Guidance for Low-Level Perceptual Editing in Unconditional Diffusion Models
Pith reviewed 2026-06-28 22:39 UTC · model grok-4.3
The pith
Degradation concept vectors steer unconditional diffusion sampling toward perceptually better images at inference time without retraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
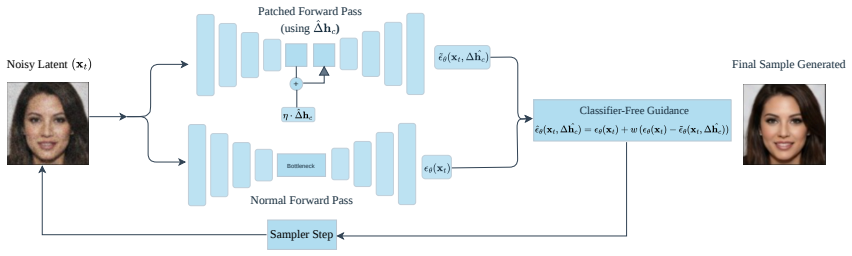
The central claim is that extracting degradation concept vectors and applying them through a combination of bottleneck patching and classifier-free guidance enables inference-time guidance that reliably moves sampling trajectories away from low-quality regions of the manifold, yielding images with improved perceptual properties compared with standard sampling or h-space patching alone.
What carries the argument
Degradation concept vectors extracted from low-level features, used to guide sampling by combining bottleneck patching with classifier-free guidance.
If this is right
- Unconditional diffusion models can receive targeted perceptual edits at test time without retraining.
- Sampling can be directed away from the degraded manifold using only information derived from the model's own features.
- Bottleneck-level interventions become effective for global changes when paired with classifier-free guidance.
- The same mechanism works across different unconditional models without architecture-specific changes.
Where Pith is reading between the lines
- The same vector extraction step could be tested on conditional diffusion models to see whether it adds control beyond the conditioning signal.
- If degradation vectors prove stable across different noise schedules, they might support iterative refinement loops that gradually push images toward higher quality.
- The approach suggests a route for attribute-specific editing by isolating other concept vectors from the same low-level feature space.
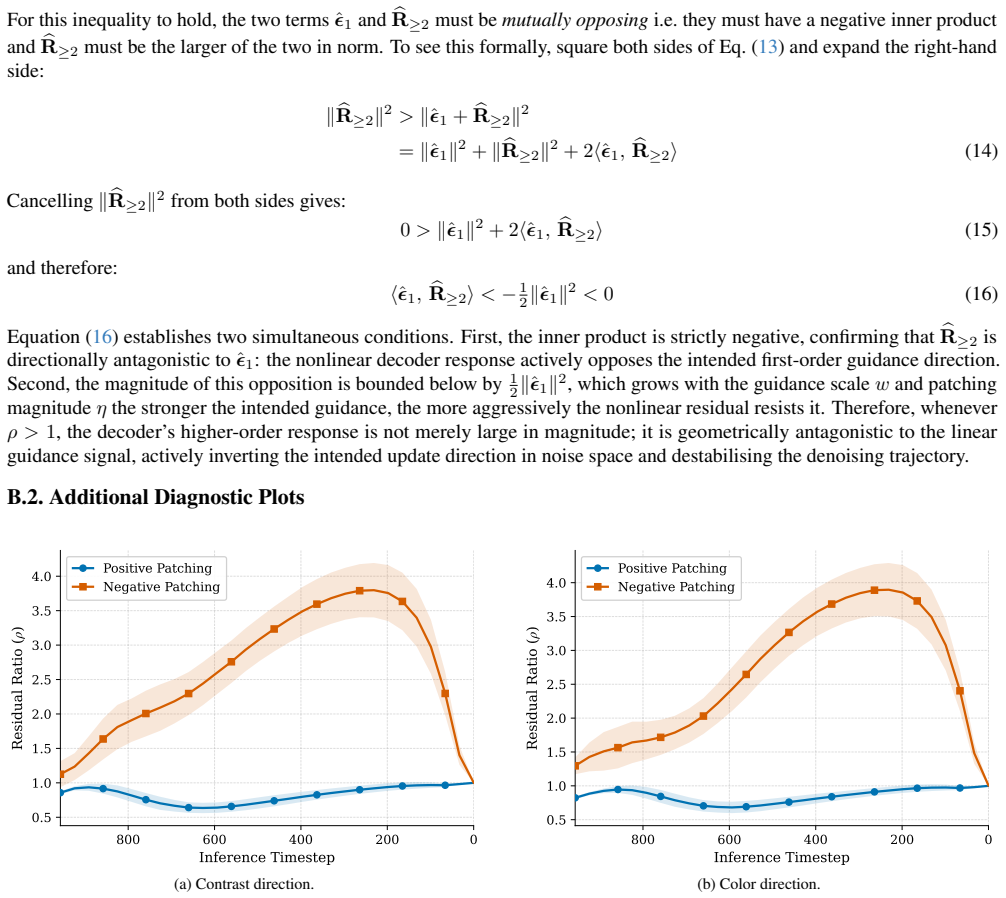
- Measuring how far the guided trajectories deviate from the original manifold could quantify the strength of the perceptual shift.
