Benchmarking Single-Step Inpainting Methods for Multi-Object 3D Gaussian Splatting Scenes
Pith reviewed 2026-06-28 22:49 UTC · model grok-4.3
The pith
Reconstruction-based inpainters outperform generative diffusion models in 3D consistency for Gaussian Splatting object removal, and scene initialization from scratch beats finetuning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
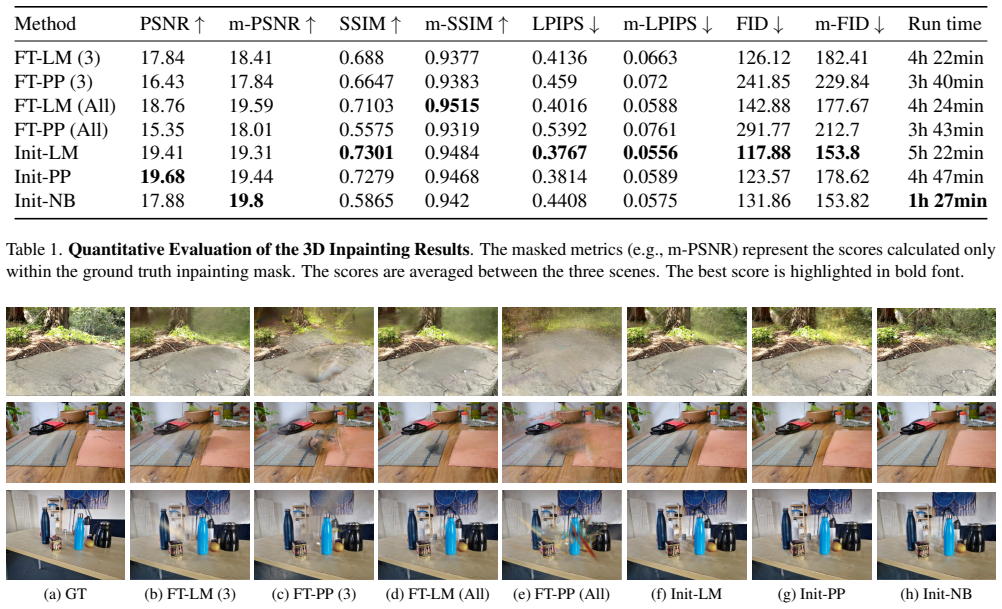
The central claim is that reconstruction-based inpainters outperform generative diffusion models in 3D consistency. Integrating 2D inpainters into single-step 3DGS methods shows that initializing the scene from scratch produces higher quality results than finetuning the existing scene. A baseline using a generative 2D inpainter highlights the need for object removal prior to inpainting. The authors also present a new multi-object scene dataset with recorded ground truth and occlusion views.
What carries the argument
Single-step methods for integrating 2D inpainters into 3D Gaussian Splatting scenes, including the choice between reconstruction-based and generative approaches and between initializing from scratch versus finetuning.
Load-bearing premise
That the performance differences observed on the authors' new multi-object scene with ground truth will generalize to other 3D Gaussian Splatting scenes and that the chosen single-step integration methods fairly represent the space of possible 3D inpainting pipelines.
What would settle it
A comparison on additional 3DGS scenes where generative diffusion models achieve higher 3D consistency scores than reconstruction-based ones, or where finetuning an existing scene yields better quality than initializing from scratch, would disprove the central claims.
