Extending AI for Research to the Humanities: A Multi-Agent Framework for Evidence-Grounded Scholarship
Pith reviewed 2026-06-28 22:30 UTC · model grok-4.3
The pith
A multi-agent framework assigns humanities operations like evidence annotation and provenance checking to cooperating agents over passages, graph communities, and semantic clusters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
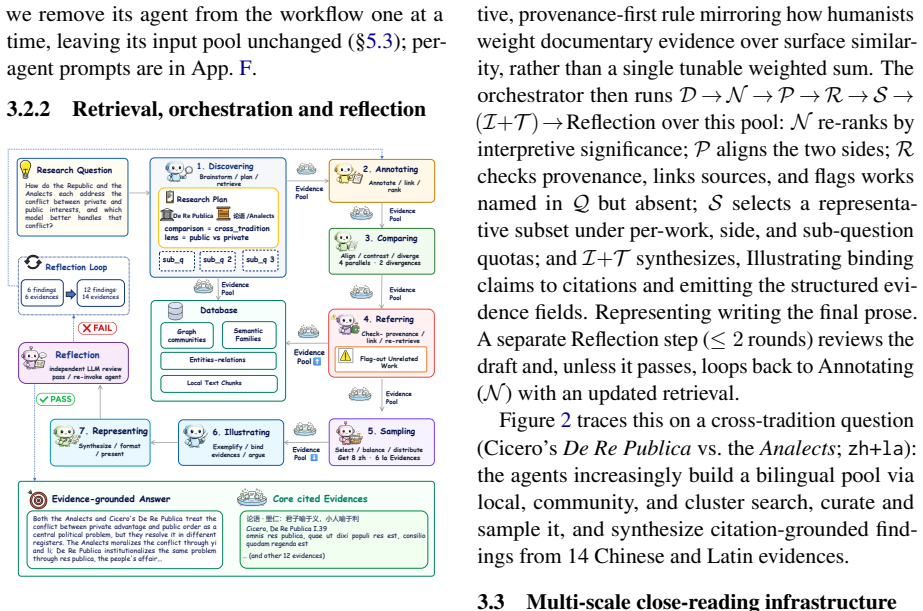
SPIRE draws on Scholarly Primitives theory to treat operations such as source discovery, evidence annotation, comparison, provenance checking, sampling, citation binding, and argumentative synthesis as cooperating agent roles. These roles act over a multi-scale close-reading substrate consisting of passages, intra-context graph communities, and cross-context semantic clusters. On a benchmark of peer-reviewed papers in classical Chinese and Greco-Roman Latin scholarship, the system recovers cited primary-source evidence more reliably than Naive LLM, Text RAG, and GraphRAG baselines and earns higher blind-judge scores for answer accuracy, depth, coverage, and evidence quality.
What carries the argument
SPIRE multi-agent framework that decomposes humanities scholarship into cooperating agent roles over a multi-scale close-reading substrate of passages, graph communities, and semantic clusters.
If this is right
- Evidence recovery and answer quality improve when scholarly operations are split across specialized agents rather than handled by a single model.
- Both the division into agent roles and the layered retrieval substrate are necessary for the performance gains observed on the benchmark.
- The approach produces outputs that score higher on accuracy, depth, coverage, and evidence quality under blind evaluation.
- The framework can be applied to other bodies of classical scholarship that rely on close reading of primary sources.
Where Pith is reading between the lines
- The same role division could be tested on modern-language literary criticism where provenance of quotations is equally central.
- Adding explicit citation-binding agents might reduce hallucinated references even in non-humanities domains that still require source tracing.
- If the substrate layers prove portable, similar multi-scale structures could be built for legal or historical argument without requiring new model training.
Load-bearing premise
Mapping humanities operations onto cooperating agent roles over a multi-scale substrate of passages, graphs, and clusters will produce faithful interpretive reasoning and verifiable evidence grounding.
