Interpretable Policy Distillation for Power Grid Topology Control
Pith reviewed 2026-06-28 19:22 UTC · model grok-4.3
The pith
A PPO policy for power grid topology control can be distilled into decision trees and random forests that exceed the teacher in reward and survival at much lower inference cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
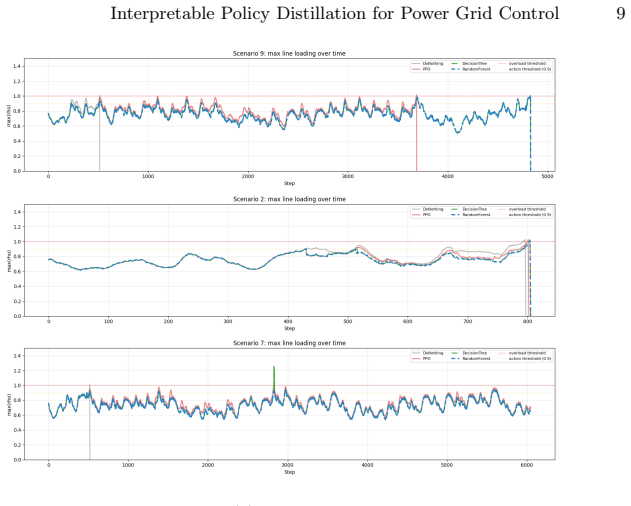
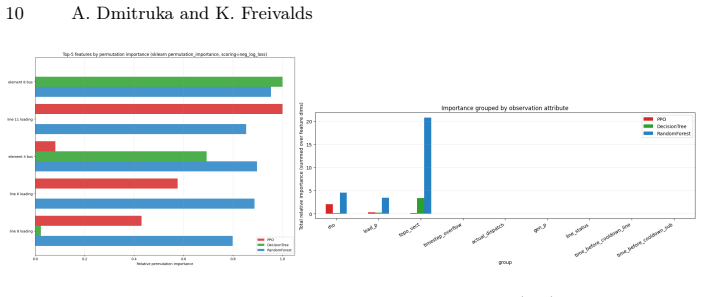
Across held-out validation episodes, both the decision tree and random forest surrogates exceed the PPO teacher in mean reward and survival length at a fraction of the inference cost. The decision tree exhibits high exact-action agreement with the PPO argmax and near-complete agreement within its top-ranked actions, while feature-importance analysis reveals a shift from line-loading signals in the PPO to bus-topology variables in the distilled tree.
What carries the argument
Stress-focused policy distillation into compact tree-based models that approximate the PPO policy for grid topology actions.
Load-bearing premise
That gains observed on held-out episodes from the same 14-bus Grid2Op environment with stress-focused collection will hold for safe real-world use or other grid setups without extra safeguards.
What would settle it
Evaluating the surrogates on a modified grid configuration or with live operational traces and checking if mean reward, survival length, and safety metrics remain superior to the teacher or baseline controllers.
Figures



read the original abstract
Deep reinforcement learning (RL) offers a promising route to real-time power grid operation, yet large neural policies are costly to evaluate, hard to deploy on constrained hardware, and opaque to operators. We ask whether a Proximal Policy Optimization (PPO) agent for grid topology control can be compressed into compact tree-based surrogates without losing operational performance. A PPO teacher is trained on Grid2Op's standard 14-bus environment with a stability-oriented reward, using stress-focused data collection on critical, high-loading states. The policy is then distilled into a decision tree and a random forest. Across held-out validation episodes, both surrogates exceed the teacher in mean reward and survival length at a fraction of the inference cost. The decision tree shows high exact-action agreement with the PPO argmax and near-complete agreement within its top-ranked actions, while remaining small enough to be inspected directly. Feature-importance analysis reveals a representational shift: the PPO policy relies mainly on line-loading signals, while the distilled tree is driven primarily by bus-topology variables. These results suggest that stress-focused distillation can convert a black-box neural controller into a lightweight, auditable rule-like surrogate suited for real-time deployment, while also surfacing risks tied to deterministic actions and topology-specific generalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript trains a PPO teacher policy on Grid2Op's 14-bus environment for topology control using stability-oriented rewards and stress-focused data collection on high-loading states, then distills the policy into a decision tree and random forest. It reports that both surrogates exceed the teacher in mean reward and survival length on held-out validation episodes, at lower inference cost; the decision tree exhibits high exact-action agreement with the PPO argmax (and near-complete agreement within top-ranked actions), remains small enough for direct inspection, and shows a representational shift where feature importance moves from line-loading signals (dominant in PPO) to bus-topology variables.
