SPARQLe: Sub-Precision Activation Representation for Quantized LLM Inference
Pith reviewed 2026-06-28 19:29 UTC · model grok-4.3
The pith
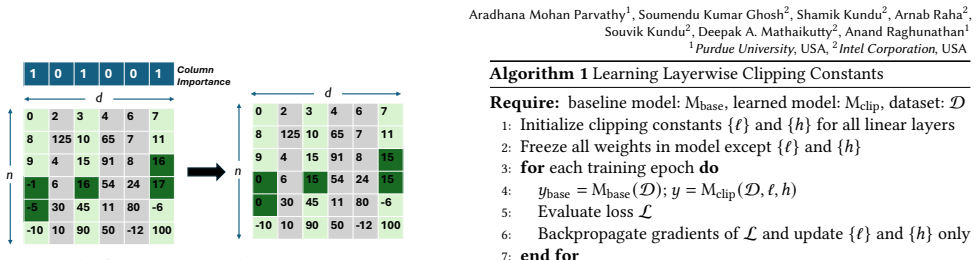
SPARQLe represents each 2k-bit quantized activation as a dense k-bit LSB tensor plus a sparse k-bit MSB tensor with a precision bitmap to cut memory traffic and run on k-bit datapaths.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
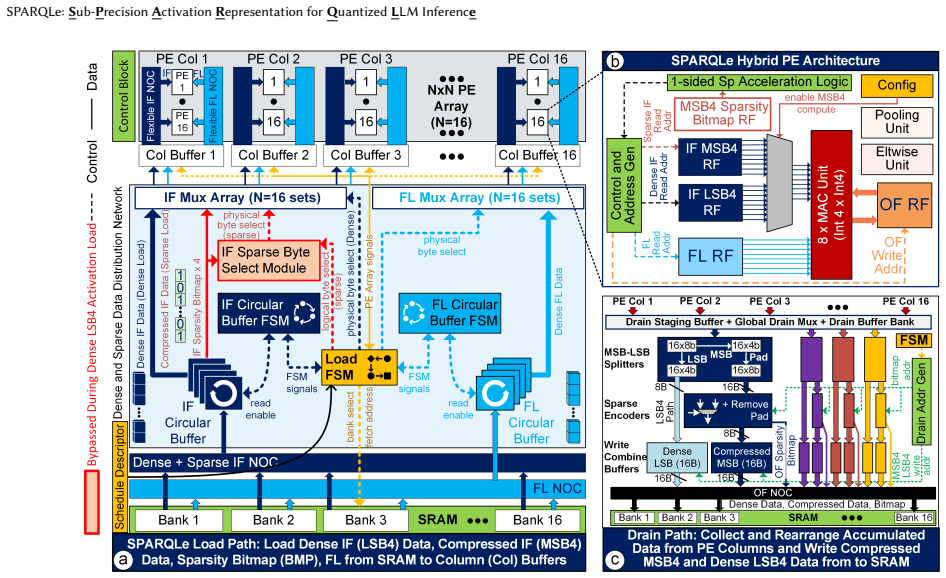
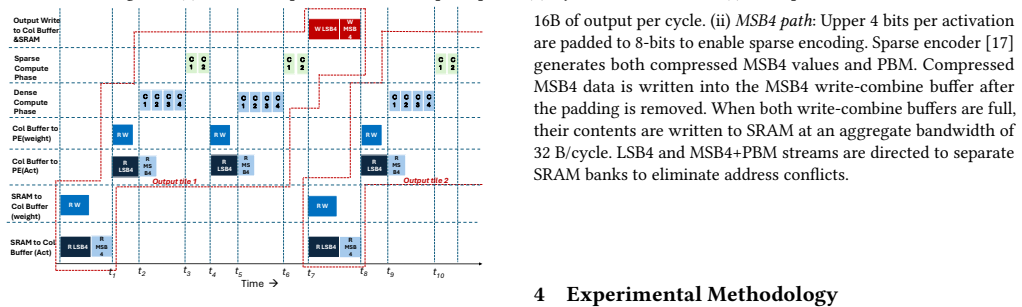
SPARQLe is a hardware-software co-design that represents each 2k-bit activation tensor as a dense k-bit LSB tensor and a sparse k-bit MSB tensor compressed with a precision bitmap, proposes a lightweight algorithm to increase MSB sparsity, and supplies an accelerator that operates directly on the hybrid format with minimal control overheads, thereby reducing activation memory traffic and enabling efficient k-bit datapath computation while preserving 2k-bit activation accuracy.
