Point-in-Time Financial RAG with Frozen LLMs and Market-Feedback Adaptive Retrieval
Pith reviewed 2026-06-28 22:29 UTC · model grok-4.3
The pith
Adapting retrieval with Bayesian source memory from matured market returns improves financial RAG while keeping the LLM frozen.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By maintaining a frozen LLM reader and adapting retrieval through an external Bayesian source memory updated from matured residual-return feedback, the system achieves better point-in-time predictions of multi-horizon residual-return signals from news and SEC filings.
What carries the argument
Bayesian source memory that updates source rankings based on matured residual-return feedback to guide retrieval of financial news and SEC passages.
If this is right
- Retrieval adaptation can match or exceed gains from reader fine-tuning under static retrieval.
- Point-in-time setups with market feedback allow modular updates without retraining the core model.
- Source memory enables handling varying utility of evidence types across market contexts.
- Portfolio performance improves when retrieval prioritizes sources that historically delivered accurate signals.
Where Pith is reading between the lines
- This modular separation of retrieval adaptation from reading might reduce computational costs in deploying financial LLMs.
- Similar feedback-driven memory could apply to other time-sensitive prediction domains like medical or legal retrieval.
- Testing the method on broader stock universes or different asset classes would clarify its scalability.
Load-bearing premise
Matured residual-return feedback provides a reliable, unbiased signal for updating source utility that generalizes to future unseen events.
What would settle it
On a subsequent out-of-sample period after the study, applying the source memory adaptation yields no improvement or a decline in macro-F1 or Sharpe ratio compared to no-memory baseline.
Figures

read the original abstract
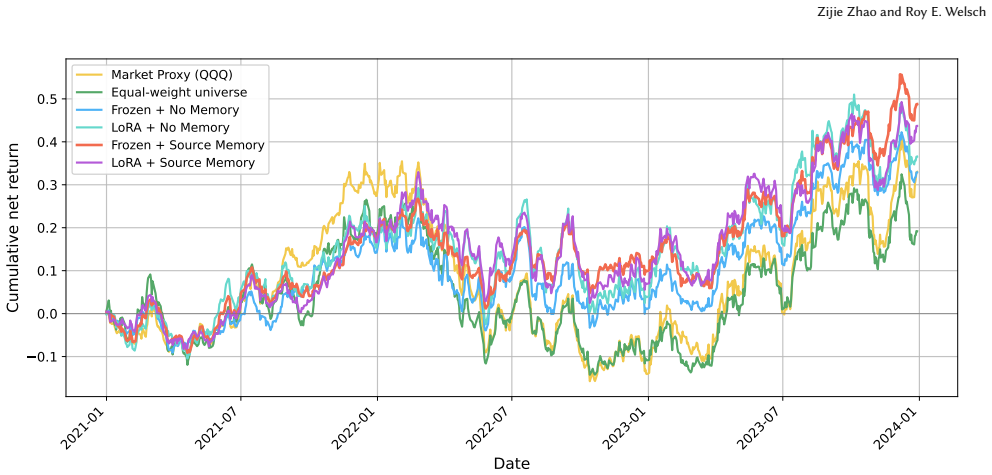
Financial retrieval-augmented generation (RAG) systems typically rank evidence by textual relevance, but in financial markets evidence utility depends on event type, forecast horizon, and market context. We study news-triggered event-impact prediction as a point-in-time financial RAG problem. For each company-news anchor, the system retrieves financial news and SEC filing passages, appends a pre-decision market-context card, and predicts multi-horizon residual-return signals. Our method keeps the LLM frozen and adapts retrieval through an external Bayesian source memory updated from matured residual-return feedback. On a fixed 89-stock Nasdaq-oriented universe derived from the FinRL-DeepSeek/FNSPID task, using original FNSPID news and point-in-time EDGAR filing passages, Frozen Reader with Source Memory improves held-out macro-F1 from 0.438 to 0.471 and downstream portfolio Sharpe from 0.52 to 0.84 relative to Frozen Reader with No Memory. Supervised LoRA gives modest gains under static retrieval, but after source-memory adaptation, the LoRA reader does not improve over the frozen reader. These results suggest that, for financial RAG systems, learning where to retrieve can be as important as learning how to read, offering a modular route to market-feedback adaptation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a point-in-time financial RAG system for news-triggered event-impact prediction that keeps the LLM frozen and adapts retrieval via an external Bayesian source memory updated from matured residual-return feedback. On a fixed 89-stock Nasdaq universe with original FNSPID news and point-in-time EDGAR passages, the Frozen Reader with Source Memory improves held-out macro-F1 from 0.438 to 0.471 and downstream portfolio Sharpe from 0.52 to 0.84 relative to the no-memory baseline; supervised LoRA yields only modest gains under static retrieval and none after source-memory adaptation.
