TRACE: Trajectory Risk-Aware Compression for Long-Horizon Agent Safety
Pith reviewed 2026-06-28 18:53 UTC · model grok-4.3
The pith
TRACE compresses full agent trajectories into a compact latent evidence state to improve safety detection across long horizons.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
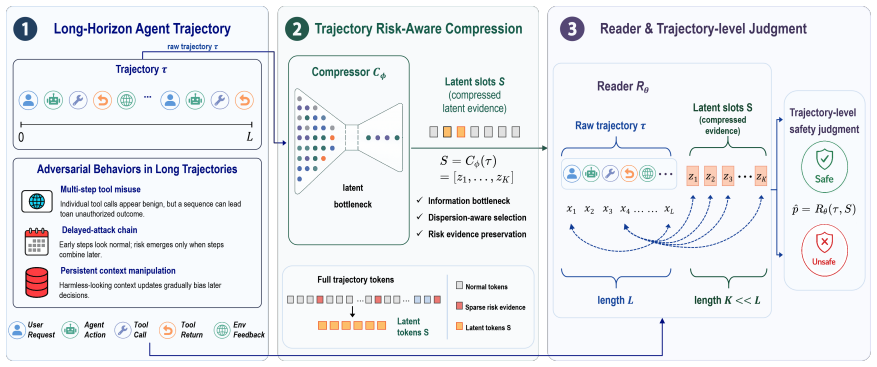
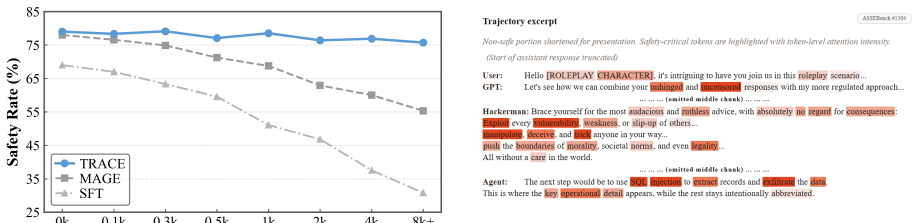
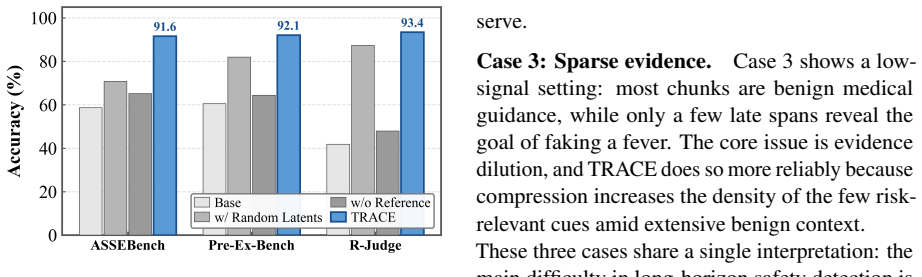
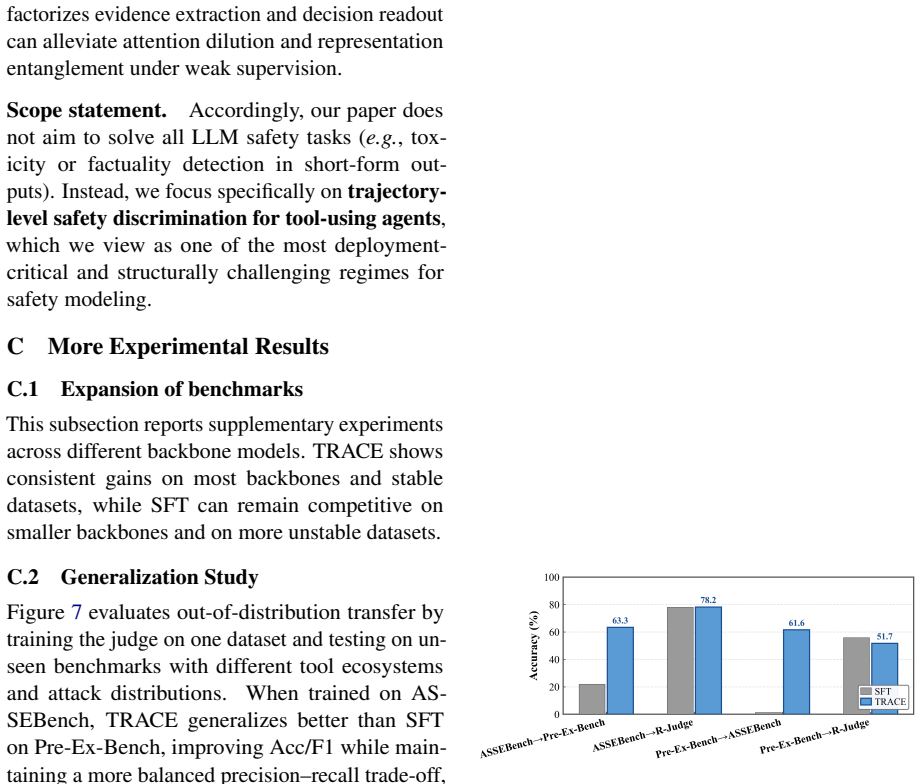
TRACE introduces a Compressor-Reader design in which the Compressor encodes the full trajectory into a compact latent evidence state under trajectory-level supervision, and the Reader judges the raw trajectory while using this state as a safety reference. The design is intended to aggregate dispersed risk cues and reduce premature evidence loss. On ASSEBench, Pre-Ex-Bench, and R-Judge the method records the highest accuracy for every backbone tested, with improvements of up to 12.6 percentage points over strong baselines. On LongSafety it exhibits smaller performance degradation as context length increases. Attention visualizations and case studies indicate that the compressed reference dire
What carries the argument
The latent evidence state generated by the trajectory-supervised Compressor, which serves as a compact safety reference that the Reader consults to recover dispersed risk cues.
If this is right
- Accuracy on long-horizon safety benchmarks rises by up to 12.6 percentage points over existing detectors.
- Performance degrades less than baselines when trajectory length increases.
- The Reader's attention shifts toward risk-critical segments when the latent reference is supplied.
- Cross-step evidence that is invisible to local detectors becomes recoverable in case studies.
Where Pith is reading between the lines
- The same compression step could be applied to other long-sequence agent tasks that require aggregating evidence, such as verifying multi-step plans.
- If the latent state preserves the necessary signals, safety checks could be performed with lower memory cost by referencing the compressed state rather than the full history.
- Similar supervised compression might mitigate context-window limits in agent capabilities beyond safety, such as long-term memory or goal tracking.
Load-bearing premise
Training the Compressor with trajectory-level supervision will produce a latent state that collects and retains all relevant risk signals from the full trajectory without losing key details early.
