Towards Interactive Video World Modeling: Frontiers, Challenges, Benchmarks, and Future Trends
Pith reviewed 2026-06-28 17:27 UTC · model grok-4.3
The pith
User actions condition video and 3D generation to enable controllable interactive world models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Recent literature shows that embedding user actions directly into world state transitions creates interactive world modeling through an action-conditioned video or 3D generation paradigm. This approach increases controllability over how worlds evolve and lets users freely traverse, manipulate, navigate, and personalize those evolutions. The review maps trends in applications and modalities, details the three core challenges, surveys benchmarks in four domains, and suggests paths toward next-generation systems.
What carries the argument
Action-conditioned video or 3D generation paradigm that incorporates user actions into world state transitions to produce interactivity.
If this is right
- Controllability over world evolutions increases in domains such as game engines, embodied AI, and autonomous driving.
- Users can traverse, manipulate, and personalize simulated environments more freely.
- Standardized benchmarks in four fields enable clearer comparison of progress on controllability and responsiveness.
- Solving long-horizon memory and real-time action following will support more practical interactive applications.
Where Pith is reading between the lines
- Improved memory mechanisms could allow simulations to support extended user sessions with consistent state across many actions.
- The paradigm may connect to embodied systems by letting planners test action sequences in controllable virtual worlds before physical execution.
- Natural language interfaces could combine with action conditioning to let users issue high-level instructions that shape scene evolution.
Load-bearing premise
The selected literature on application scenarios, technical challenges, and benchmarks represents the current state of interactive world modeling without major omissions or biases in coverage.
What would settle it
Publication of a new survey or set of papers that reveals substantial omitted literature, different dominant challenges, or contradictory benchmark results would show the review's coverage is incomplete.
Figures



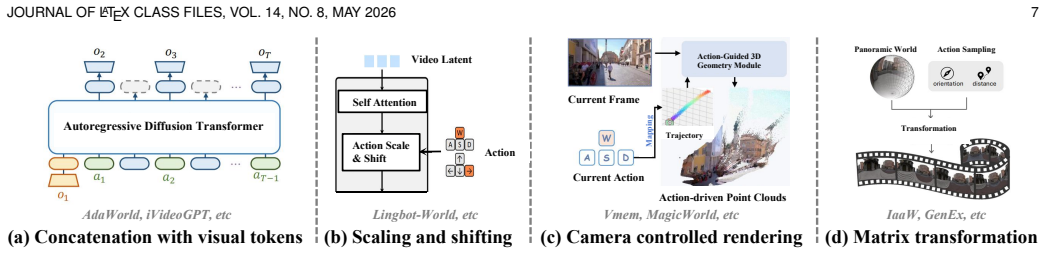
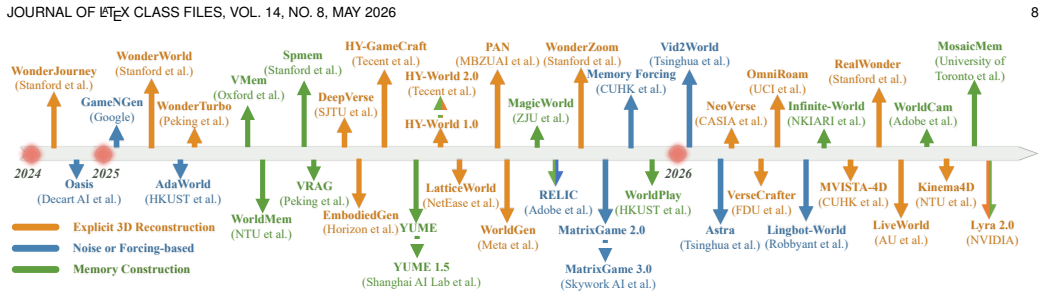


read the original abstract
With rapid development of large language models and diffusion-based content generation, world modeling has attracted increasing research attention, benefiting various downstream domains such as game engines, embodied AI, autonomous driving, etc. Through explicitly incorporating user actions into world state transition, recent literature empowers world modeling with interactivity in an action-conditioned video or 3D generation paradigm, further enhancing controllability over world evolutions and facilitating users to freely traverse, manipulate, navigate, and personalize the state evolution. In this paper, we aim to systematically review recent research trends, technical developments, evaluation benchmarks, and also propose future potential directions in interactive world modeling. Specifically, we first summarize recent efforts and trends in terms of application scenarios, world state evolution, and scene modality. Afterwards, we delve into three crucial technical challenges, including action-conditioned controllability, long-horizon interactions and memory, and action-following responsiveness for real-time interactivity. Furthermore, we also thoroughly compare existing benchmarks and metrics in four specific application fields: open-world exploration, game engine, autonomous driving, and robotics. Finally, we discuss several promising future directions in achieving next-generation interactive world modeling. The corresponding repository is publicly available at: https://github.com/liujiuming123/Awesome-Interactive-World-Model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper is a survey reviewing recent trends in interactive world modeling. It summarizes application scenarios, world state evolution, and scene modalities; examines three technical challenges (action-conditioned controllability, long-horizon interactions and memory, and action-following responsiveness); compares benchmarks and metrics across open-world exploration, game engines, autonomous driving, and robotics; and outlines future directions. The central thesis is that incorporating user actions into state transitions via action-conditioned video/3D generation enables greater interactivity and controllability.
