GraphARC: A Comprehensive Benchmark for Graph-Based Abstract Reasoning
Pith reviewed 2026-06-28 22:37 UTC · model grok-4.3
The pith
GraphARC shows language models answer graph property questions but fail full transformation tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
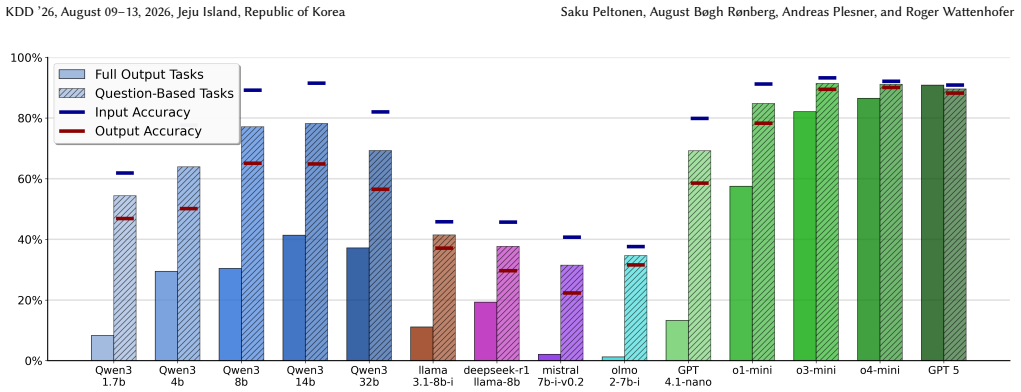
GraphARC generalizes the few-shot transformation paradigm of ARC to graphs and shows that state-of-the-art language models can answer questions about graph properties but frequently fail to solve the complete graph transformation task, with performance degrading on larger instances.
What carries the argument
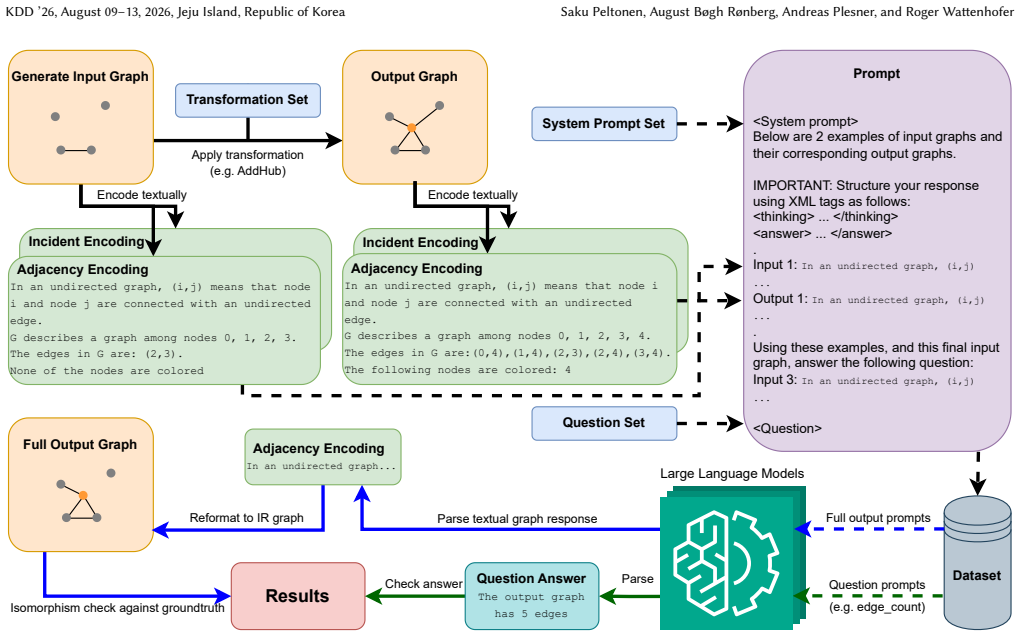
GraphARC benchmark of few-shot graph transformation tasks that cover local, global, and hierarchical operations on diverse graph families.
Load-bearing premise
The automatically generated tasks capture the intended abstract reasoning demands without systematic bias from the graph families, sizes, or transformation rules chosen.
What would settle it
A model that correctly solves most GraphARC tasks on both small and large graphs would show the reported comprehension-execution gap does not hold.
