UniVerse: A Unified Modulation Framework for Segmentation-Free,Disentangled Multi-Concept Personalization
Pith reviewed 2026-06-28 22:32 UTC · model grok-4.3
The pith
UniVerse modulates diffusion transformers to decompose complex scenes into concept-specific representations and recompose them without segmentation masks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
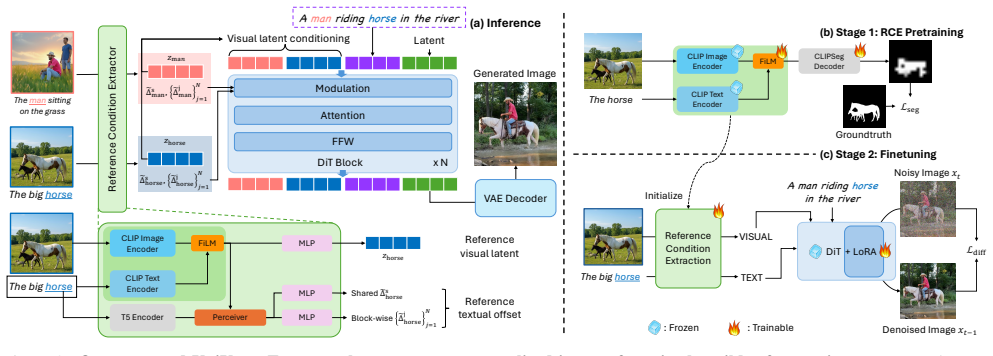
UniVerse is a Unified Modulation Framework for segmentation-free, disentangled multi-concept personalization in diffusion transformers. The method learns to decompose complex scenes into concept-specific representations and then compose them in a unified manner, enabling robust personalization across diverse visual contexts without any explicit segmentation supervision or masks.
What carries the argument
The Unified Modulation Framework, which modulates the internal layers of a diffusion transformer to perform concept decomposition and recomposition.
If this is right
- Enables fine-grained localization and representation of target objects in cluttered scenes without masks.
- Supports composable extraction and manipulation of multiple concepts in a single forward pass.
- Delivers higher localization accuracy and visual fidelity than segmentation-dependent baselines.
- Extends personalization to more flexible and interpretable visual generation tasks.
Where Pith is reading between the lines
- The same modulation idea might transfer to other transformer-based generators beyond the specific diffusion models tested.
- Success here suggests that explicit masks may not be necessary for many multi-object editing workflows.
- The decomposition step could be inspected to reveal which transformer layers carry concept identity information.
Load-bearing premise
The diffusion transformer can be modulated to achieve reliable concept decomposition and composition without any explicit segmentation supervision or masks.
What would settle it
A controlled test in which UniVerse produces overlapping or swapped concepts when two similar objects occupy the same region of an input image would show the modulation approach does not deliver the claimed disentanglement.
