SkelMo: Universal Skeletal Motion Generation for 3D Rigged Shapes
Pith reviewed 2026-06-30 11:05 UTC · model grok-4.3
The pith
A diffusion model with structural-semantic injection generates skeletal animations for arbitrary rigged 3D shapes from 2D video guidance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
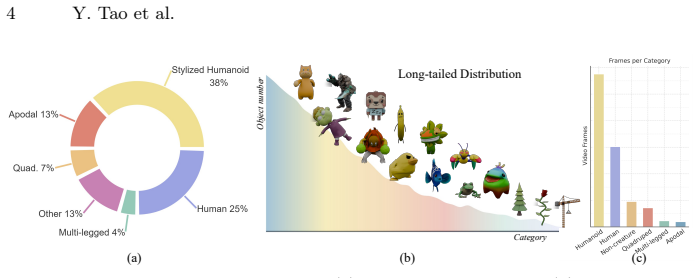
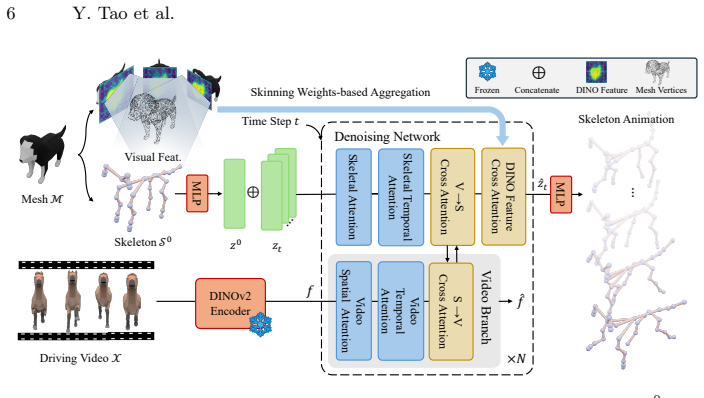
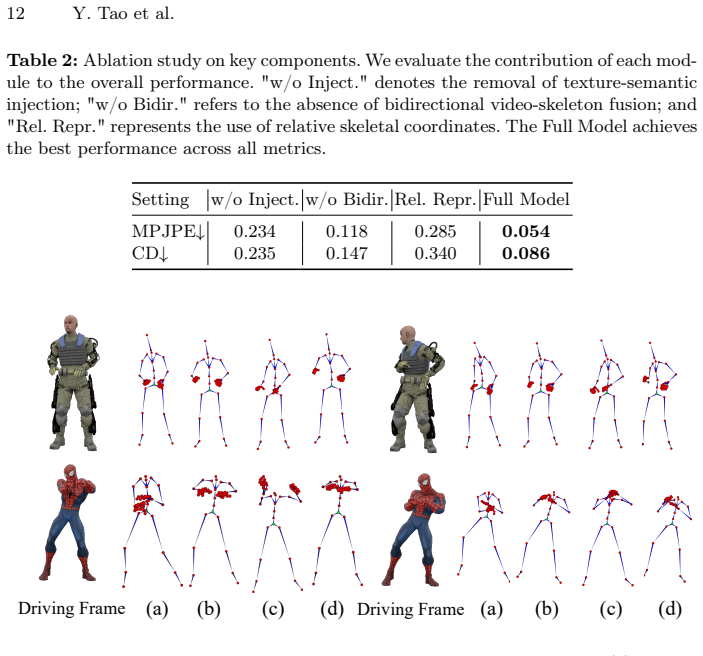
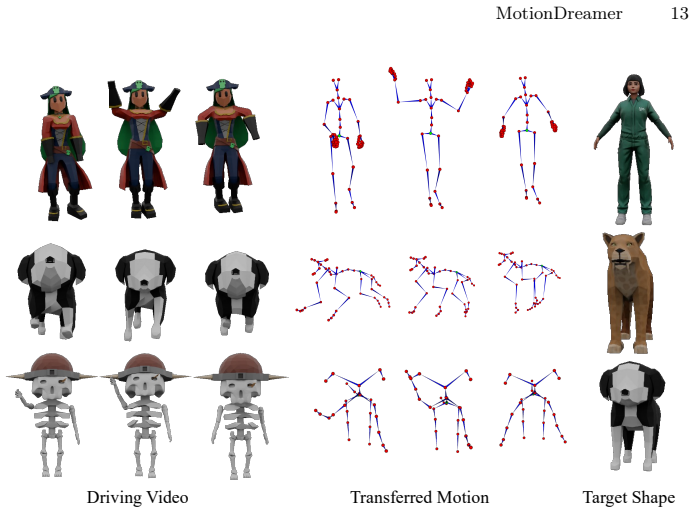
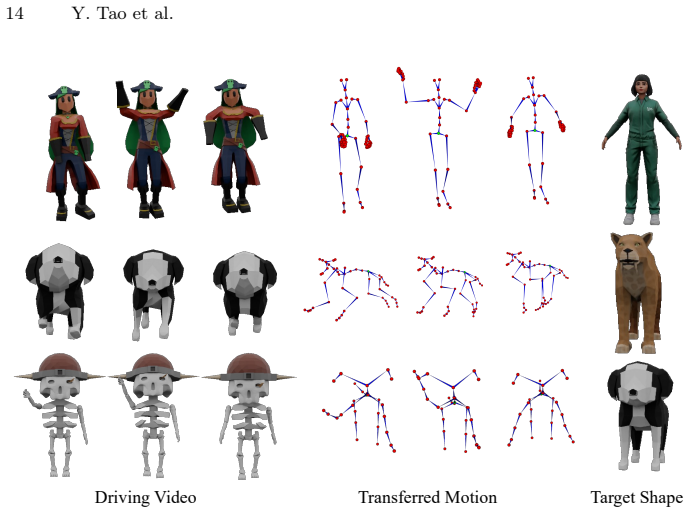
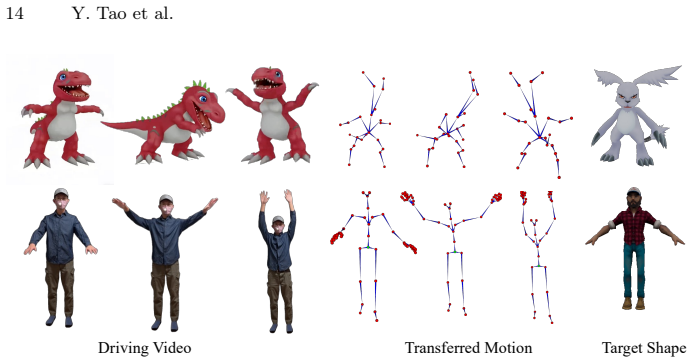
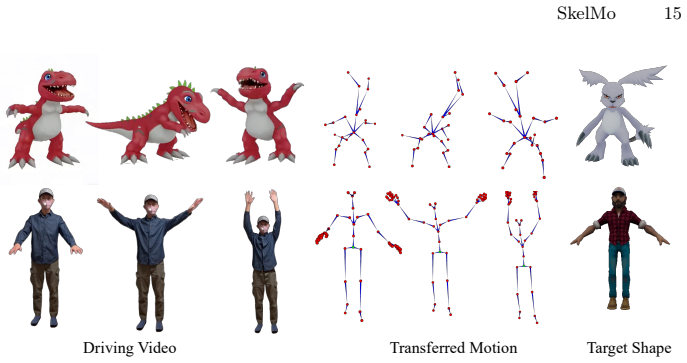
SkelMo is a diffusion-based framework for category-agnostic skeletal animation generation from 2D video guidance. To overcome data scarcity the authors curate a dataset of approximately 20,000 3D animations with textures, rigging, and varied sequences. The structural-semantic injection mechanism integrates texture and semantic attributes directly into skeletal joint representations, enabling the model to map perceived visual dynamics to specific joint hierarchies and functional roles. This produces high-fidelity animations that preserve anatomical consistency across unseen categories ranging from biological species to fantastical beings.
