SurGe: Improved Surface Geometry in Point Maps
Pith reviewed 2026-06-28 22:27 UTC · model grok-4.3
The pith
SurGe improves local surface geometry in point map predictions by adding a gradient matching loss and neighborhood attention decoder.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
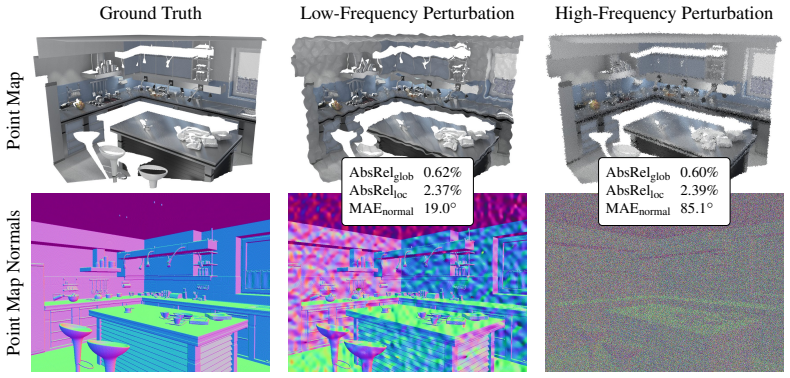
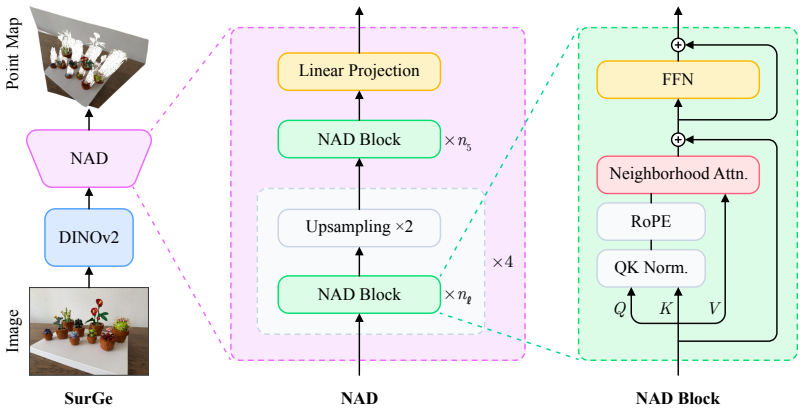
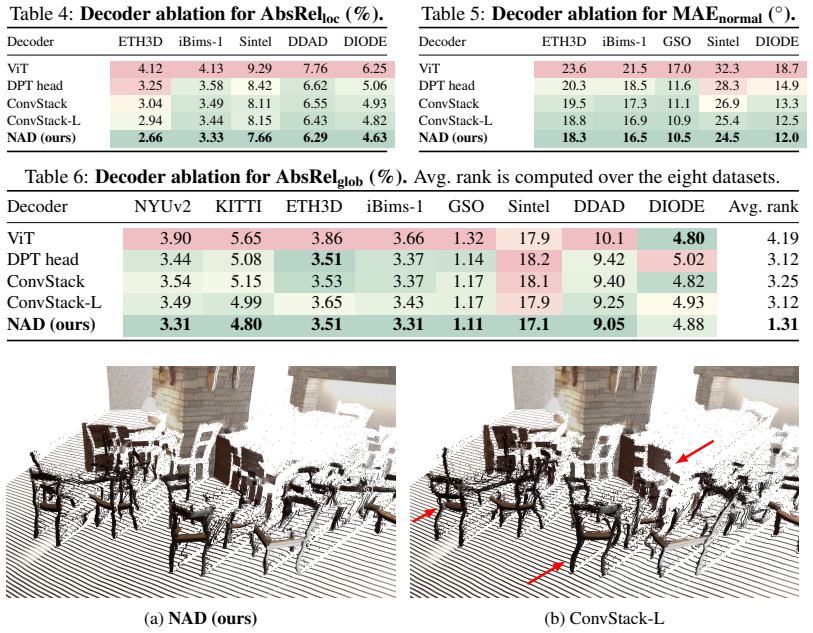
A point gradient matching loss that supervises depth-normalized 3D finite differences, paired with a Neighborhood Attention Decoder that progressively upsamples and mixes local features via neighborhood attention, yields point maps with more accurate local surface geometry as measured by a new point map normal metric, while also securing the best average rank on global point map AbsRel across eight zero-shot monocular geometry benchmarks.
