Cohort-Scale Neural Atlases of Ultrasound Video
Pith reviewed 2026-06-28 18:35 UTC · model grok-4.3
The pith
Cohort-scale neural atlases learn a shared canonical chart from ultrasound videos for efficient annotation transfer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
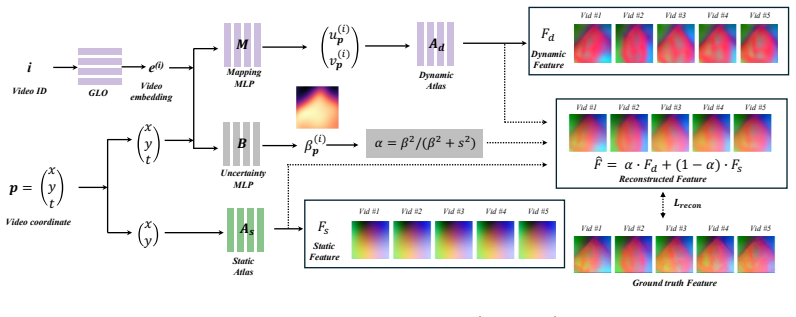
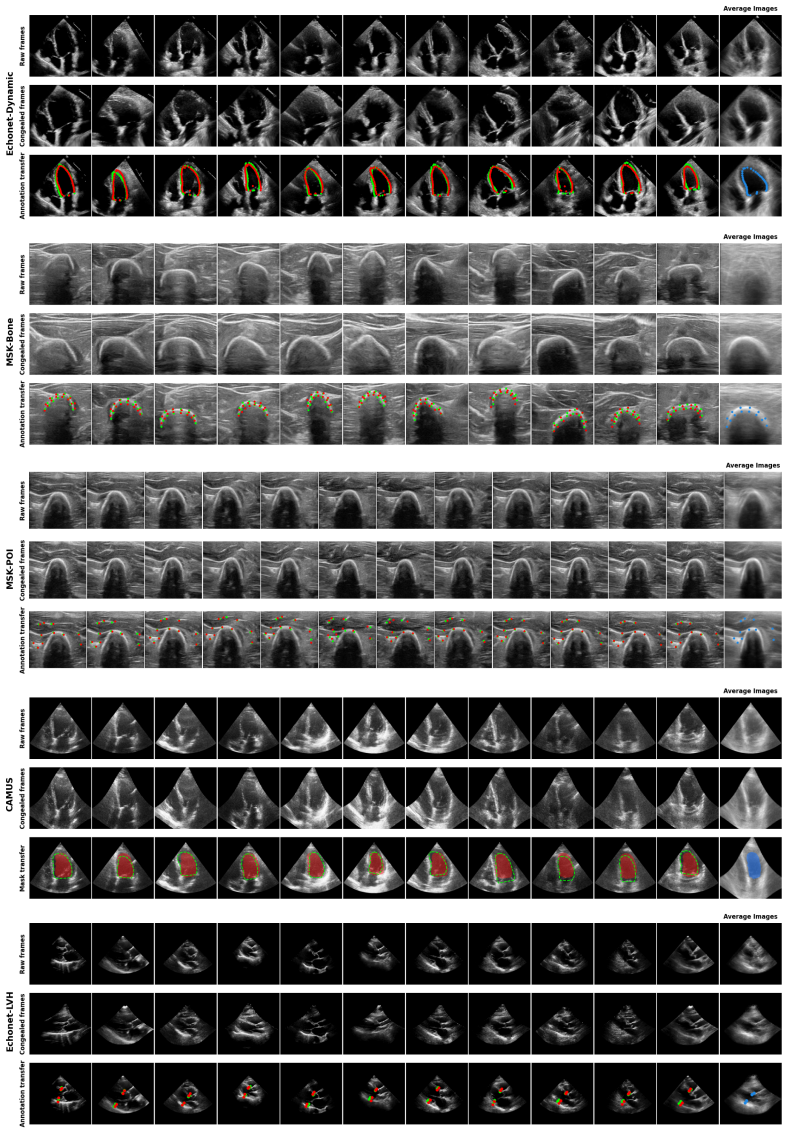
The method learns a single canonical chart with per-video generative latent optimization embeddings trained jointly over a cohort in DINOv3 feature space, yielding coherent templates that support accurate atlas-space annotation transfer on five datasets.
