Privacy-preserving Prosody Representation Learning
Pith reviewed 2026-06-28 20:30 UTC · model grok-4.3
The pith
A self-supervised prosody encoder with speaker disentanglement removes identity leakage while matching or exceeding baselines on pitch and event tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A new self-supervised encoder for prosody representations incorporates speaker disentanglement strategies, outperforming raw prosody and HuBERT-base baselines on three probing tasks while achieving strong speaker disentanglement without adverse impact on prosody-related downstream tasks.
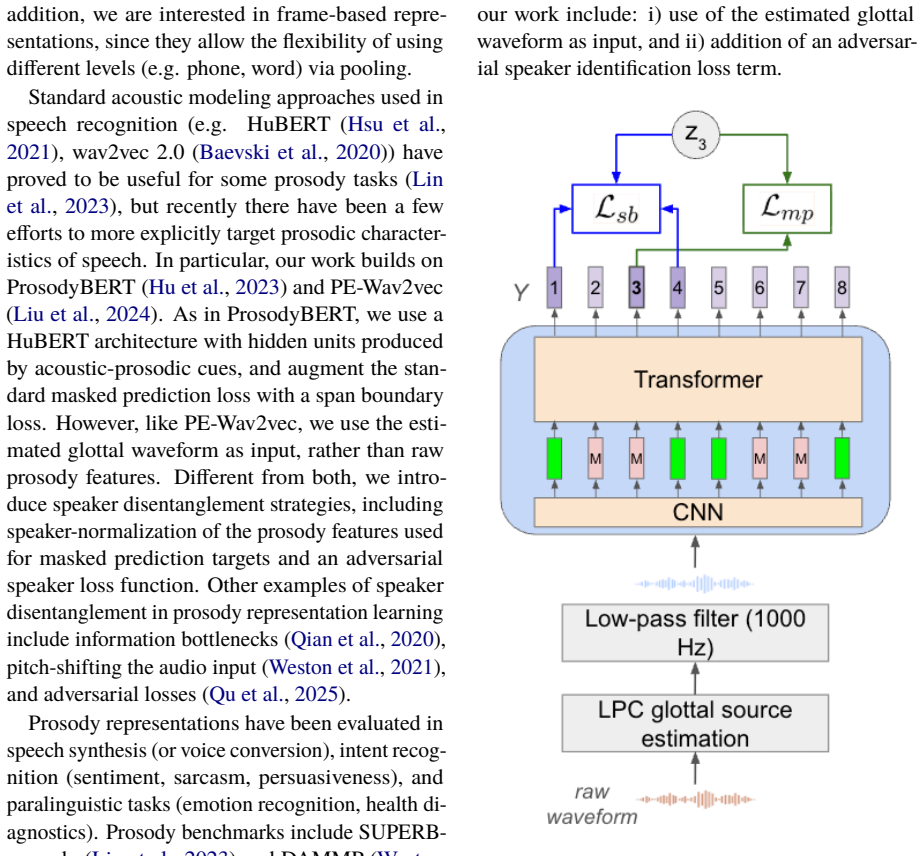
What carries the argument
Speaker disentanglement strategies added to a self-supervised training pipeline for prosody-focused speech encoders.
If this is right
- Prosody representations become usable in downstream speech tasks without exposing speaker identity.
- Privacy concerns in prosody-based generation or analysis systems can be reduced at the representation level.
- The same training approach may apply to other acoustic attributes that carry identity cues.
- Models trained this way support multi-speaker scenarios with lower risk of identity leakage.
Where Pith is reading between the lines
- The method could be combined with generation models to enable private prosody transfer between speakers.
- Similar disentanglement might be tested on other speech attributes such as emotion or accent.
- If the approach generalizes across languages, it could support privacy standards for international speech datasets.
- Deployment in real-time systems would require checking whether the added disentanglement increases latency.
Load-bearing premise
The disentanglement steps remove speaker identity information while leaving all necessary prosodic content intact, as shown by the chosen evaluation tasks.
What would settle it
If a speaker verification model trained on the learned representations achieves accuracy well above chance, or if any prosody task score falls below the raw-prosody baseline.