Figures





read the original abstract
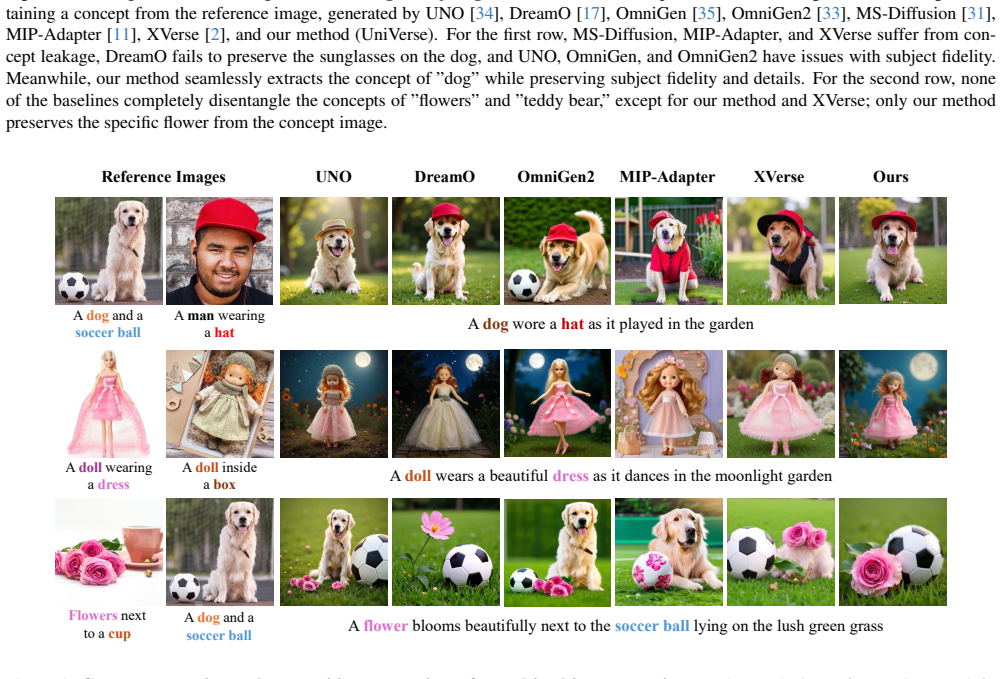
Personalized visual understanding has advanced significantly, yet existing approaches struggle to localize and extract specific concepts when input images contain multiple objects. Many prior methods rely heavily on segmentation-based supervision or exhibit poor compositional generalization, limiting their ability to accurately disentangle and manipulate individual concepts. In this work, we propose UniVerse, a Unified Modulation Framework for segmentation-free, disentangled multi-concept personalization in diffusion transformers. Our method allows for composable and decomposable concept extraction, enabling fine-grained localization and representation of target objects without explicit segmentation masks. UniVerse learns to decompose complex scenes into concept-specific representations and then compose them in a unified manner, enabling robust personalization across diverse visual contexts. Through extensive experiments on multiple benchmarks, we demonstrate that UniVerse significantly outperforms state-of-the-art baselines in both localization accuracy and visual fidelity. Qualitative and quantitative results show that our approach can precisely extract target concepts in cluttered scenes, paving the way for more flexible, interpretable, and personalized visual generation and understanding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes UniVerse, a unified modulation framework for segmentation-free, disentangled multi-concept personalization in diffusion transformers. It claims to learn concept decomposition and composition from data alone via cross-attention conditioning and masked latent manipulation objectives, enabling robust extraction and recombination of multiple concepts in cluttered scenes without segmentation masks or supervision, and reports superior localization accuracy and visual fidelity over baselines on multi-object benchmarks.
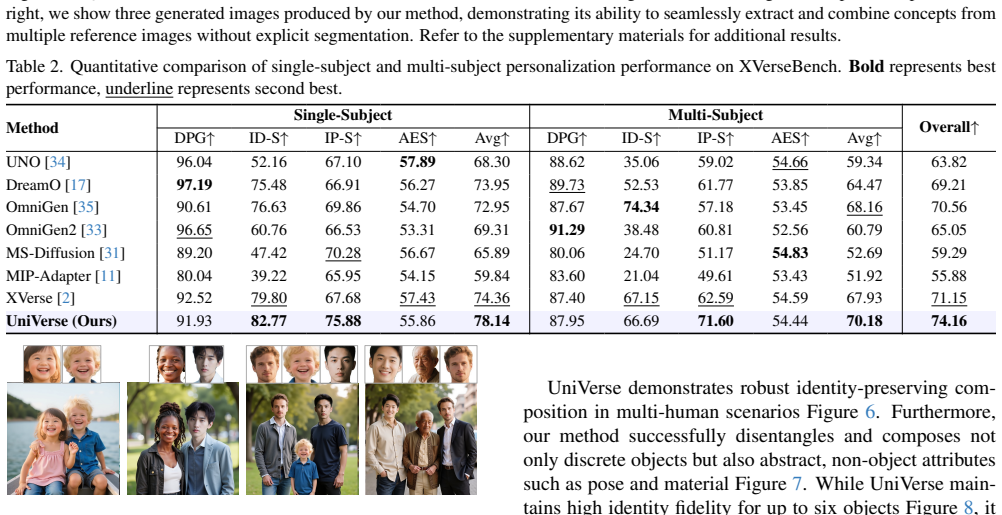
Significance. If the reported ablations and benchmark results hold, the work would provide a practical advance in personalized diffusion-based generation by removing the need for explicit segmentation, allowing more flexible handling of complex scenes. The inclusion of ablations showing degradation when modulation components are removed and the use of mask-free multi-object test scenes strengthen the empirical support for the central claim.