Significance. If the literature selection proves representative, the survey would organize an emerging intersection of diffusion models, video generation, and interactive systems, providing a useful reference for researchers in embodied AI, autonomous driving, and game engines. The public GitHub repository strengthens its role as a living resource.
major comments (2)
- [Introduction / § on literature trends] The survey's claim to 'systematically review' the field (abstract and §1) is load-bearing on representativeness of the cited literature. No explicit literature search methodology, inclusion/exclusion criteria, or database sources are provided in the introduction or methods overview, making it impossible to assess potential omissions or selection bias in the coverage of scenarios, challenges, and the four benchmark domains.
- [Benchmarks comparison section] § on benchmarks: The 'thorough' comparison across four fields is presented without a summary table enumerating how many papers per field were reviewed or explicit criteria for benchmark inclusion. This weakens the ability to verify completeness of the cross-field analysis.
minor comments (2)
- [Abstract] Abstract: 'also propose future potential directions' is redundant; 'future directions' already implies potential.
- [Application scenarios / state evolution section] The three challenges are clearly listed, but the transition between 'world state evolution' and 'scene modality' subsections could benefit from an explicit diagram or table showing how modalities map to interactivity.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and commit to revisions that improve transparency without altering the core contributions of the survey.
read point-by-point responses
-
Referee: [Introduction / § on literature trends] The survey's claim to 'systematically review' the field (abstract and §1) is load-bearing on representativeness of the cited literature. No explicit literature search methodology, inclusion/exclusion criteria, or database sources are provided in the introduction or methods overview, making it impossible to assess potential omissions or selection bias in the coverage of scenarios, challenges, and the four benchmark domains.
Authors: We acknowledge the validity of this observation. The manuscript does not include an explicit methods section detailing the literature search. While the survey is a narrative review drawing on prominent recent works in the rapidly evolving intersection of diffusion models and interactive systems, we agree that greater transparency is warranted. In the revised version, we will insert a dedicated paragraph in Section 1 that describes the literature collection approach: primary sources (arXiv, Google Scholar, CVPR/ICCV/ECCV proceedings 2022–2024), search terms (combinations of “action-conditioned video generation,” “interactive world model,” “action-controllable 3D generation”), and inclusion criteria (papers that explicitly model action-conditioned state transitions in video or 3D). This addition will allow readers to evaluate coverage and potential bias. revision: yes
-
Referee: [Benchmarks comparison section] § on benchmarks: The 'thorough' comparison across four fields is presented without a summary table enumerating how many papers per field were reviewed or explicit criteria for benchmark inclusion. This weakens the ability to verify completeness of the cross-field analysis.