What carries the argument
The structural-semantic injection mechanism, which adds texture and semantic attributes to skeletal joint representations to map 2D visual motion cues onto heterogeneous 3D joint hierarchies.
If this is right
- The approach synthesizes animations that maintain anatomical consistency for both existing species and fantastical beings.
- It removes the need for category-specific templates or per-case optimization loops.
- The model outperforms prior template-based and optimization-based methods on standard benchmarks for skeletal motion quality.
- It supports efficient production of 4D assets by converting ordinary video into rigged animations without manual intervention.
Where Pith is reading between the lines
- If the injection mechanism generalizes, it could support motion retargeting between rigs that differ in topology without additional training data.
- The same joint-representation technique might be tested on video inputs that contain partial occlusions or multiple interacting characters.
- Extending the dataset curation process to include procedural variations in joint counts could further stress-test the category-agnostic claim.
Load-bearing premise
The structural-semantic injection mechanism successfully bridges the kinematic gap between 2D visual motion cues and heterogeneous 3D skeletal structures across unseen categories.
What would settle it
A test set of rigged shapes from categories absent in the 20,000-animation dataset where generated motions produce anatomically inconsistent joint angles or non-functional limb trajectories when driven by the same 2D video input.
Figures


read the original abstract
Motion generation for rigged shapes is vital for scalable 4D asset production. However, template-based methods are limited by specific topologies and fail to generalize across diverse morphologies. Conversely, per-case optimization is computationally expensive, susceptible to local optima, and highly sensitive to viewpoint-induced ambiguities. In this paper, we present SkelMo, a diffusion-based framework designed for category-agnostic skeletal animation generation from 2D video guidance. To overcome the scarcity of high-quality training data, we have curated a large-scale dynamic dataset comprising approximately 20,000 diverse 3D animations, each featuring complete textures, skeletal rigging, and a wide array of comprehensive animation sequences. To bridge the kinematic gap between 2D visual motion cues and heterogeneous 3D skeletal structures, we propose a structural-semantic injection mechanism. Our model integrates texture and semantic attributes directly into skeletal joint representations. This allows it to map perceived visual dynamics to specific joint hierarchies and their functional roles. This enables SkelMo to synthesize high-fidelity animations that maintain anatomical consistency across a vast range of unseen categories, from existing biological species to fantastical beings. Extensive experiments demonstrate that our approach significantly outperforms existing methods, setting a new state-of-the-art benchmark for robust and efficient 4D asset generation. Project Page: https://research.davytao.me/skelmo/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SkelMo, a diffusion-based framework for category-agnostic skeletal animation generation from 2D video guidance for 3D rigged shapes. It curates a large-scale dataset of approximately 20,000 diverse 3D animations with textures, rigging, and sequences, and proposes a structural-semantic injection mechanism that integrates texture and semantic attributes into skeletal joint representations to map 2D visual dynamics to heterogeneous 3D joint hierarchies. The work claims to synthesize high-fidelity, anatomically consistent animations across unseen categories and to significantly outperform existing methods, establishing a new state-of-the-art for robust and efficient 4D asset generation.
Significance. If the central claims hold, the work would be significant for scalable 4D content creation by removing reliance on fixed templates or per-instance optimization. The curation of a 20k-animation dataset with full rigging and textures represents a concrete resource contribution that could support future research in cross-category motion transfer.
minor comments (2)
- The abstract states that 'extensive experiments demonstrate' outperformance and a new SOTA but provides no metrics, baselines, or evaluation protocol; this prevents verification of the performance claim.
- No architecture diagram, loss formulation, or training details are visible in the supplied text, making it impossible to assess the structural-semantic injection mechanism or its claimed ability to bridge the 2D-to-3D kinematic gap.