What carries the argument
The hybrid activation format (dense k-bit LSB tensor plus sparse k-bit MSB tensor indexed by a precision bitmap) that carries the argument by converting statistical near-zero concentration into reduced memory traffic and narrower datapath width.
If this is right
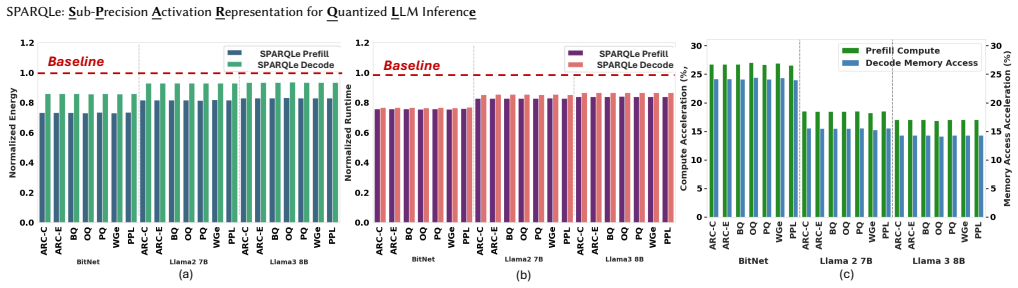
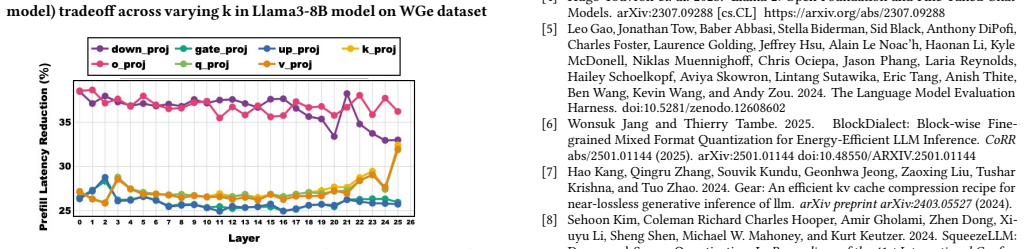
- Prefill latency drops 16-24.3% on the three evaluated models.
- Decode latency drops 13.5-23.4%.
- Prefill energy falls 17-26.7% and decode energy falls 6.5-14.2%.
- All savings occur while 2k-bit activation accuracy is preserved.
- Computation runs on k-bit datapaths instead of 2k-bit datapaths.
Where Pith is reading between the lines
- The same bitmap-plus-sparse-high-bits pattern could be applied to intermediate tensors inside attention or MLP blocks that are not currently quantized.
- If the sparsity pattern proves stable across training checkpoints, the bitmap could be generated once and reused for multiple inferences.
- Hardware vendors could add native support for the hybrid format in future matrix units to widen the efficiency gap beyond the current software-managed accelerator.
Load-bearing premise
A significant fraction of activations remain concentrated around zero after quantization, producing usable sparsity in the higher-order bits that can be exploited by the bitmap representation without accuracy loss.
What would settle it
Apply SPARQLe to a new model whose post-quantization activations show markedly lower concentration around zero and measure whether accuracy falls below the 2k-bit baseline or the reported latency-energy gains disappear.
