply the key signal for reliable control. TSPD uses a lightweight temporal-spatial controller consuming features including confidence, entropy, and momentum together with token position to decide when a token has converged and can be safely fixed. CE adds a training-free state-space module that forecasts future logit trends with uncertainty to support proactive decisions such as safe look-ahead and targeted stabilization. Together these components reduce unnecessary denoisi
What carries the argument
The temporal-spatial controller in TSPD, which consumes per-token trajectory features including confidence, entropy, and momentum together with token position to decide when a token has converged and can be safely fixed.
Load-bearing premise
That per-token denoising trajectories (confidence, entropy, momentum) plus position provide a reliable signal for safe early fixing that does not degrade final output quality across prompts and tasks.
What would settle it
An experiment on standard benchmarks where the early-fixing decisions from TSPD and CE are applied and the final generated text is compared in quality to full iterative denoising, checking for any drop in metrics such as perplexity or human preference scores.
Figures
read the original abstract
Diffusion-based large language models (dLLMs) support parallel text generation via iterative denoising, yet inference remains latency-heavy because many steps are spent on redundant refinement and repeated remasking of tokens whose final values are already determined. Prior acceleration methods mainly depend on step-local confidence heuristics or fixed schedules, which are sensitive to prompt and task variation and ignore strong positional effects within a sequence. We cast diffusion decoding as a dynamic control problem and show that token-wise denoising trajectories provide the key signal for reliable control. We propose a trace-aware decoding framework with two components. First, Temporal-Spatial Parallel Decoding (TSPD) uses a lightweight temporalspatial controller that consumes per-token trajectory features, including confidence, entropy, and momentum, together with token position, to decide when a token has converged and can be safely fixed. Second, we introduce Confidence Extrapolation (CE), a training-free state-space module that forecasts future logit trends with uncertainty to support proactive decisions, including safe look-ahead and targeted stabilization when trajectories are oscillatory or underconfident. Together, TSPD and CE reduce unnecessary denoising iterations while preserving output quality, and they compose cleanly with system optimizations such as KV caching.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce a trace-aware decoding framework for diffusion-based LLMs consisting of Temporal-Spatial Parallel Decoding (TSPD) and Confidence Extrapolation (CE). TSPD uses a lightweight controller that consumes per-token denoising trajectory features (confidence, entropy, momentum) plus token position to decide when tokens have converged and can be fixed early. CE is a training-free state-space module that forecasts future logit trends with uncertainty to enable proactive decisions such as look-ahead and stabilization. The central claim is that the two components together reduce unnecessary denoising iterations while preserving output quality and compose cleanly with system optimizations such as KV caching.
Significance. If the empirical claims hold, the work could provide a practical, training-free acceleration technique for dLLMs that moves beyond step-local heuristics by exploiting trajectory signals and positional effects. The emphasis on dynamic control and compatibility with existing optimizations would be a useful contribution to inference efficiency in parallel generation models.
major comments (2)
- [Abstract] Abstract: the central claim that TSPD and CE 'reduce unnecessary denoising iterations while preserving output quality' is stated without any quantitative results, ablation data, or error analysis, which is load-bearing for evaluating whether the quality-preservation assumption holds.
- [TSPD description] TSPD description (as summarized): the method assumes per-token trajectory features plus position suffice for safe early fixing, but provides no analysis of token-token correlations in trajectories or tests on dependency-heavy tasks; this directly risks the quality-preservation claim given the joint nature of diffusion denoising over the full sequence.
minor comments (1)
- [Abstract] Abstract: the phrase 'strong positional effects within a sequence' is mentioned but not illustrated with any concrete example of how position enters the controller.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We respond to each major comment below, proposing revisions where appropriate to address the concerns raised.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that TSPD and CE 'reduce unnecessary denoising iterations while preserving output quality' is stated without any quantitative results, ablation data, or error analysis, which is load-bearing for evaluating whether the quality-preservation assumption holds.
Authors: We agree that the abstract would benefit from quantitative support for the central claim. In the revised manuscript we will update the abstract to report key empirical results (e.g., average reduction in denoising steps and corresponding quality metrics such as perplexity or task accuracy) and will explicitly reference the ablations and error analyses already present in the main text. revision: yes
-
Referee: [TSPD description] TSPD description (as summarized): the method assumes per-token trajectory features plus position suffice for safe early fixing, but provides no analysis of token-token correlations in trajectories or tests on dependency-heavy tasks; this directly risks the quality-preservation claim given the joint nature of diffusion denoising over the full sequence.