What carries the argument
Cohort-scale neural atlas consisting of a shared canonical chart and per-video GLO embeddings optimized jointly in DINOv3 feature space; it serves as a common coordinate system for registration and propagation of annotations.
If this is right
- Enables single- and few-shot annotation transfer competitive with dense-correspondence baselines on EchoNet-Dynamic and MSK-Bone.
- Training completes in minutes on a single consumer GPU across thousands of frames.
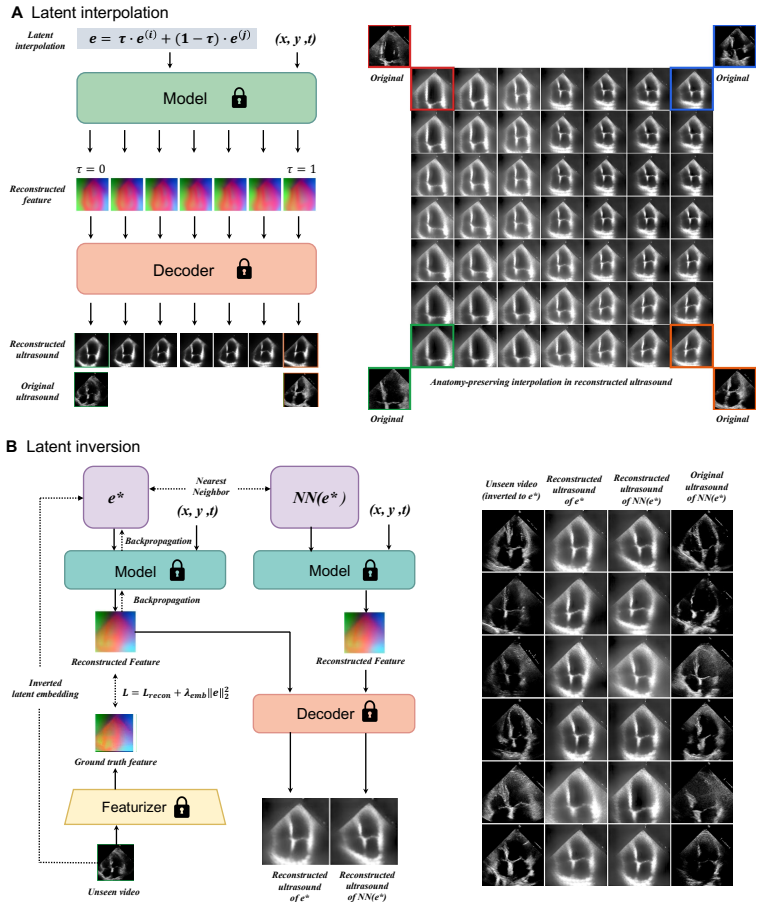
- Learned embeddings reveal structured cohort variation via linear projections and allow anatomically plausible frame interpolation.
- Test-time latent inversion can reconstruct held-out frames through the atlas.
Where Pith is reading between the lines
- The approach could be applied to other video modalities facing similar appearance variability to reduce labeling costs.
- Structured embeddings might enable new forms of cohort-level analysis or patient stratification without additional supervision.
- If the invariance holds, it suggests pre-trained vision features can bridge domain gaps in medical imaging for atlas construction.
Load-bearing premise
DINOv3 features supply enough cross-video invariance to speckle, shadowing, attenuation, and probe pose so that joint cohort optimization yields one coherent template instead of fragmented ones.
What would settle it
Observing that the optimized templates fragment into multiple disconnected modes or that annotation transfer accuracy drops below per-video baselines on a held-out cohort would falsify the claim.
