Multilingual and Cross-Lingual Citation Needed Detection on Wikipedia for Lower-Resource Languages
Pith reviewed 2026-06-28 22:45 UTC · model grok-4.3
The pith
Fine-tuned small language models outperform prompted large models for detecting missing citations on Wikipedia across 18 languages, including via English-only training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
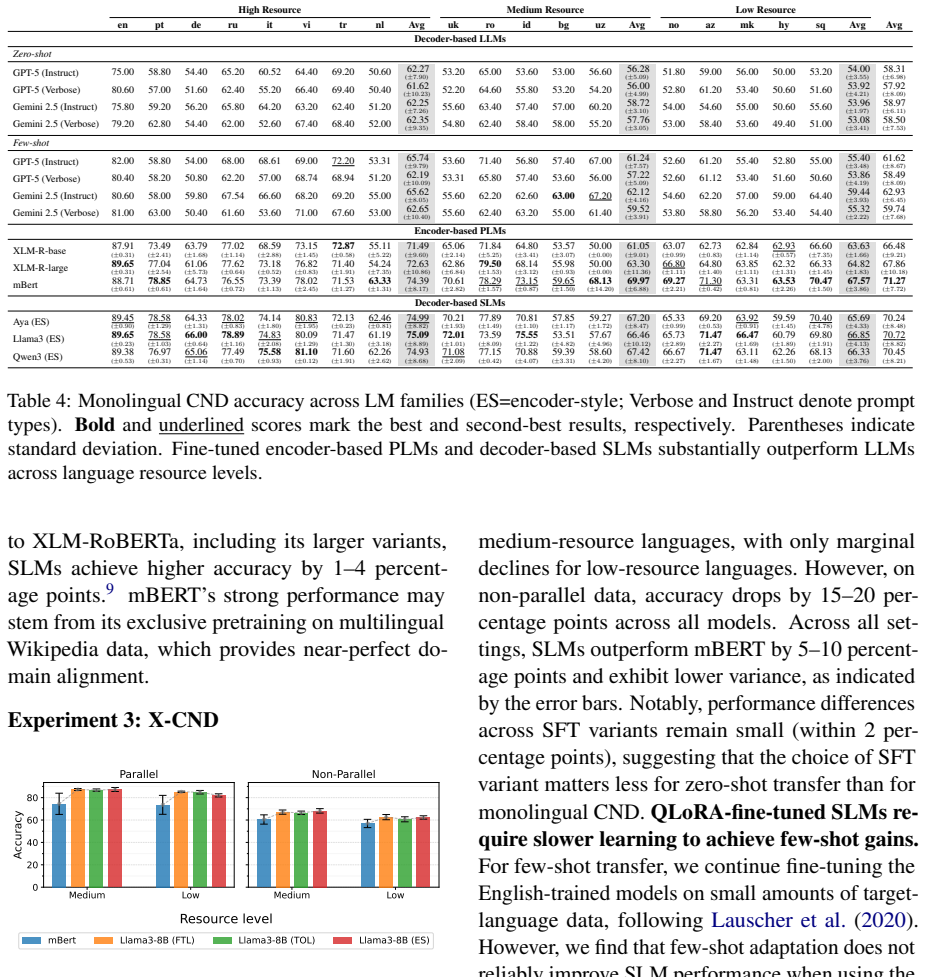
We introduce MCN, a multilingual CND corpus spanning 18 languages across three resource levels, on which we conduct an extensive study of small decoder-based language models (SLMs). Our experiments show that SLMs fine-tuned with an encoder-style objective substantially outperform prompted LLMs across languages. We further present one of the first studies on cross-lingual CND, demonstrating that SLMs fine-tuned solely on English claims surpass LLMs, even with little to no target-language adaptation.
What carries the argument
The MCN corpus paired with encoder-style fine-tuning of small decoder-based language models for the citation needed detection task.
If this is right
- Compact models become preferable to large models for citation needed detection in lower-resource Wikipedia settings.
- English-only fine-tuning transfers effectively to other languages for this task with minimal adaptation.
- Lower-resource communities gain a practical tool that does not require access to large language models.
- Task-specific fine-tuning on a dedicated corpus yields better results than prompting for citation needed detection.
Where Pith is reading between the lines
- The same fine-tuning approach could be tested on other narrow Wikipedia maintenance tasks beyond citation detection.
- If the pattern holds, organizations could maintain small specialized models instead of depending on general large models for repeated fact-checking steps.
- Cross-lingual gains may reduce the data collection burden for languages with few labeled examples.
Load-bearing premise
That the performance comparison between fine-tuned small models and prompted large models is fair and that the MCN corpus gives an unbiased sample of citation-needed claims across the 18 languages.
What would settle it
A re-evaluation on a fresh sample of Wikipedia claims from the same languages where prompted large models match or exceed the fine-tuned small models under identical evaluation rules.