Figures

read the original abstract
Speech representations that capture prosodic information can be useful for both understanding and generation. However, speaker characteristics are reflected in acoustic-prosodic features (e.g., pitch). To address privacy concerns from the leakage of identity information, we propose a new self-supervised approach to learning prosody representations that incorporates speaker disentanglement strategies. We evaluate our encoder on three tasks to probe representation capabilities, including pitch reconstruction and detection of different prosodic events. Our encoder outperforms raw prosody and HuBERT-base baselines, achieving strong speaker disentanglement without adverse impact on prosody-related downstream tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a self-supervised encoder for prosody representations that incorporates speaker disentanglement strategies to mitigate privacy leakage of speaker identity in acoustic-prosodic features. It evaluates the encoder on three tasks including pitch reconstruction and prosodic event detection, claiming outperformance over raw prosody and HuBERT-base baselines with strong speaker disentanglement and no adverse impact on prosody-related downstream tasks.
Significance. If the (unseen) methods achieve the claimed disentanglement while preserving prosodic content, the work could contribute to privacy-preserving speech representation learning. The multi-task evaluation framing is a positive aspect, but the absence of methods, data, error bars, or result tables in the manuscript prevents any assessment of whether the central claims hold or of the work's potential impact.
major comments (1)
- The provided manuscript consists solely of the abstract; no methods section, equations, experimental setup, result tables, or data details are present. This makes it impossible to verify the claimed outperformance, the effectiveness of the speaker disentanglement strategies, or whether prosodic content is preserved (as required for the three evaluation tasks).
Simulated Author's Rebuttal
We thank the referee for their comments. We agree that the submitted version contained only the abstract and will revise to include the full methods, experiments, and results.
read point-by-point responses
-
Referee: The provided manuscript consists solely of the abstract; no methods section, equations, experimental setup, result tables, or data details are present. This makes it impossible to verify the claimed outperformance, the effectiveness of the speaker disentanglement strategies, or whether prosodic content is preserved (as required for the three evaluation tasks).
Authors: We agree that the provided manuscript is limited to the abstract, which prevents verification of the claims. In the revised submission we will add a complete methods section describing the self-supervised prosody encoder and the speaker disentanglement strategies (including any loss terms or architectural modifications), the full experimental setup (datasets, training details, evaluation protocols), result tables with error bars for the pitch reconstruction and prosodic event detection tasks, and comparisons against the raw prosody and HuBERT-base baselines. These additions will allow direct assessment of whether prosodic content is preserved while speaker identity is disentangled. revision: yes
Circularity Check
No significant circularity; empirical method with no derivation chain
full rationale
The paper describes a self-supervised encoder for prosody representations incorporating speaker disentanglement, evaluated empirically on pitch reconstruction and prosodic event detection tasks. No equations, derivations, predictions, or first-principles results are present in the provided text. Claims rest on experimental comparisons to baselines rather than any mathematical reduction or self-referential fitting that could be circular by construction. The central results are falsifiable via the described downstream tasks and do not invoke self-citations or ansatzes as load-bearing elements.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Towards end-to-end prosody transfer for expressive speech synthesis with
