An Attribute-Based Measure of Video Complexity
Pith reviewed 2026-06-28 18:58 UTC · model grok-4.3
The pith
Video complexity equals the expected failure rate of a video-LLM inside cells of a quantized attribute space.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
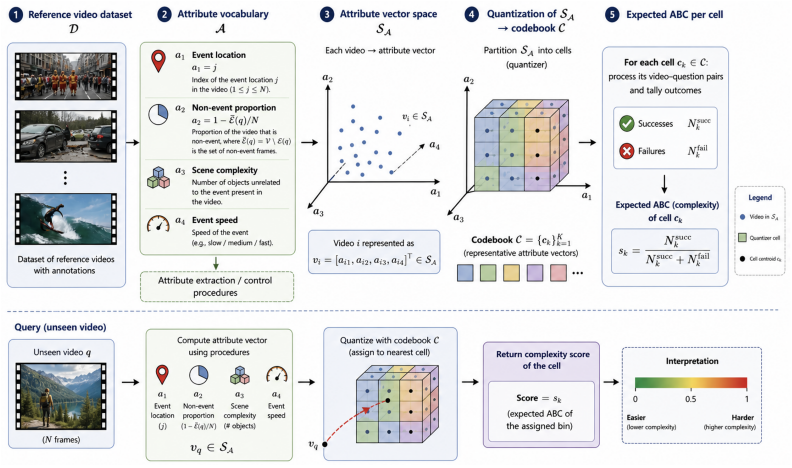
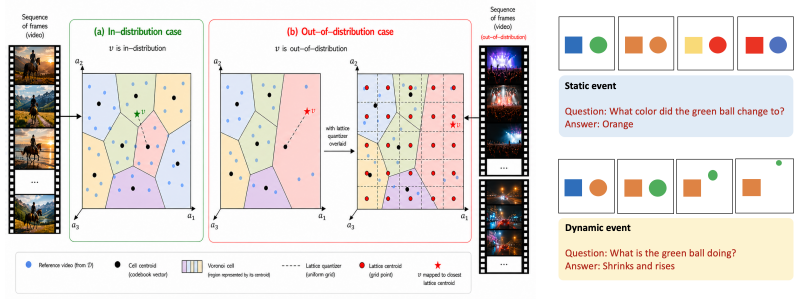
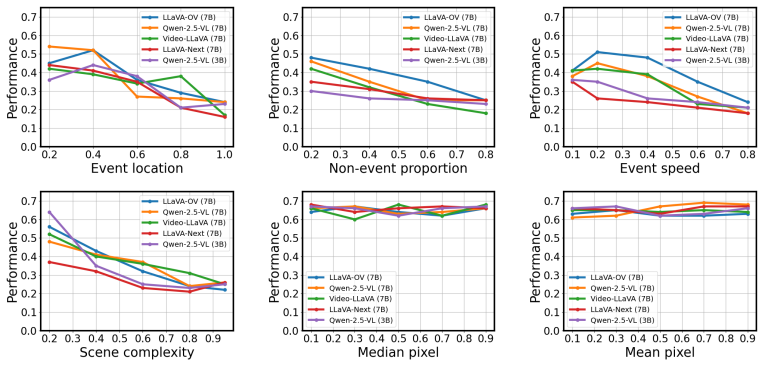
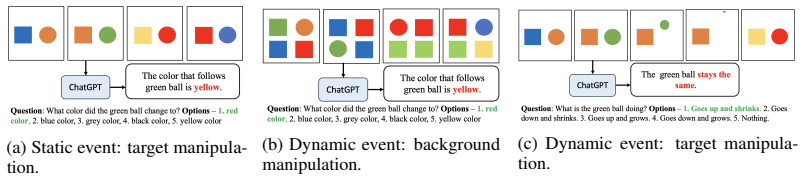
VideoABC estimates complexity by mapping videos to a pre-defined attribute space, quantizing the space, and storing the empirical failure rate of each quantization cell. A hybrid quantizer (k-means plus universal lattice) ensures coverage both inside and outside the reference distribution, while a synthetic generation procedure based on target-distractor manipulations supplies the data needed to compute cell values. The resulting score is read directly from the cell that contains the new video's attribute vector.
What carries the argument
Quantization of a low-dimensional attribute space into cells, each storing the average observed failure rate of videos that land in that cell.
