Self-Healing Agentic Orchestrators for Reliable Tool-Augmented Large Language Model Systems
Pith reviewed 2026-06-28 16:59 UTC · model grok-4.3
The pith
A self-healing orchestrator maps failure signals to budgeted recoveries and reaches 98.8% task success in tool-augmented LLM systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
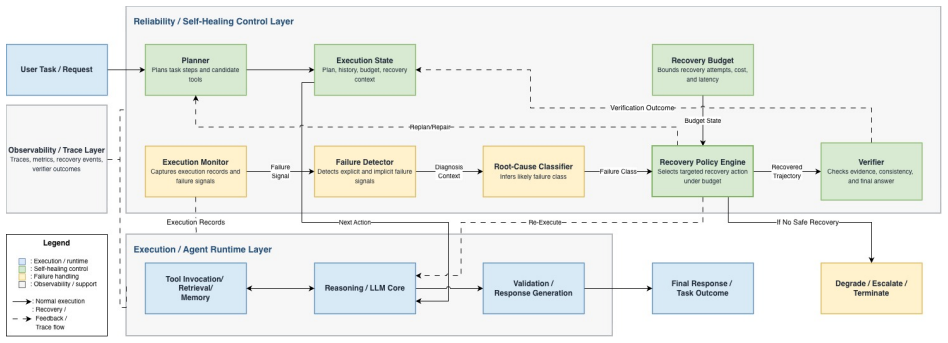
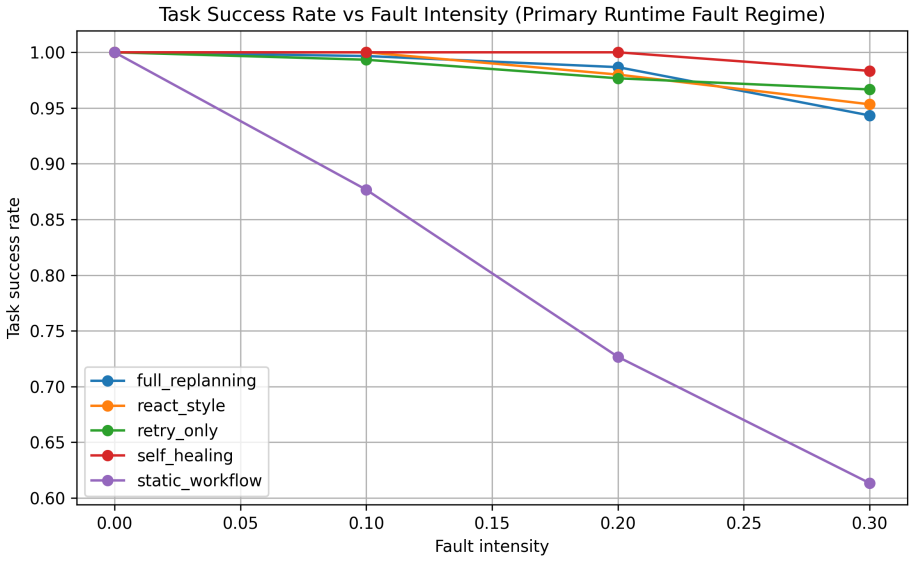