Skerry-Ryan, RJ and Battenberg, Eric and Xiao, Ying and Wang, Yuxuan and Stanton, Daisy and Shor, Joel and Weiss, Ron and Clark, Rob and Saurous, Rif A , booktitle=. Towards end-to-end prosody transfer for expressive speech synthesis with
-
[2]
Parsing speech: a neural approach to integrating lexical and acoustic-prosodic information , author=. Proc. Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
-
[3]
2010 , publisher=
Lees-Miller, John and Hammersley, John and Wilson, R , journal=. 2010 , publisher=
2010
-
[4]
2024 , volume=
Liu, Zhao-Ci and Chen, Liping and Hu, Ya-Jun and Ling, Zhen-Hua and Pan, Jia , journal=. 2024 , volume=
2024
-
[5]
IEEE/ACM Transactions on Audio, Speech, and Language Processing , author =. 2024 , keywords =. doi:10.1109/TASLP.2023.3320864 , abstract =
-
[6]
2024 , organization=
Deng, Yimin and Wang, Jianzong and Zhang, Xulong and Cheng, Ning and Xiao, Jing , booktitle=. 2024 , organization=
2024
-
[7]
doi:10.48550/arXiv.2007.09060 , abstract =
Noufi, Camille and Verma, Prateek , month = aug, year =. doi:10.48550/arXiv.2007.09060 , abstract =
-
[8]
2021 , organization=
Weston, Jack and Lenain, Raphael and Meepegama, Udeepa and Fristed, Emil , booktitle=. 2021 , organization=
2021
-
[9]
2020 , organization=
Qian, Kaizhi and Zhang, Yang and Chang, Shiyu and Hasegawa-Johnson, Mark and Cox, David , booktitle=. 2020 , organization=
2020
-
[10]
2019 , editor =
Qian, Kaizhi and Zhang, Yang and Chang, Shiyu and Yang, Xuesong and Hasegawa-Johnson, Mark , booktitle =. 2019 , editor =
2019
-
[11]
2022 , organization=
Chan, Chak Ho and Qian, Kaizhi and Zhang, Yang and Hasegawa-Johnson, Mark , booktitle=. 2022 , organization=
2022
-
[12]
2022 , editor =
Qian, Kaizhi and Zhang, Yang and Gao, Heting and Ni, Junrui and Lai, Cheng-I and Cox, David and Hasegawa-Johnson, Mark and Chang, Shiyu , booktitle =. 2022 , editor =
2022
-
[13]
IEEE/ACM Transactions on Audio, Speech, and Language Processing , author =. 2023 , keywords =. doi:10.1109/TASLP.2023.3290423 , abstract =
-
[14]
Lian, Jiachen and Zhang, Chunlei and Anumanchipalli, Gopala Krishna and Yu, Dong , booktitle=
-
[15]
2022 , organization=
Lian, Jiachen and Zhang, Chunlei and Yu, Dong , booktitle=. 2022 , organization=
2022
-
[16]
Proceedings of the 36th
Kenter, Tom and Wan, Vincent and Chan, Chun-An and Clark, Rob and Vit, Jakub , month = may, year =. Proceedings of the 36th
-
[17]
Yushi Hu and Chunlei Zhang and Jiatong Shi and Jiachen Lian and Mari Ostendorf and Dong Yu , year=
-
[18]
2023 , organization=
Lin, Guan-Ting and Feng, Chi-Luen and Huang, Wei-Ping and Tseng, Yuan and Lin, Tzu-Han and Li, Chen-An and Lee, Hung-yi and Ward, Nigel G , booktitle=. 2023 , organization=
2023
-
[19]
wav2vec 2.0:
Baevski, Alexei and Zhou, Yuhao and Mohamed, Abdelrahman and Auli, Michael , journal=. wav2vec 2.0:
-
[20]
2021 , publisher=
Hsu, Wei-Ning and Bolte, Benjamin and Tsai, Yao-Hung Hubert and Lakhotia, Kushal and Salakhutdinov, Ruslan and Mohamed, Abdelrahman , journal=. 2021 , publisher=
2021
-
[21]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Devlin, Jacob and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina , month = may, year =. doi:10.48550/arXiv.1810.04805 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1810.04805
-
[22]
WavLM: Large-Scale Self-Supervised Pre-Training for Full Stack Speech Processing , volume=
Chen, Sanyuan and Wang, Chengyi and Chen, Zhengyang and Wu, Yu and Liu, Shujie and Chen, Zhuo and Li, Jinyu and Kanda, Naoyuki and Yoshioka, Takuya and Xiao, Xiong and Wu, Jian and Zhou, Long and Ren, Shuo and Qian, Yanmin and Qian, Yao and Wu, Jian and Zeng, Michael and Yu, Xiangzhan and Wei, Furu , month = jun, year =. doi:10.1109/JSTSP.2022.3188113 , a...