Significance. If the empirical results hold under broader testing, the work would demonstrate a practical route to compact, auditable rule-like surrogates for RL-based grid control, addressing deployment constraints on hardware and operator interpretability. The stress-focused distillation procedure and the observed feature-importance shift constitute concrete, falsifiable contributions that could inform similar compression efforts in other safety-critical control domains.
major comments (2)
- [Results / Evaluation sections] Results / Evaluation sections: the central claim that surrogates exceed the teacher in mean reward and survival length rests on held-out episodes drawn exclusively from the same 14-bus Grid2Op environment and stress-focused collection distribution; no experiments on alternate topologies (e.g., 118-bus), non-stress loading regimes, or out-of-distribution states are reported, rendering the generalization required for real-world deployment claims untested.
- [Abstract and §3 (distillation procedure)] Abstract and §3 (distillation procedure): the assertion of superior surrogate performance and high action agreement supplies no quantitative metrics, confidence intervals, statistical tests, or exact agreement percentages; without these numbers the empirical superiority cannot be verified or compared to baselines.
minor comments (2)
- [Abstract] The phrase 'a fraction of the inference cost' is used without reporting wall-clock times, FLOPs, or speedup ratios relative to the neural policy.
- [§2] Notation for the stability-oriented reward and the precise definition of 'stress-focused' state sampling should be formalized in §2 to allow exact reproduction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on generalization and quantitative reporting. We address each major comment below and note one standing limitation.
read point-by-point responses
-
Referee: [Results / Evaluation sections] Results / Evaluation sections: the central claim that surrogates exceed the teacher in mean reward and survival length rests on held-out episodes drawn exclusively from the same 14-bus Grid2Op environment and stress-focused collection distribution; no experiments on alternate topologies (e.g., 118-bus), non-stress loading regimes, or out-of-distribution states are reported, rendering the generalization required for real-world deployment claims untested.
Authors: We agree the evaluation is restricted to the 14-bus benchmark. This is the standard setting in Grid2Op topology-control studies, and our contribution centers on showing that stress-focused distillation can produce compact, interpretable surrogates that match or exceed the teacher within this environment. We will add an explicit limitations paragraph stating that broader generalization to 118-bus systems or non-stress regimes remains untested and is left for future work. No additional experiments will be performed. revision: partial
-
Referee: [Abstract and §3 (distillation procedure)] Abstract and §3 (distillation procedure): the assertion of superior surrogate performance and high action agreement supplies no quantitative metrics, confidence intervals, statistical tests, or exact agreement percentages; without these numbers the empirical superiority cannot be verified or compared to baselines.
Authors: The referee is correct that the abstract and §3 currently give only qualitative statements. The detailed numerical results (mean rewards, survival times, exact-match percentages, and top-k agreement) appear only in the evaluation section. We will move the key quantitative figures, including standard deviations and agreement rates, into the abstract and §3 so that the superiority claims are directly verifiable. revision: yes
- Experiments on the 118-bus topology, non-stress regimes, or out-of-distribution states are not present and cannot be added without substantial new computation.
Circularity Check
No circularity detected; empirical evaluation on held-out episodes is independent of inputs
full rationale
The paper trains a PPO policy on the 14-bus Grid2Op environment, distills it into a decision tree and random forest via standard supervised learning on collected trajectories, and reports performance metrics (mean reward, survival length, action agreement) on separate held-out validation episodes. These comparisons are direct empirical measurements and do not reduce by construction to the training data, fitted parameters, or any self-citation chain. No equations, uniqueness theorems, or ansatzes are invoked that would make the reported superiority tautological. The reader's assessment of score 2.0 aligns with the absence of any load-bearing circular step.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The Grid2Op 14-bus environment accurately models real power grid dynamics for the purpose of policy evaluation.