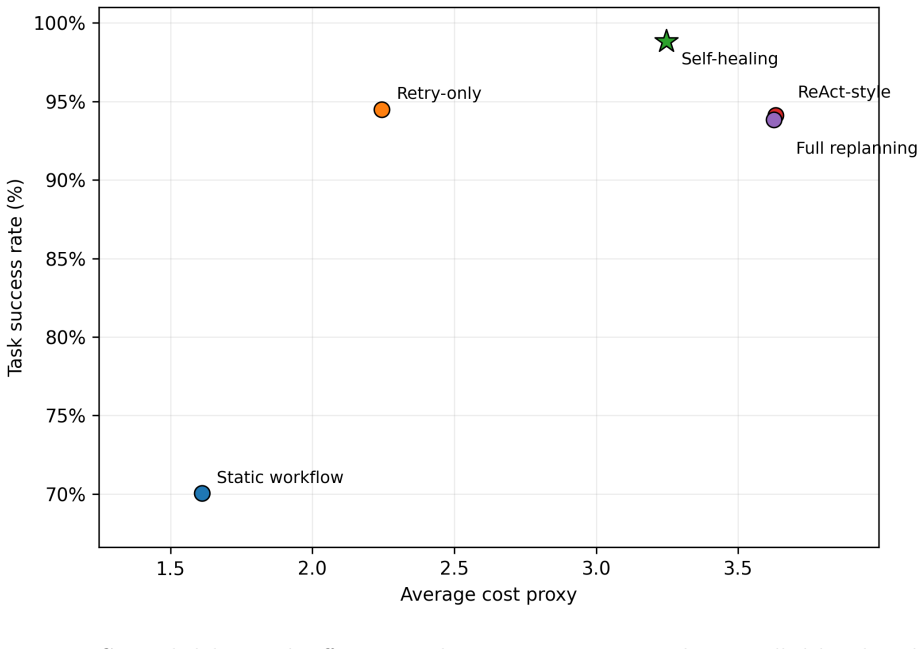
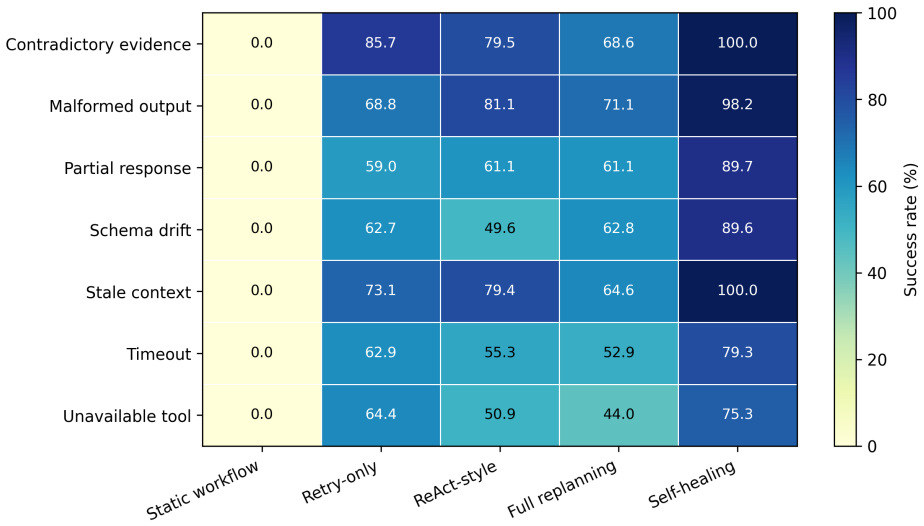
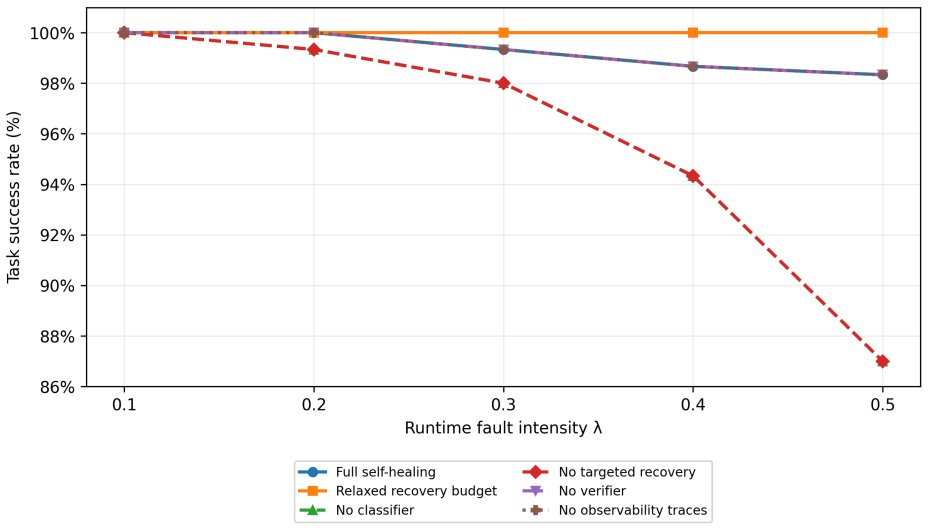
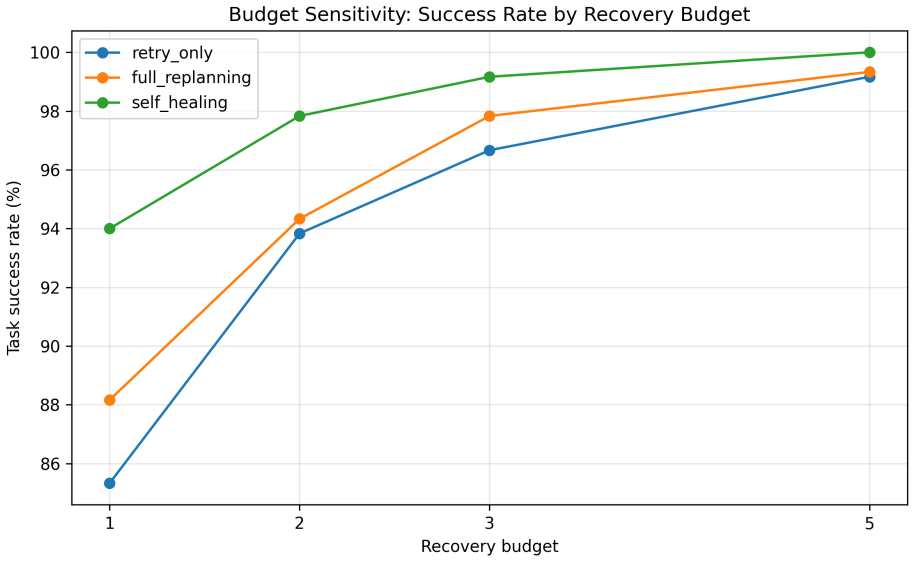
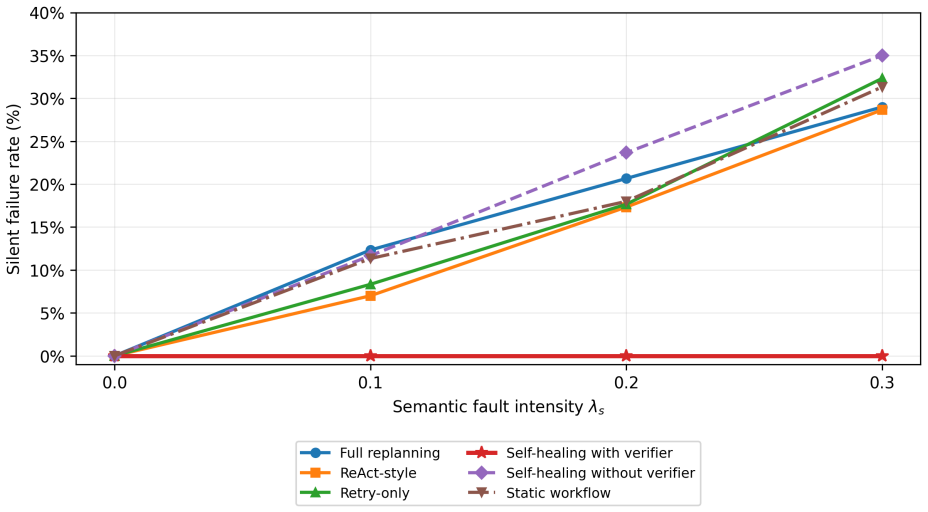
The paper claims that a self-healing agentic orchestrator improves reliability by mapping observable failure signals to inferred failure classes, selecting targeted recovery actions under explicit budgets, verifying recovered trajectories, and recording observability traces. On the 100-task benchmark this produces 98.8% task success, outperforms retry-only and full replanning at every tested budget, and drives silent failures to zero when verification is used. The same recovery mechanism continues to function when a live tool-calling model performs tool selection, argument generation, and answer synthesis over local fault-injected tools.