Authors: While the controller is intentionally lightweight and operates on per-token features, we acknowledge that the manuscript does not contain an explicit analysis of inter-token trajectory correlations or dedicated experiments on strongly dependency-dependent tasks. We will add a short analysis of token-wise correlation statistics and will include results on dependency-heavy tasks (e.g., long-context reasoning) to further support the quality-preservation claim. revision: yes
Circularity Check
No circularity: training-free trajectory-based control with independent signals
full rationale
The paper frames diffusion decoding as a dynamic control problem whose decisions rest on observable per-token features (confidence, entropy, momentum, position) extracted from the denoising process itself. TSPD and CE are explicitly training-free, with no parameters fitted to output quality metrics and no equations that define the control rule in terms of the final result it is meant to predict. No self-citation chains, uniqueness theorems, or ansatzes imported from prior author work are invoked to justify the core mechanism. The derivation therefore remains self-contained against external benchmarks of sequence quality.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Program Synthesis with Large Language Models
URL https://openreview.net/ forum?id=O2WvMkJbws. Austin, J., Johnson, D. D., Ho, J., Tarlow, D., and Van Den Berg, R. Structured denoising diffusion models in discrete state-spaces.Advances in Neural Information Processing Systems, 34:17981–17993, 2021a. Austin, J., Odena, A., Nye, M., Bosma, M., Michalewski, H., Dohan, D., Jiang, E., Cai, C., Terry, M., ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Chen, K., Liu, Z., Tao, X., Liu, H., Fu, X., Zhang, S., Tu, D., Kong, L., Liu, R., and Li, H. Beyond confidence: Adaptive and coherent decoding for diffusion language models.arXiv preprint arXiv:2512.02044, 2025a. Chen, M. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374,
-
[3]
dparallel: Learnable parallel decoding for dllms.arXiv preprint arXiv:2509.26488, 2025b
Chen, Z., Fang, G., Ma, X., Yu, R., and Wang, X. dparallel: Learnable parallel decoding for dllms.arXiv preprint arXiv:2509.26488, 2025b. Cho, K., Van Merri ¨enboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., and Bengio, Y . Learn- ing phrase representations using rnn encoder-decoder for statistical machine translation.arXiv preprint arXiv...
-
[4]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V ., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Scaling Diffusion Language Models via Adaptation from Autoregressive Models
Gong, S., Agarwal, S., Zhang, Y ., Ye, J., Zheng, L., Li, M., An, C., Zhao, P., Bi, W., Han, J., et al. Scaling diffu- sion language models via adaptation from autoregressive models.arXiv preprint arXiv:2410.17891,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Measuring Mathematical Problem Solving With the MATH Dataset
Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., and Steinhardt, J. Measuring math- ematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Hu, Z., Meng, J., Akhauri, Y ., Abdelfattah, M. S., Seo, J.-s., Zhang, Z., and Gupta, U. Accelerating diffusion language model inference via efficient kv caching and guided diffusion.arXiv preprint arXiv:2505.21467,
-
[8]
10 Efficient Diffusion LLMs via TSPD and Confidence Extrapolation Huang, P., Liu, S., Liu, Z., Yan, Y ., Wang, S., Chen, Z., and Xiao, T. Pc-sampler: Position-aware calibration of decoding bias in masked diffusion models.arXiv preprint arXiv:2508.13021,
- [9]
-
[10]
Mercury: Ultra-Fast Language Models Based on Diffusion
Khanna, S., Kharbanda, S., Li, S., Varma, H., Wang, E., Birnbaum, S., Luo, Z., Miraoui, Y ., Palrecha, A., Ermon, S., et al. Mercury: Ultra-fast language models based on diffusion.arXiv preprint arXiv:2506.17298, 1,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Kong, F., Zhang, J., Liu, Y ., Wu, Z., Tian, Y ., Zhou, G., et al. Accelerating diffusion llm inference via local deter- minism propagation.arXiv preprint arXiv:2510.07081,
-
[12]
Diffusion Language Models Know the Answer Before Decoding
Li, P., Zhou, Y ., Muhtar, D., Yin, L., Yan, S., Shen, L., Liang, Y ., V osoughi, S., and Liu, S. Diffusion language models know the answer before decoding.arXiv preprint arXiv:2508.19982,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