Figures





read the original abstract
The tasks of object removal and inpainting 3D Gaussian Splatting (3DGS) scenes face challenges such as 3D consistency across camera views. In comparing 2D inpainters and their suitability for the 3D domain, we find that reconstruction-based inpainters outperform generative diffusion models in 3D consistency. Integrating these 2D inpainters into different single-step methods for creating and finetuning 3DGS scenes, our results indicate that initializing the scene from scratch produces higher quality results than finetuning the existing scene. Using a state-of-the-art generative 2D inpainter, we create a straightforward baseline to underline the importance of object removal before inpainting in the 3D setting. Since 360{\deg} datasets rarely include real-world ground truths, and challenging occlusion scenarios are equally sparse, we introduce a novel multi-object scene with recorded ground truth data and many views with object occlusions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript benchmarks single-step inpainting methods for multi-object 3D Gaussian Splatting (3DGS) scenes. It claims that reconstruction-based inpainters outperform generative diffusion models with respect to 3D consistency across views, that initializing a 3DGS scene from scratch yields higher quality results than finetuning an existing scene when integrating 2D inpainters, and that object removal prior to inpainting is important. To support these comparisons the authors introduce a new multi-object scene containing recorded ground-truth data and multiple views with occlusions, addressing the scarcity of such data in existing 360° datasets.
Significance. If the empirical comparisons hold, the work supplies a new dataset with recorded ground truth that directly targets the acknowledged limitations of prior 360° collections and supplies concrete guidance on the relative merits of reconstruction versus generative 2D inpainters and of scratch versus finetune integration strategies. The explicit baseline that isolates the effect of object removal is a useful reference point for future 3D inpainting pipelines.
major comments (2)
- [Abstract] Abstract: the comparative claims (reconstruction-based inpainters outperform generative models; scratch initialization outperforms finetuning) are stated without any quantitative metrics, error bars, dataset cardinality, or exclusion criteria. These omissions are load-bearing for evaluating the central empirical claims.
- [Experimental Setup] The experimental protocol relies on a single newly collected multi-object scene. Without explicit reporting of scene count, view count, occlusion statistics, and the precise procedure used to record ground truth, it is impossible to assess whether the reported performance gaps generalize or are sensitive to post-hoc implementation choices.
minor comments (2)
- [Method] The description of the single-step integration methods would benefit from a concise pseudocode or diagram clarifying the exact sequence of 2D inpainting, 3DGS initialization, and any optimization steps.
- [Results] Table captions should explicitly state the number of runs or views averaged and whether error bars represent standard deviation or standard error.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript to strengthen clarity and evaluability of the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the comparative claims (reconstruction-based inpainters outperform generative models; scratch initialization outperforms finetuning) are stated without any quantitative metrics, error bars, dataset cardinality, or exclusion criteria. These omissions are load-bearing for evaluating the central empirical claims.
Authors: We agree that the abstract should provide quantitative support for the central claims. In the revised version we will incorporate key metrics (e.g., observed PSNR/SSIM differences for 3D consistency), error-bar information where applicable, the dataset cardinality, and any exclusion criteria used in the comparisons. revision: yes
-
Referee: [Experimental Setup] The experimental protocol relies on a single newly collected multi-object scene. Without explicit reporting of scene count, view count, occlusion statistics, and the precise procedure used to record ground truth, it is impossible to assess whether the reported performance gaps generalize or are sensitive to post-hoc implementation choices.
Authors: The manuscript deliberately uses one scene to supply recorded ground-truth data and occlusion cases that are absent from existing 360° collections. We will expand the experimental-setup section to state the scene count explicitly, report the exact view count, provide occlusion statistics, and detail the ground-truth recording procedure. This addresses the request for transparency while noting that the single-scene design inherently limits broad generalization statements. revision: yes
Circularity Check
No significant circularity
full rationale
This is a purely empirical benchmarking paper that introduces a new multi-object 3DGS scene with recorded ground truth and compares existing 2D inpainters plus integration strategies. No derivations, equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided abstract or description. The central claims rest on direct measurements from the new dataset, which is externally falsifiable and does not reduce to any input quantity by construction. This matches the default expectation for non-circular empirical studies.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multi-view consistency of inpainted 3DGS scenes can be evaluated by comparing rendered views against recorded ground truth after 2D inpainting.