What would settle it
A replication on the same classical Chinese and Greco-Roman Latin benchmark in which SPIRE no longer shows higher evidence recovery rates or blind-judge scores than the three baselines after the agent-role division is removed.
Figures

read the original abstract
LLM-based research agents have advanced rapidly in science and engineering, where research is organized around executable experiments, code, and quantitative signals. Humanities scholarship, however, requires a different mode of reasoning: interpretive, evidence-grounded argument over primary sources, where scholarly value depends on faithful quotation, verifiable provenance, and close reading. Existing research agents remain largely optimized for execution and retrieval, not evidence-grounded interpretive reasoning. To address this gap, we introduce SPIRE (Scholarly-Primitives-Inspired Research Engine), a multi-agent framework for evidence-grounded humanities scholarship. Drawing on Scholarly Primitives theory, SPIRE casts recurring humanities operations as cooperating agent roles (source discovery, evidence annotation, comparison, provenance checking, sampling, citation binding, and argumentative synthesis) over a multi-scale close-reading substrate of passages, intra-context graph communities, and cross-context semantic clusters. On a peer-reviewed-paper benchmark over classical Chinese and Greco-Roman Latin scholarship, SPIRE recovers cited primary-source evidence more reliably than Naive LLM, Text RAG, and GraphRAG, and receives higher blind-judge scores on answer accuracy, depth, coverage, and evidence quality. Ablations show that both the scholarly-operation agents and close-reading retrieval contribute to evidence-grounded essays. Code, data catalogues, and reproduction scripts are released at https://github.com/YatingPan/SPIRE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SPIRE, a multi-agent framework for evidence-grounded humanities scholarship that maps Scholarly Primitives operations (source discovery, evidence annotation, comparison, provenance, sampling, citation binding, and synthesis) to cooperating agent roles over a multi-scale close-reading substrate of passages, intra-context graph communities, and cross-context semantic clusters. On a benchmark derived from peer-reviewed papers in classical Chinese and Greco-Roman Latin scholarship, the paper claims SPIRE recovers cited primary-source evidence more reliably than Naive LLM, Text RAG, and GraphRAG baselines and receives higher blind-judge scores on accuracy, depth, coverage, and evidence quality. Ablations indicate that both the scholarly-operation agents and close-reading retrieval contribute to performance. Code, data catalogues, and reproduction scripts are released.
Significance. If the performance claims are substantiated with detailed metrics and a benchmark that tests interpretive synthesis, the work could meaningfully extend AI research agents beyond quantitative domains into evidence-grounded interpretive reasoning in the humanities. The grounding in established scholarly primitives theory and the public release of code and reproduction materials are explicit strengths that support verifiability and extension by others.