Figures



read the original abstract
The rapid growth in sizes of Large language models (LLMs) results in high compute and memory costs during inference. Quantization has been a significant pathway to addressing this challenge. In the quest to push the limits of quantization, weights, which are static, can often be quantized aggressively (e.g. 4 bits), while activations often require higher precision (e.g., 8 bits) to preserve accuracy, forcing hardware to operate with higher-precision datapaths. We leverage the statistical property that a significant fraction of activations are concentrated around zero, resulting in sparsity in the higher-order bits. Our proposal, SPARQLe, is a hardware-software co-design framework that exploits this sub-precision redundancy in any given quantized model. SPARQLe represents each 2k-bit activation tensor as a dense k-bit LSB tensor and a sparse k-bit MSB tensor compressed with a precision bitmap, and proposes a lightweight algorithm to increase MSB sparsity. SPARQLe reduces activation memory traffic and enables efficient computation on k-bit datapaths while preserving 2k-bit activation accuracy. SPARQLe includes an accelerator that operates directly on this hybrid format with minimal control overheads. Across the BitNet 3B, Llama2 7B, and Llama3 8B models, SPARQLe reduces prefill latency by 16-24.3% and decode latency by 13.5-23.4%, with 17-26.7% and 6.5-14.2% lower prefill and decode energy, respectively. SPARQLe demonstrates that sub-precision activation sparsity offers an effective and complementary pathway towards efficient LLM inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SPARQLe, a hardware-software co-design for quantized LLM inference that exploits observed concentration of activations around zero after quantization. Each 2k-bit activation tensor is represented as a dense k-bit LSB tensor plus a sparse k-bit MSB tensor compressed via a precision bitmap; a lightweight algorithm increases MSB sparsity. An accelerator operates directly on the hybrid format. The central empirical claim is that this yields 16-24.3% prefill and 13.5-23.4% decode latency reductions (plus corresponding energy savings) on BitNet 3B, Llama2 7B and Llama3 8B while preserving 2k-bit accuracy.
Significance. If the sparsity property and bitmap overhead measurements hold, the approach supplies a complementary, model-agnostic route to lowering activation memory traffic and enabling narrower datapaths without retraining or accuracy loss, which would be of practical interest for inference accelerators.
major comments (2)
- [Abstract / §4] Abstract (and §4/§5 experimental sections): the headline latency and energy numbers (16-24.3% prefill latency, 17-26.7% prefill energy, etc.) are load-bearing for the contribution, yet the manuscript supplies neither per-layer/per-model MSB sparsity histograms nor explicit bitmap-overhead measurements that would confirm the hybrid representation is cheaper than a dense 2k-bit baseline on the evaluated models.
- [§3.2] §3.2 (lightweight sparsity-increasing algorithm): the claim that the algorithm preserves 2k-bit accuracy while increasing usable MSB sparsity is central, but no ablation is shown that quantifies accuracy degradation when the algorithm is disabled or when the assumed zero-concentration is weaker (e.g., on other model families or bit-widths).
minor comments (2)
- [§3.1] Notation for the hybrid format (dense LSB + bitmap-compressed MSB) should be introduced with an explicit equation or diagram in §3.1 to avoid ambiguity when comparing against the 2k-bit baseline.
- [§4] Table captions in the experimental section should explicitly state the number of runs and whether error bars reflect standard deviation across seeds or models.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will revise the manuscript to strengthen the empirical support for the claims.
read point-by-point responses
-
Referee: [Abstract / §4] Abstract (and §4/§5 experimental sections): the headline latency and energy numbers (16-24.3% prefill latency, 17-26.7% prefill energy, etc.) are load-bearing for the contribution, yet the manuscript supplies neither per-layer/per-model MSB sparsity histograms nor explicit bitmap-overhead measurements that would confirm the hybrid representation is cheaper than a dense 2k-bit baseline on the evaluated models.