minor comments (3)
- [Abstract] The abstract states that UniVerse 'significantly outperforms state-of-the-art baselines' but supplies no numerical values, tables, or specific metrics; moving at least one key quantitative result (e.g., localization mIoU or FID) into the abstract would improve immediate readability.
- [Method] Notation for the modulation operator and the concept embedding extraction via cross-attention is introduced in the method section but not summarized in a single table or equation list; adding a compact notation table would aid readers.
- [Method] The training objective that encourages reconstruction through masked latent manipulation is described qualitatively; an explicit loss equation would make the objective easier to reproduce.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of UniVerse and the recommendation for minor revision. The summary accurately reflects the paper's contributions regarding segmentation-free multi-concept personalization in diffusion transformers.
Circularity Check
No significant circularity in derivation chain
full rationale
The manuscript describes an empirical method (UniVerse modulation in diffusion transformers) with training objectives, ablations, and benchmark results for segmentation-free concept decomposition. No equations, first-principles derivations, or parameter-fitting steps are shown that reduce predictions to inputs by construction. Claims rest on experimental outcomes rather than self-referential math or self-citation chains, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Break-a-scene: Extracting multi- ple concepts from a single image
Omri Avrahami, Kfir Aberman, Ohad Fried, Daniel Cohen- Or, and Dani Lischinski. Break-a-scene: Extracting multi- ple concepts from a single image. InSIGGRAPH Asia 2023 Conference Papers, 2023. 3
2023
-
[2]
Bowen Chen, Mengyi Zhao, Haomiao Sun, Li Chen, Xu Wang, Kang Du, and Xinglong Wu. Xverse: Consistent multi-subject control of identity and semantic attributes via dit modulation.arXiv preprint arXiv:2506.21416, 2025. 2, 3, 4, 5, 6, 7, 8
arXiv 2025
-
[3]
Arcface: Additive angular margin loss for deep face recognition
Jiankang Deng, Jia Guo, Niannan Xue, and Stefanos Zafeiriou. Arcface: Additive angular margin loss for deep face recognition. InCVPR, 2019. 6
2019
-
[4]
Siglip-based aesthetic score predictor v2.5
discus0434. Siglip-based aesthetic score predictor v2.5. https://github.com/discus0434/aesthetic- predictor- v2- 5, 2024. GitHub repository, accessed 2025-11-13. 6
2024
-
[5]
Scaling recti- fied flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M ¨uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling recti- fied flow transformers for high-resolution image synthesis. InICML, 2024. 3
2024
-
[6]
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patash- nik, Amit H Bermano, Gal Chechik, and Daniel Cohen- Or. An image is worth one word: Personalizing text-to- image generation using textual inversion.arXiv preprint arXiv:2208.01618, 2022. 2, 3
Pith/arXiv arXiv 2022
-
[7]
Tokenverse: Versatile multi-concept personalization in token modulation space.ACM Transactions On Graphics (TOG), 44(4):1–11, 2025
Daniel Garibi, Shahar Yadin, Roni Paiss, Omer Tov, Shiran Zada, Ariel Ephrat, Tomer Michaeli, Inbar Mosseri, and Tali Dekel. Tokenverse: Versatile multi-concept personalization in token modulation space.ACM Transactions On Graphics (TOG), 44(4):1–11, 2025. 2, 3
2025
-
[8]
Pulid: Pure and lightning id customization via contrastive alignment