major comments (2)
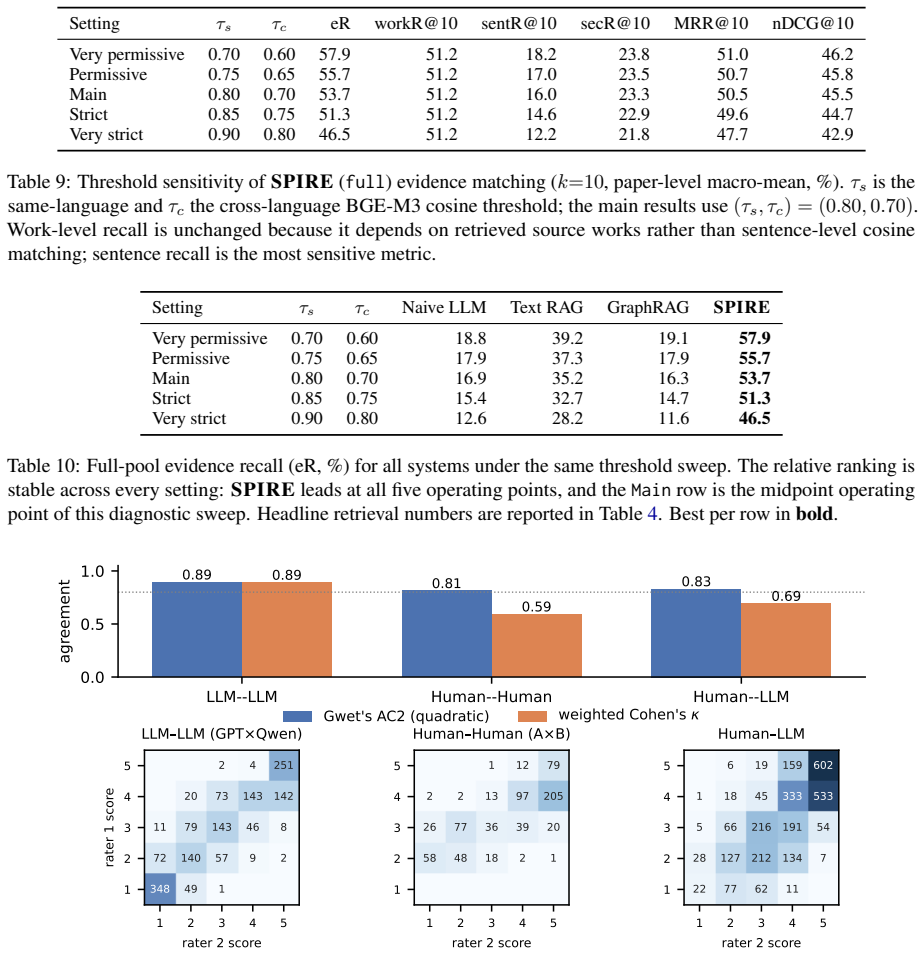
- [Evaluation section] Evaluation section: The abstract asserts superior recovery of primary-source evidence and higher judge scores, but provides no quantitative metrics (e.g., recovery rates or F1), statistical tests, benchmark construction details, or ablation numbers, leaving the central empirical claim with limited verifiable support.
- [Benchmark description] Benchmark description: The protocol for sampling test cases from the peer-reviewed papers is unspecified, including whether questions were blinded to the citing context or require the full agent pipeline; this is load-bearing because it determines whether gains reflect citation retrieval of pre-linked passages or genuine advances in novel evidence-grounded argumentation over the multi-scale substrate.
minor comments (1)
- [Abstract] Abstract: The invented term 'multi-scale close-reading substrate' is used without a diagram or formal definition of how passages, graph communities, and semantic clusters interact; adding a figure would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive review and for identifying areas where the empirical claims require greater explicit support. We address both major comments by committing to targeted revisions that add the requested quantitative details and protocol clarifications without altering the core claims or experimental design.
read point-by-point responses
-
Referee: [Evaluation section] Evaluation section: The abstract asserts superior recovery of primary-source evidence and higher judge scores, but provides no quantitative metrics (e.g., recovery rates or F1), statistical tests, benchmark construction details, or ablation numbers, leaving the central empirical claim with limited verifiable support.
Authors: We agree that the abstract summarizes results at a high level without numbers. The evaluation section (Section 4) already contains the supporting tables, but to make the central claims immediately verifiable we will revise the abstract to report key metrics (recovery rate, F1, judge scores) and statistical tests (paired t-tests with p-values). We will also add an explicit pointer to the full ablation tables and benchmark-construction appendix. These changes strengthen verifiability while preserving the existing experimental results. revision: yes
-
Referee: [Benchmark description] Benchmark description: The protocol for sampling test cases from the peer-reviewed papers is unspecified, including whether questions were blinded to the citing context or require the full agent pipeline; this is load-bearing because it determines whether gains reflect citation retrieval of pre-linked passages or genuine advances in novel evidence-grounded argumentation over the multi-scale substrate.