Load-bearing premise
The method assumes that h-space patching cannot produce the global low-level transformations required for aesthetic and perceptual refinement, so that the new degradation vectors can reliably steer sampling instead.
What would settle it
Running the method on the same prompts and seeds as standard sampling and h-space patching, then finding no consistent gain in perceptual metrics or human preference scores on the outputs, would show the central claim does not hold.
Figures









read the original abstract
Unconditional diffusion models offer powerful generative priors, yet steering them toward aesthetically enhanced outputs remains largely unexplored. We show that h-space patching, the dominant paradigm for training-free diffusion editing, systematically fails for global, low-level transformations required for aesthetic and perceptual refinement. We introduce a novel, generalized framework for image-editing in unconditional diffusion models without explicit training. This inference-time mechanism operates on low-level features by extracting degradation concept vectors and combining bottleneck patching with classifier-free guidance to guide sampling away from the degraded manifold, producing consistently improved images without any model retraining.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that h-space patching systematically fails for global, low-level transformations required for aesthetic and perceptual refinement in unconditional diffusion models. It introduces an inference-time framework that extracts degradation concept vectors and combines bottleneck patching with classifier-free guidance to steer sampling away from the degraded manifold, yielding consistently improved images without any model retraining.
Significance. If the central claims were substantiated with experiments and derivations, the work could fill a gap in training-free perceptual editing for unconditional diffusion models. As presented, however, the complete absence of any empirical validation, equations, or methodological details prevents any assessment of significance.
major comments (3)
- Abstract: the claims of systematic failure of h-space patching and consistent improvements from the new framework are stated without any experiments, data, derivations, or validation.
- Method description: the framework relies on undefined 'degradation concept vectors' whose extraction process is not specified, leaving open whether the construction is circular or reduces to ad-hoc fitting.
- The combination of bottleneck patching with classifier-free guidance is underspecified; no equation shows how a degradation concept vector is turned into a valid conditioning variable c in the standard CFG form ε_θ(x_t) + s(ε_θ(x_t,c) − ε_θ(x_t)), nor how the unconditional score is used for an unconditional model.
minor comments (1)
- The term 'bottleneck patching' is invoked without definition or citation to prior literature.
Simulated Author's Rebuttal
We thank the referee for their review and the opportunity to respond. We address each major comment below and commit to revisions where the manuscript is underspecified.
read point-by-point responses
-
Referee: Abstract: the claims of systematic failure of h-space patching and consistent improvements from the new framework are stated without any experiments, data, derivations, or validation.
Authors: The abstract is a high-level summary. The full manuscript contains the supporting experiments, quantitative results, and derivations in the dedicated Experiments and Method sections. To prevent any misinterpretation, we will revise the abstract to explicitly note that the claims are substantiated by the empirical and theoretical results presented later in the paper. revision: yes
-
Referee: Method description: the framework relies on undefined 'degradation concept vectors' whose extraction process is not specified, leaving open whether the construction is circular or reduces to ad-hoc fitting.
Authors: We agree that the current description of degradation concept vector extraction is insufficiently detailed. In the revised manuscript we will expand the Method section with a precise algorithmic description, including the exact procedure for obtaining the vectors from the diffusion model and any intermediate computations, to demonstrate that the process is well-defined and non-circular. revision: yes
-
Referee: The combination of bottleneck patching with classifier-free guidance is underspecified; no equation shows how a degradation concept vector is turned into a valid conditioning variable c in the standard CFG form ε_θ(x_t) + s(ε_θ(x_t,c) − ε_θ(x_t)), nor how the unconditional score is used for an unconditional model.
Authors: We acknowledge that the integration of the degradation concept vector into the CFG formulation is not formalized with an equation in the current version. We will add the explicit equation and accompanying derivation in the revised Method section, together with an explanation of how the unconditional score is utilized when applying the framework to an unconditional model. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The provided manuscript text consists of a high-level abstract and method description introducing degradation concept vectors and a combination of bottleneck patching with classifier-free guidance. No equations, parameter-fitting procedures, self-citations, or derivation steps are present that would allow any claim to reduce to its own inputs by construction. The central claims are presented as a novel inference-time mechanism rather than a mathematical derivation whose outputs are forced by the inputs. This is the common case of a self-contained proposal with no detectable circularity patterns.