- domain assumption The stability-oriented reward function aligns with operational safety objectives.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2503.20688 (2025)
Anguiano Batanero, E., Fernández, Á., Barbero, Á.: Graph-enhanced model-free reinforcement learning agents for efficient power grid topological control. arXiv preprint arXiv:2503.20688 (2025)
-
[2]
In: Advances in Neural Information Processing Systems 31
Bastani, O., Pu, Y., Solar-Lezama, A.: Verifiable reinforcement learning via policy extraction. In: Advances in Neural Information Processing Systems 31. pp. 2499– 2509 (2018)
2018
-
[3]
Breiman, L.: Random forests. Machine Learning45(1), 5–32 (2001). https://doi.org/10.1023/A:1010933404324
-
[4]
In: Proceedings of the IJCAI 2019 Workshop on Explainable Artificial Intelligence
Coppens, Y., Efthymiadis, K., Lenaerts, T., Nowé, A.: Distilling deep reinforcement learning policies in soft decision trees. In: Proceedings of the IJCAI 2019 Workshop on Explainable Artificial Intelligence. pp. 1–6 (2019)
2019
-
[5]
io/(2026), version 1.12.4; accessed 22 May 2026
Grid2Op Contributors: Grid2Op documentation.https://grid2op.readthedocs. io/(2026), version 1.12.4; accessed 22 May 2026
2026
-
[6]
Energy and AI23, 100671 (2026)
Hassouna, M., Holzhüter, C., Lytaev, P., Thomas, J., Sick, B., Scholz, C.: Graph reinforcement learning for power grids: A comprehensive survey. Energy and AI23, 100671 (2026). https://doi.org/10.1016/j.egyai.2025.100671
-
[7]
Distilling the Knowledge in a Neural Network
Hinton, G., Vinyals, O., Dean, J.: Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531 (2015)
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[8]
arXiv preprint arXiv:2003.07339 (2020)
Kelly, A., O’Sullivan, A., de Mars, P., Marot, A.: Reinforcement learning for electricity network operation. arXiv preprint arXiv:2003.07339 (2020)
-
[9]
Sustainable Energy, Grids and Networks39, 101510 (2024)
Lehna, M., Holzhüter, C., Tomforde, S., Scholz, C.: HUGO: Highlighting un- seen grid options: Combining deep reinforcement learning with a heuristic target topology approach. Sustainable Energy, Grids and Networks39, 101510 (2024). https://doi.org/10.1016/j.segan.2024.101510
-
[10]
arXiv preprint arXiv:2503.23101 (2025)
Marchesini, E., Donnot, B., Crozier, C., Dytham, I., Merz, C., Schewe, L., Wester- beck, N., Wu, C., Marot, A., Donti, P.L.: RL2Grid: Benchmarking reinforcement learning in power grid operations. arXiv preprint arXiv:2503.23101 (2025)
-
[11]
Lulu.com (2020)
Molnar, C.: Interpretable Machine Learning. Lulu.com (2020)
2020
-
[12]
In: Proceedings of the Sixteenth International Conference on Machine Learning
Ng, A.Y., Harada, D., Russell, S.: Policy invariance under reward transforma- tions: Theory and application to reward shaping. In: Proceedings of the Sixteenth International Conference on Machine Learning. pp. 278–287 (1999)
1999
-
[13]
Rudin, C.: Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nature Machine Intelligence1(5), 206–215 (2019). https://doi.org/10.1038/s42256-019-0048-x
-
[14]
MIT Press, 2 edn
Sutton, R.S., Barto, A.G.: Reinforcement Learning: An Introduction. MIT Press, 2 edn. (2018)
2018
-
[15]
Gymnasium: A Standard Interface for Reinforcement Learning Environments
Towers, M., Kwiatkowski, A., Terry, J., Balis, J.U., De Cola, G., Deleu, T., Goulão, M., Kallinteris, A., Krimmel, M., KG, A., Perez-Vicente, R., Pierré, A., Schulhoff, S., Tai, J.J., Tan, H., Younis, O.G.: Gymnasium: A standard interface for reinforcement learning environments. arXiv preprint arXiv:2407.17032 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
arXiv preprint arXiv:2408.11632 (2024)
Vos, D., Verwer, S.: Optimizing interpretable decision tree policies for reinforcement learning. arXiv preprint arXiv:2408.11632 (2024)
-
[17]
In: International Conference on Learning Representations (2021)
Yoon, D., Hong, S., Lee, B.J., Kim, K.E.: Winning the L2RPN challenge: Power grid management via semi-markov afterstate actor-critic. In: International Conference on Learning Representations (2021)
2021
-
[18]
arXiv preprint arXiv:2106.15200 (2021)
Zhou, B., Zeng, H., Liu, Y., Li, K., Wang, F., Tian, H.: Action set based policy optimization for safe power grid management. arXiv preprint arXiv:2106.15200 (2021)
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.