Authors: We agree that an explicit accounting would strengthen the section. The current text compares representative benchmarks but does not tabulate paper counts or selection criteria. In the revision we will add a compact table (new Table X) in the benchmarks section that reports, for each of the four domains, (i) the number of papers and benchmarks reviewed, (ii) the inclusion criteria (relevance to action-conditioned generation, public availability of datasets and metrics, coverage of long-horizon or real-time evaluation), and (iii) any notable omissions with brief justification. This change directly addresses the concern about verifiability. revision: yes
Circularity Check
No circularity: survey paper with purely descriptive content
full rationale
This is a survey paper that reviews external literature on interactive world modeling, application scenarios, challenges, and benchmarks. It contains no mathematical derivations, equations, fitted parameters, predictions, or ansatzes that could reduce to self-referential inputs. All claims are summaries of cited works; the representativeness of coverage is an external validity concern, not a circularity issue under the defined patterns. No self-citation load-bearing steps or self-definitional reductions exist.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
K. J. W. Craik,The nature of explanation. CUP Archive, 1967, vol. 445
1967
-
[2]
D. Ha and J. Schmidhuber, “World models,”arXiv preprint arXiv:1803.10122, vol. 2, no. 3, 2018
Pith/arXiv arXiv 2018
-
[3]
A path towards autonomous machine intelligence version 0.9. 2, 2022-06-27,
Y. LeCun, “A path towards autonomous machine intelligence version 0.9. 2, 2022-06-27,”Open Review, vol. 62, no. 1, pp. 1–62, 2022
2022
-
[4]
ivideogpt: Interactive videogpts are scalable world models,
J. Wu, S. Yin, N. Feng, X. He, D. Li, J. Hao, and M. Long, “ivideogpt: Interactive videogpts are scalable world models,” NeurIPS, vol. 37, pp. 68 082–68 119, 2024
2024
-
[6]
Drivedreamer: Towards real-world-drive world models for au- tonomous driving,
X. Wang, Z. Zhu, G. Huang, X. Chen, J. Zhu, and J. Lu, “Drivedreamer: Towards real-world-drive world models for au- tonomous driving,” inECCV, 2024, pp. 55–72
2024
-
[7]
A compre- hensive survey on world models for embodied ai,
X. Li, X. He, L. Zhang, M. Wu, X. Li, and Y. Liu, “A compre- hensive survey on world models for embodied ai,”arXiv preprint arXiv:2510.16732, 2025
arXiv 2025
-
[8]
Unrealzoo: Enriching photo-realistic virtual worlds for embod- ied ai,
F. Zhong, K. Wu, C. Wang, H. Chen, H. Ci, Z. Li, and Y. Wang, “Unrealzoo: Enriching photo-realistic virtual worlds for embod- ied ai,” inICCV, 2025, pp. 5769–5779
2025
-
[9]
Navigation world models,
A. Bar, G. Zhou, D. Tran, T. Darrell, and Y. LeCun, “Navigation world models,” inCVPR, 2025, pp. 15 791–15 801
2025
-
[10]
Viva: A video-generative value model for robot reinforcement learning,
J. Lv, H. Li, J. Li, Y. Nie, F. Kong, Y. Wang, X. Wang, Z. Zhu, C. Ni, Q. Denget al., “Viva: A video-generative value model for robot reinforcement learning,”arXiv preprint arXiv:2604.08168, 2026
Pith/arXiv arXiv 2026
-
[11]
Matrix-game: Interactive world foundation model,
Y. Zhang, C. Peng, B. Wang, P . Wang, Q. Zhu, F. Kang, B. Jiang, Z. Gao, E. Li, Y. Liuet al., “Matrix-game: Interactive world foundation model,”arXiv preprint arXiv:2506.18701, 2025
arXiv 2025
-
