A Reconfigurable Computing In-Memory Macro with Charge-sharing-based Weighted Accumulator
Pith reviewed 2026-06-28 20:42 UTC · model grok-4.3
The pith
A reconfigurable 256x128 SRAM in-memory array integrates a low-overhead ADC, charge-sharing accumulator, and dual-8T bitcells to support 1-7 bit inputs and weights while addressing ADC area, latency, and voltage swing limits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The proposed macro achieves its reconfigurability and performance through an IMADC that occupies only 3 percent area with a 9x improvement over prior IMADCs, a BSCHA that reduces latency by 1.9x relative to PWM and 6.6x relative to bit-slicing, and a dual-8T bitcell that stores ternary weights via a decoupled read path combined with read wordline under-driven cascode, delivering 7x better unit discharge current linearity and 3.5x greater usable read bitline voltage.
What carries the argument
The charge-sharing-based weighted accumulator (BSCHA) paired with the in-memory ADC (IMADC) and the dual-8T bitcell that uses a decoupled read path plus under-driven cascode read wordline to control discharge current.
If this is right
- The array can be programmed for different input, weight, and output precisions without redesigning the core hardware.
- Multi-bit input processing completes in less time than either PWM or bit-slicing approaches.
- The small IMADC leaves most of the die area available for the memory array itself.
- Ternary weights become practical inside a standard SRAM-style cell layout.
- Higher usable read bitline voltage allows more reliable summation of discharge currents across the column.
Where Pith is reading between the lines
- The reconfigurability may reduce the need for separate accelerators tuned to each precision level in a single system.