Figures

read the original abstract
Ultrasound is the most widely used real-time imaging modality in clinical practice, yet per-frame video annotation remains a major bottleneck: expert labels are scarce and costly, and image appearance varies with speckle, shadowing, attenuation, and operator-dependent probe pose. This is especially limiting because clinically relevant information is often dynamic, from left-ventricular motion in echocardiography to muscle and bone kinematics in musculoskeletal imaging. Population atlases can amortize annotation cost by registering observations to a shared canonical coordinate system, but existing neural atlas methods mainly target single videos, small test-time image sets, or object-centric image collections. We introduce a cohort-scale neural atlas for ultrasound video: a single canonical chart with per-video Generative Latent Optimization embeddings, trained jointly over thousands of frames in DINOv3 feature space. Across five cardiac and musculoskeletal datasets with point landmarks and segmentation masks, our method learns coherent canonical templates and enables accurate atlas-space annotation transfer. On EchoNet-Dynamic and MSK-Bone, it supports single- and few-shot transfer with accuracy competitive with strong dense-correspondence baselines, while training in minutes on a single consumer GPU. The learned embeddings are interpretable: linear projections reveal structured cohort variation, image-decoder interpolation produces anatomically plausible intermediate frames, and test-time latent inversion reconstructs held-out frames through the atlas. These results suggest that cohort-scale neural atlases offer a practical, interpretable representation for reducing expert annotation burden in ultrasound video analysis.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a cohort-scale neural atlas for ultrasound video consisting of a single canonical chart with per-video Generative Latent Optimization (GLO) embeddings, trained jointly over thousands of frames in DINOv3 feature space. It claims this produces coherent canonical templates across five cardiac and musculoskeletal datasets, enables accurate atlas-space annotation transfer (single- and few-shot) competitive with dense-correspondence baselines on EchoNet-Dynamic and MSK-Bone, trains in minutes on a consumer GPU, and yields interpretable embeddings via linear projections, decoder interpolation, and test-time inversion.
Significance. If the central claims hold, the work provides a practical, scalable representation for amortizing expert annotation costs in dynamic ultrasound analysis by enabling transfer to a shared canonical space, with advantages in training speed and interpretability over per-video or small-set neural atlas methods.
major comments (2)
- [Abstract / Methods (DINOv3 feature space and joint training)] The central claim that joint optimization over the cohort produces a single coherent canonical chart (rather than per-video fragmentation) rests on DINOv3 features supplying sufficient cross-video invariance to speckle, shadowing, attenuation, and probe-pose variation; the abstract and method description supply no direct invariance metrics, ablation replacing DINOv3 with a domain-specific extractor, or analysis of embedding collapse, leaving the load-bearing assumption unverified.
- [Abstract / Results] The abstract states 'competitive accuracy' and 'accurate atlas-space annotation transfer' on EchoNet-Dynamic and MSK-Bone but reports no quantitative numbers, error bars, ablation details, or exclusion criteria; without these in the results, it is impossible to assess whether the data support the stated claims relative to the strong baselines.
minor comments (1)
- [Abstract] The abstract would benefit from a brief statement of the number of videos/frames per dataset and the precise metrics used for 'competitive accuracy' to allow immediate evaluation of the claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on verification of the core modeling assumptions and the need for explicit quantitative support in the abstract and results. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract / Methods (DINOv3 feature space and joint training)] The central claim that joint optimization over the cohort produces a single coherent canonical chart (rather than per-video fragmentation) rests on DINOv3 features supplying sufficient cross-video invariance to speckle, shadowing, attenuation, and probe-pose variation; the abstract and method description supply no direct invariance metrics, ablation replacing DINOv3 with a domain-specific extractor, or analysis of embedding collapse, leaving the load-bearing assumption unverified.
