GRKV: Global Regression for Training-Free KV Cache Compression in Long-Context LLMs
Pith reviewed 2026-06-28 22:52 UTC · model grok-4.3
The pith
Ridge regression merges KV cache tokens to cut memory use while raising long-context accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
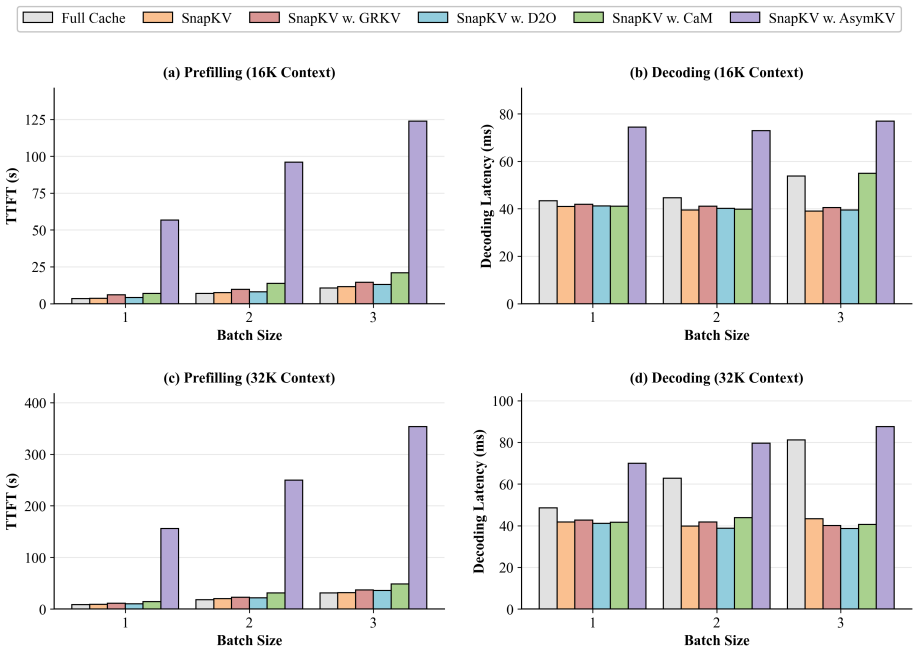
GRKV is a training-free KV-cache merging method that directly minimizes the discrepancy between compressed-cache and full-cache attention outputs. It uses ridge-regression-based merge steps to distribute information from evicted tokens across retained tokens while regularizing the updates to prevent over-smoothing. Across the LongBench and RULER long-context benchmarks, GRKV is the only merging method that improves overall performance with minimal overhead.
What carries the argument
Ridge-regression merge steps that solve for coefficients minimizing attention-output discrepancy between compressed and full caches.
If this is right
- Span retention plus merging can be made balanced enough to avoid the usual performance penalty.
- Information from discarded tokens can be redistributed without retraining the model.
- Regularized regression keeps the merge from collapsing distinct token representations.
- The added computation stays small enough to preserve the memory savings of compression.
Where Pith is reading between the lines
- The same regression idea could be tried on activation compression or other memory-bound stages of inference.
- Combining the merge with existing quantization schemes might compound the memory reduction.
- The approach may scale to contexts longer than those tested if the regression remains stable.
Load-bearing premise
Directly minimizing attention-output discrepancy via ridge regression will produce better end-task accuracy without introducing other unmeasured distortions.
What would settle it
Apply the GRKV merge on a held-out long-context benchmark and observe that its scores fall below those of a simple eviction baseline.