Zinan Guo, Yanze Wu, Chen Zhuowei, Peng Zhang, Qian He, et al. Pulid: Pure and lightning id customization via contrastive alignment. InNeurIPS, 2024. 2, 3
2024
-
[9]
Lora: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. In ICLR, 2022. 4, 5, 6
2022
-
[10]
Xiwei Hu, Rui Wang, Yixiao Fang, Bin Fu, Pei Cheng, and Gang Yu. Ella: Equip diffusion models with llm for enhanced semantic alignment.arXiv preprint arXiv:2403.05135, 2024. 6
Pith/arXiv arXiv 2024
-
[11]
Resolving multi-condition confusion for finetuning-free personalized image generation
Qihan Huang, Siming Fu, Jinlong Liu, Hao Jiang, Yipeng Yu, and Jie Song. Resolving multi-condition confusion for finetuning-free personalized image generation. InProceed- ings of the AAAI Conference on Artificial Intelligence, 2025. 2, 3, 5, 6, 7, 8
2025
-
[12]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weli- hinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024. 6
Pith/arXiv arXiv 2024
-
[13]
Perceiver: General perception with iterative attention
Andrew Jaegle, Felix Gimeno, Andy Brock, Oriol Vinyals, Andrew Zisserman, and Joao Carreira. Perceiver: General perception with iterative attention. InICML, 2021. 4
2021
-
[14]
Photomaker: Customizing re- alistic human photos via stacked id embedding
Zhen Li, Mingdeng Cao, Xintao Wang, Zhongang Qi, Ming- Ming Cheng, and Ying Shan. Photomaker: Customizing re- alistic human photos via stacked id embedding. InCVPR,
-
[15]
Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 6
Pith/arXiv arXiv 2017
-
[16]
Image segmentation using text and image prompts
Timo L ¨uddecke and Alexander Ecker. Image segmentation using text and image prompts. InCVPR, 2022. 4
2022
-
[17]
Dreamo: A unified framework for image customization.arXiv preprint arXiv:2504.16915,
Chong Mou, Yanze Wu, Wenxu Wu, Zinan Guo, Pengze Zhang, Yufeng Cheng, Yiming Luo, Fei Ding, Shiwen Zhang, Xinghui Li, et al. Dreamo: A unified framework for image customization.arXiv preprint arXiv:2504.16915,
-
[18]
Dinov2: Learning robust visual features without supervision
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023. 6
Pith/arXiv arXiv 2023
-
[19]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InICCV, 2023. 2, 3
2023
-
[20]
Yuang Peng, Yuxin Cui, Haomiao Tang, Zekun Qi, Runpei Dong, Jing Bai, Chunrui Han, Zheng Ge, Xiangyu Zhang, and Shu-Tao Xia. Dreambench++: A human-aligned bench- mark for personalized image generation.arXiv preprint arXiv:2406.16855, 2024. 6
arXiv 2024
-
[21]
Film: Visual reasoning with a general conditioning layer
Ethan Perez, Florian Strub, Harm De Vries, Vincent Du- moulin, and Aaron Courville. Film: Visual reasoning with a general conditioning layer. InAAAI, 2018. 4
2018
-
[22]
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M ¨uller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion mod- els for high-resolution image synthesis.arXiv preprint arXiv:2307.01952, 2023. 3
Pith/arXiv arXiv 2023
-
[23]
Learn- ing transferable visual models from natural language super- vision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn- ing transferable visual models from natural language super- vision. InICML, 2021. 3, 4, 6
2021
-
[24]
Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research, 21(140):1–67, 2020
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research, 21(140):1–67, 2020. 4
2020
-
[25]
Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu, and Mark Chen. Hierarchical text-conditional image gener- ation with clip latents.arXiv preprint arXiv:2204.06125, 1 (2):3, 2022. 3
Pith/arXiv arXiv 2022
-
[26]