-
[23]
Yang, Shu-wen and Chi, Po-Han and Chuang, Yung-Sung and Lai, Cheng-I Jeff and Lakhotia, Kushal and Lin, Yist Y and Liu, Andy T and Shi, Jiatong and Chang, Xuankai and Lin, Guan-Ting and others , booktitle=
-
[24]
IEEE/ACM Transactions on Audio, Speech, and Language Processing , author =. 2014 , keywords =. doi:10.1109/TASLP.2014.2363410 , abstract =
-
[25]
Chen, Li-Wei and Watanabe, Shinji and Rudnicky, Alexander , booktitle=
-
[26]
Ostendorf, Mari and Price, Patti J and Shattuck-Hufnagel, Stefanie , journal=
-
[27]
Black and Gopala Anumanchipalli , title =
Cheol Jun Cho and Nicholas Lee and Akshat Gupta and Dhruv Agarwal and Ethan Chen and Alan W. Black and Gopala Anumanchipalli , title =. The Thirteenth International Conference on Learning Representations,. 2025 , url =
2025
-
[28]
Proceedings of the ... IEEE International Conference on Acoustics, Speech, and Signal Processing / sponsored by the Institute of Electrical and Electronics Engineers Signal Processing Society. ICASSP (Conference) , author =. 2014 , pmid =. doi:10.1109/ICASSP.2014.6854525 , abstract =
-
[29]
Pervasive and Mobile Computing , author =. 2018 , note =. doi:10.1016/j.pmcj.2018.09.003 , abstract =
-
[30]
Lu, Hong and Frauendorfer, Denise and Rabbi, Mashfiqui and Mast, Marianne Schmid and Chittaranjan, Gokul T. and Campbell, Andrew T. and Gatica-Perez, Daniel and Choudhury, Tanzeem , month = sep, year =. Proceedings of the 2012. doi:10.1145/2370216.2370270 , abstract =
-
[31]
ACM Computing Surveys , author =. 2021 , note =. doi:10.1145/3412383 , abstract =
-
[32]
Tabassum, Madiha and Kosinski, Tomasz and Lipford, Heather Richter , booktitle=. "
-
[33]
doi:10.48550/arXiv.2408.15391 , abstract =
Leschanowsky, Anna and Das, Sneha , month = sep, year =. doi:10.48550/arXiv.2408.15391 , abstract =
-
[34]
29th USENIX Security Symposium (USENIX Security 20) , year =
Shimaa Ahmed and Amrita Roy Chowdhury and Kassem Fawaz and Parmesh Ramanathan , title =. 29th USENIX Security Symposium (USENIX Security 20) , year =
-
[35]
Liaqat, Daniyal and Nemati, Ebrahim and Rahman, Mahbubur and Kuang, Jilong , month = dec, year =. 2017. doi:10.1109/LSC.2017.8268148 , abstract =
-
[36]
Hu, Yu and Li, Ran and Wang, Simin and Tao, Fuqiang and Sun, Zhe , month = jul, year =. 2022 7th. doi:10.1109/DSC55868.2022.00054 , abstract =
-
[37]
doi:10.21437/Interspeech.2020-1333 , abstract =
Tomashenko, Natalia and Srivastava, Brij Mohan Lal and Wang, Xin and Vincent, Emmanuel and Nautsch, Andreas and Yamagishi, Junichi and Evans, Nicholas and Patino, Jose and Bonastre, Jean-François and Noé, Paul-Gauthier and Todisco, Massimiliano , month = oct, year =. doi:10.21437/Interspeech.2020-1333 , abstract =
-
[38]
doi:10.48550/arXiv.2203.12468 , abstract =
Tomashenko, Natalia and Wang, Xin and Miao, Xiaoxiao and Nourtel, Hubert and Champion, Pierre and Todisco, Massimiliano and Vincent, Emmanuel and Evans, Nicholas and Yamagishi, Junichi and Bonastre, Jean-François , month = sep, year =. doi:10.48550/arXiv.2203.12468 , abstract =
-
[39]
doi:10.48550/arXiv.2404.02677 , abstract =
Tomashenko, Natalia and Miao, Xiaoxiao and Champion, Pierre and Meyer, Sarina and Wang, Xin and Vincent, Emmanuel and Panariello, Michele and Evans, Nicholas and Yamagishi, Junichi and Todisco, Massimiliano , month = jun, year =. doi:10.48550/arXiv.2404.02677 , abstract =
-