Figures




read the original abstract
In automated fact-checking (AFC), check-worthiness detection identifies claims requiring verification based on domain-specific criteria. On Wikipedia, this task instantiates as Citation Needed Detection (CND), which flags claims lacking supporting citations. However, existing research has largely overlooked lower-resource languages, and recent AFC pipelines rely on large language models (LLMs), which are inaccessible to low-resource organizations. We introduce MCN, a multilingual CND corpus spanning 18 languages across three resource levels, on which we conduct an extensive study of small decoder-based language models (SLMs). Our experiments show that SLMs fine-tuned with an encoder-style objective substantially outperform prompted LLMs across languages. We further present one of the first studies on cross-lingual CND, demonstrating that SLMs fine-tuned solely on English claims surpass LLMs, even with little to no target-language adaptation. Our findings have important implications for lower-resource Wikipedia communities and suggest that compact, task-specific models are preferable to LLMs for CND. We release all data and code at https://github.com/gerritq/mcn
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the MCN corpus, a multilingual dataset for Citation Needed Detection (CND) spanning 18 languages across three resource levels. It evaluates small decoder-based language models (SLMs) fine-tuned using an encoder-style objective and reports that these models substantially outperform prompted large language models (LLMs) in both monolingual and cross-lingual settings; English-only fine-tuned SLMs are shown to surpass LLMs on target languages with minimal adaptation. The authors release the full dataset and code.
Significance. If the empirical results hold, the work is significant for lower-resource Wikipedia communities because it demonstrates that compact, task-specific models can be preferable to LLMs for CND and provides one of the first cross-lingual studies on the task. The public release of the MCN corpus and code is a clear strength that supports reproducibility and follow-on research.
minor comments (2)
- [Abstract] Abstract: the claim of outperformance is stated without reference to specific metrics, data splits, or statistical tests; adding one sentence summarizing the evaluation protocol would improve immediate verifiability.
- [Experiments] The comparison between fine-tuned SLMs and prompted LLMs is central; while code release mitigates this, a brief explicit statement in the experimental section confirming identical positive/negative sampling and metric computation across all 18 languages would strengthen the fairness claim.
Simulated Author's Rebuttal
We thank the referee for their positive summary of the MCN corpus, the significance assessment for lower-resource Wikipedia communities, and the recommendation of minor revision. No major comments were provided in the report.
Circularity Check
No circularity: empirical benchmarking study with released data
full rationale
The paper is an empirical study that introduces the MCN corpus spanning 18 languages and reports experimental comparisons between fine-tuned SLMs and prompted LLMs, including cross-lingual settings. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided abstract or description. The central claims rest on benchmark results and released code rather than any self-definitional or load-bearing reductions. This matches the default expectation for non-circular empirical work.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard machine learning assumptions including representative train/test splits and appropriate classification metrics.
Reference graph
Works this paper leans on
-
[1]
InWorking Notes of the Conference and Labs of the Evaluation Forum (CLEF 2024), CEUR Work- shop Proceedings, pages 276–286
Overview of the clef-2024 checkthat! lab task 1 on check-worthiness estimation of multigenre con- tent. InWorking Notes of the Conference and Labs of the Evaluation Forum (CLEF 2024), CEUR Work- shop Proceedings, pages 276–286. CEUR Workshop Proceedings. Publisher Copyright: © 2024 Copy- right for this paper by its authors.; 25th Working Notes of the Conf...
2024
-
[2]
Pratik Joshi, Sebastin Santy, Amar Budhiraja, Kalika Bali, and Monojit Choudhury
Wikimedia data for ai: a review of wikimedia datasets for nlp tasks and ai-assisted editing.arXiv preprint arXiv:2410.08918. Pratik Joshi, Sebastin Santy, Amar Budhiraja, Kalika Bali, and Monojit Choudhury. 2020. The state and fate of linguistic diversity and inclusion in the nlp world.arXiv preprint arXiv:2004.09095. Ashkan Kazemi, Kiran Garimella, Devin...
arXiv 2020
-
[3]
Automated fact-checking for assisting human fact-checkers.arXiv preprint arXiv:2103.07769. OpenAI. 2025. Gpt-5 system card. https://cdn. openai.com/gpt-5-system-card.pdf . Accessed: 20225-12-12. Rrubaa Panchendrarajan and Arkaitz Zubiaga. 2024. Claim detection for automated fact-checking: A sur- vey on monolingual, multilingual and cross-lingual research....
arXiv 2025
-
[4]
Show me the work: Fact-checkers’ require- ments for explainable automated fact-checking. In Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems, pages 1–21. Jason Wei, Maarten Bosma, Vincent Y Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, An- drew M Dai, and Quoc V Le. 2021. Finetuned lan- guage models are zero-shot learne...
Pith/arXiv arXiv 2025
-
[5]
: Quotation - The statement is a direct quotation or close paraphrase of a source . Statistics - The statement contains statistics or quantitative data . Controversial - The statement makes surprising or potentially controversial claims . Opinion - The statement expresses a person's subjective opinion or belief . Private Life - The statement contains clai...
arXiv 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.