If this is right
- Benchmark difficulty can be summarized by the distribution of its videos across attribute cells without running any model.
- The same attribute vocabulary supports generation of new test videos whose expected complexity is known in advance.
- Complexity estimates require only attribute extraction rather than full model inference or a second LLM judge.
- The score directly names which attributes drive the difficulty of any given video-question pair.
Where Pith is reading between the lines
- The cell values could be recomputed for different video-LLMs to reveal model-specific failure patterns across the same attributes.
- If attribute extraction itself is cheap, the measure could be used to filter or prioritize large unlabeled video collections for evaluation.
- Adding or replacing attributes in the vocabulary would change which failure modes are captured and could be tested by measuring stability of the new cells.
Load-bearing premise
A small fixed set of video attributes divides the space so that every cell has roughly the same failure rate for all videos that fall into it.
What would settle it
Collect many new videos that all map to the same quantization cell and measure their actual failure rates; if those rates vary widely around the cell's stored value, the estimate is not stable.
Figures


read the original abstract
A new framework for the estimation of the complexity posed by video-question pairs to video-LLMs, Video Attribute-Based Complexity (VideoABC), is proposed. Video complexity is defined as the probability of failure of a video-LLM for a given video-question pair. VideoABC is a non-parametric complexity measure, using a reference video dataset and a pre-defined vocabulary of video attributes informative of complexity, \eg the scene complexity or the speed of the video event informative of the question. In a training phase, reference videos are projected into the space of these attributes, which is then quantized. The expected ABC of each quantization cell is then computed. Given a new video and its projection into the attribute space, complexity is estimated by the expected ABC of the associated quantization cell. To enable the use of VideoABC with small reference video datasets, two quantizers are combined: a k-means quantizer that enables accurate complexity estimates for samples in the distribution of the reference dataset and a universal lattice quantizer that guarantees generalization to out-of-distribution samples. A synthetic video generation procedure, inspired by target-distractor manipulations of psychophysics studies, is proposed to populate the cells of the lattice quantizer during training, enabling the computation of their expected ABCs. Experimental results show that VideoABCis effective even with very low-dimensional attribute representations, substantially outperforming approaches like `video-LLM as judge' with much less complexity. Finally, the explainable nature of the VideoABC score, in terms of well-defined attributes, is shown to provide insights on how the attribute composition of benchmarks affects their complexity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Video Attribute-Based Complexity (VideoABC), a non-parametric estimator of video-question complexity for video-LLMs defined as the probability of model failure. Reference videos are projected into a low-dimensional pre-defined attribute space (e.g., scene complexity, event speed), quantized via combined k-means and universal lattice quantizers, and cell-wise expected failure rates are computed from observed failures on reference data plus synthetic videos generated via target-distractor manipulations. For a query video, complexity is the mean failure rate of its containing cell. The work claims that low-dimensional attribute representations suffice for effective estimates, that VideoABC substantially outperforms 'video-LLM as judge' approaches while being less complex, and that the attribute-based scores yield insights into benchmark difficulty.
Significance. If the core assumption holds, VideoABC would supply an efficient, explainable, and reference-based alternative to direct LLM judging for video complexity assessment, with potential utility for benchmark curation and model analysis. The dual-quantizer design and synthetic-video procedure for lattice population address small-reference-set limitations. The significance is limited by the absence of direct validation that attribute-induced cells exhibit stable intra-cell failure probabilities, especially for OOD videos.
major comments (3)
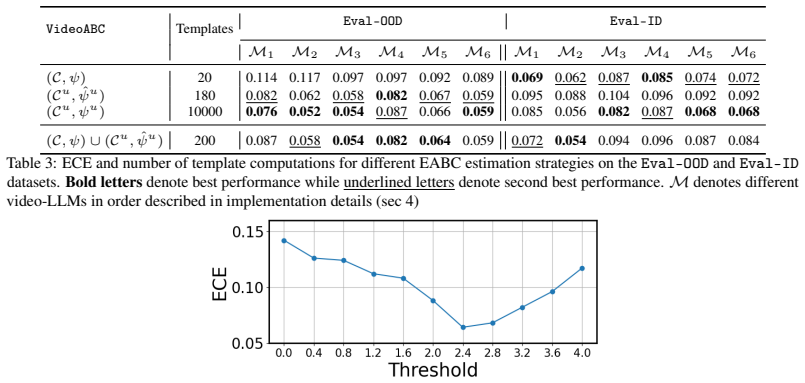
- [Abstract] Abstract and Experiments section: The central claim that VideoABC 'substantially outperform[s] approaches like video-LLM as judge' is asserted without any quantitative results, error bars, specification of the video-LLMs tested, or details on how expected ABC values are obtained from reference videos, preventing verification of the empirical contribution.
