AlbedoEdit: Unified Instance-Level Video Editing with Albedo Guidance
Pith reviewed 2026-06-28 15:53 UTC · model grok-4.3
The pith
AlbedoEdit conditions video generation on a user-edited first-frame albedo map to perform object insertion, removal, and texture editing while learning to add consistent lighting effects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AlbedoEdit is a unified generative video editing framework that jointly supports object insertion, object removal, and texture editing by conditioning on a user-edited first-frame albedo map and implicitly learning to harmonize edited contents and simulate complex real-world visual effects triggered by editing operations, including specular highlights, soft shadows, and mirror reflections.
What carries the argument
The albedo map, an intrinsic image invariant to lighting with no specularity, shadowing or inter-reflections, acts as the conditioning signal that specifies the desired appearance edit for the entire video sequence.
If this is right
- A single fine-tuned model handles object insertion, object removal, and texture editing without task-specific architectures.
- Edited videos automatically include realistic specular highlights, soft shadows, and mirror reflections triggered by the albedo change.
- The approach outperforms prior unified and task-specific video editing methods on both qualitative and quantitative metrics.
- Training on synthetic paired data transfers to real videos by learning implicit harmonization of edited content with the scene.
Where Pith is reading between the lines
- The first-frame-only conditioning could support interactive tools where users paint albedo changes on one frame and receive a full consistent video.
- The method might extend to other intrinsic properties such as surface normals to control additional effects like bump mapping in video.
- If the synthetic-to-real gap proves small, similar albedo conditioning could apply to longer or higher-resolution sequences without retraining from scratch.
- The implicit learning of lighting effects suggests the framework could be adapted for video relighting tasks where only albedo is modified.
Load-bearing premise
A user-provided edited albedo map for only the first frame plus training on synthetic paired data is sufficient for the model to correctly infer and render all subsequent-frame lighting interactions without visible artifacts.
What would settle it
Run the model on a source video containing a mirror surface, edit the first-frame albedo to introduce a new reflective object, and check whether the output video shows the expected mirror reflection and consistent shadows across later frames.
Figures

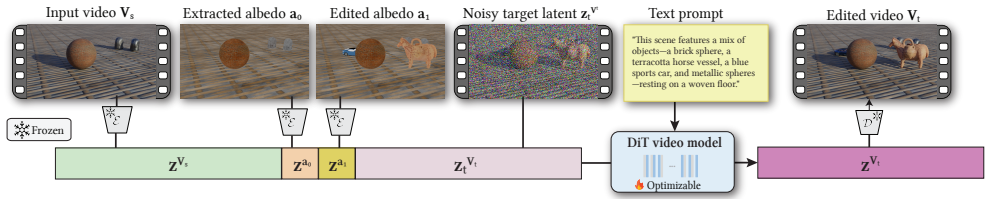



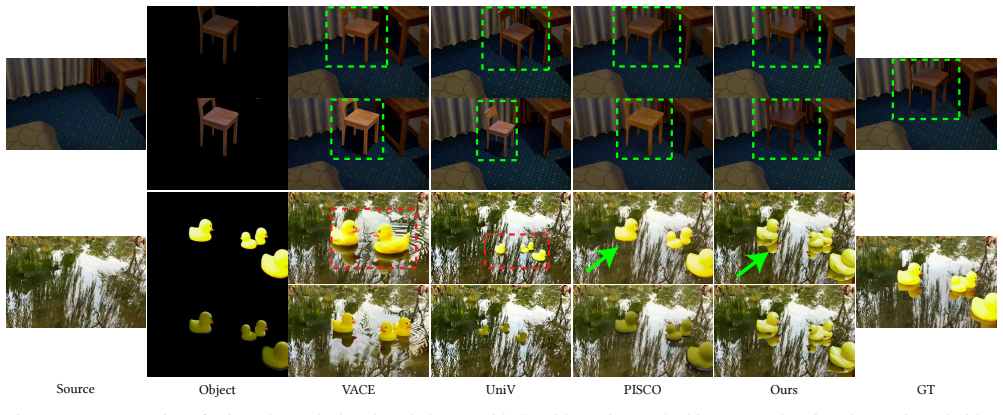

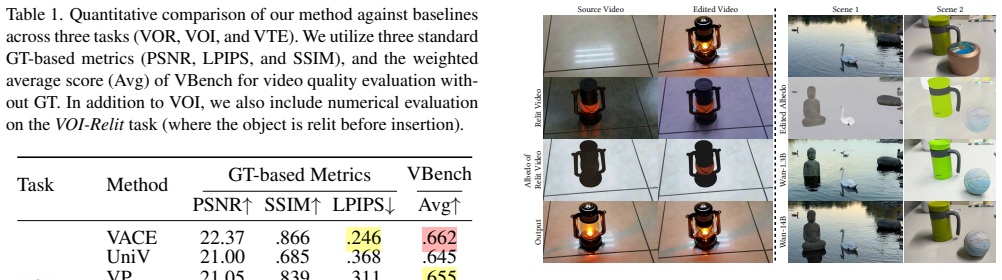

read the original abstract
Video generative models have achieved remarkable progress in synthesizing photorealistic video sequences. However, enabling broader and more creative downstream applications requires fine-grained instance-level video editing, including object insertion, object removal, and texture editing, which has emerged as a prominent yet challenging problem. Existing approaches either propose unified generative frameworks with only coarse semantic control, or design task-specific frameworks for individual editing tasks, limiting their flexibility and applicability across diverse real-world scenarios. To address these limitations, we propose AlbedoEdit, a unified generative video editing framework that jointly supports object insertion, object removal, and texture editing. Our key insight is that the intrinsic albedo map, which is invariant to lighting and contains no specularity, shadowing