Authors: We acknowledge the need for explicit protocol details. In the revised manuscript we will insert a new subsection (3.3) that fully specifies the sampling procedure: questions were derived from the scholarly papers but formulated independently of the original citing sentences; the test set was blinded to citation links; and each question requires the complete multi-agent pipeline (discovery through synthesis) rather than retrieval of pre-linked passages. We will also provide concrete examples and a flowchart to demonstrate that performance gains reflect novel evidence-grounded argumentation over the multi-scale substrate. revision: yes
Circularity Check
No significant circularity; empirical claims rest on external benchmark
full rationale
The paper introduces SPIRE as a multi-agent system mapping humanities operations to agent roles over a multi-scale substrate, then reports empirical gains on a benchmark of external peer-reviewed papers in classical Chinese and Greco-Roman Latin scholarship. No equations, fitted parameters, or self-referential definitions appear in the provided abstract or description. Performance is compared against independent baselines (Naive LLM, Text RAG, GraphRAG) with blind-judge metrics; the benchmark instances are drawn from published scholarship rather than quantities defined by the authors' own inputs or prior self-citations. The design draws on Scholarly Primitives theory without the central results reducing to ansatzes, uniqueness theorems, or renamings internal to the paper. This is a standard non-circular empirical framing.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Scholarly Primitives theory identifies recurring operations in humanities scholarship that can be directly cast as cooperating agent roles
invented entities (1)
-
multi-scale close-reading substrate (passages, intra-context graph communities, cross-context semantic clusters)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Openscholar: Synthesizing scientific literature with retrieval-augmented lms, 2024
Out of one, many: Using language mod- els to simulate human samples.Political Analysis, 31(3):337–351. David Armitage. 2012. What’s the big idea? intellectual history and the longue durée.History of European Ideas, 38(4):493–507. Akari Asai, Jacqueline He, Rulin Shao, Weijia Shi, Amanpreet Singh, Joseph Chee Chang, Kyle Lo, Luca Soldaini, Sergey Feldman, ...
-
[2]
Augmenting large language models with chem- istry tools.Nature Machine Intelligence, 6:525–535. Andong Chen, Lianzhang Lou, Kehai Chen, Xuefeng Bai, Yang Xiang, Muyun Yang, Tiejun Zhao, and Min Zhang. 2025a. Benchmarking LLMs for translating classical Chinese poetry: Evaluating adequacy, flu- ency, and elegance. InProceedings of the 2025 Con- ference on E...
-
[3]
InAdvances in Neural Information Process- ing Systems
HyperGraphRAG: Retrieval-augmented gener- ation via hypergraph-structured knowledge represen- tation. InAdvances in Neural Information Process- ing Systems. Leland McInnes, John Healy, and Steve Astels. 2017. hdbscan: Hierarchical density based clustering.Jour- nal of Open Source Software, 2(11):205. Stuart M. McManus, Yuji Li, Leo Tam, Shuyang Qiu, Songy...
2017
-
[4]
AgentSociety: Large-scale simulation of LLM-driven generative agents advances understand- ing of human behaviors and society.arXiv preprint arXiv:2502.08691. Geoffrey Rockwell and Stéfan Sinclair. 2016. Hermeneutica: Computer-Assisted Interpretation in the Humanities. MIT Press. Bernardino Romera-Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej ...
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[5]
Association for Computational Linguistics. William F. Shen, Xinchi Qiu, Chenxi Whitehouse, Lisa Alazraki, Shashwat Goel, Francesco Barbieri, Timon Willi, Akhil Mathur, and Ilias Leontiadis. 2026. Re- thinking rubric generation for improving LLM judge and reward modeling for open-ended tasks.Preprint, arXiv:2602.05125. Noah Shinn, Federico Cassano, Edward ...
-
[6]
close read- ing
Reflexion: Language agents with verbal rein- forcement learning. InAdvances in Neural Informa- tion Processing Systems. Quentin Skinner. 1969. Meaning and understanding in the history of ideas.History and Theory, 8(1):3–53. Barbara Herrnstein Smith. 2016. What was “close read- ing”? a century of method in literary studies.The Minnesota Review, 2016(87):57...