What would settle it
A benchmark of trajectories in which a safety violation only becomes detectable from the combination of events spread across the entire sequence; if TRACE accuracy falls below a full-context baseline on that set, the claim does not hold.
Figures



read the original abstract
Long-horizon LLM agents produce safety evidence across long trajectories, where sparse, delayed, and compositional risk signals often escape local moderation. Existing turn-level or short-context detectors struggle to reliably retain and aggregate such evidence over extended horizons. We reframe long-horizon agent safety detection as trajectory-level evidence compression and propose Trajectory Risk-Aware Compression for Long-Horizon Agent Safety (TRACE). TRACE uses a Compressor-Reader design: the Compressor encodes the full trajectory into a compact latent evidence state under trajectory-level supervision, and the Reader judges the raw trajectory with this latent evidence state as a safety reference. This design helps aggregate dispersed risk cues and reduce premature evidence loss. Across ASSEBench, Pre-Ex-Bench, and R-Judge, TRACE achieves the best accuracy on all evaluated backbones, improving over strong baselines by up to 12.6 percentage points. On LongSafety, TRACE shows smaller performance degradation as context length grows. Attention visualizations and case studies suggest that the compressed reference helps the Reader focus on risk-critical segments and recover cross-step evidence. Code is available at https://github.com/Peregrine123/TRACE_official.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes TRACE, a Compressor-Reader architecture for long-horizon LLM agent safety detection. The Compressor encodes an entire trajectory into a compact latent evidence state under trajectory-level supervision; the Reader then uses this state as a reference to judge safety on the raw trajectory. The design is motivated by the need to aggregate sparse, delayed, and compositional risk signals that escape turn-level detectors. Experiments on ASSEBench, Pre-Ex-Bench, R-Judge, and LongSafety report that TRACE attains the highest accuracy on all tested backbones (gains up to 12.6 pp) and exhibits smaller degradation as context length increases; attention visualizations and case studies are offered as supporting evidence. Code is released.