and inter-reflection effects, provides an effective and user-friendly mechanism for specifying fine-grained appearance edits. Built upon video foundation models, AlbedoEdit is fine-tuned to translate source RGB videos into edited RGB videos, conditioned on a user-edited first-frame albedo. Trained on a new paired synthetic dataset covering all three editing tasks, AlbedoEdit implicitly learns to harmonize edited contents and simulate complex real-world visual effects triggered by editing operations, including specular highlights, soft shadows, and mirror reflections. AlbedoEdit demonstrates superior performance over state-of-the-art video editing approaches, both qualitatively and quantitatively. Project webpage is https://vcai.mpi-inf.mpg.de/projects/AlbedoEdit/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes AlbedoEdit, a unified generative framework for instance-level video editing that supports object insertion, removal, and texture editing. It conditions a fine-tuned video foundation model on a user-provided edited albedo map of only the first frame, using a new synthetic paired training dataset to implicitly learn harmonization of edited content with the source video and simulation of lighting effects including specular highlights, soft shadows, and mirror reflections.
Significance. If the central empirical claim holds, the work offers a flexible, albedo-based control mechanism that unifies three editing tasks previously handled by separate or coarser methods, with potential impact on creative video applications. The albedo-invariance insight is a clear strength for decoupling appearance specification from lighting.
major comments (2)
- [Abstract and §3 (Method)] Abstract and presumed §3 (Method): The load-bearing claim that a single first-frame edited albedo plus synthetic-pair fine-tuning suffices to infer temporally consistent lighting interactions (specular highlights, soft shadows, mirror reflections) across all frames rests on an unverified assumption that the synthetic training distribution matches real-video lighting statistics; no explicit test of out-of-distribution real videos with complex inter-reflections is described, which directly risks falsifying the 'unified generative framework' claim.
- [Experiments section] Presumed Experiments section: The abstract asserts superior qualitative and quantitative performance, yet without reported metrics (e.g., specific PSNR/SSIM/FID values, temporal consistency scores, or ablation on albedo vs. RGB conditioning), it is impossible to verify whether gains are attributable to albedo guidance or to the underlying foundation model; this undermines assessment of the harmonization claim.
minor comments (2)
- [Abstract] Abstract: The phrase 'implicitly learns to harmonize' is repeated without a concrete definition or loss term; a short clarification of the training objective would improve readability.
- [Abstract] Project webpage link: Ensure the supplementary material includes side-by-side comparisons on real videos with strong reflections to support the generalization claim.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Abstract and §3 (Method)] Abstract and presumed §3 (Method): The load-bearing claim that a single first-frame edited albedo plus synthetic-pair fine-tuning suffices to infer temporally consistent lighting interactions (specular highlights, soft shadows, mirror reflections) across all frames rests on an unverified assumption that the synthetic training distribution matches real-video lighting statistics; no explicit test of out-of-distribution real videos with complex inter-reflections is described, which directly risks falsifying the 'unified generative framework' claim.