[12]
Matrix-game 2.0: An open-source real-time and streaming interactive world model,
X. He, C. Peng, Z. Liu, B. Wang, Y. Zhang, Q. Cui, F. Kang, B. Jiang, M. An, Y. Renet al., “Matrix-game 2.0: An open-source real-time and streaming interactive world model,”arXiv preprint arXiv:2508.13009, 2025
Pith/arXiv arXiv 2025
-
[13]
Gamefac- tory: Creating new games with generative interactive videos,
J. Yu, Y. Qin, X. Wang, P . Wan, D. Zhang, and X. Liu, “Gamefac- tory: Creating new games with generative interactive videos,” in ICCV, 2025, pp. 11 590–11 599
2025
-
[14]
Building machines that learn and think like people,
B. M. Lake, T. D. Ullman, J. B. Tenenbaum, and S. J. Gershman, “Building machines that learn and think like people,”Behavioral and brain sciences, vol. 40, p. e253, 2017
2017
-
[15]
Genie: Generative interactive environments,
J. Bruce, M. D. Dennis, A. Edwards, J. Parker-Holder, Y. Shi, E. Hughes, M. Lai, A. Mavalankar, R. Steigerwald, C. Apps, Y. Aytar, S. M. E. Bechtle, F. Behbahani, S. C. Chan, N. Heess, L. Gonzalez, S. Osindero, S. Ozair, S. Reed, J. Zhang, K. Zolna, J. Clune, N. de Freitas, S. Singh, and T. Rockt ¨aschel, “Genie: Generative interactive environments,” inICML, 2024
2024
-
[16]
Genie 2: A large-scale foundation world model,
“Genie 2: A large-scale foundation world model,” 2024. [Online]. Available: https://deepmind.google/discover/blog/ genie-2-a-large-scale-foundation-world-model/
2024
-
[17]
Genie 3: A new frontier for world models,
“Genie 3: A new frontier for world models,” 2025. [Online]. Available: https://deepmind.google/models/genie/
2025
-
[18]
Worldgen: From text to traversable and interactive 3d worlds,
D. Wang, H. Jung, T. Monnier, K. Sohn, C. Zou, X. Xiang, Y.- Y. Yeh, D. Liu, Z. Huang, T. Nguyen-Phuocet al., “Worldgen: From text to traversable and interactive 3d worlds,”arXiv preprint arXiv:2511.16825, 2025
arXiv 2025
-
[19]
Lyra 2.0: Explorable generative 3d worlds,
T. Shen, S. Bahmani, K. He, S. G. Srinivasan, T. Cao, J. Ren, R. Li, Z. Wang, N. Sharp, Z. Gojcic, S. Fidler, J. Huang, H. Ling, J. Gao, and X. Ren, “Lyra 2.0: Explorable generative 3d worlds,”arXiv preprint arXiv:2604.13036, 2026
Pith/arXiv arXiv 2026
-
[20]
Pixelverse-r1
“Pixelverse-r1.” [Online]. Available: https://pixverse.ai/en/ blog/pixverse-r1-next-generation-real-time-world-model
-
[21]
Happy oyster
“Happy oyster.” [Online]. Available: https://www.happyoyster. cn/
-
[22]
Available: https://runwayml.com/ research/introducing-runway-gwm-1
“Gwm-1.” [Online]. Available: https://runwayml.com/ research/introducing-runway-gwm-1
-
[23]
Wonderjourney: Going from anywhere to everywhere,
H.-X. Yu, H. Duan, J. Hur, K. Sargent, M. Rubinstein, W. T. Free- man, F. Cole, D. Sun, N. Snavely, J. Wuet al., “Wonderjourney: Going from anywhere to everywhere,” inCVPR, 2024, pp. 6658– 6667
2024
-
[24]
Wonderworld: Interactive 3d scene generation from a single image,
H.-X. Yu, H. Duan, C. Herrmann, W. T. Freeman, and J. Wu, “Wonderworld: Interactive 3d scene generation from a single image,” inCVPR, 2025, pp. 5916–5926
2025
-
[25]
Wonderzoom: Multi-scale 3d world generation,
J. Cao, H.-X. Yu, and J. Wu, “Wonderzoom: Multi-scale 3d world generation,”arXiv preprint arXiv:2512.09164, 2025
arXiv 2025
-
[26]
Advancing open-source world models,
R. Team, Z. Gao, Q. Wang, Y. Zeng, J. Zhu, K. L. Cheng, Y. Li, H. Wang, Y. Xu, S. Maet al., “Advancing open-source world models,”arXiv preprint arXiv:2601.20540, 2026