What carries the argument
The point gradient matching loss, which supervises depth-normalized 3D finite differences, together with the Neighborhood Attention Decoder that performs local feature mixing during progressive upsampling.
If this is right
- Local point map metrics rise consistently across benchmarks.
- Point map normal evaluations improve alongside global AbsRel scores.
- The model holds the top average rank on global point map accuracy in zero-shot settings.
- The same components can be added to existing point map predictors to target local surface errors.
Where Pith is reading between the lines
- Better local geometry in raw point maps could reduce the need for post-processing steps in surface reconstruction pipelines.
- The introduced normal metric could be adopted more widely to evaluate and compare local accuracy in future monocular 3D methods.
- Neighborhood attention during decoding might transfer to other dense prediction tasks where local consistency matters.
Load-bearing premise
The measured gains in local point map and normal metrics come from the gradient matching loss and Neighborhood Attention Decoder rather than from differences in training schedule, data, or model capacity.
What would settle it
An experiment that trains the base architecture with the exact same schedule and data but without the gradient matching loss and NAD, then measures whether local point map and normal metrics still improve at the same rate.
Figures

read the original abstract
Recent feedforward 3D reconstruction methods predict point maps and estimate global 3D geometry remarkably well. However, their predictions still exhibit inaccurate local surface geometry, which is clearly visible qualitatively but only weakly reflected in common metrics. To make these errors more explicit in evaluation, we introduce a point map normal metric that evaluates the local surface orientation induced by neighboring 3D predictions. To reduce these errors, we propose two complementary components: a point gradient matching loss that supervises depth-normalized 3D finite differences, and a Neighborhood Attention Decoder (NAD) that progressively upsamples features and uses Neighborhood Attention for local feature mixing. Across eight zero-shot monocular geometry benchmarks, our model, SurGe, achieves the best average rank for global point map AbsRel and consistently improves local point map and point map normal evaluations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that current feedforward point-map methods produce inaccurate local surface geometry despite good global performance. It introduces a point-map normal metric to expose these errors, proposes a point gradient matching loss (supervising depth-normalized 3D finite differences) together with a Neighborhood Attention Decoder (NAD) for progressive upsampling and local feature mixing, and reports that the resulting SurGe model obtains the best average rank on global AbsRel across eight zero-shot monocular geometry benchmarks while also improving the local point-map and normal metrics.
Significance. If the reported gains can be shown to arise specifically from the gradient-matching loss and NAD rather than from uncontrolled differences in training schedule, augmentation, or capacity, the work would supply a concrete, modular improvement to local geometry fidelity in feedforward reconstruction pipelines and a new evaluation axis (point-map normals) that makes local surface errors more visible.
major comments (2)
- [Abstract / Experiments] The central attribution claim—that the observed improvements in local point-map and point-map normal metrics are produced by the point gradient matching loss and NAD—is not isolated from confounding variables. The abstract states that SurGe is compared against prior methods but supplies no information on whether those baselines were retrained under identical schedules, augmentations, or parameter counts; without such controls the performance delta cannot be confidently assigned to the two proposed components.
- [Experiments] No quantitative tables, ablation studies, or error analysis appear in the abstract, and the soundness assessment notes that the full manuscript must be checked for statistical significance, baseline matching, and metric definitions; if these are absent or incomplete in §4 or §5 the empirical support for the “consistently improves” claim is insufficient.
minor comments (1)
- [Abstract] The abstract would be strengthened by a single sentence or parenthetical reference to the key quantitative deltas or table numbers that support the “best average rank” and “consistently improves” statements.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with clarifications from the manuscript and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Abstract / Experiments] The central attribution claim—that the observed improvements in local point-map and point-map normal metrics are produced by the point gradient matching loss and NAD—is not isolated from confounding variables. The abstract states that SurGe is compared against prior methods but supplies no information on whether those baselines were retrained under identical schedules, augmentations, or parameter counts; without such controls the performance delta cannot be confidently assigned to the two proposed components.
Authors: We agree the abstract provides no explicit information on baseline retraining. The full manuscript compares SurGe to the originally reported numbers from prior works, following standard practice for zero-shot monocular geometry benchmarks. However, Section 5 contains controlled ablations that fix training schedule, augmentations, and model capacity while varying only the gradient matching loss and NAD; these isolate the contributions of each component. We will revise the abstract to reference the ablation controls and add a brief statement on baseline evaluation protocol. revision: partial
-
Referee: [Experiments] No quantitative tables, ablation studies, or error analysis appear in the abstract, and the soundness assessment notes that the full manuscript must be checked for statistical significance, baseline matching, and metric definitions; if these are absent or incomplete in §4 or §5 the empirical support for the “consistently improves” claim is insufficient.
