Planner-Centric Reinforcement Learning for Deep Research with Structure-Aware Reward
Pith reviewed 2026-06-28 22:28 UTC · model grok-4.3
The pith
DecomposeR represents research plans as typed DAGs and trains planner then answerer stages separately to improve long-form LLM performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
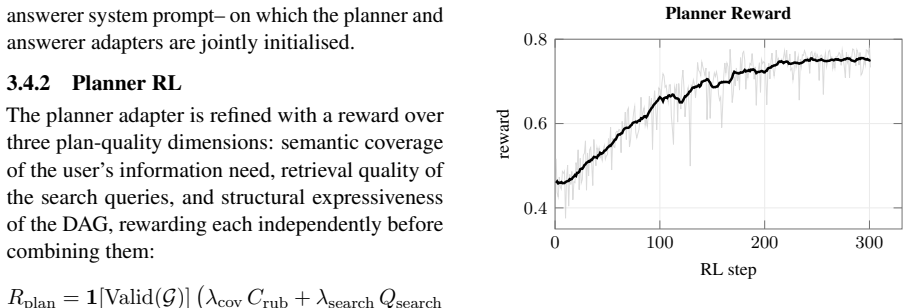
DecomposeR trains a Qwen3-8B model by first using planner reinforcement learning to learn graph structure and query decomposition on typed DAG representations of research plans, then using answerer reinforcement learning to optimize branch-level execution and final synthesis conditioned on those plans. By assigning rewards directly to explicit planner tokens and structured DAG components instead of end-to-end flat trajectories, the method enables finer-grained optimization of planning while reducing ambiguity, resulting in 5.1-8.0 point gains over comparable open baselines on popular long-form benchmarks.
What carries the argument
Typed directed acyclic graphs (DAGs) that represent research plans, enabling explicit structure for reward assignment and two-stage separation of planner RL from answerer RL.
If this is right
- Planner RL stage improves query decomposition and graph structure learning before answerer training begins.
- Rewards on structured plan components yield better credit assignment for planning decisions than end-to-end optimization.
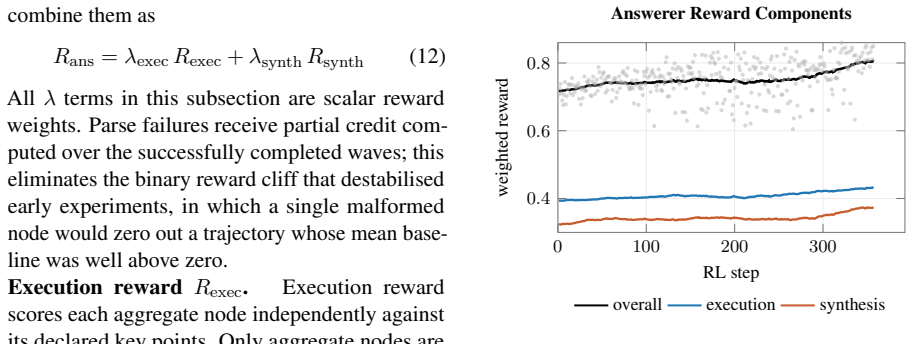
- Conditioning answerer RL on learned plans improves branch-level execution and final synthesis quality.
- The resulting DecomposeR-8B model outperforms strong open baselines by 5.1-8.0 points on long-form benchmarks.
Where Pith is reading between the lines
- The DAG representation could make intermediate plans more inspectable and editable by users or downstream systems.
- The two-stage separation might scale to other multi-step agent tasks that currently suffer from poor planning credit assignment.
- Extending the typed DAG nodes to include explicit evidence retrieval actions could further tighten the planning-execution loop.
Load-bearing premise
Assigning rewards to explicit planner tokens and structured DAG components produces finer-grained optimization of planning and reduces end-to-end training ambiguity compared to flat trajectories.
What would settle it
Running the same Qwen3-8B base model on the same long-form benchmarks with standard monolithic trajectory RL instead of the two-stage DAG planner approach and measuring whether the 5.1-8.0 point gap disappears or reverses.
Figures


















read the original abstract
Deep research tasks require LLMs to plan what to investigate, retrieve evidence, and synthesize long-form answers across multiple branches of inquiry. Existing training paradigms either rely on short-form verifiable QA as a proxy or optimize monolithic long trajectories, which makes planning and execution difficult to disentangle and yields weak credit assignment for the planning process. We propose DecomposeR, a planner-centric deep research framework that represents research plans as typed directed acyclic graphs (DAGs), allowing planning to be made explicit, structured, and rewardable. We train a Qwen3-8B model in two stages: planner reinforcement learning (RL) first learns graph structure and query decomposition to improve research planning, and answerer reinforcement learning (RL) then learns branch-level execution and final synthesis conditioned on the learned plan. By assigning rewards to explicit planner tokens and structured components rather than to a flat trajectory, DecomposeR enables finer-grained optimization of planning while reducing the ambiguity of end-to-end training. Experiments show that DecomposeR-8B improves over strong comparable open baselines by 5.1-8.0 points on popular long-form benchmarks due to improved planning and answering capabilities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DecomposeR, a planner-centric RL framework for deep research tasks. Research plans are represented as typed DAGs to make planning explicit and rewardable. A Qwen3-8B model is trained in two stages: planner RL to learn graph structure and decomposition, followed by answerer RL for branch execution and synthesis. The abstract claims this yields 5.1-8.0 point gains over strong open baselines on long-form benchmarks by providing finer-grained credit assignment via rewards on planner tokens and DAG components rather than flat trajectories.