- The cascode read technique could be examined for compatibility with other bitcell topologies that also suffer from nonlinear discharge.
- If the area and latency numbers scale with array size, larger macros might still keep the same relative overhead.
- The design leaves open the question of how the same techniques perform when the array is embedded inside a larger digital SoC with shared power rails.
Load-bearing premise
The measured area, latency, linearity, and voltage gains remain valid when process variation, temperature, and supply noise are present and without large unstated penalties in power or yield.
What would settle it
Silicon measurements on a fabricated chip that show the IMADC area rising above 3 percent of the macro or the BSCHA latency reduction dropping below the stated 1.9x and 6.6x factors under standard operating conditions.
Figures

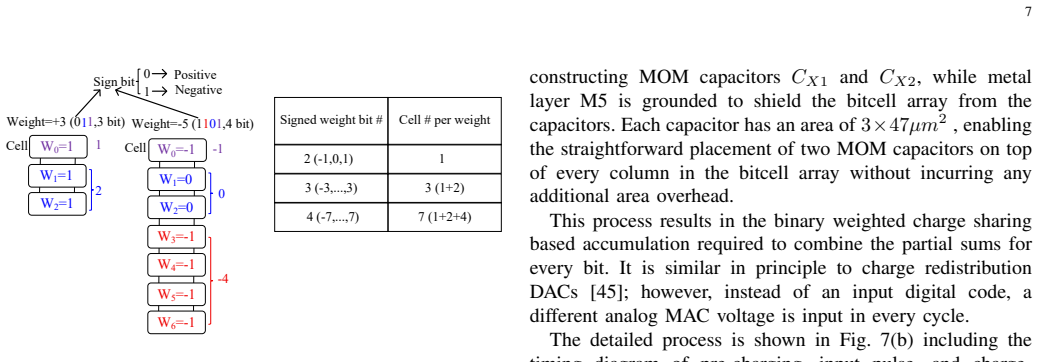

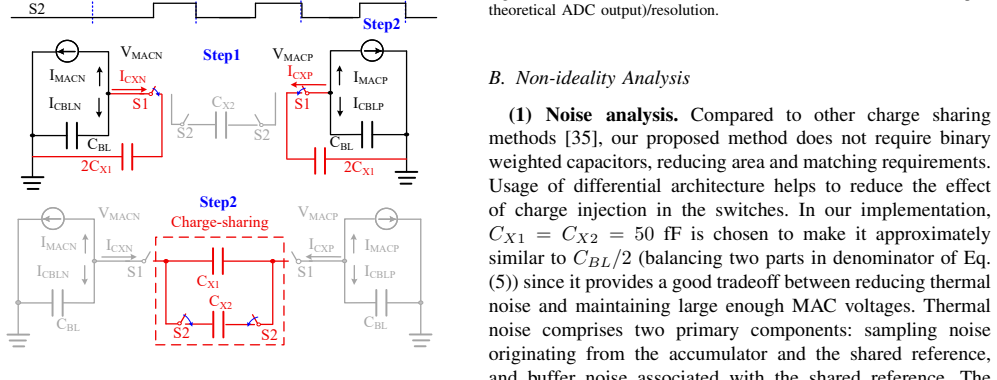

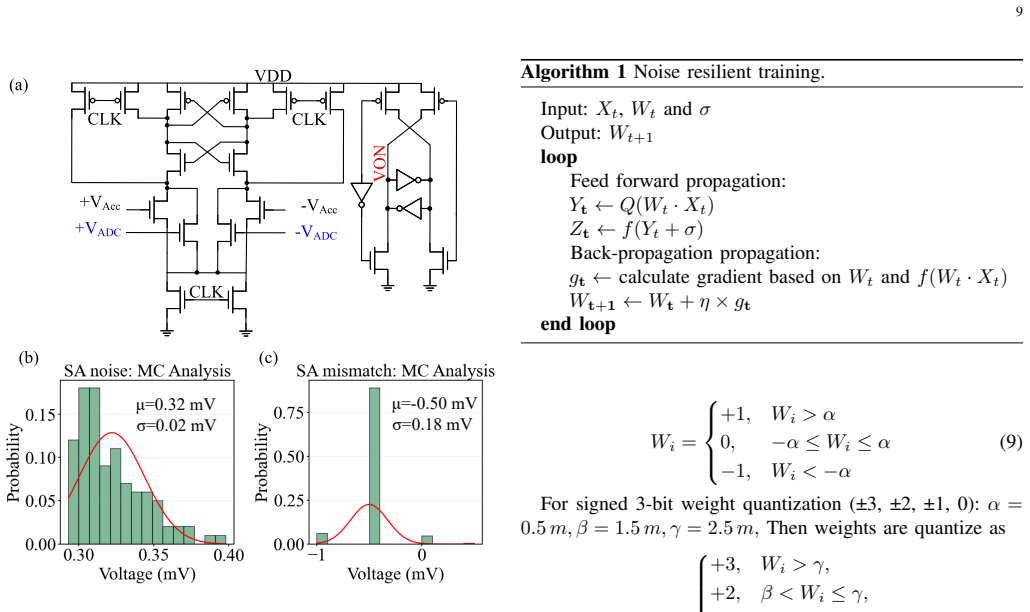







read the original abstract
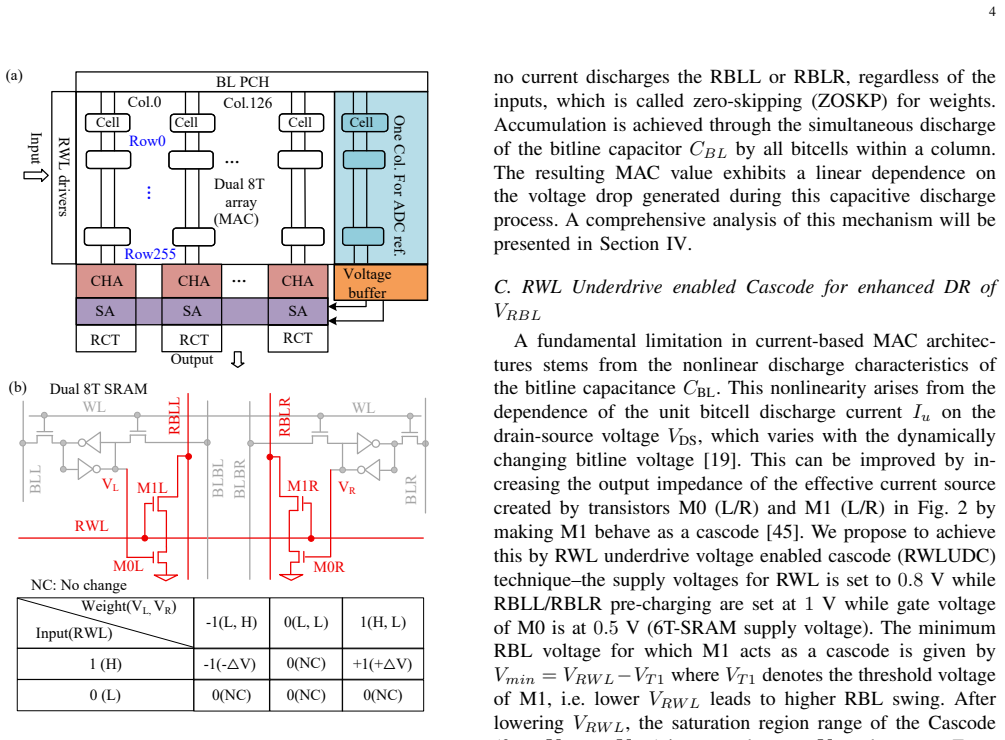
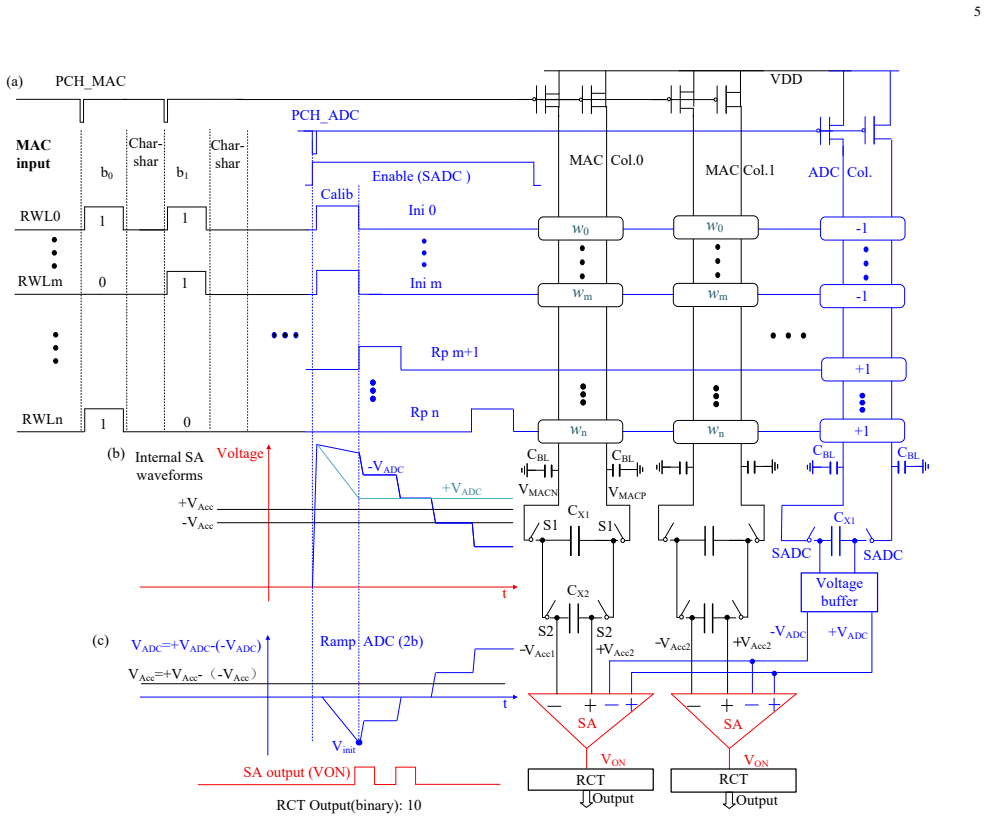
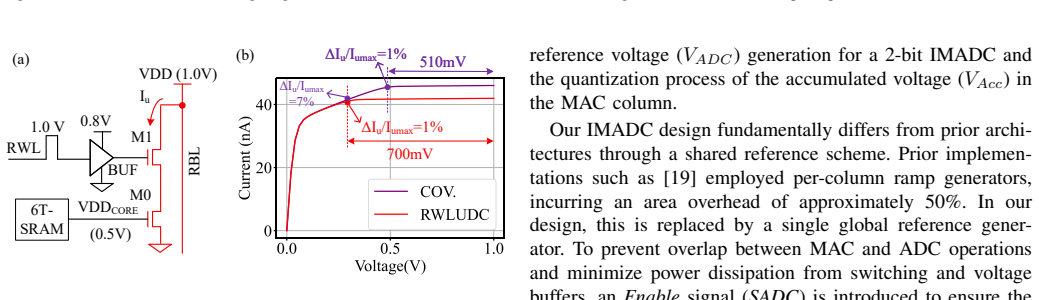
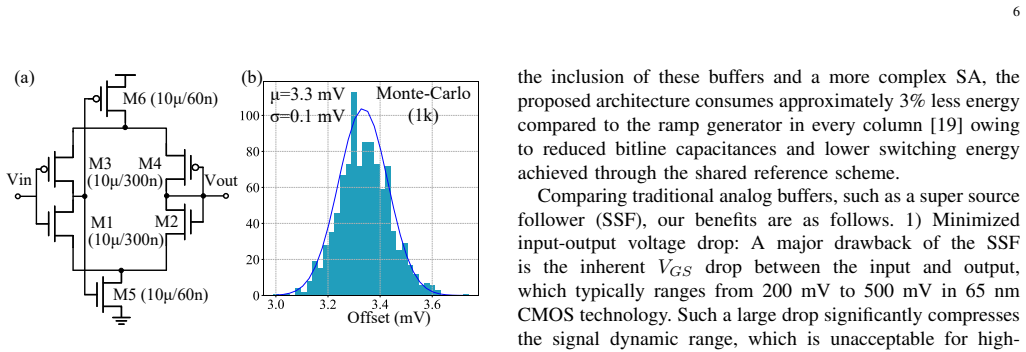
SRAM-based analog computing-in-memory demonstrates outstanding efficiency. However, it faces three critical challenges: significant ADC overhead, high latency for multi-bit inputs, and limited read bitline voltage. To address these issues, this work proposes a multi-bit highly reconfigurable 256x128 in-memory computing array supporting 1-7b input, 2-4b weight, and 1-7b output. Three key innovations are introduced: 1) The IMADC occupies only 3% area overhead, achieving a 9x improvement compared to previous IMADC; 2) The BSCHA reduces latency by 1.9x and 6.6x compared to traditional pulse-width modulation (PWM) and bit-slicing modes, respectively; 3) A dual-8T bitcell enabling ternary weight storage through a decoupled read path, integrated with a read wordline under-driven cascode technique, improves linearity of unit discharge current by 7x and increases the usable read bitline voltage by 3.5x.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a reconfigurable 256x128 SRAM-based analog computing-in-memory array supporting 1-7b inputs, 2-4b weights, and 1-7b outputs. It introduces three main contributions: an IMADC with 3% area overhead achieving 9x improvement over prior designs, a BSCHA reducing latency by 1.9x versus PWM and 6.6x versus bit-slicing modes, and a dual-8T bitcell with decoupled read path plus read-wordline under-driven cascode that improves unit discharge current linearity by 7x and usable RBL voltage range by 3.5x.
Significance. If the reported gains hold, the work meaningfully advances CiM hardware by directly tackling ADC area, multi-bit latency, and RBL voltage limitations through concrete circuit techniques. The explicit quantitative comparisons to established baselines (PWM, bit-slicing, prior IMADCs) and the parameter choices that produce the stated improvements provide clear, falsifiable benchmarks for the community.
minor comments (1)
- [Abstract] Abstract: the quantitative claims would be easier to assess if the abstract briefly indicated the simulation conditions or baseline references used for the 9x, 1.9x, 6.6x, 7x, and 3.5x figures.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our work on the reconfigurable 256x128 CIM array, the IMADC, BSCHA accumulator, and dual-8T bitcell, and for recommending minor revision. The referee's description accurately captures the claimed improvements in ADC area, latency, and RBL linearity/voltage range.
