PRISM: Progressive Reasoning through Iterative Slot Memory for Vision
Pith reviewed 2026-06-28 23:08 UTC · model grok-4.3
The pith
PRISM refines object-centric slots iteratively using learned memory to recover missing visual evidence across image scales.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
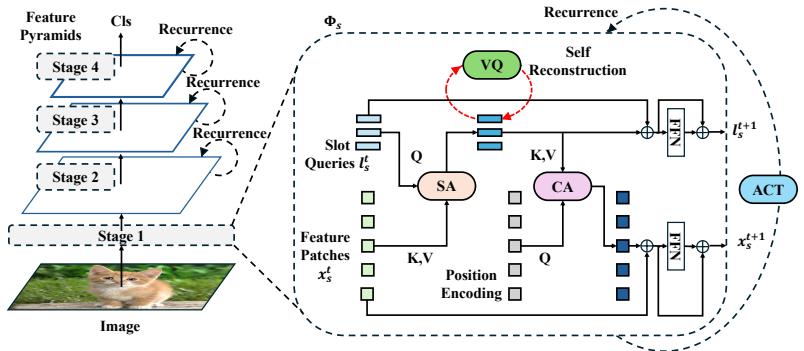
PRISM groups visual features into object-centric representations, retrieves relevant patterns from a learned memory, and iteratively refines the representation to resolve ambiguity and recover missing information, with this organize-recall-refine process operating recurrently across multiple scales in a pyramid vision architecture.
What carries the argument
The organize-recall-refine process that recurrently updates object-centric slots by retrieving from learned memory inside a multi-scale pyramid.
If this is right
- Progressive refinement across scales yields better handling of ambiguity than a single feed-forward pass.
- Object-centric slots plus memory retrieval support recovery of missing evidence under occlusion.
- The same architecture maintains competitive accuracy on clean versions of classification, detection, and segmentation tasks.
Where Pith is reading between the lines
- The same iterative slot-and-memory pattern could be tested on video or 3-D data where partial views are common.
- If memory retrieval proves key, replacing the learned memory with an external database might further improve recovery of rare patterns.
Load-bearing premise
That grouping features into object-centric slots, recalling from memory, and refining them iteratively will produce representation improvements that translate into measurable robustness gains on incomplete observations.
What would settle it
A controlled test on occluded versions of standard benchmarks in which PRISM shows no statistically significant accuracy or robustness lift over single-pass baselines of comparable size.
Figures

read the original abstract
Modern vision models process images in a single feed-forward pass, which limits their ability to recover missing evidence or refine uncertain representations under incomplete observations. Inspired by the iterative nature of human perception, we introduce PRISM (Progressive Reasoning through Iterative Slot Memory), a pyramid vision architecture that reasons over images through iterative refinement. At a high level, PRISM groups visual features into object-centric representations, retrieves relevant patterns from a learned memory, and iteratively refines the representation to resolve ambiguity and recover missing information. This organize-recall-refine process operates recurrently across multiple scales, enabling progressive improvement of visual representations. Across standard vision tasks, including image classification, object detection, and semantic segmentation, PRISM achieves competitive performance while demonstrating improved robustness under incomplete observations such as occlusion. These results suggest that iterative reasoning with structured representations and memory is a promising direction for building more resilient and adaptive vision models. Source code and models will be released.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PRISM, a pyramid vision architecture that performs progressive reasoning via an iterative organize-recall-refine process. Visual features are grouped into object-centric slots, relevant patterns are retrieved from a learned memory, and representations are refined recurrently across multiple scales to recover missing information under incomplete observations. The authors claim that this yields competitive performance on image classification, object detection, and semantic segmentation while improving robustness to occlusion.
Significance. If the iterative refinement loop can be shown to produce robustness gains beyond what is achievable by non-iterative slot-based models of equivalent capacity, the work would offer a concrete mechanism for building more resilient vision systems. The planned release of code and models is a clear strength for reproducibility.
major comments (2)
- [Experiments / Results sections] The central robustness claim requires evidence that the recurrent organize-recall-refine loop itself (rather than slot decomposition or memory retrieval alone) drives the gains. No ablation that disables iteration while preserving slots, memory, and parameter count is described; without it the causal attribution remains untested.