Figures

read the original abstract
Relational reasoning lies at the heart of intelligence, but existing benchmarks are typically confined to formats such as grids or text. We introduce GraphARC, a benchmark for abstract reasoning on graph-structured data. GraphARC generalizes the few-shot transformation learning paradigm of the Abstraction and Reasoning Corpus (ARC). Each task requires inferring a transformation rule from a few input-output pairs and applying it to a new test graph, covering local, global, and hierarchical graph transformations. Unlike grid-based ARC, GraphARC instances can be generated at scale across diverse graph families and sizes, enabling systematic evaluation of generalization abilities. We evaluate state-of-the-art language models on GraphARC and observe clear limitations. Models can answer questions about graph properties but often fail to solve the full graph transformation task, revealing a comprehension-execution gap. Performance further degrades on larger instances, exposing scaling barriers. More broadly, by combining aspects of node classification, link prediction, and graph generation within a single framework, GraphARC provides a promising testbed for future graph foundation models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces GraphARC, a benchmark generalizing the ARC few-shot transformation paradigm to graphs. Tasks require inferring a transformation rule from a few input-output graph pairs and applying it to a test graph, spanning local, global, and hierarchical transformations. The benchmark is generated at scale across graph families and sizes. Evaluation of state-of-the-art language models shows they can answer graph property questions but frequently fail the full transformation task (comprehension-execution gap), with further degradation on larger instances. GraphARC is positioned as a testbed combining node classification, link prediction, and graph generation for graph foundation models.
Significance. If the empirical observations are robustly supported, GraphARC would offer a scalable, structured-data complement to grid-based ARC for testing abstract relational reasoning. The automatic generation across sizes and families enables systematic study of generalization, and the reported gap could highlight specific limitations in current models' ability to move from comprehension to execution on graphs.
major comments (3)
- [§3] §3 (Benchmark Construction): The automatic generation from fixed graph families, size distributions, and transformation rule templates does not specify controls ensuring that property-question instances require the same global consistency and rule inference as the full transformation tasks. Without such controls, the claimed comprehension-execution gap may be an artifact of the generator rather than evidence of model reasoning limits.
- [§4] §4 (Evaluation): The abstract and high-level description provide no details on prompting methods, exact success metrics for transformations, statistical controls, or how property questions were aligned with transformation difficulty. This absence prevents verification of the central claims about the gap and scaling degradation.
- [§5] §5 (Results): The reported performance degradation on larger instances and the gap between property questions and full tasks lack accompanying quantitative tables, error analysis, or ablation on generation parameters that would make the observations load-bearing for the benchmark's conclusions.
minor comments (2)
- [Abstract] Abstract: The phrase 'clear limitations' is vague; a brief quantitative characterization of the gap (e.g., accuracy deltas) would improve precision.
- Notation: Graph transformation rules and property questions could be formalized with a small set of equations or pseudocode for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting areas where additional rigor is needed to support the central claims about the comprehension-execution gap. We address each major comment below with clarifications and commitments to revision.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction): The automatic generation from fixed graph families, size distributions, and transformation rule templates does not specify controls ensuring that property-question instances require the same global consistency and rule inference as the full transformation tasks. Without such controls, the claimed comprehension-execution gap may be an artifact of the generator rather than evidence of model reasoning limits.
Authors: We agree that the manuscript does not explicitly detail controls ensuring property questions demand equivalent global consistency and rule inference. While property questions are generated from the same rule templates as the transformation tasks, this alignment is not formalized in §3. We will revise the section to add explicit controls, including rule-inference question templates that test understanding of the full transformation (e.g., querying transformed global properties) and verification that question difficulty matches task complexity. This will strengthen the claim that the gap reflects model limitations. revision: yes
-
Referee: [§4] §4 (Evaluation): The abstract and high-level description provide no details on prompting methods, exact success metrics for transformations, statistical controls, or how property questions were aligned with transformation difficulty. This absence prevents verification of the central claims about the gap and scaling degradation.