Pith/arXiv arXiv 2026
-
[27]
Matrix-game 3.0 real-time and streaming interactive world model with long-horizon memory,
S. AI, “Matrix-game 3.0 real-time and streaming interactive world model with long-horizon memory,”arXiv preprint arXiv:, 2026
2026
-
[28]
Yume: An interactive world generation model,
X. Mao, S. Lin, Z. Li, C. Li, W. Peng, T. He, J. Pang, M. Chi, Y. Qiao, and K. Zhang, “Yume: An interactive world generation model,”arXiv preprint arXiv:2507.17744, 2025
arXiv 2025
-
[29]
Yume-1.5: A text-controlled interactive world generation model,
X. Mao, Z. Li, C. Li, X. Xu, K. Ying, T. He, J. Pang, Y. Qiao, and K. Zhang, “Yume-1.5: A text-controlled interactive world generation model,”arXiv preprint arXiv:2512.22096, 2025
arXiv 2025
-
[30]
Worldplay: Towards long-term geometric consistency for real-time interactive world modeling,
W. Sun, H. Zhang, H. Wang, J. Wu, Z. Wang, Z. Wang, Y. Wang, J. Zhang, T. Wang, and C. Guo, “Worldplay: Towards long-term geometric consistency for real-time interactive world modeling,” arXiv preprint arXiv:2512.14614, 2025
Pith/arXiv arXiv 2025
-
[31]
Vmem: Consistent inter- active video scene generation with surfel-indexed view memory,
R. Li, P . Torr, A. Vedaldi, and T. Jakab, “Vmem: Consistent inter- active video scene generation with surfel-indexed view memory,” inICCV, 2025, pp. 25 690–25 699
2025
-
[32]
Solaris: Building a multiplayer video world model in minecraft,
G. Savva, O. Michel, D. Lu, S. Waiwitlikhit, T. Meehan, D. Mishra, S. Poddar, J. Lu, and S. Xie, “Solaris: Building a multiplayer video world model in minecraft,”arXiv preprint arXiv:2602.22208, 2026
arXiv 2026
-
[33]
Realwon- der: Real-time physical action-conditioned video generation,
W. Liu, Z. Chen, Z. Li, Y. Wang, H.-X. Yu, and J. Wu, “Realwon- der: Real-time physical action-conditioned video generation,” arXiv preprint arXiv:2603.05449, 2026
arXiv 2026
-
[34]
Available: https:// danwilliamsphilosophy.com/2018/09/07/ chapter-3-kenneth-craiks-hypothesis-on-the-nature-of-thought/
[Online]. Available: https:// danwilliamsphilosophy.com/2018/09/07/ chapter-3-kenneth-craiks-hypothesis-on-the-nature-of-thought/
2018
-
[35]
L. Wong, G. Grand, A. K. Lew, N. D. Goodman, V . K. Mans- inghka, J. Andreas, and J. B. Tenenbaum, “From word models to world models: Translating from natural language to the prob- abilistic language of thought,”arXiv preprint arXiv:2306.12672, 2023
arXiv 2023
-
[36]
Neoverse: Enhancing 4d world model with in-the-wild monocular videos,
Y. Yang, L. Fan, Z. Shi, J. Peng, F. Wang, and Z. Zhang, “Neoverse: Enhancing 4d world model with in-the-wild monocular videos,” arXiv preprint arXiv:2601.00393, 2026
arXiv 2026
-
[37]
Wan: Open and advanced large-scale video generative models,
T. Wan, “Wan: Open and advanced large-scale video generative models,”arXiv preprint arXiv:2503.20314, 2025
Pith/arXiv arXiv 2025
-
[38]
Available: https://marble.worldlabs.ai/
“Marble.” [Online]. Available: https://marble.worldlabs.ai/
-
[39]
Physgen3d: Crafting a miniature interactive world from a single image,
B. Chen, H. Jiang, S. Liu, S. Gupta, Y. Li, H. Zhao, and S. Wang, “Physgen3d: Crafting a miniature interactive world from a single image,” inCVPR, 2025, pp. 6178–6189
2025
-
[40]
Vdaworld: World modelling via vlm-directed abstraction and simulation,