Figures




read the original abstract
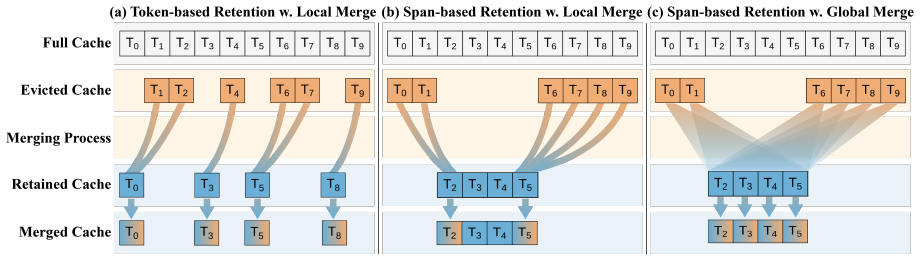
Large language models (LLMs) with extended context lengths rely on the key-value (KV) cache to support attention over prior tokens. However, maintaining the KV cache incurs substantial memory overhead, motivating KV-cache compression methods that enforce a fixed budget through eviction and merging. Modern eviction methods increasingly adopt span-based retention because preserving contiguous spans is empirically effective and better preserves semantic coherence. Yet, when combined with post-eviction merging, span-based retention concentrates merges onto a small set of span-boundary carrier tokens, producing a highly imbalanced merge pattern that exacerbates over-merging and increases information loss. To address this imbalance, we propose GRKV (Global Regression for KV Cache), a training-free KV-cache merging method that directly minimizes the discrepancy between compressed-cache and full-cache attention outputs. GRKV uses ridge-regression-based merge steps to distribute information from evicted tokens across retained tokens, while regularizing the updates to prevent over-smoothing. Across the LongBench and RULER long-context benchmarks, GRKV is the only merging method that improves overall performance with minimal overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GRKV, a training-free KV-cache merging method for long-context LLMs. It identifies that span-based retention plus post-eviction merging produces imbalanced merges concentrated on span-boundary tokens, and addresses this by applying ridge-regression merge steps that directly minimize the discrepancy between compressed-cache and full-cache attention outputs while regularizing to avoid over-smoothing. The central empirical claim is that GRKV is the only merging method that improves overall performance on the LongBench and RULER benchmarks with minimal overhead.
Significance. If the empirical gains are shown to arise from a generalizable approximation rather than query-specific fitting, the method would offer a practical, training-free route to KV-cache compression that preserves more semantic coherence than prior eviction-plus-merge baselines. The explicit use of a global regression objective with regularization is a clear technical contribution over purely heuristic merging rules.
major comments (2)
- [Method / Abstract claim] Method description (ridge-regression objective): the merge coefficients are obtained by regressing on attention outputs computed with the current query (or snapshot of recent queries) against the same cache being compressed. Because subsequent tokens employ different queries, the single-step discrepancy objective does not constrain approximation error growth; the manuscript must demonstrate that the resulting merged representations remain effective for future queries, or the translation from per-step attention matching to end-task gains is not guaranteed.
- [Abstract / Results] Abstract and results: the claim that GRKV is 'the only merging method that improves overall performance' is asserted without reported quantitative deltas, standard deviations, or per-task breakdowns in the supplied text. If the full manuscript likewise omits ablations that isolate the regression step from the evaluation queries, the independence of the fitting procedure from the reported metric remains unshown and directly affects the strength of the central claim.
minor comments (1)
- [Abstract] The abstract states the ridge-regression objective but does not specify the exact loss formulation, the choice of regularization parameter, or how many queries are used to form the regression matrix; adding these details would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. Below we address each major comment in turn, indicating planned revisions where appropriate.
read point-by-point responses
-
Referee: [Method / Abstract claim] Method description (ridge-regression objective): the merge coefficients are obtained by regressing on attention outputs computed with the current query (or snapshot of recent queries) against the same cache being compressed. Because subsequent tokens employ different queries, the single-step discrepancy objective does not constrain approximation error growth; the manuscript must demonstrate that the resulting merged representations remain effective for future queries, or the translation from per-step attention matching to end-task gains is not guaranteed.
Authors: We agree that the per-step regression is computed with respect to the query (or recent-query snapshot) present at the compression step. The ridge objective is nevertheless formulated globally over the full retained set rather than locally per token, which we expect to yield more stable approximations. To substantiate generalization, the revision will add (i) a plot of attention-output discrepancy measured on held-out future queries after each merge step and (ii) an ablation that continues generation for several hundred tokens post-compression while tracking both attention fidelity and downstream accuracy. revision: partial
-
Referee: [Abstract / Results] Abstract and results: the claim that GRKV is 'the only merging method that improves overall performance' is asserted without reported quantitative deltas, standard deviations, or per-task breakdowns in the supplied text. If the full manuscript likewise omits ablations that isolate the regression step from the evaluation queries, the independence of the fitting procedure from the reported metric remains unshown and directly affects the strength of the central claim.