Significance. If the point-in-time integrity of the feedback loop holds, the result would indicate that market-feedback adaptation of retrieval can be more effective than reader fine-tuning for financial RAG, offering a modular alternative that avoids retraining the underlying LLM. The use of a fixed universe and point-in-time EDGAR passages strengthens the evaluation design.
major comments (1)
- [Abstract / Methods] Abstract and Methods: the central claim that Bayesian source-memory updates from matured residual returns remain strictly causal and generalize without lookahead or selection bias is load-bearing for the reported macro-F1 and Sharpe gains, yet the manuscript provides no explicit description of (a) the exact maturation lag relative to the multi-horizon prediction windows, (b) whether any update window overlaps test-period events, or (c) the filtering rule applied to negative or zero-return cases before memory adjustment.
minor comments (1)
- [Abstract] The abstract refers to 'matured residual-return feedback' without defining the precise residual-return calculation or the Bayesian update rule; a short methods subsection or appendix equation would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed review and for emphasizing the importance of explicitly documenting the point-in-time properties of the Bayesian source-memory updates. We address the major comment below and will incorporate the requested clarifications in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract / Methods] Abstract and Methods: the central claim that Bayesian source-memory updates from matured residual returns remain strictly causal and generalize without lookahead or selection bias is load-bearing for the reported macro-F1 and Sharpe gains, yet the manuscript provides no explicit description of (a) the exact maturation lag relative to the multi-horizon prediction windows, (b) whether any update window overlaps test-period events, or (c) the filtering rule applied to negative or zero-return cases before memory adjustment.
Authors: We agree that the manuscript currently lacks an explicit description of these parameters, which is necessary to fully substantiate the claim of strict causality. In the revised version we will expand the Methods section with a dedicated paragraph that specifies (a) the maturation lag relative to the multi-horizon windows, (b) confirmation that update windows do not overlap test-period events under the rolling point-in-time protocol, and (c) the exact filtering rule applied to negative or zero-return cases. These additions will make the experimental design transparent without altering the reported results or experimental setup. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper presents an external Bayesian source memory updated from matured residual-return feedback as the adaptation mechanism, with performance gains reported as empirical results on held-out point-in-time data. No equations, self-citations, or steps are described that reduce the claimed predictions or improvements to fitted inputs by construction, self-definitional loops, or load-bearing self-citations. The central claim relies on external market feedback rather than internal tautologies, making the derivation self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- Bayesian source memory update parameters
axioms (1)
- domain assumption Point-in-time data availability for EDGAR filings and news without future leakage
invented entities (1)
-
Bayesian source memory
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Apple. 2020. Apple Reports Second Quarter Results. https://www.apple.com/ne wsroom/2020/04/apple-reports-second-quarter-results/. Accessed 2026
2020
-
[2]
Benzinga. 2020. Apple Reports Big Q2 Earnings Beat, Driven By Record Services Revenue. https://www.benzinga.com/news/earnings/20/04/15927541/apple- reports-big-q2-earnings-beat-driven-by-record-services-revenue. Accessed 2026
2020
-
[3]
Chanyeol Choi, Jihoon Kwon, Jaeseon Ha, Hojun Choi, Chaewoon Kim, Yongjae Lee, Jy-yong Sohn, and Alejandro Lopez-Lira. 2025. FinDER: Financial Dataset for Question Answering and Evaluating Retrieval-Augmented Generation. In Proceedings of the 6th ACM International Conference on AI in Finance. Association for Computing Machinery, 638–646. doi:10.1145/37682...
-
[4]
Chanyeol Choi, Jihoon Kwon, Alejandro Lopez-Lira, Chaewoon Kim, Minjae Kim, Juneha Hwang, Jaeseon Ha, Hojun Choi, Suyeol Yun, Yongjin Kim, and Yongjae Lee. 2025. FinAgentBench: A Benchmark Dataset for Agentic Retrieval in Financial Question Answering. InProceedings of the 6th ACM International Conference on AI in Finance. Association for Computing Machine...