Circularity Check
No significant circularity; hardware claims rest on explicit design comparisons
full rationale
The manuscript describes a reconfigurable SRAM-based in-memory computing macro with three circuit-level innovations (IMADC, BSCHA, dual-8T bitcell with under-driven cascode). All quantitative claims (3% area, 9x improvement, 1.9x/6.6x latency reductions, 7x linearity, 3.5x voltage range) are presented as outcomes of concrete implementation choices and direct comparisons to prior PWM/bit-slicing baselines. No equations, fitted parameters, predictions, or first-principles derivations appear; the work contains no self-definitional loops, fitted-input-as-prediction steps, or load-bearing self-citations that reduce the central claims to their own inputs. The derivation chain is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Towards high-quality and efficient video super-resolution via spatial- temporal data overfitting,
G. Li, J. Ji, M. Qin, W. Niu, B. Ren, F. Afghah, L. Guo, and X. Ma, “Towards high-quality and efficient video super-resolution via spatial- temporal data overfitting,” in2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2023, pp. 10 259– 10 269
2023
-
[2]
Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups,
G. Hinton, L. Deng, D. Yu, G. E. Dahl, A.-r. Mohamed, N. Jaitly, A. Senior, V . Vanhoucke, P. Nguyen, T. N. Sainathet al., “Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups,”IEEE Signal processing magazine, vol. 29, no. 6, pp. 82–97, 2012
2012
-
[3]
Quantifying the knowledge in a DNN to explain knowledge distillation for classification,
Q. Zhang, X. Cheng, Y . Chen, and Z. Rao, “Quantifying the knowledge in a DNN to explain knowledge distillation for classification,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 45, no. 4, pp. 5099–5113, 2022
2022
-
[4]
A 28-nm 64-kb 31.6-TFLOPS/W digital-domain floating-point-computing-unit and double-bit 6T-SRAM computing-in-memory macro for floating-point CNNs,
A. Guo, C. Xi, F. Dong, X. Pu, D. Li, J. Zhang, X. Dong, H. Gao, Y . Zhang, B. Wanget al., “A 28-nm 64-kb 31.6-TFLOPS/W digital-domain floating-point-computing-unit and double-bit 6T-SRAM computing-in-memory macro for floating-point CNNs,”IEEE Journal of Solid-State Circuits, vol. 59, no. 9, pp. 3032–3044, 2024
2024
-
[5]
A 28-nm 50.1-TOPS/W P-8T SRAM compute-in-memory macro design with BL charge-sharing-based in- SRAM DAC/ADC operations,
K. Lee, J. Kim, and J. Park, “A 28-nm 50.1-TOPS/W P-8T SRAM compute-in-memory macro design with BL charge-sharing-based in- SRAM DAC/ADC operations,”IEEE Journal of Solid-State Circuits, vol. 59, no. 6, pp. 1926–1937, 2023
1926
-
[6]
Eyeriss v2: A flexible accelerator for emerging deep neural networks on mobile devices,
Y .-H. Chen, T.-J. Yang, J. Emer, and V . Sze, “Eyeriss v2: A flexible accelerator for emerging deep neural networks on mobile devices,”IEEE Journal on Emerging and Selected Topics in Circuits and Systems, vol. 9, no. 2, pp. 292–308, 2019
2019
-
[7]
Efficient nonlinear function ap- proximation in analog resistive crossbars for recurrent neural networks,
J. Yang, R. Mao, M. Jiang, Y . Cheng, P.-S. V . Sun, S. Dong, G. Pedretti, X. Sheng, J. Ignowski, H. Liet al., “Efficient nonlinear function ap- proximation in analog resistive crossbars for recurrent neural networks,” Nature Communications, vol. 16, no. 1, p. 1136, 2025
2025
-
[8]
A 2941-TOPS/W charge-domain 10T SRAM compute-in-memory for ternary neural network,
S. Cheon, K. Lee, and J. Park, “A 2941-TOPS/W charge-domain 10T SRAM compute-in-memory for ternary neural network,”IEEE Transactions on Circuits and Systems I: Regular Papers, vol. 70, no. 5, pp. 2085–2097, 2023
2085
-
[9]
34.3 a 22nm 64kb lightning-like hybrid computing-in-memory macro with a compressed adder tree and analog- storage quantizers for transformer and cnns,
A. Guo, X. Chen, F. Dong, J. Chen, Z. Yuan, X. Hu, Y . Zhang, J. Zhang, Y . Tang, Z. Zhanget al., “34.3 a 22nm 64kb lightning-like hybrid computing-in-memory macro with a compressed adder tree and analog- storage quantizers for transformer and cnns,” in2024 IEEE International Solid-State Circuits Conference (ISSCC), vol. 67. IEEE, 2024, pp. 570– 572
2024
-
[10]
A 22 nm 10.03-237.99 TOPS/W time-digital-hybrid SRAM compute-in-memory AI accelerator for GNN edge device applications,