F. O’Mahony, R. Cipolla, and A. Tewari, “Vdaworld: World modelling via vlm-directed abstraction and simulation,”arXiv preprint arXiv:2512.11061, 2025
Pith/arXiv arXiv 2025
-
[41]
Make-a-video: Text-to-video generation without text-video data,
U. Singer, A. Polyak, T. Hayes, X. Yin, J. An, S. Zhang, Q. Hu, H. Yang, O. Ashual, O. Gafniet al., “Make-a-video: Text-to-video generation without text-video data,”arXiv preprint arXiv:2209.14792, 2022
Pith/arXiv arXiv 2022
-
[42]
Learning interactive real-world simulators,
S. Yang, Y. Du, S. K. S. Ghasemipour, J. Tompson, L. P . Kaelbling, D. Schuurmans, and P . Abbeel, “Learning interactive real-world simulators,” inICLR, 2024
2024
-
[43]
Adding conditional control to text-to-image diffusion models,
L. Zhang, A. Rao, and M. Agrawala, “Adding conditional control to text-to-image diffusion models,” inICCV, 2023, pp. 3836–3847
2023
-
[44]
Magicworld: Interactive geometry-driven video world exploration,
G. Li, S. Zheng, S. Xu, J. Chen, B. Li, X. Hu, L. Zhao, and P .- T. Jiang, “Magicworld: Interactive geometry-driven video world exploration,”arXiv preprint arXiv:2511.18886, 2025
arXiv 2025
-
[45]
Worldcompass: Reinforce- ment learning for long-horizon world models,
Z. Wang, T. Wang, H. Zhang, X. Zuo, J. Wu, H. Wang, W. Sun, Z. Wang, C. Cao, H. Zhaoet al., “Worldcompass: Reinforce- ment learning for long-horizon world models,”arXiv preprint arXiv:2602.09022, 2026
arXiv 2026
-
[46]
Genie envisioner: A unified world foundation platform for robotic manipulation,
Y. Liao, P . Zhou, S. Huang, D. Yang, S. Chen, Y. Jiang, Y. Hu, J. Cai, S. Liu, J. Luoet al., “Genie envisioner: A unified world foundation platform for robotic manipulation,”arXiv preprint arXiv:2508.05635, 2025
Pith/arXiv arXiv 2025
-
[47]
H. Wang, H. Ouyang, Q. Wang, Y. Yu, Y. Meng, W. Wang, K. L. Cheng, S. Ma, Q. Bai, Y. Liet al., “The world is your canvas: JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, MAY 2026 17 Painting promptable events with reference images, trajectories, and text,”arXiv preprint arXiv:2512.16924, 2025
arXiv 2026
-
[48]
Exploring the limits of transfer learning with a unified text-to-text transformer,
C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, and P . J. Liu, “Exploring the limits of transfer learning with a unified text-to-text transformer,”JMLR, vol. 21, no. 140, pp. 1–67, 2020
2020
-
[49]
Perpetualwonder: Long- horizon action-conditioned 4d scene generation,
J. Zhan, Z. Li, H.-X. Yu, and J. Wu, “Perpetualwonder: Long- horizon action-conditioned 4d scene generation,”arXiv preprint arXiv:2602.04876, 2026
Pith/arXiv arXiv 2026
-
[50]
Interactive world simulator for robot policy training and evaluation,
Y. Wang, R. Syed, F. Wu, M. Zhang, A. Onol, J. Barreiros, H. Nayyeri, T. Dear, H. Zhang, and Y. Li, “Interactive world simulator for robot policy training and evaluation,”arXiv preprint arXiv:2603.08546, 2026
arXiv 2026
-
[51]
Vid2world: Crafting video diffusion models to interactive world models,
S. Huang, J. Wu, Q. Zhou, S. Miao, and M. Long, “Vid2world: Crafting video diffusion models to interactive world models,” in ICLR, 2026
2026
-
[52]
Auto-encoding variational bayes,
D. P . Kingma and M. Welling, “Auto-encoding variational bayes,” arXiv preprint arXiv:1312.6114, 2013
Pith/arXiv arXiv 2013
-
[53]
Generative adver- sarial nets,
I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde- Farley, S. Ozair, A. Courville, and Y. Bengio, “Generative adver- sarial nets,”NeurIPS, vol. 27, 2014