Authors: The empirical success of coherent canonical templates and cross-dataset annotation transfer provides indirect evidence that DINOv3 supplies the required invariance; per-video fragmentation would preclude the reported transfer performance. We agree that direct verification would strengthen the manuscript and will add (i) an ablation replacing DINOv3 with a domain-specific ultrasound feature extractor and (ii) quantitative analysis of embedding collapse / invariance in the revised version. revision: yes
-
Referee: [Abstract / Results] The abstract states 'competitive accuracy' and 'accurate atlas-space annotation transfer' on EchoNet-Dynamic and MSK-Bone but reports no quantitative numbers, error bars, ablation details, or exclusion criteria; without these in the results, it is impossible to assess whether the data support the stated claims relative to the strong baselines.
Authors: The full results section contains the requested quantitative comparisons, error bars, and ablation details on the cited datasets. To make the claims immediately verifiable from the abstract, we will revise the abstract to report the key numerical results (accuracy, standard deviations) and will ensure the results section explicitly states exclusion criteria and baseline implementation details. revision: yes
Circularity Check
No circularity: empirical method with independent validation
full rationale
The paper introduces a cohort-scale neural atlas using DINOv3 features and per-video GLO embeddings trained jointly over ultrasound video cohorts. Claims rest on empirical results across five datasets showing coherent templates and competitive annotation transfer accuracy versus dense-correspondence baselines. No derivation chain, equations, or predictions reduce by construction to fitted inputs; no self-citations are invoked as load-bearing uniqueness theorems or ansatzes; the DINOv3 invariance assumption is explicitly the weakest link but is not smuggled in via prior self-work or renamed as a derived result. The method is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- per-video GLO embeddings
Reference graph
Works this paper leans on
-
[1]
IEEE Transactions on Medical Imaging , volume =
Deep Learning for Segmentation Using an Open Large-Scale Dataset in 2D Echocardiography , author =. IEEE Transactions on Medical Imaging , volume =. 2019 , doi =
2019
-
[2]
JAMA Cardiology , volume =
High-Throughput Precision Phenotyping of Left Ventricular Hypertrophy With Cardiovascular Deep Learning , author =. JAMA Cardiology , volume =. 2022 , doi =
2022
-
[3]
Scientific Data , year =
A multimodal biomechanics dataset with synchronized kinematics and internal tissue motions during reaching , author =. Scientific Data , year =
-
[4]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages =
Emerging Properties in Self-Supervised Vision Transformers , author =. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages =
-
[5]
Advances in Neural Information Processing Systems , volume =
Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Domains , author =. Advances in Neural Information Processing Systems , volume =
-
[6]
Computer Graphics Forum , volume =
Neural Fields in Visual Computing and Beyond , author =. Computer Graphics Forum , volume =. 2022 , doi =
2022
-
[7]
Scientific Reports , volume =
Efficient elastic tissue motions indicate general motor skill , author =. Scientific Reports , volume =. 2025 , doi =
2025
-
[8]
ACM Transactions on Graphics , volume =
Layered Neural Atlases for Consistent Video Editing , author =. ACM Transactions on Graphics , volume =. 2021 , doi =