Authors: We agree that the absence of per-layer/per-model MSB sparsity histograms and explicit bitmap-overhead breakdowns weakens the substantiation of the headline numbers. The reported latency and energy figures were obtained from cycle-accurate simulation of the accelerator that already incorporates bitmap storage and access costs. In the revised manuscript we will add the requested histograms (showing MSB sparsity per layer and model) together with a table breaking down bitmap overhead versus the dense 2k-bit baseline, confirming net traffic reduction on BitNet 3B, Llama2 7B and Llama3 8B. revision: yes
-
Referee: [§3.2] §3.2 (lightweight sparsity-increasing algorithm): the claim that the algorithm preserves 2k-bit accuracy while increasing usable MSB sparsity is central, but no ablation is shown that quantifies accuracy degradation when the algorithm is disabled or when the assumed zero-concentration is weaker (e.g., on other model families or bit-widths).
Authors: The algorithm is a lightweight post-quantization pass whose only purpose is to increase MSB sparsity; the manuscript already states that end-to-end accuracy remains identical to the 2k-bit baseline on the three evaluated models. We will add an ablation table in §3.2 (and corresponding text in §5) that reports perplexity/accuracy with the algorithm disabled versus enabled on BitNet 3B, Llama2 7B and Llama3 8B. Extending the ablation to additional model families or bit-widths would require new experiments outside the current scope; we will note this limitation and discuss the dependence on the observed zero-concentration property. revision: partial
Circularity Check
No circularity; empirical results rest on observed sparsity property
full rationale
The paper proposes SPARQLe as a hardware-software co-design that exploits an observed statistical property of quantized activations (concentration around zero yielding MSB sparsity) to represent tensors as dense LSB plus bitmap-compressed sparse MSB, with a lightweight sparsity-increasing algorithm. Performance numbers (latency/energy reductions on BitNet 3B, Llama2 7B, Llama3 8B) are obtained from direct accelerator measurements and are not derived from any equations, fitted parameters, or self-citations that reduce the claims to their own inputs by construction. The central premise is an external empirical observation rather than a self-referential derivation, making the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A significant fraction of activations are concentrated around zero after quantization, producing sparsity in higher-order bits.
invented entities (1)
-
Hybrid activation format (dense k-bit LSB tensor + sparse k-bit MSB tensor with precision bitmap)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman
Saleh Ashkboos, Amirkeivan Mohtashami, Maximilian L. Croci, Bo Li, Pashmina Cameron, Martin Jaggi, Dan Alistarh, Torsten Hoefler, and James Hensman. 2024. QuaRot: Outlier-Free 4-Bit Inference in Rotated LLMs. InAdvances in Neural Information Processing Systems, A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang (Eds.), Vol. ...
- [2]
-
[3]
Aaron Grattafiori et. al. 2024. The Llama 3 Herd of Models. arXiv:2407.21783 [cs.AI] https://arxiv.org/abs/2407.21783
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Hugo Touvron et. al. 2023. Llama 2: Open Foundation and Fine-Tuned Chat Models. arXiv:2307.09288 [cs.CL] https://arxiv.org/abs/2307.09288
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Leo Gao, Jonathan Tow, Baber Abbasi, Stella Biderman, Sid Black, Anthony DiPofi, Charles Foster, Laurence Golding, Jeffrey Hsu, Alain Le Noac’h, Haonan Li, Kyle McDonell, Niklas Muennighoff, Chris Ociepa, Jason Phang, Laria Reynolds, Hailey Schoelkopf, Aviya Skowron, Lintang Sutawika, Eric Tang, Anish Thite, Ben Wang, Kevin Wang, and Andy Zou. 2024. The L...
-
[6]
Wonsuk Jang and Thierry Tambe. 2025. BlockDialect: Block-wise Fine- grained Mixed Format Quantization for Energy-Efficient LLM Inference.CoRR abs/2501.01144 (2025). arXiv:2501.01144 doi:10.48550/ARXIV.2501.01144
- [7]
-
[8]
Mahoney, and Kurt Keutzer
Sehoon Kim, Coleman Richard Charles Hooper, Amir Gholami, Zhen Dong, Xi- uyu Li, Sheng Shen, Michael W. Mahoney, and Kurt Keutzer. 2024. SqueezeLLM: Dense-and-Sparse Quantization. InProceedings of the 41st International Confer- ence on Machine Learning (Proceedings of Machine Learning Research, Vol. 235), Ruslan Salakhutdinov, Zico Kolter, Katherine Helle...