- [Method] Method (quantization and synthetic generation): The non-parametric estimator assigns complexity via cell-mean failure rates; this is load-bearing on the untested claim that the chosen low-dimensional attributes induce partitions where intra-cell failure probability is approximately constant for both in-distribution and OOD videos handled by the lattice quantizer. No measurement of within-cell variance or of agreement between synthetic and real failure rates is reported.
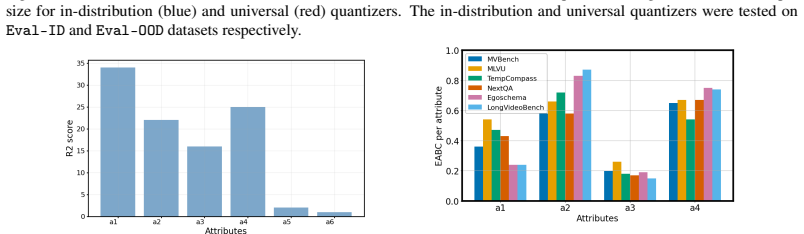
- [Experiments] Experiments: The effectiveness at 'very low-dimensional attribute representations' is claimed, yet the paper supplies no ablation or direct test of how well the pre-defined attribute vocabulary (scene complexity, event speed, etc.) captures factors driving LLM failures versus orthogonal factors such as fine-grained object relations or question-video misalignment.
minor comments (2)
- [Abstract] Abstract: 'VideoABCis' is missing a space.
- [Method] The description of how the lattice quantizer 'guarantees generalization' would benefit from a brief statement of the lattice spacing and coverage properties.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below with clarifications and note where revisions will strengthen the presentation of results and validation of assumptions.
read point-by-point responses
-
Referee: [Abstract] Abstract and Experiments section: The central claim that VideoABC 'substantially outperform[s] approaches like video-LLM as judge' is asserted without any quantitative results, error bars, specification of the video-LLMs tested, or details on how expected ABC values are obtained from reference videos, preventing verification of the empirical contribution.
Authors: We agree that the current version does not provide sufficient quantitative details, error bars, model specifications, or computation descriptions in the abstract or Experiments section to allow full verification. We will revise both sections to include specific performance metrics with error bars, the video-LLMs evaluated, and explicit details on computing expected ABC values from the reference videos. revision: yes
-
Referee: [Method] Method (quantization and synthetic generation): The non-parametric estimator assigns complexity via cell-mean failure rates; this is load-bearing on the untested claim that the chosen low-dimensional attributes induce partitions where intra-cell failure probability is approximately constant for both in-distribution and OOD videos handled by the lattice quantizer. No measurement of within-cell variance or of agreement between synthetic and real failure rates is reported.
Authors: The assumption of stable intra-cell failure probabilities underpins the estimator for both ID and OOD cases via the lattice quantizer. While the dual-quantizer design and psychophysics-inspired synthesis aim to support this, we acknowledge the absence of explicit variance measurements or synthetic-real agreement checks. We will add these analyses to the revised Method and Experiments sections. revision: yes
-
Referee: [Experiments] Experiments: The effectiveness at 'very low-dimensional attribute representations' is claimed, yet the paper supplies no ablation or direct test of how well the pre-defined attribute vocabulary (scene complexity, event speed, etc.) captures factors driving LLM failures versus orthogonal factors such as fine-grained object relations or question-video misalignment.
Authors: The reported effectiveness with low-dimensional attributes is based on overall benchmark performance. We agree that a direct ablation comparing the chosen vocabulary against orthogonal factors would provide stronger evidence. We will add such an ablation study to the revised Experiments section. revision: yes
Circularity Check
No circularity; standard non-parametric estimator from observed failures
full rationale
The paper defines complexity explicitly as LLM failure probability and estimates it via attribute-space quantization followed by cell-wise averaging of observed failures on reference (and synthetic) data. This is a conventional non-parametric procedure equivalent to binning and lookup; it does not reduce the target quantity to itself by definition or by self-citation. No load-bearing uniqueness theorem, fitted parameter renamed as prediction, or ansatz imported via prior work appears. The modeling assumption that the chosen attributes induce stable intra-cell failure rates is an empirical claim subject to validation, not a circular step in the derivation chain.