Authors: Quantitative tables, ablation studies, and error analysis are presented in Sections 4 and 5 of the full manuscript rather than the abstract, which is a high-level summary. Section 4 reports global AbsRel ranks and local point-map/normal metrics across the eight benchmarks; Section 5 provides ablations and qualitative error analysis. Metric definitions appear in Section 3, baselines follow the same evaluation protocol, and statistical significance is assessed via standard paired comparisons. No changes are required. revision: no
Circularity Check
No circularity; empirical claims rest on external benchmarks
full rationale
The paper introduces a point gradient matching loss and Neighborhood Attention Decoder, then reports empirical rankings on eight zero-shot monocular geometry benchmarks. No equations, derivations, or first-principles results appear in the abstract or described claims. Performance deltas are attributed to the proposed components via direct comparison against prior methods, with no self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations that reduce the central result to its own inputs by construction. The evaluation chain is therefore self-contained against external data rather than internally forced.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Neighborhood Attention Decoder (NAD)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
J. L. Ba, J. R. Kiros, and G. E. Hinton. Layer normalization.arXiv preprint arXiv:1607.06450, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[2]
Baruch, Z
G. Baruch, Z. Chen, A. Dehghan, T. Dimry, Y . Feigin, P. Fu, T. Gebauer, B. Joffe, D. Kurz, A. Schwartz, and E. Shulman. ARKitscenes - a diverse real-world dataset for 3d indoor scene understanding using mobile RGB-d data. InNeurIPS Datasets and Benchmarks Track, 2021
2021
-
[3]
Bochkovskii, A
A. Bochkovskii, A. Delaunoy, H. Germain, M. Santos, Y . Zhou, S. R. Richter, and V . Koltun. Depth Pro: Sharp monocular metric depth in less than a second. InICLR, 2025
2025
-
[4]
D. J. Butler, J. Wulff, G. B. Stanley, and M. J. Black. A naturalistic open source movie for optical flow evaluation. InECCV, 2012
2012
-
[5]
L. Chambon, P. Couairon, E. Zablocki, A. Boulch, N. Thome, and M. Cord. Naf: Zero-shot feature upsampling via neighborhood attention filtering, 2025. URLhttps://arxiv.org/abs/2511.18452
-
[6]
Dehghani, J
M. Dehghani, J. Djolonga, B. Mustafa, P. Padlewski, J. Heek, J. Gilmer, A. P. Steiner, M. Caron, R. Geirhos, I. Alabdulmohsin, et al. Scaling vision transformers to 22 billion parameters. InICML, 2023
2023
-
[7]
InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
M. Deitke, D. Schwenk, J. Salvador, L. Weihs, O. Michel, E. VanderBilt, L. Schmidt, K. Ehsani, A. Kemb- havi, and A. Farhadi. Objaverse: A universe of annotated 3d objects.arXiv preprint arXiv:2212.08051, 2022
-
[8]
Z. Ding, Y . Zhang, C. Zhu, G. Zhang, X. Li, N. Jiang, Y . Que, Y . Peng, and X. Guan. Cat-unet: An enhanced u-net architecture with coordinate attention and skip-neighborhood attention transformer for medical image segmentation.Information Sciences, 2024
2024
-
[9]
Dosovitskiy, L
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Min- derer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InICLR, 2021
2021
-
[10]
Downs, A