Reference graph
Works this paper leans on
-
[1]
Barron, Ben Mildenhall, Dor Verbin, Pratul P
Jonathan T. Barron, Ben Mildenhall, Dor Verbin, Pratul P. Srinivasan, and Peter Hedman. Mip-nerf 360: Unbounded anti-aliased neural radiance fields.CVPR, 2022. 1, 2
2022
-
[2]
Yuxin Cheng, Binxiao Huang, Taiqiang Wu, Wenyong Zhou, Chenchen Ding, Zhengwu Liu, Graziano Chesi, and Ngai Wong. Perspective-aware 3d gaussian inpainting with multi- view consistency.arXiv preprint arXiv:2510.10993, 2025. 1
-
[3]
Gans trained by a two time-scale update rule converge to a local nash equilib- rium
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilib- rium. InProceedings of the 31st International Conference on Neural Information Processing Systems, page 6629–6640, Red Hook, NY , USA, 2017. Curran Associates Inc. 2
2017
-
[4]
3d gaussian inpainting with depth-guided cross-view consistency
Sheng-Yu Huang, Zi-Ting Chou, and Yu-Chiang Frank Wang. 3d gaussian inpainting with depth-guided cross-view consistency. InProceedings of the Computer Vision and Pat- tern Recognition Conference, pages 26704–26713, 2025. 1, 2, 3
2025
-
[5]
Brushnet: A plug-and-play image inpainting model with decomposed dual-branch diffusion, 2024
Xuan Ju, Xian Liu, Xintao Wang, Yuxuan Bian, Ying Shan, and Qiang Xu. Brushnet: A plug-and-play image inpainting model with decomposed dual-branch diffusion, 2024. 1, 2, 3, 4
2024
-
[6]
3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42 (4), 2023
Bernhard Kerbl, Georgios Kopanas, Thomas Leimk ¨uhler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42 (4), 2023. 1
2023
-
[7]
Srinivasan, Matthew Tancik, Jonathan T
Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: representing scenes as neural radiance fields for view synthe- sis.Commun. ACM, 65(1):99–106, 2021. 1
2021
-
[8]
Derpanis, Jonathan Kelly, Marcus A
Ashkan Mirzaei, Tristan Aumentado-Armstrong, Konstanti- nos G. Derpanis, Jonathan Kelly, Marcus A. Brubaker, Igor Gilitschenski, and Alex Levinshtein. SPIn-NeRF: Multiview segmentation and perceptual inpainting with neural radiance fields. InCVPR, 2023. 1
2023
-
[9]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10684–10695, 2022. 1
2022
-
[10]
Schonberger and Jan-Michael Frahm
Johannes L. Schonberger and Jan-Michael Frahm. Structure- from-motion revisited. InProceedings of the IEEE Confer- ence on Computer Vision and Pattern Recognition (CVPR),
-
[11]
Roman Suvorov, Elizaveta Logacheva, Anton Mashikhin, Anastasia Remizova, Arsenii Ashukha, Aleksei Silvestrov, Naejin Kong, Harshith Goka, Kiwoong Park, and Victor Lempitsky. Resolution-robust large mask inpainting with fourier convolutions.arXiv preprint arXiv:2109.07161,
-
[12]
InNeRF360: Text-Guided 3D-Consistent Object Inpainting on 360-degree Neural Radiance Fields
Dongqing Wang, Tong Zhang, Alaa Abboud, and Sabine S¨usstrunk. InNeRF360: Text-Guided 3D-Consistent Object Inpainting on 360-degree Neural Radiance Fields. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024. 1, 2
2024
-
[13]
In- paint360gs: Efficient object-aware 3d inpainting via gaus- sian splatting for 360° scenes
Shaoxiang Wang, Shihong Zhang, Christen Millerdurai, R¨udiger Westermann, Didier Stricker, and Alain Pagani. In- paint360gs: Efficient object-aware 3d inpainting via gaus- sian splatting for 360° scenes. InProc. of. IEEE Winter Con- ference on Applications of Computer Vision (WACV-2026). IEEE/CVF, 2026. 1
2026
-
[14]