Axiom & Free-Parameter Ledger
free parameters (2)
- attribute vocabulary
- quantizer hyperparameters (k, lattice spacing)
axioms (1)
- domain assumption Selected video attributes capture the factors that determine LLM failure probability
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
arXiv preprint arXiv:2108.02818 (2021)
Agarwal, S., Krueger, G., Clark, J., Radford, A., Kim, J.W., Brundage, M.: Evaluating clip: towards characterization of broader capabilities and downstream implications. arXiv preprint arXiv:2108.02818 (2021)
-
[3]
In: Handbook of research on machine learning applications and trends: Algorithms, methods, and techniques, pp
Bella, A., Ferri, C., Hernández-Orallo, J., Ramírez-Quintana, M.J.: Calibration of machine learning models. In: Handbook of research on machine learning applications and trends: Algorithms, methods, and techniques, pp. 128–146. IGI Global Scientific Publishing (2010)
2010
-
[4]
Information Systems95, 101641 (2021)
Böken, B.: On the appropriateness of platt scaling in classifier calibration. Information Systems95, 101641 (2021)
2021
-
[5]
Elsevier (2013)
Broadbent, D.E.: Perception and communication. Elsevier (2013)
2013
-
[6]
In: Proceedings of the ieee conference on computer vision and pattern recognition
Caba Heilbron, F., Escorcia, V ., Ghanem, B., Carlos Niebles, J.: Activitynet: A large-scale video benchmark for human activity understanding. In: Proceedings of the ieee conference on computer vision and pattern recognition. pp. 961–970 (2015)
2015
-
[7]
arXiv preprint arXiv:2305.13292 (2023)
Chen, G., Zheng, Y .D., Wang, J., Xu, J., Huang, Y ., Pan, J., Wang, Y ., Wang, Y ., Qiao, Y ., Lu, T., et al.: Videollm: Modeling video sequence with large language models. arXiv preprint arXiv:2305.13292 (2023)
-
[8]
Chun, M.M., Wolfe, J.M.: Just say no: How are visual searches terminated when there is no target present? Cognitive psychology30(1), 39–78 (1996)
1996
-
[9]
Springer New York (1999)
Conway, J.H., Sloane, N.J.A.: Sphere Packings, Lattices and Groups. Springer New York (1999)
1999
-
[10]
Frontiers in psychology5, 841 (2014)
Craik, F.I.: Effects of distraction on memory and cognition: a commentary. Frontiers in psychology5, 841 (2014)
2014
-
[11]
Global ecology and biogeography29(4), 760–765 (2020)
Dormann, C.F.: Calibration of probability predictions from machine-learning and statistical models. Global ecology and biogeography29(4), 760–765 (2020)
2020
-
[12]
Wiley-Interscience, 2 edn
Duda, R.O., Hart, P.E., Stork, D.G.: Pattern Classification (2nd Edition). Wiley-Interscience, 2 edn. (November 2000)
2000
-
[13]
Duncker & Humblot (1885)
Ebbinghaus, H.: Über das gedächtnis: untersuchungen zur experimentellen psychologie. Duncker & Humblot (1885)
-
[14]
arXiv preprint arXiv:2505.13429 (2025)
Eyzaguirre, C., Vasiljevic, I., Dave, A., Wu, J., Ambrus, R.A., Kollar, T., Niebles, J.C., Tokmakov, P.: Understanding complexity in videoqa via visual program generation. arXiv preprint arXiv:2505.13429 (2025)
-
[15]
Fechner, G.T.: Elemente der psychophysik, vol. 2. Breitkopf u. Härtel (1860)
- [16]
-
[17]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Fu, C., Dai, Y ., Luo, Y ., Li, L., Ren, S., Zhang, R., Wang, Z., Zhou, C., Shen, Y ., Zhang, M., et al.: Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 24108–24118 (2025)
2025
-
[18]
Current Directions in Psychological Science 23(2), 147–153 (2014)
Geng, J.J.: Attentional mechanisms of distractor suppression. Current Directions in Psychological Science 23(2), 147–153 (2014)
2014
-
[19]
Cengage learning Stamford, CT (2015)
Goldstein, E.B.: Cognitive psychology: Connecting mind, research, and everyday experience. Cengage learning Stamford, CT (2015)
2015
-
[20]
IEEE transactions on pattern analysis and machine intelligence29(12), 2247–2253 (2007)
Gorelick, L., Blank, M., Shechtman, E., Irani, M., Basri, R.: Actions as space-time shapes. IEEE transactions on pattern analysis and machine intelligence29(12), 2247–2253 (2007)