What carries the argument
The self-healing agentic orchestrator that maps observable failure signals to failure classes and selects targeted recovery actions under explicit budgets with verification.
If this is right
- Self-healing outperforms retry-only and full replanning at every tested recovery budget.
- With a single recovery attempt self-healing reaches 94.0% success versus 85.3% and 88.2% for the baselines.
- Verifier-guided self-healing reduces silent failures to 0.0% under the controlled semantic setting.
- The recovery mechanism operates when a live tool-calling model handles tool selection and answer synthesis.
Where Pith is reading between the lines
- Explicit recovery budgets may help control compute costs when the orchestrator runs in production.
- Recorded observability traces could support iterative refinement of the failure-class mapping over time.
- The signal-to-class mapping might transfer to orchestration problems outside tool use, such as multi-agent coordination.
Load-bearing premise
Observable failure signals can be accurately mapped to distinct failure classes so that targeted recovery actions selected under budgets produce verifiable successful trajectories.
What would settle it
A run of the 100-task fault-injection benchmark in which self-healing produces no gain in task success or fails to reduce silent failures below the levels of retry-only and replanning baselines would falsify the central claim.
Figures
read the original abstract
Tool-augmented large language model (LLM) agents rely on orchestration layers that coordinate planning, retrieval, tool invocation, validation, memory, and recovery. In these systems, failures arise not only from model errors, but also from orchestration-level issues such as tool timeouts, malformed arguments, stale context, contradictory evidence, retry loops, and unverified intermediate outputs. This paper presents a self-healing agentic orchestrator that treats reliability as a bounded runtime control problem. The orchestrator maps observable failure signals to inferred failure classes, selects targeted recovery actions under explicit budgets, verifies recovered trajectories, and records observability traces. We evaluate the approach on a 100-task controlled fault-injection benchmark against static workflow, retry-only, ReAct-style, and full-replanning baselines. Self-healing achieves 98.8\% task success, compared with 94.5\% for retry-only and 93.8\% for full replanning. A matched recovery-budget sweep shows that self-healing outperforms retry-only and full replanning at every tested budget, with the largest gap under a single recovery attempt: 94.0\% versus 85.3\% and 88.2\%, respectively. Under a controlled semantic silent-failure setting, verifier-guided self-healing reduces silent failures to 0.0\%, while non-verifying baselines return wrong-but-plausible outputs more often. A compact model-in-the-loop validation shows that the same recovery mechanism can operate when a live tool-calling model performs tool selection, argument generation, and answer synthesis over local fault-injected tools. These results provide controlled evidence that failure-aware, budgeted, and verification-guided orchestration improves reliability and diagnosability in tool-augmented LLM systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a self-healing agentic orchestrator for tool-augmented LLM systems that treats reliability as a bounded runtime control problem. Observable failure signals are mapped to inferred failure classes, targeted recovery actions are selected under explicit budgets, recovered trajectories are verified, and observability traces are recorded. On a 100-task controlled fault-injection benchmark, the approach achieves 98.8% task success (vs. 94.5% retry-only, 93.8% full replanning), outperforms baselines at every budget level (largest gap at single attempt: 94.0% vs. 85.3%/88.2%), reduces silent failures to 0.0% under verifier guidance, and shows viability in a model-in-the-loop setting with live tool-calling models.
Significance. If the results hold under independent validation, the work supplies controlled evidence that failure-aware, budgeted, and verification-guided orchestration can improve reliability and diagnosability over standard baselines in tool-augmented LLM agents. The budget-sweep design and explicit silent-failure experiment offer a structured way to quantify trade-offs that could inform practical system design.
major comments (2)
- [Abstract] Abstract: The headline claims (98.8% success, 0.0% silent failures) rest on accurate mapping of observable signals to failure classes followed by budgeted recovery selection. No description of the mapping mechanism (rule-based or learned), no classification precision/recall metrics, and no separate validation on faults whose signatures were not used to tune the policies are supplied. This is load-bearing for interpreting the gains over retry-only and replanning baselines.