2021
-
[9]
Ouyang, Hao and Wang, Qiuyu and Xiao, Yuxi and Bai, Qingyan and Zhang, Juntao and Zheng, Kecheng and Zhou, Xiaowei and Chen, Qifeng and Shen, Yujun , booktitle =
-
[10]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
Neural Congealing: Aligning Images to a Joint Semantic Atlas , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
-
[11]
Peebles, William and Zhu, Jun-Yan and Zhang, Richard and Torralba, Antonio and Efros, Alexei and Shechtman, Eli , booktitle =
-
[12]
Gupta, Kamal and Jampani, Varun and Esteves, Carlos and Shrivastava, Abhinav and Makadia, Ameesh and Snavely, Noah and Kar, Abhishek , booktitle =
-
[13]
Zhang, Yunzhi and Li, Zizhang and Raj, Amit and Engelhardt, Andreas and Li, Yuanzhen and Hou, Tingbo and Wu, Jiajun and Jampani, Varun , booktitle =
-
[14]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume =
Data Driven Image Models through Continuous Joint Alignment , author =. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume =. 2006 , doi =
2006
-
[15]
Advances in Neural Information Processing Systems , year =
Implicit Neural Representations with Periodic Activation Functions , author =. Advances in Neural Information Processing Systems , year =
-
[16]
, booktitle =
Fu, Stephanie and Hamilton, Mark and Brandt, Laura and Feldmann, Axel and Zhang, Zhoutong and Freeman, William T. , booktitle =
-
[17]
Transactions on Machine Learning Research , year =
Oquab, Maxime and Darcet, Timoth. Transactions on Machine Learning Research , year =
-
[18]
2025 , eprint =
Sim. 2025 , eprint =
2025
-
[19]
and Barron, Jonathan T
Martin-Brualla, Ricardo and Radwan, Noha and Sajjadi, Mehdi S.M. and Barron, Jonathan T. and Dosovitskiy, Alexey and Duckworth, Daniel , booktitle =
-
[20]
Proceedings of the International Conference on Machine Learning , year =
Optimizing the Latent Space of Generative Networks , author =. Proceedings of the International Conference on Machine Learning , year =
-
[21]
and Collins, D
Evans, Alan C. and Collins, D. Louis and Mills, S.R. and Brown, E.D. and Kelly, R.L. and Peters, Terry M. , journal =
-
[22]
Co-Planar Stereotaxic Atlas of the Human Brain:
Talairach, Jean and Tournoux, Pierre , publisher =. Co-Planar Stereotaxic Atlas of the Human Brain:
-
[23]
Louis and Neelin, Peter and Peters, Terry M
Collins, D. Louis and Neelin, Peter and Peters, Terry M. and Evans, Alan C. , journal =. Automatic
-
[24]
Fischl, Bruce , journal =
-
[25]
Computer Methods and Programs in Biomedicine , volume =
A Review of Atlas-Based Segmentation for Magnetic Resonance Brain Images , author =. Computer Methods and Programs in Biomedicine , volume =
-
[26]
Medical Image Analysis , volume =
Symmetric Diffeomorphic Image Registration with Cross-Correlation: Evaluating Automated Labeling of Elderly and Neurodegenerative Brain , author =. Medical Image Analysis , volume =. 2008 , doi =
2008
-
[27]
and Guttag, John and Dalca, Adrian V
Balakrishnan, Guha and Zhao, Amy and Sabuncu, Mert R. and Guttag, John and Dalca, Adrian V. , journal =. 2019 , doi =
2019
-
[28]
and Heidenreich, Paul A
Ouyang, David and He, Bryan and Ghorbani, Amirata and Yuan, Neal and Ebinger, Joseph and Langlotz, Curt P. and Heidenreich, Paul A. and Harrington, Robert A. and Liang, David H. and Ashley, Euan A. and Zou, James Y. , journal =. Video-Based. 2020 , doi =
2020
-
[29]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
Xue, Fei and Elflein, Sven and Leal-Taix. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
-
[30]
Advances in Neural Information Processing Systems , year =