2014
-
[54]
Learn- ing to simulate dynamic environments with gamegan,
S. W. Kim, Y. Zhou, J. Philion, A. Torralba, and S. Fidler, “Learn- ing to simulate dynamic environments with gamegan,” inCVPR, 2020, pp. 1231–1240
2020
-
[55]
Deep unsupervised learning using nonequilibrium thermody- namics,
J. Sohl-Dickstein, E. Weiss, N. Maheswaranathan, and S. Ganguli, “Deep unsupervised learning using nonequilibrium thermody- namics,” inICML, 2015, pp. 2256–2265
2015
-
[56]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P . Abbeel, “Denoising diffusion probabilistic models,”NeurIPS, vol. 33, pp. 6840–6851, 2020
2020
-
[57]
Gamegen-x: Interactive open-world game video generation,
H. Che, X. He, Q. Liu, C. Jin, and H. Chen, “Gamegen-x: Interactive open-world game video generation,”arXiv preprint arXiv:2411.00769, 2024
arXiv 2024
-
[58]
Worldmem: Long-term consistent world simulation with memory,
Z. Xiao, L. Yushi, Y. Zhou, W. Ouyang, S. Yang, Y. Zeng, and X. Pan, “Worldmem: Long-term consistent world simulation with memory,” inNeurIPS, 2025
2025
-
[59]
Fantasyworld: Geometry-consistent world modeling via unified video and 3d prediction,
Y. Dai, F. Jiang, C. Wang, M. Xu, and Y. Qi, “Fantasyworld: Geometry-consistent world modeling via unified video and 3d prediction,” inICLR, 2026
2026
-
[60]
Live: Long-horizon interactive video world modeling,
J. Huang, Z. Ye, X. Hu, T. He, G. Zhang, S. Shi, J. Bian, and L. Jiang, “Live: Long-horizon interactive video world modeling,” arXiv preprint arXiv:2602.03747, 2026
arXiv 2026
-
[61]
Olaf-world: Orienting latent actions for video world modeling,
Y. Jiang, Y. Gu, I. W. Tsang, and M. Z. Shou, “Olaf-world: Orienting latent actions for video world modeling,”arXiv preprint arXiv:2602.10104, 2026
Pith/arXiv arXiv 2026
-
[62]
J. Nam, Y. Hong, C.-H. P . Huang, F. Liu, J. Lee, J. Kim, S. Jin, Y. Lee, J. Jung, S. Choiet al., “Worldcam: Interactive autoregres- sive 3d gaming worlds with camera pose as a unifying geometric representation,”arXiv preprint arXiv:2603.16871, 2026
arXiv 2026
-
[63]
Scalable diffusion models with transform- ers,
W. Peebles and S. Xie, “Scalable diffusion models with transform- ers,” inICCV, 2023, pp. 4195–4205
2023
-
[64]
Mineworld: a real-time and open-source interactive world model on minecraft,
J. Guo, Y. Ye, T. He, H. Wu, Y. Jiang, T. Pearce, and J. Bian, “Mineworld: a real-time and open-source interactive world model on minecraft,”arXiv preprint arXiv:2504.08388, 2025
arXiv 2025
-
[65]
Video2game: Real- time interactive realistic and browser-compatible environment from a single video,
H. Xia, Z.-H. Lin, W.-C. Ma, and S. Wang, “Video2game: Real- time interactive realistic and browser-compatible environment from a single video,” inCVPR, 2024, pp. 4578–4588
2024
-
[66]
Diffusion for world modeling: Visual details matter in atari,
E. Alonso, A. Jelley, V . Micheli, A. Kanervisto, A. Storkey, T. Pearce, and F. Fleuret, “Diffusion for world modeling: Visual details matter in atari,”NeurIPS, vol. 37, pp. 58 757–58 791, 2024
2024
-
[67]
Oasis: A universe in a transformer,
J. Q. Decart, Q. McIntyre, S. Campbell, X. Chen, and R. Wachen, “Oasis: A universe in a transformer,” 2024
2024
-
[68]
Diffusion models are real-time game engines,
D. Valevski, Y. Leviathan, M. Arar, and S. Fruchter, “Diffusion models are real-time game engines,” inICLR, 2025