L. Downs, A. Francis, N. Koenig, B. Kinman, R. Hickman, K. Reymann, T. B. McHugh, and V . Vanhoucke. Google scanned objects: A high-quality dataset of 3D scanned household items. InICRA, 2022
2022
-
[11]
Fonder and M
M. Fonder and M. V . Droogenbroeck. Mid-air: A multi-modal dataset for extremely low altitude drone flights. InCVPR Workshops, 2019. 10
2019
-
[12]
Guizilini, R
V . Guizilini, R. Ambrus, S. Pillai, A. Raventos, and A. Gaidon. 3D packing for self-supervised monocular depth estimation. InCVPR, 2020
2020
-
[13]
J. L. Gómez, M. Silva, A. Seoane, A. Borràs, M. Noriega, G. Ros, J. A. Iglesias-Guitian, and A. M. López. All for one, and one for all: Urbansyn dataset, the third musketeer of synthetic driving scenes. Neurocomputing, 2025
2025
-
[14]
A. Hassani and H. Shi. Dilated neighborhood attention transformer.arXiv preprint arXiv:2209.15001, 2022
-
[15]
Hassani, S
A. Hassani, S. Walton, J. Li, S. Li, and H. Shi. Neighborhood attention transformer. InCVPR, 2023
2023
-
[16]
Hassani, W.-M
A. Hassani, W.-M. Hwu, and H. Shi. Faster neighborhood attention: Reducing the O(n2) cost of self attention at the threadblock level. InAdvances in Neural Information Processing Systems, 2024
2024
-
[17]
A. Hassani, F. Zhou, A. Kane, J. Huang, C.-Y . Chen, M. Shi, S. Walton, M. Hoehnerbach, V . Thakkar, M. Isaev, et al. Generalized neighborhood attention: Multi-dimensional sparse attention at the speed of light.arXiv preprint arXiv:2504.16922, 2025
-
[18]
Hernandez-Juarez, L
D. Hernandez-Juarez, L. Schneider, A. Espinosa, D. Vazquez, A. M. Lopez, U. Franke, M. Pollefeys, and J. C. Moure. Slanted stixels: Representing san francisco’s steepest streets. InBMVC, 2017
2017
-
[19]
Huang, K
P.-H. Huang, K. Matzen, J. Kopf, N. Ahuja, and J.-B. Huang. Deepmvs: Learning multi-view stereopsis. InCVPR, 2018
2018
-
[20]
Keetha, N
N. Keetha, N. Müller, J. Schönberger, L. Porzi, Y . Zhang, T. Fischer, A. Knapitsch, D. Zauss, E. Weber, N. Antunes, J. Luiten, M. Lopez-Antequera, S. R. Bulò, C. Richardt, D. Ramanan, S. Scherer, and P. Kontschieder. MapAnything: Universal feed-forward metric 3D reconstruction. In3DV, 2026
2026
-
[21]
T. Koch, L. Liebel, F. Fraundorfer, and M. Körner. Evaluation of CNN-based single-image depth estimation methods. InECCV Workshops, 2018
2018
-
[22]
Y . Li, L. Jiang, L. Xu, Y . Xiangli, Z. Wang, D. Lin, and B. Dai. Matrixcity: A large-scale city dataset for city-scale neural rendering and beyond. InICCV, 2023
2023
-
[23]
Li and N
Z. Li and N. Snavely. MegaDepth: Learning single-view depth prediction from internet photos. InCVPR, 2018
2018
-
[24]
H. Lin, S. Chen, J. H. Liew, D. Y . Chen, Z. Li, G. Shi, J. Feng, and B. Kang. Depth Anything 3: recovering the visual space from any views. InICLR, 2026
2026
- [25]
-
[26]
Loshchilov and F
I. Loshchilov and F. Hutter. Decoupled weight decay regularization. InICLR, 2019
2019
-
[27]
Niklaus, L
S. Niklaus, L. Mai, J. Yang, and F. Liu. 3d ken burns effect from a single image.ACM TOG, 2019
2019
-
[28]
Odena, V
A. Odena, V . Dumoulin, and C. Olah. Deconvolution and checkerboard artifacts.Distill, 2016
2016
-
[29]
Oquab, T
M. Oquab, T. Darcet, T. Moutakanni, H. V . V o, M. Szafraniec, V . Khalidov, P. Fernandez, D. Haziza, F. Massa, A. El-Nouby, M. Assran, N. Ballas, W. Galuba, R. Howes, P.-Y . Huang, S.-W. Li, I. Misra, M. Rabbat, V . Sharma, G. Synnaeve, H. Xu, H. Jegou, J. Mairal, P. Labatut, A. Joulin, and P. Bojanowski. DINOv2: Learning robust visual features without s...