C.-J. Jhang, W.-S. Khwa, P.-C. Wu, A. S. Lele, P.-S. Wu, C.-E. Ke, T.-C. Chiu, Y .-C. Hung, W.-T. Hsu, J.-M. Hsuet al., “A 22 nm 10.03-237.99 TOPS/W time-digital-hybrid SRAM compute-in-memory AI accelerator for GNN edge device applications,”IEEE Transactions on Circuits and Systems for Artificial Intelligence, vol. 1, no. 1, pp. 15–25, 2024
2024
-
[11]
A twin-8T SRAM computation-in- memory unit-macro for multibit CNN-based AI edge processors,
X. Si, J.-J. Chen, Y .-N. Tu, W.-H. Huang, J.-H. Wang, Y .-C. Chiu, W.-C. Wei, S.-Y . Wu, X. Sun, R. Liuet al., “A twin-8T SRAM computation-in- memory unit-macro for multibit CNN-based AI edge processors,”IEEE Journal of Solid-State Circuits, vol. 55, no. 1, pp. 189–202, 2019
2019
-
[12]
A 33.6–136.2-TOPS/W Nonlinear Analog Computing-in-Memory Macro for Multi-Bit LSTM Accelerator in 65-nm CMOS,
J. Yang, X. Luo, Y . Ke, Z. Wang, H. Shang, S. Dong, Z. Fu, X. Yang, H. Liu, and A. Basu, “A 33.6–136.2-TOPS/W Nonlinear Analog Computing-in-Memory Macro for Multi-Bit LSTM Accelerator in 65-nm CMOS,”IEEE Journal of Solid-State Circuits, 2025
2025
-
[14]
An overview of computing-in-memory circuits with DRAM and NVM,
S. Kim and H.-J. Yoo, “An overview of computing-in-memory circuits with DRAM and NVM,”IEEE Transactions on Circuits and Systems II: Express Briefs, vol. 71, no. 3, pp. 1626–1631, 2023
2023
-
[15]
In-memory computation of a machine-learning classifier in a standard 6T SRAM array,
J. Zhang, Z. Wang, and N. Verma, “In-memory computation of a machine-learning classifier in a standard 6T SRAM array,”IEEE Journal of Solid-State Circuits, vol. 52, no. 4, pp. 915–924, 2017. 14
2017
-
[16]
Macc-sram: A multistep accumu- lation capacitor-coupling in-memory computing sram macro for deep convolutional neural networks,
B. Zhang, J. Saikia, J. Meng, D. Wang, S. Kwon, S. Myung, H. Kim, S. J. Kim, J.-S. Seo, and M. Seok, “Macc-sram: A multistep accumu- lation capacitor-coupling in-memory computing sram macro for deep convolutional neural networks,”IEEE Journal of Solid-State Circuits, vol. 59, no. 6, pp. 1938–1949, 2023
1938
-
[17]
a 65nm 3T dynamic analog RAM- based computing-in-memory macro and CNN accelerator with retention enhancement, adaptive analog sparsity and 44TOPS/W system energy efficiency,
Z. Chen, X. Chen, and J. Gu, “a 65nm 3T dynamic analog RAM- based computing-in-memory macro and CNN accelerator with retention enhancement, adaptive analog sparsity and 44TOPS/W system energy efficiency,” in2021 IEEE International Solid-State Circuits Conference (ISSCC), vol. 64. IEEE, 2021, pp. 240–242
2021
-
[18]
An overview of processing-in-memory circuits for artificial intelligence and machine learning,
D. Kim, C. Yu, S. Xie, Y . Chen, J.-Y . Kim, B. Kim, J. P. Kulkarni, and T. T.-H. Kim, “An overview of processing-in-memory circuits for artificial intelligence and machine learning,”IEEE Journal on Emerging and Selected Topics in Circuits and Systems, vol. 12, no. 2, pp. 338–353, 2022
2022
-
[19]
SRAM-based in-memory computing macro featuring voltage-mode accumulator and row-by-row ADC for processing neural networks,
J. Mu, H. Kim, and B. Kim, “SRAM-based in-memory computing macro featuring voltage-mode accumulator and row-by-row ADC for processing neural networks,”IEEE Transactions on Circuits and Systems I: Regular Papers, vol. 69, no. 6, pp. 2412–2422, 2022
2022
-
[20]
A 64-tile 2.4- Mb in-memory-computing CNN accelerator employing charge-domain compute,
H. Valavi, P. J. Ramadge, E. Nestler, and N. Verma, “A 64-tile 2.4- Mb in-memory-computing CNN accelerator employing charge-domain compute,”IEEE Journal of Solid-State Circuits, vol. 54, no. 6, pp. 1789– 1799, 2019
2019
-
[21]
A 65-nm 8T SRAM compute-in-memory macro with column ADCs for processing neural networks,
C. Yu, T. Yoo, K. T. C. Chai, T. T.-H. Kim, and B. Kim, “A 65-nm 8T SRAM compute-in-memory macro with column ADCs for processing neural networks,”IEEE Journal of Solid-State Circuits, vol. 57, no. 11, pp. 3466–3476, 2022
2022
-
[22]
Neuro-CIM: ADC-less neuromorphic computing-in-memory processor with operation gating/stopping and digital–analog networks,
S. Kim, S. Kim, S. Um, S. Kim, K. Kim, and H.-J. Yoo, “Neuro-CIM: ADC-less neuromorphic computing-in-memory processor with operation gating/stopping and digital–analog networks,”IEEE Journal of Solid- State Circuits, vol. 58, no. 10, pp. 2931–2945, 2023
2023
-
[23]
High Energy-efficiency and Low latency In-Memory Computing using Analog Accumulator and In-Memory ADC with shared References,