Axiom & Free-Parameter Ledger
invented entities (1)
-
degradation concept vectors
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Self-rectifying diffusion sampling with perturbed-attention guidance
Donghoon Ahn, Hyoungwon Cho, Jaewon Min, Wooseok Jang, Jungwoo Kim, SeonHwa Kim, Hyun Hee Park, Ky- ong Hwan Jin, and Seungryong Kim. Self-rectifying diffusion sampling with perturbed-attention guidance. InECCV, 2024. 1
2024
-
[2]
Diffusion models beat GANs on image synthesis
Prafulla Dhariwal and Alex Nichol. Diffusion models beat GANs on image synthesis. InNeurIPS, 2021. 1
2021
-
[3]
The use of multiple measurements in tax- onomic problems.Annals of eugenics, 7(2):179–188, 1936
Ronald A Fisher. The use of multiple measurements in tax- onomic problems.Annals of eugenics, 7(2):179–188, 1936. 8
1936
-
[4]
Ingo Fr¨und, J. Patel, and E. D. Stalker. Contrast invariant tun- ing in human perception of image content.bioRxiv preprint 10.1101/711804, 2019. 1
-
[5]
Fengyi Fu, Mengqi Huang, Lei Zhang, and Zhendong Mao. Layeredit: Disentangled multi-object editing via conflict- aware multi-layer learning.arXiv preprint arXiv:2511.08251,
-
[6]
Concept sliders: LoRA adaptors for precise control in diffusion models
Rohit Gandikota, Joanna Materzynska, Tingrui Zhou, Anto- nio Torralba, and David Bau. Concept sliders: LoRA adaptors for precise control in diffusion models. InECCV, 2024. 2
2024
-
[7]
Generative adversarial nets
Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. InNeurIPS,
-
[8]
Discovering interpretable directions in the semantic latent space of diffusion models
Rene Haas, Inbar Huberman-Spiegelglas, Rotem Mulayoff, Stella Grasshof, Sami Sebastian Brandt, and Tomer Michaeli. Discovering interpretable directions in the semantic latent space of diffusion models. InIEEE International Conference on Automatic Face and Gesture Recognition, 2024. 1, 3, 9
2024
-
[9]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022. 1, 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
Denoising diffu- sion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffu- sion probabilistic models. InNeurIPS, 2020. 1
2020
-
[11]
Susung Hong. Smoothed energy guidance: Guiding diffusion models with reduced energy curvature of attention.arXiv preprint arXiv:2408.00760, 2024. 1
-
[12]
Improving sample quality of diffusion models using self-attention guidance
Susung Hong, Gyuseong Lee, Wooseok Jang, and Seungry- ong Kim. Improving sample quality of diffusion models using self-attention guidance. InICCV, pages 7428–7437, 2023. 1
2023
-
[13]
On the ”Steer- ability” of generative adversarial networks
Ali Jahanian, Lucy Chai, and Phillip Isola. On the ”Steer- ability” of generative adversarial networks. InICLR, 2020. 1
2020
-
[14]
Diffusion models already have a semantic latent space
Mingi Kwon, Jaeseok Jeong, and Youngjung Uh. Diffusion models already have a semantic latent space. InICLR, 2023. 1, 2, 3
2023
-
[15]
Deep learning face attributes in the wild
Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Deep learning face attributes in the wild. InICCV, pages 3730–3738, 2015. 9
2015
-
[16]
Beautification of images by generative adversarial networks
Amar Muˇsi´c, Anne-Sofie Maertens, and Johan Wagemans. Beautification of images by generative adversarial networks. J. Vis., 23(10):14, 2023. 1
2023
-
[17]
arXiv preprint arXiv:2302.12469 , year=
Yong-Hyun Park, Mingi Kwon, Junghyo Jo, and Youngjung Uh. Unsupervised discovery of semantic latent directions in diffusion models.arXiv preprint arXiv:2302.12469, 2023. 1, 3
-
[18]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InProceedings of the 38th International Conference on Machine Learning, pages 8748–8763, 2021. 9
2021
-
[19]
Rethinking the spatial inconsistency in classifier- free diffusion guidance
Dazhong Shen, Guanglu Song, Zeyue Xue, Fu-Yun Wang, and Yu Liu. Rethinking the spatial inconsistency in classifier- free diffusion guidance. InCVPR, 2024. 1
2024
-
[20]
Denoising diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. InICLR, 2021. 1
2021
-
[21]
steerability
Nurit Spingarn, Ron Banner, and Tomer Michaeli. GAN “steerability” without optimization. InICLR, 2021. 1 5 Appendix A. Transformations For each contrastive pair, the degraded image is obtained by applying the transformation to the clean RGB image prior to resizing and normalization. The three transformations are defined as follows. Blur.The blurred image˜...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.