- [5]
-
[6]
FinRL Contest. 2025. Task 1: FinRL-DeepSeek Stock-News Benchmark. https: //finrl-contest.readthedocs.io/en/latest/finrl2025/task1.html. Accessed 2026
2025
-
[7]
Chinmay Gondhalekar, Urjitkumar Patel, and Fang-Chun Yeh. 2025. Multi- FinRAG: An Optimized Multimodal Retrieval-Augmented Generation Frame- work for Financial Question Answering. arXiv:2506.20821 [cs.IR] https: //arxiv.org/abs/2506.20821
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Tian Guo and Emmanuel Hauptmann. 2024. Fine-Tuning Large Language Models for Stock Return Prediction Using Newsflow. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track. Association for Computational Linguistics, Miami, Florida, USA, 1028–1045. doi:10.18653/v 1/2024.emnlp-industry.77
work page doi:10.18653/v 2024
-
[9]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. LoRA: Low-Rank Adaptation of Large Language Models. InInternational Conference on Learning Representations. https://openreview.net/forum?id=nZeVKeeFYf9
2022
-
[10]
Giorgos Iacovides, Thanos Konstantinidis, Mingxue Xu, and Danilo P. Mandic
-
[11]
InProceedings of the 5th ACM International Conference on AI in Finance
FinLlama: LLM-Based Financial Sentiment Analysis for Algorithmic Trad- ing. InProceedings of the 5th ACM International Conference on AI in Finance. Association for Computing Machinery, 134–141. doi:10.1145/3677052.3698696
- [12]
-
[13]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. InAdvances in Neural Informa- tion Processing Systems, Vol. 33. 9459–9474. https://proceedings....
2020
- [14]
-
[15]
A. Craig MacKinlay. 1997. Event Studies in Economics and Finance.Journal of Economic Literature35, 1 (1997), 13–39. https://www.jstor.org/stable/2729691
-
[16]
Meta. 2024. Llama-3.1-8B-Instruct Model Card. https://huggingface.co/meta- llama/Llama-3.1-8B-Instruct. Accessed 2026
2024
-
[17]
Qwen Team. 2025. Qwen3-8B Model Card. https://huggingface.co/Qwen/Qwen3- 8B. Accessed 2026
2025
-
[18]
Securities and Exchange Commission
U.S. Securities and Exchange Commission. 2020. Apple Inc. Form 8-K, April 30,
2020
-
[19]
Accessed 2026
https://www.sec.gov/Archives/edgar/data/320193/000032019320000050/a8- kq220203282020.htm. Accessed 2026
2026
-
[20]
Securities and Exchange Commission
U.S. Securities and Exchange Commission. 2024. EDGAR Application Program- ming Interfaces. https://www.sec.gov/search-filings/edgar-application- programming-interfaces. Accessed 2026
2024
-
[21]
Yang, and Xiao-Yang Liu
Dannong Wang, Jaisal Patel, Daochen Zha, Steve Y. Yang, and Xiao-Yang Liu
-
[22]
arXiv:2505.19819 [cs.CL] https://arxiv.org/abs/2505.19819
FinLoRA: Benchmarking LoRA Methods for Fine-Tuning LLMs on Financial Datasets. arXiv:2505.19819 [cs.CL] https://arxiv.org/abs/2505.19819
- [23]
-
[24]
Boyu Zhang, Hongyang Yang, Tianyu Zhou, Muhammad Ali Babar, and Xiao- Yang Liu. 2023. Enhancing Financial Sentiment Analysis via Retrieval Augmented Large Language Models. InProceedings of the 4th ACM International Conference on AI in Finance. Association for Computing Machinery, 349–356. doi:10.1145/36 04237.3626866
work page doi:10.1145/36 2023
-
[25]
Zijie Zhao and Roy E. Welsch. 2024. Aligning LLMs with Human Instructions and Stock Market Feedback in Financial Sentiment Analysis. arXiv:2410.14926 [cs.CE] https://arxiv.org/abs/2410.14926 7 Zijie Zhao and Roy E. Welsch A Event-Type Mapping Event types are assigned before retrieval by a deterministic rule- based mapper over the news anchor. The mapper u...
-
[26]
Results of Operations and Financial Condition,
The anchor headline isApple Reports Big Q2 Earnings Beat, Driven By Record Services Revenue, corresponding to a Benzinga earnings article reporting Apple’s fiscal Q2 2020 results [2]. Apple also furnished a Form 8-K on April 30, 2020. The filing reports fiscal Q2 results under Item 2.02, “Results of Operations and Financial Condition, ” and attaches the c...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.