Authors: We accept that the abstract statement requires quantitative backing. The full manuscript already reports per-task LongBench and RULER scores; the revision will (a) insert concrete overall deltas and standard deviations into both the abstract and results tables, and (b) add an explicit ablation that performs the ridge regression on a disjoint set of queries from those used at evaluation time, thereby isolating the contribution of the regression objective itself. revision: yes
Circularity Check
No significant circularity; method is a defined heuristic with separate empirical validation
full rationale
The paper defines GRKV as a training-free procedure that applies ridge regression to merge weights specifically to minimize the per-step discrepancy between compressed-cache and full-cache attention outputs. This minimization is an explicit design choice in the algorithm, not a derived prediction of downstream benchmark scores. The reported gains on LongBench and RULER are presented as experimental outcomes measured after applying the method, not as quantities that reduce algebraically or statistically to the regression objective by construction. No self-citations, uniqueness theorems, or ansatzes are invoked in the abstract to justify core steps, and the fitting uses only the current cache state rather than the final task metric. The derivation chain therefore remains self-contained as a proposed compression heuristic supported by independent benchmark results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Marah Abdin, Jyoti Aneja, Harkirat Behl, S \'e bastien Bubeck, Ronen Eldan, Suriya Gunasekar, Michael Harrison, Russell J Hewett, Mojan Javaheripi, Piero Kauffmann, and 1 others. 2024. https://arxiv.org/abs/2412.08905 Phi-4 technical report . arXiv preprint arXiv:2412.08905
Pith/arXiv arXiv 2024
-
[2]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, and 1 others. 2023. https://arxiv.org/abs/2303.08774 Gpt-4 technical report . arXiv preprint arXiv:2303.08774
Pith/arXiv arXiv 2023
-
[3]
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. 2024. https://doi.org/10.18653/v1/2024.acl-long.172 L ong B ench: A bilingual, multitask benchmark for long context understanding . In Proceedings of the 62nd Annual Meeting of the Association for ...
-
[4]
Zefan Cai, Yichi Zhang, Bofei Gao, Yuliang Liu, Yucheng Li, Tianyu Liu, Keming Lu, Wayne Xiong, Yue Dong, Junjie Hu, and 1 others. 2024. https://arxiv.org/abs/2406.02069 Pyramidkv: Dynamic kv cache compression based on pyramidal information funneling . arXiv preprint arXiv:2406.02069
Pith/arXiv arXiv 2024
-
[5]
Chi-Chih Chang, Wei-Cheng Lin, Chien-Yu Lin, Chong-Yan Chen, Yu-Fang Hu, Pei-Shuo Wang, Ning-Chi Huang, Luis Ceze, Mohamed S Abdelfattah, and Kai-Chiang Wu. 2024. https://arxiv.org/abs/2407.21118 Palu: Compressing kv-cache with low-rank projection . arXiv preprint arXiv:2407.21118
arXiv 2024
-
[6]
Wanyun Cui and Mingwei Xu. 2026. https://proceedings.neurips.cc/paper_files/paper/2025/file/750b0f9fccafad88e0da366315e03d1a-Paper-Conference.pdf Homogeneous keys, heterogeneous values: Exploiting local kv cache asymmetry for long-context llms . Advances in Neural Information Processing Systems, 38:81628--81650
2026
-
[7]
Tri Dao. 2024. https://proceedings.iclr.cc/paper_files/paper/2024/file/98ed250b203d1ac6b24bbcf263e3d4a7-Paper-Conference.pdf Flashattention-2: Faster attention with better parallelism and work partitioning . In International Conference on Learning Representations, volume 2024, pages 35549--35562
2024
-
[8]
Tri Dao, Dan Fu, Stefano Ermon, Atri Rudra, and Christopher R \'e . 2022. https://proceedings.neurips.cc/paper_files/paper/2022/file/67d57c32e20fd0a7a302cb81d36e40d5-Paper-Conference.pdf Flashattention: Fast and memory-efficient exact attention with io-awareness . Advances in neural information processing systems, 35:16344--16359
2022
-
[9]
Alessio Devoto, Maximilian Jeblick, and Simon J \'e gou. 2025. https://arxiv.org/abs/2510.00636 Expected attention: Kv cache compression by estimating attention from future queries distribution . arXiv preprint arXiv:2510.00636
arXiv 2025
-
[10]
Yuan Feng, Junlin Lv, Yukun Cao, Xike Xie, and S Kevin Zhou. 2025. https://arxiv.org/abs/2502.03805 Identify critical kv cache in llm inference from an output perturbation perspective . arXiv preprint arXiv:2502.03805
Pith/arXiv arXiv 2025
-
[11]
Yuan Feng, Junlin Lv, Yukun Cao, Xike Xie, and S Kevin Zhou. 2026. https://proceedings.neurips.cc/paper_files/paper/2025/file/a40ff56daab9f4808b1e18350c8a11ce-Paper-Conference.pdf Ada-kv: Optimizing kv cache eviction by adaptive budget allocation for efficient llm inference . Advances in Neural Information Processing Systems, 38:113152--113188
2026
-
[12]
Yu Fu, Zefan Cai, Abedelkadir Asi, Wayne Xiong, Yue Dong, and Wen Xiao. 2025. https://proceedings.iclr.cc/paper_files/paper/2025/file/f649556471416b35e60ae0de7c1e3619-Paper-Conference.pdf Not all heads matter: A head-level kv cache compression method with integrated retrieval and reasoning . In International Conference on Learning Representations, volume ...