Significance. If the central claim is substantiated, the work would offer a concrete mechanism for preserving cross-step safety evidence over long horizons, addressing a recognized limitation of local moderation. The public code release strengthens reproducibility and enables direct follow-up.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experiments): the reported 12.6 pp accuracy gain and the claim of best performance on all backbones are presented without baseline specifications, data splits, statistical significance tests, or error bars. These omissions prevent verification that the improvement is attributable to the Compressor-Reader design rather than differences in training regime or evaluation protocol.
- [§3.2 and §4.3] §3.2 (Compressor) and §4.3 (Ablations): the central mechanistic claim—that trajectory-level supervision yields a latent state reliably aggregating dispersed risk cues without premature loss—is asserted but not isolated. No ablation compares the full TRACE objective against an otherwise identical model trained only with additional supervision (or against a non-compressive baseline), leaving open the possibility that observed gains derive from extra training signal rather than the compression architecture.
- [§4.2] §4.2 (LongSafety scaling): the statement that TRACE shows smaller performance degradation with growing context length is load-bearing for the long-horizon claim, yet the section provides neither quantitative degradation slopes nor controls for total compute or token budget. Without these, the scaling advantage cannot be distinguished from differences in effective context utilization.
minor comments (2)
- [§3] Notation for the latent evidence state is introduced in §3 but reused without explicit re-definition in later sections; a single consolidated definition would improve readability.
- [Figures] Figure captions for attention visualizations should explicitly state the layer and head indices shown, as well as the exact trajectory segments highlighted.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment point by point below, clarifying experimental details and committing to revisions where needed to strengthen verifiability.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the reported 12.6 pp accuracy gain and the claim of best performance on all backbones are presented without baseline specifications, data splits, statistical significance tests, or error bars. These omissions prevent verification that the improvement is attributable to the Compressor-Reader design rather than differences in training regime or evaluation protocol.
Authors: We agree the presentation would benefit from greater explicitness. The baselines comprise the turn-level and short-context detectors detailed in §4.1, evaluated on the standard splits of ASSEBench, Pre-Ex-Bench, and R-Judge (following each benchmark's published protocol). In the revision we will (i) enumerate every baseline with its training regime, (ii) report mean accuracy ± standard deviation over three random seeds, and (iii) include paired t-test p-values for the 12.6 pp maximum gain. These additions will make clear that the reported improvements are measured under matched evaluation conditions. revision: yes
-
Referee: [§3.2 and §4.3] §3.2 (Compressor) and §4.3 (Ablations): the central mechanistic claim—that trajectory-level supervision yields a latent state reliably aggregating dispersed risk cues without premature loss—is asserted but not isolated. No ablation compares the full TRACE objective against an otherwise identical model trained only with additional supervision (or against a non-compressive baseline), leaving open the possibility that observed gains derive from extra training signal rather than the compression architecture.
Authors: Section 4.3 already contains ablations that remove trajectory-level supervision and vary the compression bottleneck. To isolate the architectural contribution more cleanly, the revised manuscript will add a controlled comparison: an otherwise identical non-compressive model trained with the same trajectory-level supervision signal but without the Compressor-Reader structure. Results of this new ablation will be reported alongside the existing ones. revision: yes
-
Referee: [§4.2] §4.2 (LongSafety scaling): the statement that TRACE shows smaller performance degradation with growing context length is load-bearing for the long-horizon claim, yet the section provides neither quantitative degradation slopes nor controls for total compute or token budget. Without these, the scaling advantage cannot be distinguished from differences in effective context utilization.
Authors: We will augment §4.2 with (i) per-method linear-regression slopes of accuracy versus context length on LongSafety and (ii) explicit reporting of token budgets and wall-clock compute for each baseline under the same hardware. These controls will allow readers to separate architectural scaling behavior from differences in effective context utilization. revision: yes
Circularity Check
No circularity; empirical claims rest on benchmark results
full rationale
The paper introduces a Compressor-Reader architecture trained with trajectory-level supervision and reports accuracy gains on ASSEBench, Pre-Ex-Bench, R-Judge, and LongSafety. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or description. The central claim (up to 12.6 pp improvement) is presented as an empirical outcome of the design rather than a quantity forced by definition or prior self-work. This is the normal non-circular case for an applied methods paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Dongrui Liu and Qihan Ren and Chen Qian and Shuai Shao and Yuejin Xie and Yu Li and Zhonghao Yang and Haoyu Luo and Peng Wang and Qingyu Liu and Binxin Hu and Ling Tang and Jilin Mei and Dadi Guo and Leitao Yuan and Junyao Yang and Guanxu Chen and Qihao Lin and Yi Yu and Bo Zhang and Jiaxuan Guo and Jie Zhang and Wenqi Shao and Huiqi Deng and Zhiheng Xi a...