Authors: We acknowledge that the core generalization from synthetic pairs to real-video lighting statistics is an assumption that merits stronger support. The video foundation model is pre-trained on large-scale real footage, and our qualitative results on real test videos show plausible handling of specular highlights, soft shadows, and reflections. Nevertheless, we agree that dedicated examples of out-of-distribution real videos with complex inter-reflections are not explicitly presented. In the revision we will add a new subsection (or appendix) with such examples together with a discussion of the synthetic dataset’s coverage and remaining limitations. revision: yes
-
Referee: [Experiments section] Presumed Experiments section: The abstract asserts superior qualitative and quantitative performance, yet without reported metrics (e.g., specific PSNR/SSIM/FID values, temporal consistency scores, or ablation on albedo vs. RGB conditioning), it is impossible to verify whether gains are attributable to albedo guidance or to the underlying foundation model; this undermines assessment of the harmonization claim.
Authors: We apologize that the specific numerical values and the requested ablation were not presented with sufficient clarity. The experiments section does contain quantitative comparisons, but we will revise the manuscript to explicitly tabulate PSNR, SSIM, FID, and temporal-consistency scores, and to add an ablation that isolates albedo conditioning from RGB conditioning. These additions will make the contribution of the albedo guidance transparent. revision: yes
Circularity Check
No circularity; empirical ML training on synthetic pairs
full rationale
The paper presents a fine-tuned video generative model that takes a user-edited first-frame albedo as conditioning input and is trained end-to-end on a new synthetic paired dataset to produce edited RGB video. No equations, parameter-fitting steps, or derivation chain are described that would reduce any output quantity to the input by construction. The central claim rests on empirical performance after training rather than on self-definition, fitted-input predictions, or load-bearing self-citations of uniqueness theorems. The approach is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Albedo maps are invariant to lighting and contain no specularity, shadowing or inter-reflection effects.
- domain assumption Fine-tuning a video foundation model on synthetic paired data will generalize to produce realistic lighting effects on real videos.
Reference graph
Works this paper leans on
-
[1]
Abdal, O
R. Abdal, O. Patashnik, I. Skorokhodov, W. Menapace, A. Siarohin, S. Tulyakov, D. Cohen-Or, and K. Aberman. Dynamic concepts personalization from single videos. In Proceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers, pages 1–9, 2025
2025
-
[2]
Adobe photoshop.https://www.adobe
Adobe Inc. Adobe photoshop.https://www.adobe. com/products/photoshop.html, 2026
2026
- [3]
-
[4]
J. Bai, S. Bai, Y . Chu, Z. Cui, K. Dang, X. Deng, Y . Fan, W. Ge, Y . Han, F. Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[5]
Batifol, A
S. Batifol, A. Blattmann, F. Boesel, S. Consul, C. Diagne, T. Dockhorn, J. English, Z. English, P. Esser, S. Kulal, et al. Flux. 1 kontext: Flow matching for in-context image genera- tion and editing in latent space.arXiv e-prints, pages arXiv– 2506, 2025
2025
-
[6]
Y . Bian, Z. Zhang, X. Ju, M. Cao, L. Xie, Y . Shan, and Q. Xu. Videopainter: Any-length video inpainting and editing with plug-and-play context control. InProceedings of the Special Interest Group on Computer Graphics and Interactive Tech- niques Conference Conference Papers, pages 1–12, 2025
2025
-
[7]
Deitke, D
M. Deitke, D. Schwenk, J. Salvador, L. Weihs, O. Michel, E. VanderBilt, L. Schmidt, K. Ehsani, A. Kembhavi, and A. Farhadi. Objaverse: A universe of annotated 3d objects. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 13142–13153, 2023
2023
-
[8]
Dhariwal and A