2025
-
[13]
Suyu Ge, Yunan Zhang, Liyuan Liu, Minjia Zhang, Jiawei Han, and Jianfeng Gao. 2024. https://proceedings.iclr.cc/paper_files/paper/2024/file/639a9a172c044fbb64175b5fad42e9a5-Paper-Conference.pdf Model tells you what to discard: Adaptive kv cache compression for llms . In International Conference on Learning Representations, volume 2024, pages 22975--22988
2024
-
[14]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, and 1 others. 2024. https://arxiv.org/abs/2407.21783 The llama 3 herd of models . arXiv preprint arXiv:2407.21783
Pith/arXiv arXiv 2024
-
[15]
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, Yang Zhang, and Boris Ginsburg. 2024. https://arxiv.org/abs/2404.06654 Ruler: What's the real context size of your long-context language models? arXiv preprint arXiv:2404.06654
Pith/arXiv arXiv 2024
-
[16]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, L \'e lio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timoth \'e e Lacroix, and William El Sayed. 2023. https://arxiv.org/ab...
Pith/arXiv arXiv 2023
-
[17]
Tom \'a s Ko c isk \'y , Jonathan Schwarz, Phil Blunsom, Chris Dyer, Karl Moritz Hermann, G \'a bor Melis, and Edward Grefenstette. 2018. https://doi.org/10.1162/tacl_a_00023 The N arrative QA reading comprehension challenge . Transactions of the Association for Computational Linguistics, 6:317--328
-
[18]
Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen. 2024. https://doi.org/10.52202/079017-0722 Snapkv: Llm knows what you are looking for before generation . Advances in Neural Information Processing Systems, 37:22947--22970
-
[19]
Akide Liu, Jing Liu, Zizheng Pan, Yefei He, Gholamreza Haffari, and Bohan Zhuang. 2024. https://doi.org/10.52202/079017-4443 Minicache: Kv cache compression in depth dimension for large language models . Advances in Neural Information Processing Systems, 37:139997--140031
-
[20]
Zichang Liu, Aditya Desai, Fangshuo Liao, Weitao Wang, Victor Xie, Zhaozhuo Xu, Anastasios Kyrillidis, and Anshumali Shrivastava. 2023. https://proceedings.neurips.cc/paper_files/paper/2023/file/a452a7c6c463e4ae8fbdc614c6e983e6-Paper-Conference.pdf Scissorhands: Exploiting the persistence of importance hypothesis for llm kv cache compression at test time ...
2023
-
[21]
Matanel Oren, Michael Hassid, Nir Yarden, Yossi Adi, and Roy Schwartz. 2024. https://doi.org/10.18653/v1/2024.emnlp-main.1043 Transformers are multi-state RNN s . In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 18724--18741, Miami, Florida, USA. Association for Computational Linguistics
-
[22]
Myle Ott, Sergey Edunov, Alexei Baevski, Angela Fan, Sam Gross, Nathan Ng, David Grangier, and Michael Auli. 2019. https://doi.org/10.18653/v1/N19-4009 fairseq: A fast, extensible toolkit for sequence modeling . In Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics (Demonstrations) , pages 48...