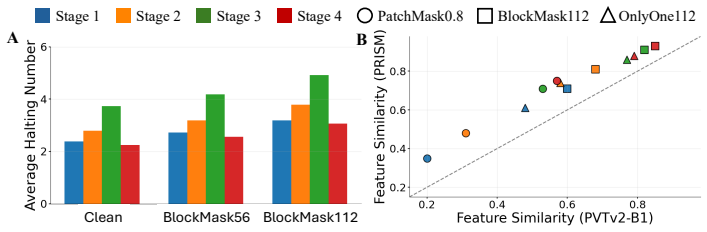
- [Results / Evaluation protocol] Table or figure reporting occlusion robustness should include per-occlusion-level deltas together with controls for total parameters and training compute against non-iterative baselines; the current description of results does not isolate these factors.
minor comments (1)
- [Method / Architecture description] A concise pseudocode block or expanded diagram would clarify the exact recurrence schedule across pyramid levels and the memory update rule.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on strengthening the causal evidence for our iterative refinement mechanism. We will revise the manuscript to incorporate the requested ablations and controls.
read point-by-point responses
-
Referee: [Experiments / Results sections] The central robustness claim requires evidence that the recurrent organize-recall-refine loop itself (rather than slot decomposition or memory retrieval alone) drives the gains. No ablation that disables iteration while preserving slots, memory, and parameter count is described; without it the causal attribution remains untested.
Authors: We agree that isolating the contribution of the recurrent loop is essential. In the revised manuscript we will add an ablation that disables the iterative organize-recall-refine process (single forward pass only) while preserving slot decomposition, memory retrieval, and total parameter count by adjusting the capacity of non-iterative components. Results will be reported on the same occlusion benchmarks to directly quantify the incremental benefit of iteration. revision: yes
-
Referee: [Results / Evaluation protocol] Table or figure reporting occlusion robustness should include per-occlusion-level deltas together with controls for total parameters and training compute against non-iterative baselines; the current description of results does not isolate these factors.
Authors: We will update the occlusion robustness tables and figures to report per-occlusion-level performance deltas. We will also explicitly document and enforce controls for total parameter count and training compute when comparing against non-iterative baselines, adding these details to the experimental protocol section. revision: yes
Circularity Check
No derivation chain or equations present; architecture description only
full rationale
The provided abstract and context contain no equations, derivations, fitted parameters, or first-principles claims that could reduce to inputs by construction. The paper describes an iterative slot-memory architecture and reports empirical results on vision tasks, but offers no mathematical steps, predictions, or self-citations that match any of the enumerated circularity patterns. Without a derivation chain to inspect, no circularity is identifiable.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A. Ali, H. Touvron, M. Caron, P. Bojanowski, M. Douze, A. Joulin, I. Laptev, N. Neverova, G. Synnaeve, J. Verbeek, et al. Xcit: Cross-covariance image transformers.Advances in neural information processing systems, 34:20014–20027, 2021
2021
-
[2]
Banino, J
A. Banino, J. Balaguer, and C. Blundell. Pondernet: Learning to ponder. InAdvances in Neural Information Processing Systems, 2021
2021
-
[3]
Bomatter, M
P. Bomatter, M. Zhang, D. Karev, S. Madan, C. Tseng, and G. Kreiman. When pigs fly: Contextual reasoning in synthetic and natural scenes. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 255–264, 2021
2021
-
[4]
C. P. Burgess, L. Matthey, N. Watters, R. Kabra, I. Higgins, M. Botvinick, and A. Lerchner. Monet: Unsupervised scene decomposition and representation. InInternational Conference on Learning Representations, 2019
2019
- [5]
-
[6]