Doersch, Carl and Gupta, Ankush and Markeeva, Larisa and Recasens, Adri. Advances in Neural Information Processing Systems , year =
-
[31]
and Tancik, Matthew and Barron, Jonathan T
Mildenhall, Ben and Srinivasan, Pratul P. and Tancik, Matthew and Barron, Jonathan T. and Ramamoorthi, Ravi and Ng, Ren , booktitle =
-
[32]
Shi, Minglei and Wang, Haolin and Zhang, Borui and Zheng, Wenzhao and Zeng, Bohan and Yuan, Ziyang and Wu, Xiaoshi and Zhang, Yuanxing and Yang, Huan and Wang, Xintao and Wan, Pengfei and Gai, Kun and Zhou, Jie and Lu, Jiwen , journal =
-
[33]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
Edstedt, Johan and Sun, Qiyu and Bokman, Georg and Wadenb. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
-
[34]
Advances in Neural Information Processing Systems , year =
Emergent Correspondence from Image Diffusion , author =. Advances in Neural Information Processing Systems , year =
-
[35]
Deng, Xiaolong and Wu, Huisi and Zeng, Runhao and Qin, Jing , booktitle =
-
[36]
Brian B. Avants, Charles L. Epstein, Murray Grossman, and James C. Gee. Symmetric diffeomorphic image registration with cross-correlation: Evaluating automated labeling of elderly and neurodegenerative brain. Medical Image Analysis, 12 0 (1): 0 26--41, 2008. doi:10.1016/j.media.2007.06.004
-
[37]
Guha Balakrishnan, Amy Zhao, Mert R. Sabuncu, John Guttag, and Adrian V. Dalca. VoxelMorph : A learning framework for deformable medical image registration. IEEE Transactions on Medical Imaging, 38 0 (8): 0 1788--1800, 2019. doi:10.1109/TMI.2019.2897538
-
[38]
Optimizing the latent space of generative networks
Piotr Bojanowski, Armand Joulin, David Lopez-Paz, and Arthur Szlam. Optimizing the latent space of generative networks. In Proceedings of the International Conference on Machine Learning, 2018
2018
-
[39]
A review of atlas-based segmentation for magnetic resonance brain images
Mariano Cabezas, Arnau Oliver, Xavier Llad \'o , Jordi Freixenet, and Meritxell Bach Cuadra. A review of atlas-based segmentation for magnetic resonance brain images. Computer Methods and Programs in Biomedicine, 104 0 (3): 0 e158--e177, 2011
2011
-
[40]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv \'e J \'e gou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 9630--9640, 2021
2021
-
[41]
Louis Collins, Peter Neelin, Terry M
D. Louis Collins, Peter Neelin, Terry M. Peters, and Alan C. Evans. Automatic 3-D intersubject registration of MR volumetric data in standardized talairach space. Journal of Computer Assisted Tomography, 18 0 (2): 0 192--205, 1994
1994
-
[42]
MemSAM : Taming segment anything model for echocardiography video segmentation
Xiaolong Deng, Huisi Wu, Runhao Zeng, and Jing Qin. MemSAM : Taming segment anything model for echocardiography video segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[43]
TAP-Vid : A benchmark for tracking any point in a video
Carl Doersch, Ankush Gupta, Larisa Markeeva, Adri \`a Recasens, Lucas Smaira, Yusuf Aytar, Jo \ a o Carreira, Andrew Zisserman, and Yi Yang. TAP-Vid : A benchmark for tracking any point in a video. In Advances in Neural Information Processing Systems, 2022
2022
-
[44]
Cheng, Neal Yuan, Bryan He, Alan C
Grant Duffy, Paul P. Cheng, Neal Yuan, Bryan He, Alan C. Kwan, Matthew J. Shun-Shin, Kevin M. Alexander, Joseph Ebinger, Matthew P. Lungren, Florian Rader, David H. Liang, Ingela Schnittger, Euan A. Ashley, James Y. Zou, Jignesh Patel, Ronald Witteles, Susan Cheng, and David Ouyang. High-throughput precision phenotyping of left ventricular hypertrophy wit...