2024
-
[9]
Seunghyun Lee, Dongho Ha, Sungbin Kim, Sungwoo Kim, Hyunwuk Lee, and Won Woo Ro. 2025. BitL: A Hybrid Bit-Serial and Parallel Deep Learning Acceler- ator for Critical Path Reduction. InProceedings of the 58th IEEE/ACM International Symposium on Microarchitecture (MICRO ’25). Association for Computing Ma- chinery, New York, NY, USA, 1565–1578. doi:10.1145/...
- [10]
-
[11]
Haokun Lin, Haobo Xu, Yichen Wu, Jingzhi Cui, Yingtao Zhang, Linzhan Mou, Linqi Song, Zhenan Sun, and Ying Wei. 2024. DuQuant: distributing outliers via dual transformation makes stronger quantized LLMs. InProceedings of the 38th International Conference on Neural Information Processing Systems(Vancouver, BC, Canada)(NIPS ’24). Curran Associates Inc., Red...
2024
-
[12]
Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, and Song Han. 2024. AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration. InMLSys
2024
- [13]
-
[14]
James Liu, Pragaash Ponnusamy, Tianle Cai, Han Guo, Yoon Kim, and Ben Athiwaratkun. 2025. Training-Free Activation Sparsity in Large Language Models. InThe Thirteenth International Conference on Learning Representations. Aradhana Mohan Parvathy1, Soumendu Kumar Ghosh2, Shamik Kundu2, Arnab Raha2, Souvik Kundu2, Deepak A. Mathaikutty2, Anand Raghunathan1 1...
2025
-
[15]
Shuming Ma, Hongyu Wang, Lingxiao Ma, Lei Wang, Wenhui Wang, Shaohan Huang, Li Dong, Ruiping Wang, Jilong Xue, and Furu Wei. 2024. The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits.CoRRabs/2402.17764 (2024). arXiv:2402.17764 doi:10.48550/ARXIV.2402.17764
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.17764 2024
-
[16]
Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. 2016. Pointer Sentinel Mixture Models. arXiv:1609.07843 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[17]
Mathaikutty, Shamik Kundu, and Soumendu K
Arnab Raha, Deepak A. Mathaikutty, Shamik Kundu, and Soumendu K. Ghosh
-
[18]
doi:10.3389/fhpcp.2025.1570210
FlexNPU: a dataflow-aware flexible deep learning accelerator for energy- efficient edge devices.Frontiers in High Performance ComputingVolume 3 - 2025 (2025). doi:10.3389/fhpcp.2025.1570210
-
[19]
Akshat Ramachandran, Souvik Kundu, and Tushar Krishna. 2025. MicroScopiQ: Accelerating Foundational Models through Outlier-Aware Microscaling Quanti- zation. InProceedings of the 52nd Annual International Symposium on Computer Architecture (ISCA ’25). Association for Computing Machinery, New York, NY, USA, 1193–1209. doi:10.1145/3695053.3730989
-
[20]
Wenqi Shao, Mengzhao Chen, Zhaoyang Zhang, Peng Xu, Lirui Zhao, Zhiqian Li, Kaipeng Zhang, Peng Gao, Yu Qiao, and Ping Luo. 2024. OmniQuant: Omnidirec- tionally Calibrated Quantization for Large Language Models. InThe Twelfth Inter- national Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net. https://openrev...
2024
-
[21]
Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. 2023. SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models. InProceedings of the 40th International Conference on Machine Learning
2023
-
[22]
Yilong Zhao, Chien-Yu Lin, Kan Zhu, Zihao Ye, Lequn Chen, Size Zheng, Luis Ceze, Arvind Krishnamurthy, Tianqi Chen, and Baris Kasikci. 2024. Atom: Low-Bit Quantization for Efficient and Accurate LLM Serving. InProceedings of Machine Learning and Systems, P. Gibbons, G. Pekhimenko, and C. De Sa (Eds.), Vol. 6. 196–209. https://proceedings.mlsys.org/paper_f...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.