D. Chi, H. Kim, Y . Oh, Y . Kim, D. Lee, D. Jo, J. Kim, J. Baek, S. Ahn, and S. Kim. Slot-mllm: Object-centric visual tokenization for multimodal llm.arXiv preprint arXiv:2505.17726, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Dehghani, S
M. Dehghani, S. Gouws, O. Vinyals, J. Uszkoreit, and Ł. Kaiser. Universal transformers. In International Conference on Learning Representations, 2019
2019
-
[8]
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009
2009
-
[9]
M. Ding, B. Xiao, N. Codella, P. Luo, J. Wang, and L. Yuan. Davit: Dual attention vision transformers. InEuropean conference on computer vision, pages 74–92. Springer, 2022
2022
-
[10]
Elbayad, J
M. Elbayad, J. Gu, E. Grave, and M. Auli. Depth-adaptive transformer. InInternational Conference on Learning Representations, 2020
2020
-
[11]
Esser, R
P. Esser, R. Rombach, and B. Ommer. Taming transformers for high-resolution image synthesis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12873–12883, 2021
2021
-
[12]
Grainger, T
R. Grainger, T. Paniagua, X. Song, N. Cuntoor, M. W. Lee, and T. Wu. Paca-vit: learning patch-to-cluster attention in vision transformers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18568–18578, 2023
2023
-
[13]
A. Graves. Adaptive computation time for recurrent neural networks.arXiv preprint arXiv:1603.08983, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[14]
Greff, R
K. Greff, R. L. Kaufman, R. Kabra, N. Watters, C. Burgess, D. Zoran, L. Matthey, M. Botvinick, and A. Lerchner. Multi-object representation learning with iterative variational inference. In Proceedings of the 36th International Conference on Machine Learning, pages 2424–2433, 2019. 10
2019
-
[15]
S. Han, Z. Wang, and M. Zhang. Flow snapshot neurons in action: Deep neural networks generalize to biological motion perception.Advances in Neural Information Processing Systems, 37:53732–53763, 2024
2024
-
[16]
Hiller, K
M. Hiller, K. A. Ehinger, and T. Drummond. Perceiving longer sequences with bi-directional cross-attention transformers.Advances in Neural Information Processing Systems, 37:94097–94129, 2024
2024
- [17]
-
[18]
Kar and J
K. Kar and J. J. DiCarlo. Fast recurrent processing via ventrolateral prefrontal cortex is needed by the primate ventral stream for robust core visual object recognition.Neuron, 109(1):164–176, 2021
2021
-
[19]
T. C. Kietzmann, C. J. Spoerer, L. K. Sörensen, R. M. Cichy, O. Hauk, and N. Kriegeskorte. Recurrence is required to capture the representational dynamics of the human visual system. Proceedings of the National Academy of Sciences, 116(43):21854–21863, 2019
2019
-
[20]
T. Kipf, G. F. Elsayed, A. Mahendran, A. Stone, S. Sabour, G. Heigold, R. Jonschkowski, A. Dosovitskiy, and K. Greff. Conditional object-centric learning from video. InInternational Conference on Learning Representations, 2022
2022
-
[21]
Kubilius, M
J. Kubilius, M. Schrimpf, K. Kar, R. Rajalingham, H. Hong, N. Majaj, E. Issa, P. Bashivan, J. Prescott-Roy, K. Schmidt, et al. Brain-like object recognition with high-performing shallow recurrent anns.Advances in neural information processing systems, 32, 2019
2019
-
[22]
D. Lee, C. Kim, S. Kim, M. Cho, and W.-S. Han. Autoregressive image generation using residual quantization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11523–11532, 2022
2022
-
[23]
Q. Lin, J. Zhang, Y .-S. Ong, and M. Zhang. Make me happier: Evoking emotions through image diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 16367–16376, 2025
2025
- [24]
-
[25]
Y . Liu, F. Meng, J. Zhou, Y . Chen, and J. Xu. Faster depth-adaptive transformers. InProceedings of the AAAI Conference on Artificial Intelligence, 2021
2021
-
[26]
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo. Swin transformer: Hierarchical vision transformer using shifted windows. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 10012–10022, 2021