J. Yang, S. Dong, Z. Fu, H. Shang, and A. Basu, “High Energy-efficiency and Low latency In-Memory Computing using Analog Accumulator and In-Memory ADC with shared References,” in2025 62nd ACM/IEEE Design Automation Conference (DAC). IEEE, 2025, pp. 1–7
2025
-
[24]
A 1-16b reconfig- urable 80Kb 7T SRAM-based digital near-memory computing macro for processing neural networks,
H. Kim, J. Mu, C. Yu, T. T.-H. Kim, and B. Kim, “A 1-16b reconfig- urable 80Kb 7T SRAM-based digital near-memory computing macro for processing neural networks,”IEEE Transactions on Circuits and Systems I: Regular Papers, vol. 70, no. 4, pp. 1580–1590, 2023
2023
-
[25]
SRAM with In-Memory Inference and 90% Bitline Activity Reduction for Always-On Sensing with 109 TOPS/mm 2 and 749-1,459 TOPS/W in 28nm,
V . K. Rajanna, S. Taneja, and M. Alioto, “SRAM with In-Memory Inference and 90% Bitline Activity Reduction for Always-On Sensing with 109 TOPS/mm 2 and 749-1,459 TOPS/W in 28nm,” inESSCIRC 2021-IEEE 47th European Solid State Circuits Conference (ESSCIRC). IEEE, 2021, pp. 127–130
2021
-
[26]
Process-Variation-Aware In-Memory Computation With Improved Linearity Using On-Chip Configurable Current-Steering Thermometric DAC,
P. K. Saragada and B. P. Das, “Process-Variation-Aware In-Memory Computation With Improved Linearity Using On-Chip Configurable Current-Steering Thermometric DAC,”IEEE Transactions on Circuits and Systems I: Regular Papers, 2024
2024
-
[27]
Impact of aging and process variability on SRAM-based in-memory computing architectures,
J. B. Shaik, X. Guo, and S. Singhal, “Impact of aging and process variability on SRAM-based in-memory computing architectures,”IEEE Transactions on Circuits and Systems I: Regular Papers, 2024
2024
-
[28]
A Dual 7T SRAM-Based Zero-Skipping Compute-In-Memory Macro With 1-6b Binary Searching ADCs for Processing Quantized Neural Networks,
C. Yu, H. Jiang, J. Mu, K. T. C. Chai, T. T.-H. Kim, and B. Kim, “A Dual 7T SRAM-Based Zero-Skipping Compute-In-Memory Macro With 1-6b Binary Searching ADCs for Processing Quantized Neural Networks,” IEEE Transactions on Circuits and Systems I: Regular Papers, 2024
2024
-
[29]
34.9 a flash-SRAM-ADC-fused plastic computing-in- memory macro for learning in neural networks in a standard 14nm FinFET process,
L. Wang, W. Li, Z. Zhou, H. Gao, Z. Li, W. Ye, H. Hu, J. Liu, J. Yue, J. Yanget al., “34.9 a flash-SRAM-ADC-fused plastic computing-in- memory macro for learning in neural networks in a standard 14nm FinFET process,” in2024 IEEE International Solid-State Circuits Con- ference (ISSCC), vol. 67. IEEE, 2024, pp. 582–584
2024
-
[30]
Topkima-Former: Low-Energy, Low-Latency Inference for Transformers Using Top-k In-Memory ADC,
S. Dong, J. Yang, X. Peng, H. Shang, Y . Ke, X. Yang, H. Liu, and A. Basu, “Topkima-Former: Low-Energy, Low-Latency Inference for Transformers Using Top-k In-Memory ADC,”IEEE Transactions on Circuits and Systems I: Regular Papers, 2025
2025
-
[31]
Hybrid SRAM/ROM Compute-in-Memory Architecture for High Task-Level Energy Efficiency in Transformer Models With 8928-kb/mm 2 Density in 28nm CMOS,
G. Yin, Y . Chen, M. Lee, X. Du, Y . Ke, W. Tang, Z. Chen, M. Zhou, J. Yue, H. Yanget al., “Hybrid SRAM/ROM Compute-in-Memory Architecture for High Task-Level Energy Efficiency in Transformer Models With 8928-kb/mm 2 Density in 28nm CMOS,”IEEE Journal of Solid-State Circuits, 2025
2025
-
[32]
Cramming More Weight Data Onto Compute-in-Memory Macros for High Task-Level Energy Efficiency Using Custom ROM With 3984-kb/mm 2 Density in 65-nm CMOS,
G. Yin, Y . Chen, M. Zhou, W. Tang, M. Lee, Z. Yang, T. Liao, X. Du, V . Narayanan, H. Yanget al., “Cramming More Weight Data Onto Compute-in-Memory Macros for High Task-Level Energy Efficiency Using Custom ROM With 3984-kb/mm 2 Density in 65-nm CMOS,” IEEE Journal of Solid-State Circuits, vol. 59, no. 6, pp. 1912–1925, 2023
1912
-
[33]
A charge domain SRAM compute-in-memory macro with C-2C ladder- based 8-bit MAC unit in 22-nm FinFET process for edge inference,
H. Wang, R. Liu, R. Dorrance, D. Dasalukunte, D. Lake, and B. Carlton, “A charge domain SRAM compute-in-memory macro with C-2C ladder- based 8-bit MAC unit in 22-nm FinFET process for edge inference,” IEEE Journal of Solid-State Circuits, vol. 58, no. 4, pp. 1037–1050, 2023
2023
-
[34]