P. Dhariwal and A. Nichol. Diffusion models beat gans on image synthesis.Advances in neural information processing systems, 34:8780–8794, 2021
2021
- [9]
- [10]
- [11]
-
[12]
Garibi, S
D. Garibi, S. Yadin, R. Paiss, O. Tov, S. Zada, A. Ephrat, T. Michaeli, I. Mosseri, and T. Dekel. Tokenverse: Versa- tile multi-concept personalization in token modulation space. ACM Transactions On Graphics (TOG), 44(4):1–11, 2025
2025
-
[13]
Z. Gu, R. Yan, J. Lu, P. Li, Z. Dou, C. Si, Z. Dong, Q. Liu, C. Lin, Z. Liu, et al. Diffusion as shader: 3d-aware video dif- fusion for versatile video generation control. InProceedings of the Special Interest Group on Computer Graphics and In- teractive Techniques Conference Conference Papers, pages 1–12, 2025
2025
-
[14]
LTX-2: Efficient Joint Audio-Visual Foundation Model
Y . HaCohen, B. Brazowski, N. Chiprut, Y . Bitterman, A. Kvochko, A. Berkowitz, D. Shalem, D. Lifschitz, D. Moshe, E. Porat, et al. Ltx-2: Efficient joint audio-visual foundation model.arXiv preprint arXiv:2601.03233, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
H. He, Y . Xu, Y . Guo, G. Wetzstein, B. Dai, H. Li, and C. Yang. Cameractrl: Enabling camera control for text-to- video generation.arXiv preprint arXiv:2404.02101, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [16]
-
[17]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion proba- bilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
2020
-
[18]
W. Hong, M. Ding, W. Zheng, X. Liu, and J. Tang. Cogvideo: Large-scale pretraining for text-to-video gener- ation via transformers.arXiv preprint arXiv:2205.15868, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[19]
Huang, Y
Z. Huang, Y . He, J. Yu, F. Zhang, C. Si, Y . Jiang, Y . Zhang, T. Wu, Q. Jin, N. Chanpaisit, Y . Wang, X. Chen, L. Wang, D. Lin, Y . Qiao, and Z. Liu. VBench: Comprehensive bench- mark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[20]
Jiang, Z
Z. Jiang, Z. Han, C. Mao, J. Zhang, Y . Pan, and Y . Liu. Vace: All-in-one video creation and editing. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 17191–17202, 2025
2025
-
[21]
H. Jin, H. Jang, J. Kim, J. Hyung, K. Kim, D. Kim, H. Choi, H. Kim, and J. Choo. Insertanywhere: Bridging 4d scene geometry and diffusion models for realistic video object in- sertion.arXiv preprint arXiv:2512.17504, 2025
work page internal anchor Pith review arXiv 2025
-
[22]
D. P. Kingma and M. Welling. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[23]
W. Kong, Q. Tian, Z. Zhang, R. Min, Z. Dai, J. Zhou, J. Xiong, X. Li, B. Wu, J. Zhang, et al. Hunyuanvideo: A sys- tematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [24]
- [25]
- [26]
-
[27]
Liang, Z
R. Liang, Z. Gojcic, H. Ling, J. Munkberg, J. Hasselgren, C.- H. Lin, J. Gao, A. Keller, N. Vijaykumar, S. Fidler, et al. Dif- fusion renderer: Neural inverse and forward rendering with video diffusion models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 26069– 26080, 2025
2025
-
[28]
C. Lin, H. Liu, Q. Lin, Z. Bright, S. Tang, Y . He, M. Liu, L. Zhu, and C. Le. Objaverse++: Curated 3D Object Dataset with Quality Annotations. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Work- shops, pages 6813–6822, 2025
2025
-
[29]
Flow Matching for Generative Modeling
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[30]
Decoupled Weight Decay Regularization
I. Loshchilov and F. Hutter. Decoupled weight decay regu- larization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[31]
L. Lyu, V . Deschaintre, Y . Hold-Geoffroy, M. Ha ˇsan, J. S. Yoon, T. Leimk¨uhler, C. Theobalt, and I. Georgiev. Intrin- sicedit: Precise generative image manipulation in intrinsic space.ACM Transactions on Graphics (TOG), 44(4):1–13, 2025
2025
-
[32]
X. Ma, V . Deschaintre, M. Haˇsan, F. Luan, K. Zhou, H. Wu, and Y . Hu. Materialpicker: Multi-modal dit-based mate- rial generation.ACM Transactions on Graphics, 44(4):1–12, July 2025. ISSN 1557-7368. doi: 10.1145/3731199. URL http://dx.doi.org/10.1145/3731199
- [33]
-
[34]