Authors: The evaluation section indeed provides only high-level descriptions without the requested specifics on prompting, metrics, statistics, or alignment. This is a genuine limitation for verification. We will expand §4 with detailed subsections covering: exact prompting formats (including few-shot examples), success metrics (e.g., exact graph edit distance or isomorphism for transformations), statistical controls (multiple random seeds with confidence intervals), and alignment methods for property questions. These additions will enable reproducibility and direct assessment of the reported phenomena. revision: yes
-
Referee: [§5] §5 (Results): The reported performance degradation on larger instances and the gap between property questions and full tasks lack accompanying quantitative tables, error analysis, or ablation on generation parameters that would make the observations load-bearing for the benchmark's conclusions.
Authors: We acknowledge that the results section relies on high-level trends without supporting quantitative tables, error breakdowns, or ablations, which weakens the load-bearing nature of the observations. We will revise §5 to include: performance tables stratified by instance size, graph family, and transformation category; categorized error analysis (e.g., failures in rule comprehension vs. execution); and ablations on generation parameters such as rule template complexity and size scaling. This will provide the necessary empirical support for the benchmark conclusions. revision: yes
Circularity Check
No circularity: empirical benchmark without derivations or self-referential predictions
full rationale
The paper introduces GraphARC as a benchmark and reports empirical model evaluations on generated tasks, with observations such as the comprehension-execution gap arising directly from accuracy measurements rather than any derivation chain. No equations, fitted parameters renamed as predictions, self-citations invoked as uniqueness theorems, or ansatzes appear in the load-bearing claims. The construction of tasks from graph families and rules is presented as a methodological choice, not a self-defining loop that forces results. This is a standard empirical benchmark paper whose central findings are falsifiable via external replication and thus self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
ARC Prize Foundation. 2024. 2024 Progress on ARC-AGI-Pub. https://arcprize. org/blog/2024-progress-arc-agi-pub. Accessed: 2025-09-01
2024
-
[2]
ARC Prize Foundation. 2024. OpenAI O3 Breakthrough High Score on ARC-AGI- PUB. https://arcprize.org/blog/oai-o3-pub-breakthrough. Accessed: 2025-01-01
2024
-
[3]
Rim Assouel, Pau Rodriguez, Perouz Taslakian, David Vazquez, and Yoshua Ben- gio. 2022. Object-centric compositional imagination for visual abstract reasoning. InICLR2022 Workshop on the Elements of Reasoning: Objects, Structure and Causal- ity
2022
-
[4]
François Chollet. 2019. On the measure of intelligence.arXiv preprint arXiv:1911.01547(2019)
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[5]
Francois Chollet, Mike Knoop, Gregory Kamradt, Bryan Landers, and Henry Pinkard. 2025. Arc-agi-2: A new challenge for frontier ai reasoning systems. arXiv preprint arXiv:2505.11831(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [6]
-
[7]
Hwang, Soumya Sanyal, Sean Welleck, Xiang Ren, Allyson Ettinger, Zaid Harchaoui, and Yejin Choi
Nouha Dziri, Ximing Lu, Melanie Sclar, Xiang Lorraine Li, Liwei Jiang, Bill Yuchen Lin, Peter West, Chandra Bhagavatula, Ronan Le Bras, Jena D. Hwang, Soumya Sanyal, Sean Welleck, Xiang Ren, Allyson Ettinger, Zaid Harchaoui, and Yejin Choi. 2023. Faith and fate: limits of transformers on compositionality. InProceed- ings of the 37th International Conferen...