2025
-
[69]
Adaworld: Learning adaptable world models with latent actions,
S. Gao, S. Zhou, Y. Du, J. Zhang, and C. Gan, “Adaworld: Learning adaptable world models with latent actions,” inICML, 2025
2025
-
[70]
Wonderturbo: Generating interactive 3d world in 0.72 seconds,
C. Ni, X. Wang, Z. Zhu, W. Wang, H. Li, G. Zhao, J. Li, W. Qin, G. Huang, and W. Mei, “Wonderturbo: Generating interactive 3d world in 0.72 seconds,” inICCV, 2025, pp. 27 423–27 434
2025
-
[71]
Long-context state-space video world models,
R. Po, Y. Nitzan, R. Zhang, B. Chen, T. Dao, E. Shechtman, G. Wetzstein, and X. Huang, “Long-context state-space video world models,” inICCV, 2025, pp. 8733–8744
2025
-
[72]
Aether: Geometric-aware unified world modeling,
H. Zhu, Y. Wang, J. Zhou, W. Chang, Y. Zhou, Z. Li, J. Chen, C. Shen, J. Pang, and T. He, “Aether: Geometric-aware unified world modeling,” inICCV, 2025, pp. 8535–8546
2025
-
[73]
Video world models with long-term spatial memory,
T. Wu, S. Yang, R. Po, Y. Xu, Z. Liu, D. Lin, and G. Wet- zstein, “Video world models with long-term spatial memory,” inNeurIPS, 2025
2025
-
[74]
Image as a world: Gener- ating interactive world from single image via panoramic video generation,
D. Gui, X. Guo, W. Zhou, and Y. Lu, “Image as a world: Gener- ating interactive world from single image via panoramic video generation,” inNeurIPS, 2025
2025
-
[75]
The matrix: Infinite-horizon world generation with real-time moving control,
R. Feng, H. Zhang, Z. Shu, Z. Yang, L. Tang, Z. Wang, A. Zheng, J. Xiao, Z. Liu, R. Chu, Y. Huang, Y. Liu, and H. Zhang, “The matrix: Infinite-horizon world generation with real-time moving control,” inNeurIPS, 2025
2025
-
[76]
Deepverse: 4d autoregressive video generation as a world model,
J. Chen, H. Zhu, X. He, Y. Wang, J. Zhou, W. Chang, Y. Zhou, Z. Li, Z. Fu, J. Panget al., “Deepverse: 4d autoregressive video generation as a world model,”arXiv preprint arXiv:2506.01103, 2025
arXiv 2025
-
[77]
Embodiedgen: Towards a generative 3d world engine for embodied intelligence,
X. Wang, L. Liu, Y. Cao, R. Wu, W. Qin, D. Wang, W. Sui, and Z. Su, “Embodiedgen: Towards a generative 3d world engine for embodied intelligence,”arXiv preprint arXiv:2506.10600, 2025
arXiv 2025
-
[78]
Hunyuan-gamecraft: High-dynamic interactive game video generation with hybrid history condition,
J. Li, J. Tang, Z. Xu, L. Wu, Y. Zhou, S. Shao, T. Yu, Z. Cao, and Q. Lu, “Hunyuan-gamecraft: High-dynamic interactive game video generation with hybrid history condition,” 2025
2025
-
[79]
Hunyuanworld 1.0: Generating immersive, explorable, and interactive 3d worlds from words or pixels,
H. Team, Z. Wang, Y. Liu, J. Wu, Z. Gu, H. Wang, X. Zuo, T. Huang, W. Li, S. Zhanget al., “Hunyuanworld 1.0: Generating immersive, explorable, and interactive 3d worlds from words or pixels,”arXiv preprint arXiv:2507.21809, 2025
arXiv 2025
-
[80]
Matrix-3d: Omnidirectional explorable 3d world generation,
Z. Yang, W. Ge, Y. Li, J. Chen, H. Li, M. An, F. Kang, H. Xue, B. Xu, Y. Yinet al., “Matrix-3d: Omnidirectional explorable 3d world generation,”arXiv preprint arXiv:2508.08086, 2025
arXiv 2025
-
[81]
Training agents inside of scalable world models,
D. Hafner, W. Yan, and T. Lillicrap, “Training agents inside of scalable world models,”arXiv preprint arXiv:2509.24527, 2025
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.