S. Motamed, W. Harvey, B. Klein, L. Van Gool, Z. Yuan, and T.-Y . Cheng. V oid: Video object and interaction deletion. arXiv preprint arXiv:2604.02296, 2026
-
[35]
Peebles and S
W. Peebles and S. Xie. Scalable diffusion models with trans- formers. InProceedings of the IEEE/CVF international con- ference on computer vision, pages 4195–4205, 2023
2023
-
[36]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learn- ing, pages 8748–8763. PmLR, 2021
2021
-
[37]
Rombach, A
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Om- mer. High-resolution image synthesis with latent diffu- sion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684– 10695, 2022
2022
- [38]
- [39]
-
[40]
Sohl-Dickstein, E
J. Sohl-Dickstein, E. Weiss, N. Maheswaranathan, and S. Ganguli. Deep unsupervised learning using nonequilib- rium thermodynamics. InInternational conference on ma- chine learning, pages 2256–2265. pmlr, 2015
2015
-
[41]
Van Den Oord, O
A. Van Den Oord, O. Vinyals, et al. Neural discrete represen- tation learning.Advances in neural information processing systems, 30, 2017
2017
-
[42]
T. Wan, A. Wang, B. Ai, B. Wen, C. Mao, C.-W. Xie, D. Chen, F. Yu, H. Zhao, J. Yang, et al. Wan: Open and ad- vanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [43]
-
[44]
Z. Wang, A. C. Bovik, H. R. Sheikh, and E. P. Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE transactions on image processing, 13(4): 600–612, 2004
2004
- [45]
-
[46]
Video models are zero-shot learners and reasoners
T. Wiedemer, Y . Li, P. Vicol, S. S. Gu, N. Matarese, K. Swersky, B. Kim, P. Jaini, and R. Geirhos. Video mod- els are zero-shot learners and reasoners.arXiv preprint arXiv:2509.20328, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Z. Yang, J. Teng, W. Zheng, M. Ding, S. Huang, J. Xu, Y . Yang, W. Hong, X. Zhang, G. Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer. arXiv preprint arXiv:2408.06072, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [48]
-
[49]
M. Yu, W. Hu, J. Xing, and Y . Shan. Trajectorycrafter: Redi- recting camera trajectory for monocular videos via diffusion models. InProceedings of the IEEE/CVF international con- ference on computer vision, pages 100–111, 2025
2025
-
[50]
X. Yu, T. Wang, S. Y . Kim, P. Guerrero, X. Chen, Q. Liu, Z. Lin, and X. Qi. Objectmover: Generative object move- ment with video prior. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 17682–17691, 2025
2025
-
[51]
Z. Zeng, V . Deschaintre, I. Georgiev, Y . Hold-Geoffroy, Y . Hu, F. Luan, L.-Q. Yan, and M. Ha ˇsan. Rgb¡-¿x: Image decomposition and synthesis using material- and lighting-aware diffusion models. InACM SIGGRAPH 2024 Conference Papers, SIGGRAPH ’24, New York, NY , USA, 2024. Association for Computing Machinery. ISBN 9798400705250. doi: 10.1145/3641519.36...
-
[52]
Zhang, A
L. Zhang, A. Rao, and M. Agrawala. Adding conditional control to text-to-image diffusion models. InProceedings of the IEEE/CVF international conference on computer vision, pages 3836–3847, 2023
2023
-
[53]
Zhang, P
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang. The unreasonable effectiveness of deep features as a percep- tual metric. InProceedings of the IEEE conference on com- puter vision and pattern recognition, pages 586–595, 2018
2018
-
[54]
Y . Zhang, K. T´othov´a, Z. Wang, K. Yin, H. Turki, R. de Lu- tio, Y .-Y . Chang, O. Litany, S. Fidler, and Z. Gojcic. Dif- fusionharmonizer: Bridging neural reconstruction and pho- torealistic simulation with online diffusion enhancer.arXiv preprint arXiv:2602.24096, 2026
- [55]
-
[56]
S. Zhou, C. Li, K. C. Chan, and C. C. Loy. Propainter: Im- proving propagation and transformer for video inpainting. In Proceedings of the IEEE/CVF international conference on computer vision, pages 10477–10486, 2023
2023
-
[57]
B. Zi, S. Zhao, X. Qi, J. Wang, Y . Shi, Q. Chen, B. Liang, R. Xiao, K.-F. Wong, and L. Zhang. Cococo: Improving text- guided video inpainting for better consistency, controllability and compatibility. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 11067–11076, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.