2023
-
[8]
Bahare Fatemi, Jonathan Halcrow, and Bryan Perozzi. 2024. Talk like a Graph: Encoding Graphs for Large Language Models
2024
-
[9]
Michael Galkin, Jincheng Zhou, Bruno Ribeiro, Jian Tang, and Zhaocheng Zhu
-
[10]
A foundation model for zero-shot logical query reasoning.Advances in Neural Information Processing Systems37 (2024), 54137–54160
2024
-
[11]
Graeme S Halford, William H Wilson, and Steven Phillips. 2010. Relational knowledge: The foundation of higher cognition.Trends in cognitive sciences14, 11 (2010), 497–505
2010
-
[12]
Keith J Holyoak. 2012. 13 Analogy and Relational Reasoning.The Oxford handbook of thinking and reasoning(2012), 234
2012
-
[13]
John E Hummel and Keith J Holyoak. 2003. A symbolic-connectionist theory of relational inference and generalization.Psychological review110, 2 (2003), 220
2003
-
[14]
Bowen Jin, Gang Liu, Chi Han, Meng Jiang, Heng Ji, and Jiawei Han. 2024. Large Language Models on Graphs: A Comprehensive Survey.IEEE Trans. on Knowl. and Data Eng.36, 12 (Dec. 2024), 8622–8642. doi:10.1109/TKDE.2024.3469578
-
[15]
Kipf and Max Welling
Thomas N. Kipf and Max Welling. 2017. Semi-Supervised Classification with Graph Convolutional Networks. In5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings. OpenReview.net. https://openreview.net/forum?id=SJU4ayYgl
2017
-
[16]
Brenden M Lake, Tomer D Ullman, Joshua B Tenenbaum, and Samuel J Gershman
-
[17]
Building machines that learn and think like people.Behavioral and brain sciences40 (2017), e253
2017
- [18]
-
[19]
Jiawei Liu, Cheng Yang, Zhiyuan Lu, Junze Chen, Yibo Li, Mengmei Zhang, Ting Bai, Yuan Fang, Lichao Sun, Philip S Yu, et al. 2025. Graph foundation models: Concepts, opportunities and challenges.IEEE Transactions on Pattern Analysis and Machine Intelligence(2025)
2025
- [20]
-
[21]
Oscar Méndez-Lucio, Christos A Nicolaou, and Berton Earnshaw. 2024. MolE: a foundation model for molecular graphs using disentangled attention.Nature Communications15, 1 (2024), 9431
2024
-
[22]
Parsa Mirtaheri, Ezra Edelman, Samy Jelassi, Eran Malach, and Enric Boix-Adsera
- [23]
-
[24]
Steven Pinker. 1998. Words and rules.Lingua106, 1-4 (1998), 219–242
1998
-
[25]
Clayton Sanford, Bahare Fatemi, Ethan Hall, Anton Tsitsulin, Mehran Kazemi, Jonathan Halcrow, Bryan Perozzi, and Vahab Mirrokni. 2024. Understanding transformer reasoning capabilities via graph algorithms.Advances in Neural Information Processing Systems37 (2024), 78320–78370
2024
-
[26]
Martin Simonovsky and Nikos Komodakis. 2018. Graphvae: Towards generation of small graphs using variational autoencoders. InInternational conference on artificial neural networks. Springer, 412–422
2018
-
[27]
Edward E Smith, Christopher Langston, and Richard E Nisbett. 1992. The case for rules in reasoning.Cognitive science16, 1 (1992), 1–40
1992
-
[28]
Charlie Victor Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. 2025. Scaling LLM test-time compute optimally can be more effective than scaling parameters for reasoning. InThe Thirteenth International Conference on Learning Representations
2025
-
[29]
Heng Wang, Shangbin Feng, Tianxing He, Zhaoxuan Tan, Xiaochuang Han, and Yulia Tsvetkov. 2023. Can language models solve graph problems in natural language?Advances in Neural Information Processing Systems36 (2023), 30840– 30861
2023
- [30]
-
[31]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. 2022. Chain-of-thought prompting elicits reasoning in large language models. InProceedings of the 36th International Conference on Neural Information Processing Systems(New Orleans, LA, USA) (NIPS ’22). Curran Associates Inc., Red Hook, NY...
2022
-
[32]
Yudong Xu, Wenhao Li, Pashootan Vaezipoor, Scott Sanner, and Elias B Khalil
- [33]
-
[34]
Zhitao Ying, Jiaxuan You, Christopher Morris, Xiang Ren, Will Hamilton, and Jure Leskovec. 2018. Hierarchical graph representation learning with differentiable pooling.Advances in neural information processing systems31 (2018)
2018
-
[35]
Muhan Zhang and Yixin Chen. 2018. Link prediction based on graph neural networks.Advances in neural information processing systems31 (2018)
2018
-
[36]
You are a graph analyst. Study the following graph examples carefully and answer the ques- tion that follows
Haiteng Zhao, Shengchao Liu, Ma Chang, Hannan Xu, Jie Fu, Zhihong Deng, Ling- peng Kong, and Qi Liu. 2023. Gimlet: A unified graph-text model for instruction- based molecule zero-shot learning.Advances in neural information processing systems36 (2023), 5850–5887. A Instance Generation Framework A.1 Graph Generators We employ multiple graph generators to e...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.