- [Evaluation] Evaluation section: The 100-task controlled fault-injection benchmark and matched recovery-budget sweep are the primary evidence, yet the manuscript supplies no statistical tests, confidence intervals, or ablation on the failure-class inference component itself. Without these, the reported percentages cannot be assessed for robustness beyond the specific injected-fault distribution.
minor comments (1)
- [Abstract] The abstract mentions 'a compact model-in-the-loop validation' but provides no details on model size, tool set, or how local fault injection was performed; a short methods paragraph would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the need for transparency on the failure-class mapping and for statistical rigor in the evaluation. We address each major comment below and outline targeted revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claims (98.8% success, 0.0% silent failures) rest on accurate mapping of observable signals to failure classes followed by budgeted recovery selection. No description of the mapping mechanism (rule-based or learned), no classification precision/recall metrics, and no separate validation on faults whose signatures were not used to tune the policies are supplied. This is load-bearing for interpreting the gains over retry-only and replanning baselines.
Authors: We agree the abstract omits key details on the mapping. The manuscript (Section 3.2) defines the mapping as a deterministic rule-based classifier driven by observable signals such as error codes, timeout flags, and validation failures; the rules were derived from pilot runs and not tuned on the evaluation tasks. We will revise the abstract to state this explicitly and add a sentence on coverage of the injected fault signatures. Classification precision/recall metrics are not reported because the mapping is non-probabilistic; we will instead supply per-class coverage statistics in the revised evaluation. A held-out validation set using novel fault signatures was not conducted and constitutes a genuine limitation we will acknowledge. revision: partial
-
Referee: [Evaluation] Evaluation section: The 100-task controlled fault-injection benchmark and matched recovery-budget sweep are the primary evidence, yet the manuscript supplies no statistical tests, confidence intervals, or ablation on the failure-class inference component itself. Without these, the reported percentages cannot be assessed for robustness beyond the specific injected-fault distribution.
Authors: We accept that the evaluation would benefit from statistical support. Although the benchmark uses fixed, reproducible fault injections yielding exact counts, we will add bootstrap confidence intervals on the success rates and include an ablation that disables the failure-class inference (replacing it with generic recovery) to quantify its isolated contribution. These additions will appear in the revised Evaluation section. revision: yes
Circularity Check
No circularity; empirical benchmark results only
full rationale
The paper reports experimental outcomes from a 100-task fault-injection benchmark (98.8% success for self-healing vs. baselines) without any derivation chain, equations, fitted parameters, or predictions that reduce to prior quantities. Claims rest on direct measurement of task success and silent-failure rates under controlled conditions rather than self-referential mappings or self-citations. The failure-class mapping is presented as an implemented component whose accuracy is assessed via the same benchmark results, with no load-bearing uniqueness theorem or ansatz imported from prior author work. This is a standard empirical systems paper whose central claims are falsifiable against the stated benchmark and therefore self-contained.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 1 Pith paper
-
Contract2Tool: Learning Preconditions and Effects for Reliable Tool-Augmented LLM Agents
Contract2Tool learns normalized symbolic contracts from tool metadata and traces to support causal filtering in LLM agents, reaching 0.980 downstream success versus 0.990 with gold contracts.