1969
-
[7]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Autogen: Enabling next-gen llm applica- tions via multi-agent conversation.arXiv preprint arXiv:2308.08155. Qiankun Xu, Yutong Liu, Dongbo Wang, and Shuiqing Huang. 2025. Automatic recognition of cross- language classic entities based on large language models.npj Heritage Science, 13:59. Yue Yang, Yinzhi Xu, Chenghao Huang, JohnMichael Jurgensen, Han Hu, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
high agreement, low kappa
From automation to autonomy: A survey on large language models in scientific discovery. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 17733–17750, Suzhou, China. Association for Com- putational Linguistics. Gucheng Zhou, editor. 1992.Zhongguo Xueshu Mingzhu Tiyao (Compendium of Chinese Academic Masterwork...
2025
-
[9]
INTERPRETATION: what the passage tells us in relation to the question (1-2 sentences of interpretive significance, not a summary)
-
[10]
SUB_QUESTION: which sub-question id (q1, q2, ...) it best bears on; "general" if several or none
-
[11]
CONNECTIONS: references it makes to other works/authors/concepts that also appear elsewhere in the batch
-
[12]
annotations
RELEVANCE_RANK: 1-5 (5 = directly addresses the core with specific textual evidence; 1 = tangential background). Output VALID JSON only: a single object with an "annotations" array of {text_unit_id, interpretation, sub_question, connections[], relevance_rank}. Do NOT return a bare array. Comparing – system prompt You are performing a scholarly comparison ...
-
[13]
Chinese e.g
Concept -- a recurring intellectual touchstone in a tradition (concept, doctrine, motif, value, or problem recurring across texts). Chinese e.g. ren, yi, li, dao, tian, ming, xing-shan, xing-e, si-duan, gewu-zhizhi, wu-wei, zhongyong, kong, yuanqi, fo-xing. Latin/Greco-Roman e.g. iustitia, virtus, fides, pietas, officium, prudentia, ratio, logos, natura, ...
-
[14]
Person -- a named individual who proposes, defines, debates, transmits, criticizes, or exemplifies a Concept (Confucius, Mencius, Zhu Xi, Cicero, Seneca, Augustine, Aristotle)
-
[15]
entities
Work -- a named text/treatise/poem/collection that carries, defines, records, or debates a Concept (Lunyu, Mengzi, Daxue, De Officiis). === ENTITY FIELDS (all required) === type (Concept|Person|Work); domain (Ethics & Morality | Politics & Governance | Religion & Spirituality | Metaphysics & Epistemology | Natural Philosophy & Science | Literature & Aesth...
-
[16]
AnswerAccuracy -- does the essay precisely address the relation the question asks (how / why / in what sense / through what mechanism) with textually sound claims, not merely list related concepts? 1 = off-topic / contradicts the texts; 2 = misreads the core concept; 3 = relevant but generic or half-answers the key relation 28 (topical adequacy CAPS HERE)...
-
[17]
ArgumentDepth -- is the argument driven by specific textual detail and developed in layers, not paraphrastic summary? 1 = no real argument; 2 = assertion/paraphrase only; 3 = a thesis but mainly generalisation or restatement (SUMMARY CAPS HERE); 4 = structured multi-step argument, several moves text-driven; 5 = layered analysis deriving claims from close ...
-
[18]
CoverageCompleteness -- does it cover the sub-tasks the question entails? (A comparison requires both sides + similarity + difference + the limits of the comparison.) 1 = misses major dimensions; 2 = one side only; 3 = main question answered but a key sub-dimension thin (a single general point CAPS HERE); 4 = main dimensions covered, minor omissions; 5 = ...
-
[19]
AnswerAccuracy
EvidenceQuality -- how well is the answer grounded in specific primary-text evidence: density of direct quotation, specificity of citation, close reading of the source material, versus vague work-name dropping or hand-waving paraphrase? (Faithfulness floor: treat a citation as fabricated only if the quoted words clearly do not belong to the cited work or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.