2007
-
[21]
Adaptive Computation Time for Recurrent Neural Networks
Graves, A.: Adaptive computation time for recurrent neural networks. arXiv preprint arXiv:1603.08983 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[22]
Macmillan London (1890)
James, W., Burkhardt, F., Bowers, F., Skrupskelis, K.: The principles of psychology. Macmillan London (1890)
-
[23]
Cognitive psychology24(2), 175–219 (1992)
Kahneman, D., Treisman, A., Gibbs, B.J.: The reviewing of object files: Object-specific integration of information. Cognitive psychology24(2), 175–219 (1992)
1992
-
[24]
The Kinetics Human Action Video Dataset
Kay, W., Carreira, J., Simonyan, K., Zhang, B., Hillier, C., Vijayanarasimhan, S., Viola, F., Green, T., Back, T., Natsev, P., et al.: The kinetics human action video dataset. arXiv preprint arXiv:1705.06950 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[25]
In: 2011 International conference on computer vision
Kuehne, H., Jhuang, H., Garrote, E., Poggio, T., Serre, T.: Hmdb: a large video database for human motion recognition. In: 2011 International conference on computer vision. pp. 2556–2563. IEEE (2011) 11
2011
-
[26]
Laurençon, H., Tronchon, L., Cord, M., Sanh, V .: What matters when building vision-language models? Advances in Neural Information Processing Systems37, 87874–87907 (2024)
2024
-
[27]
Current directions in psychological science19(3), 143–148 (2010)
Lavie, N.: Attention, distraction, and cognitive control under load. Current directions in psychological science19(3), 143–148 (2010)
2010
-
[28]
LLaVA-OneVision: Easy Visual Task Transfer
Li, B., Zhang, Y ., Guo, D., Zhang, R., Li, F., Zhang, H., Zhang, K., Zhang, P., Li, Y ., Liu, Z., et al.: Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[29]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Li, K., Wang, Y ., He, Y ., Li, Y ., Wang, Y ., Liu, Y ., Wang, Z., Xu, J., Chen, G., Luo, P., et al.: Mvbench: A comprehensive multi-modal video understanding benchmark. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 22195–22206 (2024)
2024
-
[30]
In: Proceedings of the European conference on computer vision (ECCV)
Li, Y ., Li, Y ., Vasconcelos, N.: Resound: Towards action recognition without representation bias. In: Proceedings of the European conference on computer vision (ECCV). pp. 513–528 (2018)
2018
-
[31]
In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing
Lin, B., Ye, Y ., Zhu, B., Cui, J., Ning, M., Jin, P., Yuan, L.: Video-llava: Learning united visual representation by alignment before projection. In: Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. pp. 5971–5984 (2024)
2024
-
[32]
arXiv e-prints pp
Liu, F., Liu, Y ., Shi, L., Huang, H., Wang, R., Yang, Z., Zhang, L., Li, Z., Ma, Y .: Exploring and evaluating hallucinations in llm-powered code generation. arXiv e-prints pp. arXiv–2404 (2024)
2024
-
[33]
Liu, Y ., Li, S., Liu, Y ., Wang, Y ., Ren, S., Li, L., Chen, S., Sun, X., Hou, L.: Tempcompass: Do video llms really understand videos? arXiv preprint arXiv:2403.00476 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
Journal of verbal learning and verbal behavior13(5), 585–589 (1974)
Loftus, E.F., Palmer, J.C.: Reconstruction of automobile destruction: An example of the interaction between language and memory. Journal of verbal learning and verbal behavior13(5), 585–589 (1974)
1974
-
[35]
Trends in cognitive sciences25(3), 228–239 (2021)
Lorenc, E.S., Mallett, R., Lewis-Peacock, J.A.: Distraction in visual working memory: Resistance is not futile. Trends in cognitive sciences25(3), 228–239 (2021)
2021
-
[36]
Advances in Neural Information Processing Systems36, 46212–46244 (2023)
Mangalam, K., Akshulakov, R., Malik, J.: Egoschema: A diagnostic benchmark for very long-form video language understanding. Advances in Neural Information Processing Systems36, 46212–46244 (2023)
2023
-
[37]