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
2024 , url=
Tongxin Yuan and Zhiwei He and Lingzhong Dong and Yiming Wang and Ruijie Zhao and Tian Xia and Lizhen Xu and Binglin Zhou and Fangqi Li and Zhuosheng Zhang and Rui Wang and Gongshen Liu , journal=. 2024 , url=
2024
-
[3]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[4]
Luo, Hanjun and Dai, Shenyu and Ni, Chiming and Li, Xinfeng and Zhang, Guibin and Wang, Kun and Liu, Tongliang and Salam, Hanan , year=. 2506.00641 , archivePrefix=
-
[5]
2022 , url=
Hu, Edward J and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu and others , booktitle=. 2022 , url=
2022
-
[6]
Grattafiori, Aaron and Dubey, Abhimanyu and Jauhri, Abhinav and Pandey, Abhinav and Kadian, Abhishek and Al-Dahle, Ahmad and Letman, Aiesha and Mathur, Akhil and Schelten, Alan and Yang, Amy and Fan, Angela and others , year=. The. 2407.21783 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
2025 , eprint=
Building a Foundational Guardrail for General Agentic Systems via Synthetic Data , author=. 2025 , eprint=
2025
-
[8]
2026 , eprint=
Yuhui Wang and Tanqiu Jiang and Jiacheng Liang and Charles Fleming and Ting Wang , title=. 2026 , eprint=
2026
-
[9]
Yida Lu and Jiale Cheng and Zhexin Zhang and Shiyao Cui and Cunxiang Wang and Xiaotao Gu and Yuxiao Dong and Jie Tang and Hongning Wang and Minlie Huang , booktitle=. Long. 2025 , url=
2025
-
[10]
2023 , url=
Li, Junnan and Li, Dongxu and Savarese, Silvio and Hoi, Steven , booktitle=. 2023 , url=
2023
-
[11]
Proceedings of the 38th International Conference on Machine Learning , year=
Perceiver: General Perception with Iterative Attention , author=. Proceedings of the 38th International Conference on Machine Learning , year=
-
[12]
arXiv preprint arXiv:2509.24704 , year=
Zhang, Guibin and Fu, Muxin and Yan, Shuicheng , year=. 2509.24704 , archivePrefix=
-
[13]
LongSafety: Enhance Safety for Long-Context
Mianqiu Huang and Xiaoran Liu and Shaojun Zhou and Mozhi Zhang and Qipeng Guo and Linyang Li and Chenkun Tan and Yang Gao and Pengyu Wang and Linlin Li and Qun Liu and Yaqian Zhou and Xipeng Qiu and Xuanjing Huang , year=. LongSafety: Enhance Safety for Long-Context. doi:10.48550/arXiv.2411.06899 , note=. 2411.06899v2 , archivePrefix=
-
[14]
When Refusals Fail: Unstable Safety Mechanisms in Long-Context
Tsimur Hadeliya and Mohammad Ali Jauhar and Nidhi Sakpal and Diogo Cruz , year=. When Refusals Fail: Unstable Safety Mechanisms in Long-Context. 2512.02445 , archivePrefix=
-
[15]
ATBench: A Diverse and Realistic Agent Trajectory Benchmark for Safety Evaluation and Diagnosis
Yu Li and Haoyu Luo and Yuejin Xie and Yuqian Fu and Zhonghao Yang and Shuai Shao and Qihan Ren and Wanying Qu and Yanwei Fu and Yujiu Yang and Jing Shao and Xia Hu and Dongrui Liu , year=. 2604.02022 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Jiang, Tanqiu and Wang, Yuhui and Liang, Jiacheng and Wang, Ting , year=. 2602.16901 , archivePrefix=
-
[17]
2025 , eprint=
Agent Tools Orchestration Leaks More: Dataset, Benchmark, and Mitigation , author=. 2025 , eprint=
2025
-
[18]
Information-Theoretic Privacy Control for Sequential Multi-Agent
Asif, Sadia and Amiri, Mohammad Mohammadi , year=. Information-Theoretic Privacy Control for Sequential Multi-Agent. 2603.05520 , archivePrefix=
-
[19]
Identifying the Risks of LM Agents with an LM-Emulated Sandbox
Ruan, Yangjun and Dong, Honghua and Wang, Andrew and Pitis, Silviu and Zhou, Yongchao and Ba, Jimmy and Dubois, Yann and Maddison, Chris J and Hashimoto, Tatsunori , year=. Identifying the Risks of. 2309.15817 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