2024
-
[30]
Peebles and S
W. Peebles and S. Xie. Scalable diffusion models with transformers. InICCV, 2023
2023
-
[31]
Piccinelli, C
L. Piccinelli, C. Sakaridis, Y .-H. Yang, M. Segu, S. Li, W. Abbeloos, and L. V . Gool. UniDepthV2: Universal monocular metric depth estimation made simpler.IEEE TPAMI, 2026
2026
-
[32]
L. Qiu, G. Chen, X. Gu, Q. Zuo, M. Xu, Y . Wu, W. Yuan, Z. Dong, L. Bo, and X. Han. Richdreamer: A generalizable normal-depth diffusion model for detail richness in text-to-3d. InCVPR, 2024
2024
-
[33]
Ranftl, A
R. Ranftl, A. Bochkovskiy, and V . Koltun. Vision transformers for dense prediction. InICCV, 2021
2021
-
[34]
Ranftl, K
R. Ranftl, K. Lasinger, D. Hafner, K. Schindler, and V . Koltun. Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer.IEEE TPAMI, 2022
2022
-
[35]
Roberts, J
M. Roberts, J. Ramapuram, A. Ranjan, A. Kumar, M. A. Bautista, N. Paczan, R. Webb, and J. M. Susskind. Hypersim: A photorealistic synthetic dataset for holistic indoor scene understanding. InICCV, 2021. 11
2021
-
[36]
D. Saadati, O. N. Manzari, and S. Mirzakuchaki. Dilated-unet: A fast and accurate medical image segmentation approach using a dilated transformer and u-net architecture.arXiv preprint arXiv:2304.11450, 2023
-
[37]
Schöps, J
T. Schöps, J. L. Schönberger, S. Galliani, T. Sattler, K. Schindler, M. Pollefeys, and A. Geiger. A multi-view stereo benchmark with high-resolution images and multi-camera videos. InCVPR, 2017
2017
-
[38]
W. Shi, J. Caballero, F. Huszár, J. Totz, A. P. Aitken, R. Bishop, D. Rueckert, and Z. Wang. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In CVPR, 2016
2016
-
[39]
Silberman, D
N. Silberman, D. Hoiem, P. Kohli, and R. Fergus. Indoor segmentation and support inference from RGBD images. InECCV, 2012
2012
-
[40]
J. Su, M. Ahmed, Y . Lu, S. Pan, W. Bo, and Y . Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 2024
2024
-
[41]
P. Sun, H. Kretzschmar, X. Dotiwalla, A. Chouard, V . Patnaik, P. Tsui, J. Guo, Y . Zhou, Y . Chai, B. Caine, V . Vasudevan, W. Han, J. Ngiam, H. Zhao, A. Timofeev, S. Ettinger, M. Krivokon, A. Gao, A. Joshi, Y . Zhang, J. Shlens, Z. Chen, and D. Anguelov. Scalability in perception for autonomous driving: Waymo open dataset. InCVPR, 2020
2020
-
[42]
F. Tosi, Y . Liao, C. Schmitt, and A. Geiger. SMD-Nets: Stereo mixture density networks. InCVPR, 2021
2021
-
[43]
Touvron, M
H. Touvron, M. Cord, A. Sablayrolles, G. Synnaeve, and H. Jégou. Going deeper with image transformers. InICCV, 2021
2021
-
[44]
Uhrig, N
J. Uhrig, N. Schneider, L. Schneider, U. Franke, T. Brox, and A. Geiger. Sparsity invariant CNNs. In3DV, 2017
2017
-
[45]
Diode: A dense indoor and outdoor depth dataset.arXiv preprint arXiv:1908.00463, 2019
I. Vasiljevic, N. I. Kolkin, S. Zhang, R. Luo, H. Wang, F. Z. Dai, A. F. Daniele, M. Mostajabi, S. Basart, M. R. Walter, and G. Shakhnarovich. DIODE: A dense indoor and outdoor DEpth dataset.CoRR, abs/1908.00463, 2019
-
[46]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin. Attention is all you need. InNeurIPS, 2017
2017
-
[47]
J. Wang, M. Chen, N. Karaev, A. Vedaldi, C. Rupprecht, and D. Novotny. VGGT: Visual geometry grounded transformer. InCVPR, 2025
2025
-
[48]
Wang and S
K. Wang and S. Shen. Flow-motion and depth network for monocular stereo and beyond.IEEE Robotics and Automation Letters, 2020
2020
-
[49]
Q. Wang, S. Zheng, Q. Yan, F. Deng, K. Zhao, and X. Chu. Irs: A large naturalistic indoor robotics stereo dataset to train deep models for disparity and surface normal estimation. InICME, 2021
2021
-
[50]