dLLM-Cache: Accelerating Diffusion Large Language Models with Adaptive Caching
Liu, Z., Yang, Y ., Zhang, Y ., Chen, J., Zou, C., Wei, Q., Wang, S., and Zhang, L. dllm-cache: Accelerating diffu- sion large language models with adaptive caching.arXiv preprint arXiv:2506.06295,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution
Lou, A., Meng, C., and Ermon, S. Discrete diffusion model- ing by estimating the ratios of the data distribution.arXiv preprint arXiv:2310.16834,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Ma, Y ., Du, L., Wei, L., Chen, K., Xu, Q., Wang, K., Feng, G., Lu, G., Liu, L., Qi, X., et al. dinfer: An efficient in- ference framework for diffusion language models.arXiv preprint arXiv:2510.08666,
-
[16]
Decoding large language diffusion models with foreseeing move- ment.arXiv preprint arXiv:2512.04135,
Mo, Y ., Chen, Q., Li, M., Wei, Z., and Wang, Y . Decoding large language diffusion models with foreseeing move- ment.arXiv preprint arXiv:2512.04135,
-
[17]
Nie, S., Zhu, F., Du, C., Pang, T., Liu, Q., Zeng, G., Lin, M., and Li, C. Scaling up masked diffusion models on text. arXiv preprint arXiv:2410.18514,
-
[18]
Large Language Diffusion Models
Nie, S., Zhu, F., You, Z., Zhang, X., Ou, J., Hu, J., Zhou, J., Lin, Y ., Wen, J.-R., and Li, C. Large language diffusion models.arXiv preprint arXiv:2502.09992,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Autoregressive large language models are computationally universal
Schuurmans, D., Dai, H., and Zanini, F. Autoregressive large language models are computationally universal. arXiv preprint arXiv:2410.03170,
-
[20]
Bidirectional Attention Flow for Machine Comprehension
Seo, M., Kembhavi, A., Farhadi, A., and Hajishirzi, H. Bidirectional attention flow for machine comprehension. arXiv preprint arXiv:1611.01603,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Denoising Diffusion Implicit Models
Song, J., Meng, C., and Ermon, S. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502,
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[22]
CreditDecoding: Accelerating Parallel Decoding in Diffusion Large Language Models with Trace Credit
Wang, K., Jiang, Z., Feng, H., Zhao, W., Liu, L., Li, J., Lan, Z., and Lin, W. Creditdecoding: Accelerating parallel decoding in diffusion large language models with trace credits.arXiv preprint arXiv:2510.06133, 2025a. Wang, W., Fang, B., Jing, C., Shen, Y ., Shen, Y ., Wang, Q., Ouyang, H., Chen, H., and Shen, C. Time is a feature: Ex- ploiting temporal...
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Fast-dllm v2: Efficient block-diffusion llm.arXiv preprint arXiv:2509.26328, 2025a
Wu, C., Zhang, H., Xue, S., Diao, S., Fu, Y ., Liu, Z., Molchanov, P., Luo, P., Han, S., and Xie, E. Fast- dllm v2: Efficient block-diffusion llm.arXiv preprint arXiv:2509.26328, 2025a. Wu, C., Zhang, H., Xue, S., Liu, Z., Diao, S., Zhu, L., Luo, P., Han, S., and Xie, E. Fast-dllm: Training-free acceler- ation of diffusion llm by enabling kv cache and par...
-
[24]
Zhao, S., Gupta, D., Zheng, Q., and Grover, A. d1: Scaling reasoning in diffusion large language models via rein- forcement learning.arXiv preprint arXiv:2504.12216,
-
[25]
Llada-moe: A sparse moe diffusion language model.arXiv preprint arXiv:2509.24389, 2025
Zhu, F., You, Z., Xing, Y ., Huang, Z., Liu, L., Zhuang, Y ., Lu, G., Wang, K., Wang, X., Wei, L., et al. Llada-moe: A sparse moe diffusion language model.arXiv preprint arXiv:2509.24389,
-
[26]
We collect supervision traces using an Extremely Greedy Parallel policy (Bao et al., 2025). For each prompt, we run the base dLLM to completion for K steps and store, for each position i and step t: (i) trace features r(t) i , (ii) the current top-1 token ˆy(t) i , and (iii) the final token ˆy(1) i . We then assign a binary label y(t) i =I ˆy(t) i = ˆy(1)...
2025
-
[27]
δ(t) i ˙δ(t) i # , x (t−1) i =Ax (t) i +ϵ, A=
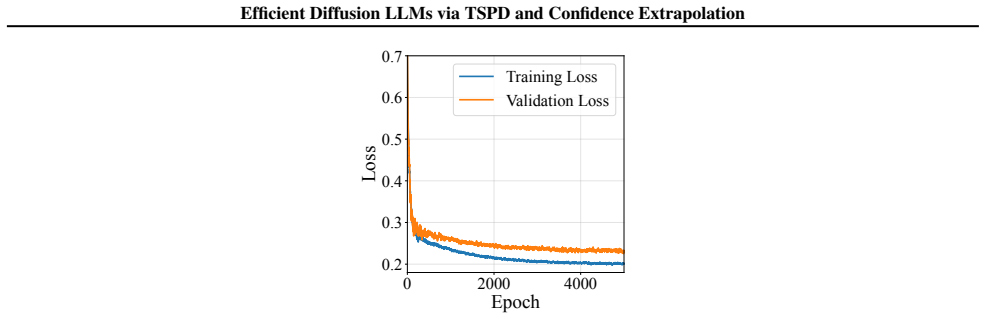
We train TSPD with weighted binary cross-entropy to address label imbalance: L=−w 1ylogπ−w 0(1−y) log(1−π), with w1/w0 set by inverse class frequency on the training split. We use AdamW with learning rate10−3, weight decay 10−2. 13 Efficient Diffusion LLMs via TSPD and Confidence Extrapolation 0 2000 4000 Epoch 0.2 0.3 0.4 0.5 0.6 0.7Loss Training Loss Va...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.