Psychological review63(2), 81 (1956)
Miller, G.A.: The magical number seven, plus or minus two: Some limits on our capacity for processing information. Psychological review63(2), 81 (1956)
1956
-
[38]
In: CVPR workshops
Nixon, J., Dusenberry, M.W., Zhang, L., Jerfel, G., Tran, D.: Measuring calibration in deep learning. In: CVPR workshops. vol. 2 (2019)
2019
-
[39]
Pichai, S., Hassabis, D., Kavukcuoglu, K.: A new era of intelligence with gemini 3. Google. URL: https://blog. google/products-and-platforms/products/gemini/gemini-3/ (2025)
2025
-
[40]
In: Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers)
Platanios, E.A., Stretcu, O., Neubig, G., Poczos, B., Mitchell, T.: Competence-based curriculum learning for neural machine translation. In: Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers). pp. 1162–1172 (2019)
2019
-
[41]
arXiv preprint arXiv:2405.08813 (2024)
Rawal, R., Saifullah, K., Farré, M., Basri, R., Jacobs, D., Somepalli, G., Goldstein, T.: Cinepile: A long video question answering dataset and benchmark. arXiv preprint arXiv:2405.08813 (2024)
-
[42]
In: Proceedings of the 17th International Conference on Pattern Recognition, 2004
Schuldt, C., Laptev, I., Caputo, B.: Recognizing human actions: a local svm approach. In: Proceedings of the 17th International Conference on Pattern Recognition, 2004. ICPR 2004. vol. 3, pp. 32–36. IEEE (2004)
2004
-
[43]
In: Proceedings of the 2024 ACM Conference on International Computing Education Research-V olume 1
Smith, D.H., Poulsen, S., Emeka, C., Wu, Z., Haynes-Magyar, C., Zilles, C.: Distractors make you pay attention: Investigating the learning outcomes of including distractor blocks in parsons problems. In: Proceedings of the 2024 ACM Conference on International Computing Education Research-V olume 1. pp. 177–191 (2024)
2024
-
[44]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
Soomro, K., Zamir, A.R., Shah, M.: Ucf101: A dataset of 101 human actions classes from videos in the wild. arXiv preprint arXiv:1212.0402 (2012)
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[45]
less is more
Spitkovsky, V .I., Alshawi, H., Jurafsky, D.: Baby steps: How “less is more” in unsupervised dependency parsing. NIPS: Grammar Induction, Representation of Language and Language Learning pp. 1–10 (2009)
2009
-
[46]
Advances in Neural Information Processing Systems 37, 34188–34216 (2024)
Sriramanan, G., Bharti, S., Sadasivan, V .S., Saha, S., Kattakinda, P., Feizi, S.: Llm-check: Investigating detection of hallucinations in large language models. Advances in Neural Information Processing Systems 37, 34188–34216 (2024)
2024
-
[47]
Journal of Experimental Psychology: Human Perception and Performance17(3), 652 (1991)
Treisman, A.: Search, similarity, and integration of features between and within dimensions. Journal of Experimental Psychology: Human Perception and Performance17(3), 652 (1991)
1991
-
[48]
Cognitive psychology14(1), 107–141 (1982)
Treisman, A., Schmidt, H.: Illusory conjunctions in the perception of objects. Cognitive psychology14(1), 107–141 (1982)
1982
-
[49]
Scientific American255(5), 114–125 (1986) 12
Treisman, A., et al.: Features and objects in visual processing. Scientific American255(5), 114–125 (1986) 12
1986
-
[50]
Quarterly Journal of Experimental Psychology 12(4), 242–248 (1960)
Treisman, A.M.: Contextual cues in selective listening. Quarterly Journal of Experimental Psychology 12(4), 242–248 (1960)
1960
-
[51]
Psychological review76(3), 282 (1969)
Treisman, A.M.: Strategies and models of selective attention. Psychological review76(3), 282 (1969)
1969
-
[52]
Cognitive psychology12(1), 97–136 (1980)
Treisman, A.M., Gelade, G.: A feature-integration theory of attention. Cognitive psychology12(1), 97–136 (1980)
1980
-
[53]
science185(4157), 1124–1131 (1974)
Tversky, A., Kahneman, D.: Judgment under uncertainty: Heuristics and biases: Biases in judgments reveal some heuristics of thinking under uncertainty. science185(4157), 1124–1131 (1974)