In-memory computing in emerging memory technologies for machine learning: An overview,
K. Roy, I. Chakraborty, M. Ali, A. Ankit, and A. Agrawal, “In-memory computing in emerging memory technologies for machine learning: An overview,” in2020 57th ACM/IEEE Design Automation Conference (DAC). IEEE, 2020, pp. 1–6
2020
-
[35]
A charge-sharing based 8T SRAM In-Memory Computing for edge DNN acceleration,
K. Lee, S. Cheon, J. Jo, W. Choi, and J. Park, “A charge-sharing based 8T SRAM In-Memory Computing for edge DNN acceleration,” in2021 58th ACM/IEEE Design Automation Conference (DAC). IEEE, 2021, pp. 739–744
2021
-
[36]
C3SRAM: An in-memory- computing SRAM macro based on robust capacitive coupling computing mechanism,
Z. Jiang, S. Yin, J.-S. Seo, and M. Seok, “C3SRAM: An in-memory- computing SRAM macro based on robust capacitive coupling computing mechanism,”IEEE Journal of Solid-State Circuits, vol. 55, no. 7, pp. 1888–1897, 2020
2020
-
[37]
Cadc: Crossbar- aware dendritic convolution for efficient in-memory computing,
S. Dong, J. Yang, Y . Ke, H. Shang, and A. Basu, “Cadc: Crossbar- aware dendritic convolution for efficient in-memory computing,” in2026 31st Asia and South Pacific Design Automation Conference (ASP-DAC). IEEE, 2026, pp. 667–673
2026
-
[38]
A 351 TOPS/W and 372.4 GOPS compute-in-memory SRAM macro in 7nm FinFET CMOS for machine- learning applications,
Q. Dong, M. E. Sinangil, B. Erbagci, D. Sun, W.-S. Khwa, H.-J. Liao, Y . Wang, and J. Chang, “A 351 TOPS/W and 372.4 GOPS compute-in-memory SRAM macro in 7nm FinFET CMOS for machine- learning applications,” in2020 IEEE International Solid-State Circuits Conference-(ISSCC). IEEE, 2020, pp. 242–244
2020
-
[39]
A 42 pJ/decision 3.12 TOPS/W robust in-memory machine learning classifier with on-chip training,
S. K. Gonugondla, M. Kang, and N. Shanbhag, “A 42 pJ/decision 3.12 TOPS/W robust in-memory machine learning classifier with on-chip training,” in2018 IEEE International Solid-State Circuits Conference- (ISSCC). IEEE, 2018, pp. 490–492
2018
-
[40]
Challenges and trends of SRAM-based computing-in-memory for AI edge devices,
C.-J. Jhang, C.-X. Xue, J.-M. Hung, F.-C. Chang, and M.-F. Chang, “Challenges and trends of SRAM-based computing-in-memory for AI edge devices,”IEEE Transactions on Circuits and Systems I: Regular Papers, vol. 68, no. 5, pp. 1773–1786, 2021
2021
-
[41]
F. Li, B. Liu, X. Wang, B. Zhang, and J. Yan, “Ternary weight networks,” arXiv preprint arXiv:1605.04711, 2016
-
[42]
Mitigating methodology of hardware non-ideal characteristics for non-volatile memory based neural networks,
L. Han, P. Huang, Y . Wang, Z. Zhou, H. Yang, Y . Chen, X. Liu, and J. Kang, “Mitigating methodology of hardware non-ideal characteristics for non-volatile memory based neural networks,”Science China Infor- mation Sciences, vol. 68, no. 2, p. 122403, 2025
2025
-
[43]
XNOR-SRAM: In-memory computing SRAM macro for binary/ternary deep neural networks,
S. Yin, Z. Jiang, J.-S. Seo, and M. Seok, “XNOR-SRAM: In-memory computing SRAM macro for binary/ternary deep neural networks,”IEEE Journal of Solid-State Circuits, vol. 55, no. 6, pp. 1733–1743, 2020
2020
-
[44]
A backpropagation with gradient accumulation algorithm capable of tolerating memristor non-idealities for training memristive neural networks,
S. Dong, Y . Chen, Z. Fan, K. Chen, M. Qin, M. Zeng, X. Lu, G. Zhou, X. Gao, and J.-M. Liu, “A backpropagation with gradient accumulation algorithm capable of tolerating memristor non-idealities for training memristive neural networks,”Neurocomputing, vol. 494, pp. 89–103, 2022
2022
-
[45]
E and Holberg, D.,CMOS Analog Circuit Design
Allen, P. E and Holberg, D.,CMOS Analog Circuit Design. Oxford University Press, 2011
2011
-
[46]
Pseudo asynchronous level crossing ADC for ECG signal acquisition,
T. Marisa, T. Niederhauser, A. Haeberlin, R. A. Wildhaber, R. V ogel, J. Goette, and M. Jacomet, “Pseudo asynchronous level crossing ADC for ECG signal acquisition,”IEEE transactions on biomedical circuits and systems, vol. 11, no. 2, pp. 267–278, 2017
2017
-
[47]
Graph attention networks,
P. Velickovic, G. Cucurull, A. Casanova, A. Romero, P. Lio, Y . Bengio et al., “Graph attention networks,”stat, vol. 1050, no. 20, pp. 10–48 550, 2017
2017
-
[48]
A 40nm analog-input ADC- free compute-in-memory RRAM macro with pulse-width modulation between sub-arrays,