-
[45]
RoMa : Robust dense feature matching
Johan Edstedt, Qiyu Sun, Georg Bokman, M rten Wadenb \"a ck, and Michael Felsberg. RoMa : Robust dense feature matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[46]
Evans, D
Alan C. Evans, D. Louis Collins, S.R. Mills, E.D. Brown, R.L. Kelly, and Terry M. Peters. 3D statistical neuroanatomical models from 305 MRI volumes. IEEE Nuclear Science Symposium and Medical Imaging Conference, 1993
1993
-
[47]
FreeSurfer
Bruce Fischl. FreeSurfer . NeuroImage, 62 0 (2): 0 774--781, 2012
2012
-
[48]
Stephanie Fu, Mark Hamilton, Laura Brandt, Axel Feldmann, Zhoutong Zhang, and William T. Freeman. FeatUp : A model-agnostic framework for features at any resolution. In International Conference on Learning Representations, 2024
2024
-
[49]
ASIC : Aligning sparse in-the-wild image collections
Kamal Gupta, Varun Jampani, Carlos Esteves, Abhinav Shrivastava, Ameesh Makadia, Noah Snavely, and Abhishek Kar. ASIC : Aligning sparse in-the-wild image collections. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023
2023
-
[50]
Layered neural atlases for consistent video editing
Yoni Kasten, Dolev Ofri, Oliver Wang, and Tali Dekel. Layered neural atlases for consistent video editing. ACM Transactions on Graphics, 40 0 (6), 2021. doi:10.1145/3478513.3480546
-
[51]
Erik G. Learned-Miller. Data driven image models through continuous joint alignment. IEEE Transactions on Pattern Analysis and Machine Intelligence, 28 0 (2): 0 236--250, 2006. doi:10.1109/TPAMI.2006.34
-
[52]
IEEE Transactions on Medical Imaging38(9), 2198–2210 (2019)
Sarah Leclerc, Erik Smistad, Jo \ a o Pedrosa, Andreas stvik, Frederic Cervenansky, Florian Espinosa, Torvald Espeland, Erik Andreas Rye Berg, Pierre-Marc Jodoin, Thomas Grenier, Carole Lartizien, Jan D'hooge, Lasse L vstakken, and Olivier Bernard. Deep learning for segmentation using an open large-scale dataset in 2d echocardiography. IEEE Transactions o...
-
[53]
Sajjadi, Jonathan T
Ricardo Martin-Brualla, Noha Radwan, Mehdi S.M. Sajjadi, Jonathan T. Barron, Alexey Dosovitskiy, and Daniel Duckworth. NeRF in the wild: Neural radiance fields for unconstrained photo collections. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021
2021
-
[54]
Srinivasan, Matthew Tancik, Jonathan T
Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. NeRF : Representing scenes as neural radiance fields for view synthesis. In Proceedings of the European Conference on Computer Vision, 2020
2020
-
[55]
Praneeth Namburi, Roger Pallar \`e s-L \'o pez, Duarte Folgado, Uriel Magana-Salgado, Jessica Rosendorf, Enya Ryu, Armin Kappacher, Hugo Gamboa, Brian W. Anthony, and Luca Daniel. Efficient elastic tissue motions indicate general motor skill. Scientific Reports, 15 0 (1): 0 36532, 2025. doi:10.1038/s41598-025-17092-0. URL https://www.nature.com/articles/s...
-
[56]
Neural congealing: Aligning images to a joint semantic atlas
Dolev Ofri-Amar, Michal Geyer, Yoni Kasten, and Tali Dekel. Neural congealing: Aligning images to a joint semantic atlas. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023
2023
-
[57]
Maxime Oquab, Timoth \'e e Darcet, Th \'e o Moutakanni, Huy V. Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mahmoud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herv \'e J \'e gou, Julien M...