2021
-
[27]
Locatello, D
F. Locatello, D. Weissenborn, T. Unterthiner, A. Mahendran, G. Heigold, J. Uszkoreit, A. Dosovitskiy, and T. Kipf. Object-centric learning with slot attention. InAdvances in Neural Information Processing Systems, volume 33, pages 11525–11538, 2020
2020
- [28]
-
[29]
Takida, W.-H
Y . Takida, W.-H. Liao, C. Takahashi, T. Shibuya, and Y . Mitsufuji. Hq-vae: Hierarchical discrete representation learning with variational bayes.Transactions on Machine Learning Research, 2024
2024
-
[30]
M. B. Talbot, R. Zawar, R. Badkundri, M. Zhang, and G. Kreiman. Tuned compositional feature replays for efficient stream learning.IEEE Transactions on Neural Networks and Learning Systems, 36(2):3300–3314, 2023
2023
-
[31]
H. Tang, M. Schrimpf, W. Lotter, C. Moerman, A. Paredes, J. Ortega Caro, W. Hardesty, D. Cox, and G. Kreiman. Recurrent computations for visual pattern completion.Proceedings of the National Academy of Sciences, 115(35):8835–8840, 2018. 11
2018
-
[32]
Touvron, M
H. Touvron, M. Cord, M. Douze, F. Massa, A. Sablayrolles, and H. Jégou. Training data-efficient image transformers & distillation through attention. InInternational conference on machine learning, pages 10347–10357. PMLR, 2021
2021
-
[33]
van den Oord, O
A. van den Oord, O. Vinyals, and K. Kavukcuoglu. Neural discrete representation learning. In Advances in Neural Information Processing Systems, volume 30, 2017
2017
-
[34]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[35]
W. Wang, E. Xie, X. Li, D.-P. Fan, K. Song, D. Liang, T. Lu, P. Luo, and L. Shao. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 568–578, 2021
2021
-
[36]
W. Wang, E. Xie, X. Li, D.-P. Fan, K. Song, D. Liang, T. Lu, P. Luo, and L. Shao. Pvt v2: Improved baselines with pyramid vision transformer.Computational Visual Media, 8(3):415–424, 2022
2022
- [37]
-
[38]
Z. Wang, M. Z. Shou, and M. Zhang. Object-centric learning with cyclic walks between parts and whole.Advances in Neural Information Processing Systems, 36:9388–9408, 2023
2023
- [39]
-
[40]
Z. Wu, N. Dvornik, K. Greff, T. Kipf, and A. Garg. Slotformer: Unsupervised visual dynamics simulation with object-centric models. InInternational Conference on Learning Representations, 2023
2023
-
[41]
H. Yin, A. Vahdat, J. M. Alvarez, A. Mallya, J. Kautz, and P. Molchanov. A-vit: Adaptive tokens for efficient vision transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022
2022
-
[42]
L. Yu, J. Lezama, N. B. Gundavarapu, L. Versari, K. Sohn, D. Minnen, Y . Cheng, A. Gupta, X. Gu, A. G. Hauptmann, B. Gong, M.-H. Yang, I. Essa, D. A. Ross, and L. Jiang. Language model beats diffusion – tokenizer is key to visual generation. InInternational Conference on Learning Representations, 2024
2024
-
[43]
Zadaianchuk, M
A. Zadaianchuk, M. Kleindessner, Y . Zhu, F. Locatello, T. Brox, and G. Martius. Object-centric learning for real-world videos by predicting temporal feature similarities. InAdvances in Neural Information Processing Systems, volume 36, pages 12710–12730, 2023
2023
-
[44]
Zhang, C
M. Zhang, C. Tseng, and G. Kreiman. Putting visual object recognition in context. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12985–12994, 2020
2020
-
[45]
R. Zhao, V . Wang, J. Kannala, and J. Pajarinen. Vector-quantized vision foundation models for object-centric learning. InProceedings of the ACM International Conference on Multimedia, 2025
2025
-
[46]
L. Zhu, X. Wang, Z. Ke, W. Zhang, and R. W. Lau. Biformer: Vision transformer with bi-level routing attention. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10323–10333, 2023. 12 A1 Preliminaries We introduce the basic operators used in our model, including attention-based feature aggregation, vector quantizati...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.