[40]
doi:10.5281/ZENODO.3773931 , note =
Son, Rob Van , month = apr, year =. doi:10.5281/ZENODO.3773931 , note =
-
[41]
Interspeech 2020 , publisher =
Mawalim, Candy Olivia and Galajit, Kasorn and Karnjana, Jessada and Unoki, Masashi , month = oct, year =. Interspeech 2020 , publisher =. doi:10.21437/interspeech.2020-1887 , abstract =
-
[42]
and Singh, Shrishti and Kamble, Madhu R
Gupta, Priyanka and Prajapati, Gauri P. and Singh, Shrishti and Kamble, Madhu R. and Patil, Hemant A. , month = dec, year =. 2020
2020
-
[43]
Meyer, Sarina and Tilli, Pascal and Lux, Florian and Denisov, Pavel and Koch, Julia and Vu, Ngoc Thang , booktitle=
-
[44]
Gaznepoglu, Unal Ege and Leschanowsky, Anna and Peters, Nils , booktitle=
-
[45]
Yao, Jixun and Kuzmin, Nikita and Wang, Qing and Guo, Pengcheng and Ning, Ziqian and Guo, Dake and Lee, Kong Aik and Chng, Eng-Siong and Xie, Lei , month = sep, year =. 4th. doi:10.21437/spsc.2024-12 , abstract =
-
[46]
Tan, Tao and Liu, Shutao and Duan, Yibo and Zhao, Sheng and Shao, Xi , month = sep, year =. 4th
-
[47]
Hua, Hua and Shang, Zengqiang and Li, Xuyuan and Shi, Peiyang and Yang, Chen and Wang, Li and Zhang, Pengyuan , month = sep, year =. 4th. doi:10.21437/spsc.2024-10 , abstract =
-
[48]
Kuzmin, Nikita and Luong, Hieu-Thi and Yao, Jixun and Xie, Lei and Lee, Kong Aik and Chng, Eng-Siong , month = sep, year =. 4th. doi:10.21437/spsc.2024-13 , abstract =
-
[49]
Xinyuan, Henry Li and Cai, Zexin and Garg, Ashi and Duh, Kevin and García-Perera, Leibny Paola and Khudanpur, Sanjeev and Andrews, Nicholas and Wiesner, Matthew , month = sep, year =. 4th. doi:10.48550/arXiv.2409.08913 , abstract =
-
[50]
Matthew Baas and Benjamin. 2023 , booktitle =. doi:10.21437/Interspeech.2023-419 , issn =
-
[51]
Speech Communication , author =. 2017 , note =. doi:10.1016/j.specom.2017.01.008 , abstract =
-
[52]
Speech Communication , author =. 2022 , note =. doi:10.1016/j.specom.2021.11.006 , abstract =
-
[53]
IEEE Transactions on Pattern Analysis and Machine Intelligence , author =. 2023 , note =. doi:10.1109/TPAMI.2023.3263585 , abstract =
-
[54]
doi:10.48550/arXiv.2306.16962 , abstract =
Burkhardt, Felix and Wagner, Johannes and Wierstorf, Hagen and Eyben, Florian and Schuller, Björn , month = jun, year =. doi:10.48550/arXiv.2306.16962 , abstract =
-
[55]
2021 , organization=
Chung, Yu-An and Zhang, Yu and Han, Wei and Chiu, Chung-Cheng and Qin, James and Pang, Ruoming and Wu, Yonghui , booktitle=. 2021 , organization=
2021
-
[56]
2020 , publisher=
Gulati, Anmol and Qin, James and Chiu, Chung-Cheng and Parmar, Niki and Zhang, Yu and Yu, Jiahui and Han, Wei and Wang, Shibo and Zhang, Zhengdong and Wu, Yonghui and others , journal=. 2020 , publisher=
2020
-
[57]
Findings of the Association for Computational Linguistics: ACL 2024
Zhang, Duzhen and Yu, Yahan and Dong, Jiahua and Li, Chenxing and Su, Dan and Chu, Chenhui and Yu, Dong. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.738
-
[58]
Rabiner, Lawrence and Schafer, Ronald , year=
-
[59]
Quarterly journal of experimental psychology (2006) , author =. 2010 , pmid =. doi:10.1080/17470211003721642 , abstract =
-
[60]
Language and Speech , author =. 1997 , note =. doi:10.1177/002383099704000203 , abstract =
-
[61]
Beckman, Mary E and Hirschberg, Julia , journal=
-
[62]
Kong, Jungil and Kim, Jaehyeon and Bae, Jaekyoung , journal=