Image quality assessment: From error visibility to structural similarity.Image Processing, IEEE Transactions on, 13:600 – 612, 2004
Zhou Wang, Alan Bovik, Hamid Sheikh, and Eero Simon- celli. Image quality assessment: From error visibility to structural similarity.Image Processing, IEEE Transactions on, 13:600 – 612, 2004. 2
2004
-
[15]
Nerfiller: Completing scenes via generative 3d inpainting
Ethan Weber, Aleksander Holynski, Varun Jampani, Saurabh Saxena, Noah Snavely, Abhishek Kar, and Angjoo Kanazawa. Nerfiller: Completing scenes via generative 3d inpainting. InCVPR, 2024. 1
2024
-
[16]
Gaussians-to-life: Text-driven animation of 3d gaussian splatting scenes
Thomas Wimmer, Michael Oechsle, Michael Niemeyer, and Federico Tombari. Gaussians-to-life: Text-driven animation of 3d gaussian splatting scenes. In2025 International Con- ference on 3D Vision (3DV), 2025. 1
2025
-
[17]
Gaussian grouping: Segment and edit anything in 3d scenes
Mingqiao Ye, Martin Danelljan, Fisher Yu, and Lei Ke. Gaussian grouping: Segment and edit anything in 3d scenes. arXiv preprint arXiv:2312.00732, 2023. 1, 2, 3
-
[18]
Efros, Eli Shecht- man, and Oliver Wang
Richard Zhang, Phillip Isola, Alexei A. Efros, Eli Shecht- man, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE Conference on Computer Vision and Pattern Recogni- tion (CVPR), 2018. 2, 1
2018
-
[19]
A task is worth one word: Learning with task prompts for high-quality versatile image inpainting
Junhao Zhuang, Yanhong Zeng, Wenran Liu, Chun Yuan, and Kai Chen. A task is worth one word: Learning with task prompts for high-quality versatile image inpainting. In European Conference on Computer Vision, pages 195–211. Springer, 2024. 1, 2, 3, 4
2024
-
[20]
Is nano banana pro a low-level vision all- rounder? a comprehensive evaluation on 14 tasks and 40 datasets, 2025
Jialong Zuo, Haoyou Deng, Hanyu Zhou, Jiaxin Zhu, Yicheng Zhang, Yiwei Zhang, Yongxin Yan, Kaixing Huang, Weisen Chen, Yongtai Deng, Rui Jin, Nong Sang, and Changxin Gao. Is nano banana pro a low-level vision all- rounder? a comprehensive evaluation on 14 tasks and 40 datasets, 2025. 1, 2, 3, 4 Benchmarking Single-Step Inpainting Methods for Multi-Object ...
2025
-
[21]
The loss terms are different for reference views and for non-reference views
Losses for Finetuning For finetuning, we define the following losses. The loss terms are different for reference views and for non-reference views. We define Lrecon = ( LM 1 (Iin, I)ifv∈V ref LLP IP S(Iin, I)otherwise, (1) whereV ref is the set of reference views,L M 1 is the masked L1 loss,L LP IP S is the LPIPS loss [18] around the masked region,I In is...
-
[22]
Experiments and Ablations We provide additional material for the 2D inpainers and the qualitative and quantitative results. 6.1. 2D Inpainter Comparison LaMa. Many 3D inpainting pipelines [4, 13, 17] use LaMa [11] as their 2D inpainter. It produces smooth re- sults without sharp details in the inpainted region, which is beneficial in the 3D setting, since...
-
[23]
Prompt Details For reproduction, we specify the exact prompts we use for the respective experiments. 7.1. Nano Banana Prompt When inpainting with Nano Banana [20], we use a scene specific prompt because each scene has a different object to remove. They are given in the following. Bear. Remove the grey stone bear sculpture and the square grey stone plinth ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.