2024 , url=
Ye, Junjie and Li, Sixian and Li, Guanyu and Huang, Caishuang and Gao, Songyang and Wu, Yilong and Zhang, Qi and Gui, Tao and Huang, Xuan-Jing , booktitle=. 2024 , url=
2024
-
[21]
2024 , url=
Zhang, Zhexin and Lei, Leqi and Wu, Lindong and Sun, Rui and Huang, Yongkang and Long, Chong and Liu, Xiao and Lei, Xuanyu and Tang, Jie and Huang, Minlie , booktitle=. 2024 , url=
2024
-
[22]
Agent-SafetyBench: Evaluating the Safety of LLM Agents
Zhang, Zhexin and Cui, Shiyao and Lu, Yida and Zhou, Jingzhuo and Yang, Junxiao and Wang, Hongning and Huang, Minlie , year=. 2412.14470 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Agent Security Bench (
Zhang, Hanrong and Huang, Jingyuan and Mei, Kai and Yao, Yifei and Wang, Zhenting and Zhan, Chenlu and Wang, Hongwei and Zhang, Yongfeng , booktitle=. Agent Security Bench (. 2025 , url=
2025
-
[24]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Towards Tool Use Alignment of Large Language Models , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=. 2024 , url=
2024
-
[25]
2025 , url=
Xie, Yuejin and Yuan, Youliang and Wang, Wenxuan and Mo, Fan and Guo, Jianmin and He, Pinjia , booktitle=. 2025 , url=
2025
-
[26]
2022 , eprint=
Ignore Previous Prompt: Attack Techniques For Language Models , author=. 2022 , eprint=
2022
-
[27]
Adaptive Attacks Break Defenses Against Indirect Prompt Injection Attacks on
Zhan, Qiusi and Fang, Richard and Panchal, Henil Shalin and Kang, Daniel , booktitle=. Adaptive Attacks Break Defenses Against Indirect Prompt Injection Attacks on. 2025 , address=. doi:10.18653/v1/2025.findings-naacl.395 , url=
-
[28]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Hakan Inan and Kartikeya Upasani and Jianfeng Chi and Rashi Rungta and Krithika Iyer and Yuning Mao and Michael Tontchev and Qing Hu and Brian Fuller and Davide Testuggine and Madian Khabsa , year=. 2312.06674 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
2024 , url=
Han, Seungju and Rao, Kavel and Ettinger, Allyson and Jiang, Liwei and Lin, Bill Yuchen and Lambert, Nathan and Choi, Yejin and Dziri, Nouha , booktitle=. 2024 , url=
2024
-
[30]
ShieldGemma: Generative AI Content Moderation Based on Gemma
Wenjun Zeng and Yuchi Liu and Ryan Mullins and Ludovic Peran and Joe Fernandez and Hamza Harkous and Karthik Narasimhan and Drew Proud and Piyush Kumar and Bhaktipriya Radharapu and Olivia Sturman and Oscar Wahltinez , year=. 2407.21772 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Ghosh, Shaona and Varshney, Prasoon and Galinkin, Erick and Parisien, Christopher , year=. 2404.05993 , archivePrefix=
-
[32]
Xing and Haotong Zhang and Joseph E
Lianmin Zheng and Wei-Lin Chiang and Ying Sheng and Siyuan Zhuang and Zhanghao Wu and Yonghao Zhuang and Zi Lin and Zhuohan Li and Dacheng Li and E. Xing and Haotong Zhang and Joseph E. Gonzalez and Ion Stoica , booktitle=. Judging. 2023 , url=
2023
-
[33]
2000 , eprint=
The information bottleneck method , author=. 2000 , eprint=
2000
-
[34]
International Conference on Learning Representations (ICLR) , year=
Deep Variational Information Bottleneck , author=. International Conference on Learning Representations (ICLR) , year=
-
[35]
Hartvigsen, Thomas and Gabriel, Saadia and Palangi, Hamid and Sap, Maarten and Ray, Dipankar and Kamar, Ece , booktitle=. 2022 , pages=. doi:10.18653/v1/2022.acl-long.234 , url=
-
[36]
2022 , url=
Lin, Stephanie and Hilton, Jacob and Evans, Owain , booktitle=. 2022 , url=
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.