-
[63]
doi:10.48550/arXiv.2505.15004 , abstract =
Yao, Jixun and Liu, Hexin and Chng, Eng Siong and Xie, Lei , month = may, year =. doi:10.48550/arXiv.2505.15004 , abstract =
-
[64]
International conference on machine learning , pages=
Casanova, Edresson and Weber, Julian and Shulby, Christopher D and Junior, Arnaldo Candido and G. International conference on machine learning , pages=. 2022 , organization=
2022
-
[65]
2021 , organization=
Kim, Jaehyeon and Kong, Jungil and Son, Juhee , booktitle=. 2021 , organization=
2021
-
[66]
9th International Conference on Learning Representations,
Yi Ren and Chenxu Hu and Xu Tan and Tao Qin and Sheng Zhao and Zhou Zhao and Tie. 9th International Conference on Learning Representations,. 2021 , url =
2021
-
[67]
2018 , organization=
Wang, Yuxuan and Stanton, Daisy and Zhang, Yu and Ryan, RJ-Skerry and Battenberg, Eric and Shor, Joel and Xiao, Ying and Jia, Ye and Ren, Fei and Saurous, Rif A , booktitle=. 2018 , organization=
2018
-
[68]
McAuliffe, Michael and Socolof, Michaela and Mihuc, Sarah and Wagner, Michael and Sonderegger, Morgan , title =. Proc. Interspeech 2017 , pages=
2017
-
[69]
Audiocomposer: Towards fine-grained audio generation with natural language descriptions,
Tomashenko, Natalia and Vincent, Emmanuel and Tommasi, Marc , month = apr, year =. doi:10.1109/ICASSP49660.2025.10887896 , abstract =
-
[70]
Bagher Zadeh, AmirAli and Liang, Paul Pu and Poria, Soujanya and Cambria, Erik and Morency, Louis-Philippe , editor =. Proceedings of the 56th. 2018 , pages =. doi:10.18653/v1/P18-1208 , abstract =
-
[71]
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics
Castro, Santiago and Hazarika, Devamanyu and P \'e rez-Rosas, Ver \'o nica and Zimmermann, Roger and Mihalcea, Rada and Poria, Soujanya. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1455
-
[72]
Park, Sunghyun and Shim, Han Suk and Chatterjee, Moitreya and Sagae, Kenji and Morency, Louis-Philippe , month = nov, year =. Proceedings of the 16th. doi:10.1145/2663204.2663260 , abstract =
-
[73]
Chu, Wei and Alwan, Abeer , month = apr, year =. 2009. doi:10.1109/ICASSP.2009.4960497 , abstract =
-
[74]
doi:10.48550/arXiv.2104.00355 , abstract =
Polyak, Adam and Adi, Yossi and Copet, Jade and Kharitonov, Eugene and Lakhotia, Kushal and Hsu, Wei-Ning and Mohamed, Abdelrahman and Dupoux, Emmanuel , month = jul, year =. doi:10.48550/arXiv.2104.00355 , abstract =
-
[75]
doi:10.21437/interspeech.2017-950 , booktitle=
Nagrani, Arsha and Chung, Joon Son and Zisserman, Andrew , year=. doi:10.21437/interspeech.2017-950 , booktitle=
-
[76]
2021 , publisher=
Chen, Guoguo and Chai, Shuzhou and Wang, Guan-Bo and Du, Jiayu and Zhang, Wei-Qiang and Weng, Chao and Su, Dan and Povey, Daniel and Trmal, Jan and Zhang, Junbo and others , journal=. 2021 , publisher=
2021
-
[77]
Godfrey, J.J. and Holliman, E.C. and McDaniel, J. , month = mar, year =. [. doi:10.1109/ICASSP.1992.225858 , abstract =
-
[78]
Zen, Heiga and Dang, Viet and Clark, Rob and Zhang, Yu and Weiss, Ron J and Jia, Ye and Chen, Zhifeng and Wu, Yonghui , booktitle=
-
[79]
Junichi Yamagishi and Christophe Veaux and Kirsten MacDonald , year=
-
[80]
and Fränti, Pasi , month = jan, year =
Malinen, Mikko I. and Fränti, Pasi , month = jan, year =. doi:10.48550/arXiv.2501.16113 , abstract =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.