R. Wang, S. Xu, C. Dai, J. Xiang, Y . Deng, X. Tong, and J. Yang. MoGe: Unlocking accurate monocular geometry estimation for open-domain images with optimal training supervision. InCVPR, 2025
2025
-
[51]
R. Wang, S. Xu, Y . Dong, Y . Deng, J. Xiang, Z. Lv, G. Sun, X. Tong, and J. Yang. MoGe-2: Accurate monocular geometry with metric scale and sharp details. InNeurIPS, 2025
2025
-
[52]
S. Wang, V . Leroy, Y . Cabon, B. Chidlovskii, and J. Revaud. DUSt3R: Geometric 3d vision made easy. In CVPR, 2024
2024
-
[53]
W. Wang, D. Zhu, X. Wang, Y . Hu, Y . Qiu, C. Wang, Y . Hu, A. Kapoor, and S. Scherer. Tartanair: A dataset to push the limits of visual slam. InIROS, 2020
2020
-
[54]
Y . Wang, J. Zhou, H. Zhu, W. Chang, Y . Zhou, Z. Li, J. Chen, J. Pang, C. Shen, and T. He.π3: Permutation- equivariant visual geometry learning. InICLR, 2026
2026
-
[55]
Weinzaepfel, V
P. Weinzaepfel, V . Leroy, T. Lucas, R. Brégier, Y . Cabon, V . Arora, L. Antsfeld, B. Chidlovskii, G. Csurka, and J. Revaud. Croco: Self-supervised pre-training for 3d vision tasks by cross-view completion.NeurIPS, 2022
2022
-
[56]
Weinzaepfel, T
P. Weinzaepfel, T. Lucas, V . Leroy, Y . Cabon, V . Arora, R. Brégier, G. Csurka, L. Antsfeld, B. Chidlovskii, and J. Revaud. Croco v2: Improved cross-view completion pre-training for stereo matching and optical flow. InICCV, 2023. 12
2023
-
[57]
Wilson, W
B. Wilson, W. Qi, T. Agarwal, J. Lambert, J. Singh, S. Khandelwal, B. Pan, R. Kumar, A. Hartnett, J. K. Pontes, D. Ramanan, P. Carr, and J. Hays. Argoverse 2: Next generation datasets for self-driving perception and forecasting. InNeurIPS Datasets and Benchmarks Track, 2021
2021
- [58]
-
[59]
J. Yang, A. Sax, K. J. Liang, M. Henaff, H. Tang, A. Cao, J. Chai, F. Meier, and M. Feiszli. Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass. InCVPR, 2025
2025
-
[60]
L. Yang, B. Kang, Z. Huang, X. Xu, J. Feng, and H. Zhao. Depth anything: Unleashing the power of large-scale unlabeled data. InCVPR, 2024
2024
-
[61]
L. Yang, B. Kang, Z. Huang, Z. Zhao, X. Xu, J. Feng, and H. Zhao. Depth anything v2. InNeurIPS, 2024
2024
-
[62]
Y . Yao, Z. Luo, S. Li, J. Zhang, Y . Ren, L. Zhou, T. Fang, and L. Quan. BlendedMVS: A large-scale dataset for generalized multi-view stereo networks. InCVPR, 2020
2020
-
[63]
H. Yu, H. Lin, J. Wang, J. Li, Y . Wang, X. Zhang, Y . Wang, X. Zhou, R. Hu, and S. Peng. InfiniDepth: Arbitrary-resolution and fine-grained depth estimation with neural implicit fields. InCVPR, 2026
2026
-
[64]
A. R. Zamir, A. Sax, W. B. Shen, L. Guibas, J. Malik, and S. Savarese. Taskonomy: Disentangling task transfer learning. InCVPR, 2018
2018
-
[65]
X. Zhai, A. Kolesnikov, N. Houlsby, and L. Beyer. Scaling vision transformers. InCVPR, 2022
2022
-
[66]
Zhang and R
B. Zhang and R. Sennrich. Root mean square layer normalization. InNeurIPS, 2019
2019
-
[67]
Zheng, J
J. Zheng, J. Zhang, J. Li, R. Tang, S. Gao, and Z. Zhou. Structured3D: A large photo-realistic dataset for structured 3d modeling. InECCV, 2020
2020
-
[68]
J. Zhu, X. Chen, K. He, Y . LeCun, and Z. Liu. Transformers without normalization. InCVPR, 2025
2025
-
[69]
Zolfaghari Bengar, A
J. Zolfaghari Bengar, A. Gonzalez-Garcia, G. Villalonga, B. Raducanu, H. H. Aghdam, M. Mozerov, A. M. Lopez, and J. van de Weijer. Temporal coherence for active learning in videos. InICCV Workshops, 2019. 13 Appendix A Details on the Point Gradient Matching Loss Pseudocode A gives a Python-like specification ofLpgm in Eq. (3). The loss optimizes the orien...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.