Significance. If the performance delta can be isolated to the typed-DAG reward structure, the approach would provide a concrete mechanism for disentangling planning from execution in long-horizon LLM RL, potentially improving optimization of multi-branch research workflows.
major comments (1)
- [Abstract] Abstract: the central claim attributes the 5.1-8.0 point gains specifically to 'assigning rewards to explicit planner tokens and structured DAG components rather than to a flat trajectory.' This requires a control experiment (two-stage flat-trajectory RL vs. two-stage typed-DAG RL) to isolate the contribution of the DAG representation and component-level rewards from the mere separation into planner and answerer stages. No such ablation is described, so the core premise remains unverified and the attribution is not load-bearing.
minor comments (1)
- The abstract supplies no details on reward formulations, baseline descriptions, statistical significance, or experimental setup, making it impossible to assess whether reported gains are reproducible or attributable to the claimed mechanism.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on strengthening the attribution of our results. We respond to the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim attributes the 5.1-8.0 point gains specifically to 'assigning rewards to explicit planner tokens and structured DAG components rather than to a flat trajectory.' This requires a control experiment (two-stage flat-trajectory RL vs. two-stage typed-DAG RL) to isolate the contribution of the DAG representation and component-level rewards from the mere separation into planner and answerer stages. No such ablation is described, so the core premise remains unverified and the attribution is not load-bearing.
Authors: We agree that the manuscript does not contain a direct ablation isolating two-stage flat-trajectory RL from two-stage typed-DAG RL, and that such a control would more rigorously separate the contribution of the DAG structure and component-level rewards from the planner-answerer stage separation alone. Our existing experiments compare DecomposeR against strong open baselines that use neither the two-stage approach nor typed DAGs, and the framework is explicitly designed to enable rewards on planner tokens and DAG components. To address the referee's concern, we will add the requested control experiment in the revised manuscript. revision: yes
Circularity Check
No circularity: empirical method with benchmark deltas
full rationale
The paper describes a two-stage RL training procedure on typed DAG plans and reports 5.1-8.0 point gains on long-form benchmarks. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described method. The central claim is an observed performance delta from an explicit training recipe; it does not reduce to a definitional identity or to a prior result supplied only by the same authors. The absence of any load-bearing derivation chain makes the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Rahul K. Arora, Jason Wei, Rebecca Soskin Hicks, Preston Bowman, Joaquin Quiñonero-Candela, Foivos Tsimpourlas, Michael Sharman, Meghan Shah, Andrea Vallone, Alex Beutel, Johannes Heidecke, and Karan Singhal. 2025. https://arxiv.org/abs/2505.08775 Healthbench: Evaluating large language models towards improved human health . Preprint, arXiv:2505.08775
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Akari Asai, Jacqueline He, Rulin Shao, Weijia Shi, Amanpreet Singh, Joseph Chee Chang, Kyle Lo, Luca Soldaini, Sergey Feldman, Mike D'arcy, David Wadden, Matt Latzke, Minyang Tian, Pan Ji, Shengyan Liu, Hao Tong, Bohao Wu, Yanyu Xiong, Luke Zettlemoyer, and 6 others. 2024 a . https://arxiv.org/abs/2411.14199 Openscholar: Synthesizing scientific literature...