-
[23]
Siyu Ren and Kenny Q Zhu. 2024. https://arxiv.org/abs/2402.06262 On the efficacy of eviction policy for key-value constrained generative language model inference . arXiv preprint arXiv:2402.06262
arXiv 2024
-
[24]
Gemma Team, Morgane Riviere, Shreya Pathak, Pier Giuseppe Sessa, Cassidy Hardin, Surya Bhupatiraju, L \'e onard Hussenot, Thomas Mesnard, Bobak Shahriari, Alexandre Ram \'e , and 1 others. 2024. https://arxiv.org/abs/2408.00118 Gemma 2: Improving open language models at a practical size . arXiv preprint arXiv:2408.00118
Pith/arXiv arXiv 2024
-
[25]
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timoth \'e e Lacroix, Baptiste Rozi \`e re, Naman Goyal, Eric Hambro, Faisal Azhar, and 1 others. 2023 a . https://arxiv.org/abs/2302.13971 Llama: Open and efficient foundation language models . arXiv preprint arXiv:2302.13971
Pith/arXiv arXiv 2023
-
[26]
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, and 1 others. 2023 b . https://arxiv.org/abs/2307.09288 Llama 2: Open foundation and fine-tuned chat models . arXiv preprint arXiv:2307.09288
Pith/arXiv arXiv 2023
-
[27]
Zhongwei Wan, Xinjian Wu, Yu Zhang, Yi Xin, Chaofan Tao, Zhihong Zhu, Xin Wang, Siqi Luo, Jing Xiong, Longyue Wang, and 1 others. 2025. https://proceedings.iclr.cc/paper_files/paper/2025/file/d862f7f5445255090de13b825b880d59-Paper-Conference.pdf D2o: Dynamic discriminative operations for efficient long-context inference of large language models . In Inter...
2025
-
[28]
Yixuan Wang, Haoyu Qiao, Lujun Li, Qingfu Zhu, and Wanxiang Che. 2025. https://arxiv.org/abs/2508.16134 Commonkv: Compressing kv cache with cross-layer parameter sharing . arXiv preprint arXiv:2508.16134
arXiv 2025
-
[29]
Zheng Wang, Boxiao Jin, Zhongzhi Yu, and Minjia Zhang. 2024. https://arxiv.org/abs/2407.08454 Model tells you where to merge: Adaptive kv cache merging for llms on long-context tasks . arXiv preprint arXiv:2407.08454
arXiv 2024
-
[30]
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, and 3 others. 2020. https://doi.org/10.18653/v1/2020.emnlp-demos.6 Transformers: Sta...
-
[31]
Haoyi Wu and Kewei Tu. 2024. https://doi.org/10.18653/v1/2024.acl-long.602 Layer-condensed KV cache for efficient inference of large language models . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 11175--11188, Bangkok, Thailand. Association for Computational Linguistics
-
[32]
Guangxuan Xiao, Jiaming Tang, Jingwei Zuo, Junxian Guo, Shang Yang, Haotian Tang, Yao Fu, and Song Han. 2025. https://proceedings.iclr.cc/paper_files/paper/2025/file/5c1ddd2e59df46fd2aa85c833b1b36ed-Paper-Conference.pdf Duoattention: Efficient long-context llm inference with retrieval and streaming heads . In International Conference on Learning Represent...
2025
-
[33]
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. 2024. https://proceedings.iclr.cc/paper_files/paper/2024/file/5e5fd18f863cbe6d8ae392a93fd271c9-Paper-Conference.pdf Efficient streaming language models with attention sinks . In International Conference on Learning Representations, volume 2024, pages 21875--21895
2024
-
[34]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, and 1 others. 2025. https://arxiv.org/abs/2505.09388 Qwen3 technical report . arXiv preprint arXiv:2505.09388
Pith/arXiv arXiv 2025
-
[35]
Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. 2018. https://doi.org/10.18653/v1/D18-1259 H otpot QA : A dataset for diverse, explainable multi-hop question answering . In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 2369--2380, Brussels...
-
[36]
Yuxin Zhang, Yuxuan Du, Gen Luo, Yunshan Zhong, Zhenyu Zhang, Shiwei Liu, and Rongrong Ji. 2024. https://openreview.net/forum?id=LCTmppB165 Cam: Cache merging for memory-efficient llms inference . In Forty-first international conference on machine learning
2024
-
[37]
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher R \'e , Clark Barrett, and 1 others. 2023. https://proceedings.neurips.cc/paper_files/paper/2023/file/6ceefa7b15572587b78ecfcebb2827f8-Paper-Conference.pdf H2o: Heavy-hitter oracle for efficient generative inference of large language model...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.