1974
-
[54]
Frontiers in Psychology16, 1632165 (2025)
Wang, C.: The dual system model of distraction: explaining the cognitive mechanism of distraction. Frontiers in Psychology16, 1632165 (2025)
2025
-
[55]
arXiv preprint arXiv:2407.15018 (2024)
Wiegreffe, S., Tafjord, O., Belinkov, Y ., Hajishirzi, H., Sabharwal, A.: Answer, assemble, ace: Understand- ing how lms answer multiple choice questions. arXiv preprint arXiv:2407.15018 (2024)
-
[56]
Psychonomic bulletin & review1(2), 202–238 (1994)
Wolfe, J.M.: Guided search 2.0 a revised model of visual search. Psychonomic bulletin & review1(2), 202–238 (1994)
1994
-
[57]
Wolfe, J.M.: What can 1 million trials tell us about visual search? Psychological Science9(1), 33–39 (1998)
1998
-
[58]
Journal of Experimental Psychology: Human perception and performance15(3), 419 (1989)
Wolfe, J.M., Cave, K.R., Franzel, S.L.: Guided search: an alternative to the feature integration model for visual search. Journal of Experimental Psychology: Human perception and performance15(3), 419 (1989)
1989
-
[59]
Wolfe, J.M., Horowitz, T.S.: What attributes guide the deployment of visual attention and how do they do it? Nature reviews neuroscience5(6), 495–501 (2004)
2004
-
[60]
Advances in Neural Information Processing Systems37, 28828–28857 (2024)
Wu, H., Li, D., Chen, B., Li, J.: Longvideobench: A benchmark for long-context interleaved video-language understanding. Advances in Neural Information Processing Systems37, 28828–28857 (2024)
2024
-
[61]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Xiao, J., Shang, X., Yao, A., Chua, T.S.: Next-qa: Next phase of question-answering to explaining temporal actions. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 9777–9786 (2021)
2021
-
[62]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al.: Qwen3 technical report. arXiv preprint arXiv:2505.09388 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[63]
Yang, A., Yu, B., Li, C., Liu, D., Huang, F., Huang, H., Jiang, J., Tu, J., Zhang, J., Zhou, J., et al.: Qwen2. 5-1m technical report. arXiv preprint arXiv:2501.15383 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[64]
VideoLLaMA 3: Frontier Multimodal Foundation Models for Image and Video Understanding
Zhang, B., Li, K., Cheng, Z., Hu, Z., Yuan, Y ., Chen, G., Leng, S., Jiang, Y ., Zhang, H., Li, X., et al.: Videollama 3: Frontier multimodal foundation models for image and video understanding. arXiv preprint arXiv:2501.13106 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[65]
arXiv e-prints pp
Zhou, J., Shu, Y ., Zhao, B., Wu, B., Xiao, S., Yang, X., Xiong, Y ., Zhang, B., Huang, T., Liu, Z.: Mlvu: A comprehensive benchmark for multi-task long video understanding. arXiv e-prints pp. arXiv–2406 (2024)
2024
-
[66]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Zhu, J., Wang, W., Chen, Z., Liu, Z., Ye, S., Gu, L., Tian, H., Duan, Y ., Su, W., Shao, J., et al.: Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models. arXiv preprint arXiv:2504.10479 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Zohar, O., Wang, X., Dubois, Y ., Mehta, N., Xiao, T., Hansen-Estruch, P., Yu, L., Wang, X., Juefei-Xu, F., Zhang, N., et al.: Apollo: An exploration of video understanding in large multimodal models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 18891–18901 (2025) 13 A Appendix The appendix is arranged as follows -
2025
-
[68]
Limitations.The main limitation is that this work only considers four complexity attributes
Data curation for universal quantizer B Limitations. Limitations.The main limitation is that this work only considers four complexity attributes. We believe that the space of the latter is much higher dimensional. In this sense, the current version of VideoABC is simply a starting point for additional research. We have also only used VideoABC to perform a...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.