H. Jiang, W. Li, S. Huang, and S. Yu, “A 40nm analog-input ADC- free compute-in-memory RRAM macro with pulse-width modulation between sub-arrays,” in2022 IEEE Symposium on VLSI Technology and Circuits (VLSI Technology and Circuits). IEEE, 2022, pp. 266–267
2022
-
[49]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gellyet al., “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[50]
Rethinking the inception architecture for computer vision,
C. Szegedy, V . Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna, “Rethinking the inception architecture for computer vision,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 2818–2826
2016
-
[51]
Benchmarking monolithic 3D integration for compute-in- memory accelerators: overcoming ADC bottlenecks and maintaining scalability to 7nm or beyond,
X. Peng, W. Chakraborty, A. Kaul, W. Shim, M. S. Bakir, S. Datta, and S. Yu, “Benchmarking monolithic 3D integration for compute-in- memory accelerators: overcoming ADC bottlenecks and maintaining scalability to 7nm or beyond,” in2020 IEEE International Electron Devices Meeting (IEDM). IEEE, 2020, pp. 30–4
2020
-
[52]
ENNA: An efficient neural network accelerator design based on ADC-free compute-in-memory subarrays,
H. Jiang, S. Huang, W. Li, and S. Yu, “ENNA: An efficient neural network accelerator design based on ADC-free compute-in-memory subarrays,”IEEE Transactions on Circuits and Systems I: Regular Papers, vol. 70, no. 1, pp. 353–363, 2022. 15
2022
-
[53]
NeuC-CIM: A 1.3 pJ/SOP Neuromorphic Charge-Domain Compute-in-Memory Macro for Spiking Neural Net- work,
H. Fu, H. Zheng, Y . Zhou, X. Wen, Y . Chen, H. Ren, X. Lin, Z. Zong, L. Wu, and B. Cheng, “NeuC-CIM: A 1.3 pJ/SOP Neuromorphic Charge-Domain Compute-in-Memory Macro for Spiking Neural Net- work,” in2025 Symposium on VLSI Technology and Circuits (VLSI Technology and Circuits). IEEE, 2025, pp. 1–3
2025
-
[54]
A 5.1 pJ/neuron 127.3 us/inference RNN- based speech recognition processor using 16 computing-in-memory SRAM macros in 65nm CMOS,
R. Guo, Y . Liu, S. Zheng, S.-Y . Wu, P. Ouyang, W.-S. Khwa, X. Chen, J.- J. Chen, X. Li, L. Liuet al., “A 5.1 pJ/neuron 127.3 us/inference RNN- based speech recognition processor using 16 computing-in-memory SRAM macros in 65nm CMOS,” in2019 Symposium on VLSI Circuits. IEEE, 2019, pp. C120–C121
2019
-
[55]
DNN+ NeuroSim V2. 0: An end-to-end benchmarking framework for compute-in-memory accelerators for on-chip training,
X. Peng, S. Huang, H. Jiang, A. Lu, and S. Yu, “DNN+ NeuroSim V2. 0: An end-to-end benchmarking framework for compute-in-memory accelerators for on-chip training,”IEEE Transactions on Computer- Aided Design of Integrated Circuits and Systems, vol. 40, no. 11, pp. 2306–2319, 2020
2020
-
[56]
ISAAC: A convolutional neural network accelerator with in-situ analog arithmetic in crossbars,
A. Shafiee, A. Nag, N. Muralimanohar, R. Balasubramonian, J. P. Stra- chan, M. Hu, R. S. Williams, and V . Srikumar, “ISAAC: A convolutional neural network accelerator with in-situ analog arithmetic in crossbars,” ACM SIGARCH Computer Architecture News, vol. 44, no. 3, pp. 14–26, 2016
2016
-
[57]
PUMA: A programmable ultra-efficient memristor-based accelerator for machine learning inference,
A. Ankit, I. E. Hajj, S. R. Chalamalasetti, G. Ndu, M. Foltin, R. S. Williams, P. Faraboschi, W.-m. W. Hwu, J. P. Strachan, K. Royet al., “PUMA: A programmable ultra-efficient memristor-based accelerator for machine learning inference,” inProceedings of the twenty-fourth international conference on architectural support for programming languages and opera...
2019
-
[58]
FPSA: A full system stack solution for reconfigurable ReRAM- based NN accelerator architecture,
Y . Ji, Y . Zhang, X. Xie, S. Li, P. Wang, X. Hu, Y . Zhang, and Y . Xie, “FPSA: A full system stack solution for reconfigurable ReRAM- based NN accelerator architecture,” inProceedings of the Twenty-Fourth International Conference on Architectural Support for Programming Languages and Operating Systems, 2019, pp. 733–747
2019
-
[59]
A 40-nm MLC-RRAM compute-in-memory macro with sparsity control, on-chip write-verify, and temperature-independent ADC references,
W. Li, X. Sun, S. Huang, H. Jiang, and S. Yu, “A 40-nm MLC-RRAM compute-in-memory macro with sparsity control, on-chip write-verify, and temperature-independent ADC references,”IEEE Journal of Solid- State Circuits, vol. 57, no. 9, pp. 2868–2877, 2022
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.