Reference graph
Works this paper leans on
-
[1]
Lewis and E
P. Lewis and E. Perez and A. Piktus and F. Petroni and V. Karpukhin and N. Goyal and H. K. Retrieval-Augmented Generation for Knowledge-Intensive. Adv. Neural Inf. Process. Syst. , volume =. 2020 , doi =
2020
-
[2]
Yao and J
S. Yao and J. Zhao and D. Yu and N. Du and I. Shafran and K. Narasimhan and Y. Cao , title =. Proc. Int. Conf. Learn. Represent. (ICLR) , year =
-
[3]
Schick and J
T. Schick and J. Dwivedi-Yu and R. Dess. Adv. Neural Inf. Process. Syst. , volume =
-
[4]
Qin and S
Y. Qin and S. Liang and Y. Ye and K. Zhu and L. Yan and Y. Lu and Y. Lin and X. Cong and X. Tang and B. Qian and S. Zhao and L. Hong and R. Tian and R. Xie and J. Zhou and M. Gerstein and D. Li and Z. Liu and M. Sun , title =. Proc. Int. Conf. Learn. Represent. (ICLR) , year =
-
[5]
Wang and C
L. Wang and C. Ma and X. Feng and Z. Zhang and H. Yang and J. Zhang and Z. Chen and J. Tang and X. Chen and Y. Lin and W. X. Zhao and Z. Wei and J. R. Wen , title =. Front. Comput. Sci. , volume =. 2024 , doi =
2024
-
[6]
Shinn and F
N. Shinn and F. Cassano and E. Berman and A. Gopinath and K. Narasimhan and S. Yao , title =. Adv. Neural Inf. Process. Syst. , volume =
-
[7]
J. S. Park and J. C. O'Brien and C. J. Cai and M. R. Morris and P. Liang and M. S. Bernstein , title =. Proc. 36th Annu. ACM Symp. User Interface Softw. Technol. (UIST) , year =
-
[8]
Liu and H
X. Liu and H. Yu and H. Zhang and Y. Xu and X. Lei and H. Lai and Y. Gu and H. Ding and K. Men and K. Yang and S. Zhang and X. Deng and A. Zeng and Z. Du and C. Zhang and S. Shen and T. Zhang and Y. Su and H. Sun and M. Huang and Y. Dong and J. Tang , title =. Proc. Int. Conf. Learn. Represent. (ICLR) , year =
-
[9]
Winston and R
C. Winston and R. Just , title =. Proc. IEEE/ACM Int. Conf. Autom. Softw. Test (AST) , pages =. 2025 , doi =
2025
- [10]
-
[11]
J. O. Kephart and D. M. Chess , title =. Computer , volume =. 2003 , doi =
2003
-
[12]
2006 , note =
An Architectural Blueprint for Autonomic Computing , publisher =. 2006 , note =
2006
-
[13]
F. S. Miranda and B. N. de Deus and T. C. de Oliveira and S. S. Mahmud , title =. Proc. 28th Eur. Conf. Pattern Lang. Programs (EuroPLoP) , year =
-
[14]
Zhou and F
S. Zhou and F. F. Xu and H. Zhu and X. Zhou and R. Lo and A. Sridhar and X. Cheng and T. Ou and Y. Bisk and D. Fried and U. Alon and G. Neubig , title =. Proc. Int. Conf. Learn. Represent. (ICLR) , year =
-
[15]
C. E. Jimenez and J. Yang and A. Wettig and S. Yao and K. Pei and O. Press and K. Narasimhan , title =. Proc. Int. Conf. Learn. Represent. (ICLR) , year =
-
[16]
Mialon and C
G. Mialon and C. Fourrier and C. Swift and T. Wolf and Y. LeCun and T. Scialom , title =. Proc. Int. Conf. Learn. Represent. (ICLR) , year =
-
[17]
Wohlin and P
C. Wohlin and P. Runeson and M. H. Experimentation in Software Engineering , publisher =. 2012 , doi =
2012
-
[18]
Runeson and M
P. Runeson and M. H. Guidelines for Conducting and Reporting Case Study Research in Software Engineering , journal =. 2009 , doi =
2009
-
[19]
and Chess, David M
Kephart, Jeffrey O. and Chess, David M. , title =. Computer , volume =. 2003 , doi =
2003
-
[20]
2006 , type =
An Architectural Blueprint for Autonomic Computing , institution =. 2006 , type =
2006
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.