2024
-
[58]
David Ouyang, Bryan He, Amirata Ghorbani, Neal Yuan, Joseph Ebinger, Curt P. Langlotz, Paul A. Heidenreich, Robert A. Harrington, David H. Liang, Euan A. Ashley, and James Y. Zou. Video-based AI for beat-to-beat assessment of cardiac function. Nature, 580: 0 252--256, 2020. doi:10.1038/s41586-020-2145-8
-
[59]
CoDeF : Content deformation fields for temporally consistent video processing
Hao Ouyang, Qiuyu Wang, Yuxi Xiao, Qingyan Bai, Juntao Zhang, Kecheng Zheng, Xiaowei Zhou, Qifeng Chen, and Yujun Shen. CoDeF : Content deformation fields for temporally consistent video processing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[60]
Roger Pallar \`e s-L \'o pez, Duarte Folgado, Uriel Magana-Salgado, Jessica Rosendorf, Enya Ryu, Micha Feigin-Almon, Hugo Gamboa, Luca Daniel, Brian W. Anthony, and Praneeth Namburi. A multimodal biomechanics dataset with synchronized kinematics and internal tissue motions during reaching. Scientific Data, 2026. doi:10.1038/s41597-026-07019-3
-
[61]
GAN -supervised dense visual alignment
William Peebles, Jun-Yan Zhu, Richard Zhang, Antonio Torralba, Alexei Efros, and Eli Shechtman. GAN -supervised dense visual alignment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022
2022
-
[62]
Minglei Shi, Haolin Wang, Borui Zhang, Wenzhao Zheng, Bohan Zeng, Ziyang Yuan, Xiaoshi Wu, Yuanxing Zhang, Huan Yang, Xintao Wang, Pengfei Wan, Kun Gai, Jie Zhou, and Jiwen Lu. SVG-T2I : Scaling up text-to-image latent diffusion model without variational autoencoder. arXiv preprint arXiv:2512.11749, 2025
-
[63]
Oriane Sim \'e oni, Huy V. Vo, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Micha \"e l Ramamonjisoa, Francisco Massa, Daniel Haziza, Luca Wehrstedt, Jianyuan Wang, Timoth \'e e Darcet, Th \'e o Moutakanni, Leonel Sentana, Claire Roberts, Andrea Vedaldi, Jamie Tolan, John Brandt, Camille ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[64]
Martel, Alexander W
Vincent Sitzmann, Julien N.P. Martel, Alexander W. Bergman, David B. Lindell, and Gordon Wetzstein. Implicit neural representations with periodic activation functions. In Advances in Neural Information Processing Systems, 2020
2020
-
[65]
Co-Planar Stereotaxic Atlas of the Human Brain: 3-Dimensional Proportional System: An Approach to Cerebral Imaging
Jean Talairach and Pierre Tournoux. Co-Planar Stereotaxic Atlas of the Human Brain: 3-Dimensional Proportional System: An Approach to Cerebral Imaging . Thieme, 1988
1988
-
[66]
Srinivasan, Ben Mildenhall, Sara Fridovich-Keil, Nithin Raghavan, Utkarsh Singhal, Ravi Ramamoorthi, Jonathan T
Matthew Tancik, Pratul P. Srinivasan, Ben Mildenhall, Sara Fridovich-Keil, Nithin Raghavan, Utkarsh Singhal, Ravi Ramamoorthi, Jonathan T. Barron, and Ren Ng. Fourier features let networks learn high frequency functions in low dimensional domains. In Advances in Neural Information Processing Systems, volume 33, pages 7537--7547, 2020
2020
-
[67]
Emergent correspondence from image diffusion
Luming Tang, Menglin Jia, Qianqian Wang, Cheng Perng Phoo, and Bharath Hariharan. Emergent correspondence from image diffusion. In Advances in Neural Information Processing Systems, 2023
2023
-
[68]
Neural fields in visual computing and beyond
Yiheng Xie, Towaki Takikawa, Shunsuke Saito, Or Litany, Shiqin Yan, Numair Khan, Federico Tombari, James Tompkin, Vincent Sitzmann, and Srinath Sridhar. Neural fields in visual computing and beyond. Computer Graphics Forum, 41 0 (2): 0 641--676, 2022. doi:10.1111/cgf.14505
-
[69]
MATCHA : Towards matching anything
Fei Xue, Sven Elflein, Laura Leal-Taix \'e , and Qunjie Zhou. MATCHA : Towards matching anything. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[70]
3D congealing: 3D -aware image alignment in the wild
Yunzhi Zhang, Zizhang Li, Amit Raj, Andreas Engelhardt, Yuanzhen Li, Tingbo Hou, Jiajun Wu, and Varun Jampani. 3D congealing: 3D -aware image alignment in the wild. In Proceedings of the European Conference on Computer Vision, 2024
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.