-
[3]
Akari Asai, Zeqiu Wu, Yizhong Wang, Avi Sil, and Hannaneh Hajishirzi. 2024 b . Self-rag: Learning to retrieve, generate, and critique through self-reflection. In International conference on learning representations, volume 2024, pages 9112--9141
2024
-
[4]
Mingyang Chen, Linzhuang Sun, Tianpeng Li, Haoze Sun, Chenzheng Zhu, Haofen Wang, Jeff Pan, Wen Zhang, Huajun Chen, Fan Yang, and 1 others. 2026. Learning to reason with search for llms via reinforcement learning. Advances in Neural Information Processing Systems, 38:85287--85307
2026
-
[5]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, and 1 others. 2025. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Mingxuan Du, Benfeng Xu, Chiwei Zhu, Xiaorui Wang, and Zhendong Mao. 2025. Deepresearch bench: A comprehensive benchmark for deep research agents. arXiv preprint arXiv:2506.11763
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, and 1 others. 2025. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. https://arxiv.org/abs/2106.09685 Lora: Low-rank adaptation of large language models . Preprint, arXiv:2106.09685
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[9]
Zhengbao Jiang, Frank F Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. 2023. Active retrieval augmented generation. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 7969--7992
2023
-
[10]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan O. Arik, Dong Wang, Hamed Zamani, and Jiawei Han. 2025. https://arxiv.org/abs/2503.09516 Search-r1: Training llms to reason and leverage search engines with reinforcement learning . In Proceedings of the Conference on Language Modeling
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Tushar Khot, Harsh Trivedi, Matthew Finlayson, Yao Fu, Kyle Richardson, Peter Clark, and Ashish Sabharwal. 2023. Decomposed prompting: A modular approach for solving complex tasks. In International Conference on Learning Representations
2023
-
[12]
Efficient Memory Management for Large Language Model Serving with PagedAttention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. 2023. https://arxiv.org/abs/2309.06180 Efficient memory management for large language model serving with pagedattention . Preprint, arXiv:2309.06180
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Kuan Li, Zhongwang Zhang, Huifeng Yin, Liwen Zhang, Litu Ou, Jialong Wu, Wenbiao Yin, Baixuan Li, Zhengwei Tao, Xinyu Wang, Weizhou Shen, Junkai Zhang, Dingchu Zhang, Xixi Wu, Yong Jiang, Ming Yan, Pengjun Xie, Fei Huang, and Jingren Zhou. 2025. https://arxiv.org/abs/2507.02592 Websailor: Navigating super-human reasoning for web agent . Preprint, arXiv:2507.02592
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Xiaoxi Li, Jiajie Jin, Guanting Dong, Hongjin Qian, Yongkang Wu, Ji-Rong Wen, Yutao Zhu, and Zhicheng Dou. 2026 a . Webthinker: Empowering large reasoning models with deep research capability. Advances in Neural Information Processing Systems, 38:120091--120131
2026
-
[15]
Zijian Li, Xin Guan, Bo Zhang, Shen Huang, Houquan Zhou, Shaopeng Lai, Ming Yan, Yong Jiang, Pengjun Xie, Fei Huang, Jun Zhang, and Jingren Zhou. 2026 b . https://openreview.net/forum?id=MtNCJjlrKt Webweaver: Structuring web-scale evidence with dynamic outlines for open-ended deep research . In The Fourteenth International Conference on Learning Representations
2026
-
[16]
Junteng Liu, Yunji Li, Chi Zhang, Jingyang Li, Aili Chen, Ke Ji, Weiyu Cheng, Zijia Wu, Chengyu Du, Qidi Xu, Jiayuan Song, Zhengmao Zhu, Wenhu Chen, Pengyu Zhao, and Junxian He. 2025. https://arxiv.org/abs/2509.06501 Webexplorer: Explore and evolve for training long-horizon web agents . Preprint, arXiv:2509.06501
-
[17]
Jianbiao Mei, Tao Hu, Daocheng Fu, Licheng Wen, Xuemeng Yang, Rong Wu, Pinlong Cai, Xinyu Cai, Xing Gao, Yu Yang, Chengjun Xie, Botian Shi, Yong Liu, and Yu Qiao. 2025. https://arxiv.org/abs/2505.16582 O ^2 -searcher: A searching-based agent model for open-domain open-ended question answering . Preprint, arXiv:2505.16582
-
[18]
OpenAI . 2025. Introducing deep research. https://openai.com/index/introducing-deep-research/
2025
-
[19]
Perplexity Team . 2025. Introducing perplexity deep research. https://www.perplexity.ai/hub/blog/introducing-perplexity-deep-research
2025
-
[20]
Nils Reimers and Iryna Gurevych. 2019. https://arxiv.org/abs/1908.10084 Sentence-bert: Sentence embeddings using siamese bert-networks . In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[21]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. 2024. https://arxiv.org/abs/2402.03300 Deepseekmath: Pushing the limits of mathematical reasoning in open language models . Preprint, arXiv:2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. 2025. https://doi.org/10.1145/3689031.3696075 Hybridflow: A flexible and efficient rlhf framework . In Proceedings of the Twentieth European Conference on Computer Systems, EuroSys ’25, page 1279–1297. ACM
-
[23]
Amanpreet Singh, Joseph Chee Chang, Dany Haddad, Aakanksha Naik, Jena D Hwang, Rodney Kinney, Daniel S Weld, Doug Downey, and Sergey Feldman. 2025. AI2 scholar QA : Organized literature synthesis with attribution. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations), pages 513--523
2025
-
[24]
Huatong Song, Jinhao Jiang, Yingqian Min, Jie Chen, Zhipeng Chen, Wayne Xin Zhao, Lei Fang, and Ji-Rong Wen. 2025. https://arxiv.org/abs/2503.05592 R1-searcher: Incentivizing the search capability in llms via reinforcement learning . Preprint, arXiv:2503.05592
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. 2023. Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, pages 10014--10037
2023
-
[26]
Lei Wang, Wanyu Xu, Yihuai Lan, Zhiqiang Hu, Yunshi Lan, Roy Ka-Wei Lee, and Ee-Peng Lim. 2023. https://doi.org/10.18653/v1/2023.acl-long.147 Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models . In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)
-
[27]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, and 41 others. 2025. https://arxiv.org/abs/2505.09388 Qwen3 technical report . Preprint, arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. 2023. https://openreview.net/forum?id=WE_vluYUL-X React: Synergizing reasoning and acting in language models . In The Eleventh International Conference on Learning Representations
2023
- [29]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.