High-resolution image syn- thesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High-resolution image syn- thesis with latent diffusion models. InCVPR, 2022. 3
2022
-
[27]
U- net: Convolutional networks for biomedical image segmen- tation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U- net: Convolutional networks for biomedical image segmen- tation. InInternational Conference on Medical image com- puting and computer-assisted intervention, 2015. 2
2015
-
[28]
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. InCVPR, 2023. 2, 3
2023
-
[29]
Photorealistic text-to-image diffusion models with deep language understanding
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding. InNeurIPS, 2022. 3
2022
-
[30]
Seededit: Align image re-generation to image editing.arXiv preprint arXiv:2411.06686, 2024
Yichun Shi, Peng Wang, and Weilin Huang. Seededit: Align image re-generation to image editing.arXiv preprint arXiv:2411.06686, 2024. 3
arXiv 2024
-
[31]
Xierui Wang, Siming Fu, Qihan Huang, Wanggui He, and Hao Jiang. Ms-diffusion: Multi-subject zero-shot im- age personalization with layout guidance.arXiv preprint arXiv:2406.07209, 2024. 3, 5, 6, 7, 8
arXiv 2024
-
[32]
Phrasecut: Language-based image segmen- tation in the wild
Chenyun Wu, Zhe Lin, Scott Cohen, Trung Bui, and Subhransu Maji. Phrasecut: Language-based image segmen- tation in the wild. InCVPR, 2020. 6
2020
-
[33]
Omnigen2: Exploration to advanced multimodal generation.arXiv preprint arXiv:2506.18871, 2025
Chenyuan Wu, Pengfei Zheng, Ruiran Yan, Shitao Xiao, Xin Luo, Yueze Wang, Wanli Li, Xiyan Jiang, Yexin Liu, Junjie Zhou, et al. Omnigen2: Exploration to advanced multimodal generation.arXiv preprint arXiv:2506.18871, 2025. 3, 5, 6, 7, 8
Pith/arXiv arXiv 2025
-
[34]
Shaojin Wu, Mengqi Huang, Wenxu Wu, Yufeng Cheng, Fei Ding, and Qian He. Less-to-more generalization: Unlocking more controllability by in-context generation.arXiv preprint arXiv:2504.02160, 2025. 2, 3, 5, 6, 7, 8
arXiv 2025
-
[35]
Omnigen: Unified image genera- tion
Shitao Xiao, Yueze Wang, Junjie Zhou, Huaying Yuan, Xin- grun Xing, Ruiran Yan, Chaofan Li, Shuting Wang, Tiejun Huang, and Zheng Liu. Omnigen: Unified image genera- tion. InCVPR, 2025. 2, 3, 5, 6, 7, 8
2025
-
[36]
Understanding and improving layer normaliza- tion
Jingjing Xu, Xu Sun, Zhiyuan Zhang, Guangxiang Zhao, and Junyang Lin. Understanding and improving layer normaliza- tion. InNeurIPS, 2019. 3
2019
-
[37]
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. Ip- adapter: Text compatible image prompt adapter for text-to- image diffusion models.arXiv preprint arXiv:2308.06721,
-
[38]
A survey on personalized content synthesis with diffu- sion models.Machine Intelligence Research, 22(5):817–848,
Xulu Zhang, Xiaoyong Wei, Wentao Hu, Jinlin Wu, Jiaxin Wu, Wengyu Zhang, Zhaoxiang Zhang, Zhen Lei, and Qing Li. A survey on personalized content synthesis with diffu- sion models.Machine Intelligence Research, 22(5):817–848,
-
[39]
Ssr-encoder: Encoding selective subject representation for subject-driven generation
Yuxuan Zhang, Yiren Song, Jiaming Liu, Rui Wang, Jinpeng Yu, Hao Tang, Huaxia Li, Xu Tang, Yao Hu, Han Pan, et al. Ssr-encoder: Encoding selective subject representation for subject-driven generation. InCVPR, 2024. 3
2024
-
[40]
Weizhi Zhong, Huan Yang, Zheng Liu, Huiguo He, Zijian He, Xuesong Niu, Di Zhang, and Guanbin Li. Mod-adapter: Tuning-free and versatile multi-concept personalization via modulation adapter.arXiv preprint arXiv:2505.18612, 2025. 2
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.