Simulated Author's Rebuttal
We thank the referee for their review and summary of our work. The report notes potential significance but gives an uncertain recommendation without listing any specific major comments. We therefore have no individual points to rebut point-by-point and stand ready to supply additional evidence or clarifications should the referee identify particular concerns about the claims, experiments, or dataset.
Circularity Check
No significant circularity detected
full rationale
The paper describes an empirical ML framework (diffusion model with structural-semantic injection) trained on a curated dataset of ~20k animations. No derivation chain, equations, or first-principles predictions are presented that reduce to fitted inputs or self-citations by construction. Claims rest on experimental outperformance rather than tautological mappings. The abstract and description contain no load-bearing self-referential steps of the enumerated kinds.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Auto-rig pro.https://superhivemarket.com/products/auto-rig-pro, blender add-on for character rigging and animation retargeting
-
[2]
Bai, J., Bai, S., Chu, Y., Cui, Z., Dang, K., Deng, X., Fan, Y., Ge, W., Han, Y., Huang, F., et al.: Qwen technical report. arXiv preprint arXiv:2309.16609 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
ByteDance: Doubao.https://www.doubao.com/(2026), accessed: 2026-03-05
2026
-
[4]
In: CVPR (2026)
Chen, H., Chen, X., Zhang, Y., Xu, Z., Chen, A.: Motion 3-to-4: 3d motion recon- struction for 4d synthesis. In: CVPR (2026)
2026
-
[5]
In: CVPR
Choi, H., Moon, G., Chang, J.Y., Lee, K.M.: Beyond static features for temporally consistent 3d human pose and shape from a video. In: CVPR. pp. 1964–1973 (2021)
1964
-
[6]
In: CVPR
Chu, R., Liu, Z., Ye, X., Tan, X., Qi, X., Fu, C.W., Jia, J.: Command-driven artic- ulated object understanding and manipulation. In: CVPR. pp. 8813–8823 (2023)
2023
-
[7]
NIPS36, 35799–35813 (2023)
Deitke, M., Liu, R., Wallingford, M., Ngo, H., Michel, O., Kusupati, A., Fan, A., Laforte, C., Voleti, V., Gadre, S.Y., et al.: Objaverse-xl: A universe of 10m+ 3d objects. NIPS36, 35799–35813 (2023)
2023
-
[8]
In: CVPR
Deitke, M., Schwenk, D., Salvador, J., Weihs, L., Michel, O., VanderBilt, E., Schmidt, L., Ehsani, K., Kembhavi, A., Farhadi, A.: Objaverse: A universe of annotated 3d objects. In: CVPR. pp. 13142–13153 (2023)
2023
-
[9]
In: SIGGRAPH
Gat, I., Raab, S., Tevet, G., Reshef, Y., Bermano, A.H., Cohen-Or, D.: Anytop: Character animation diffusion with any topology. In: SIGGRAPH. pp. 1–10 (2025)
2025
-
[10]
In: CVPR
Gong,K.,Wen,Z.,He,W.,Xu,M.,Wang,Q.,Zhang,N.,Li,Z.,Lian,D.,Zhao,W., He, X., et al.: Mocapanything: Unified 3d motion capture for arbitrary skeletons from monocular videos. In: CVPR. pp. 7089–7099 (2026)
2026
-
[11]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Kanazawa, A., Black, M.J., Jacobs, D.W., Malik, J.: End-to-end recovery of human shape and pose. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 7122–7131 (2018)
2018
-
[12]
In: ECCV
Kanazawa, A., Tulsiani, S., Efros, A.A., Malik, J.: Learning category-specific mesh reconstruction from image collections. In: ECCV. pp. 371–386 (2018)
2018
-
[13]
In: CVPR
Kocabas, M., Athanasiou, N., Black, M.J.: Vibe: Video inference for human body pose and shape estimation. In: CVPR. pp. 5253–5263 (2020)
2020
-
[14]
Kocabas, M., Yuan, Y., Molchanov, P., Guo, Y., Black, M.J., Hilliges, O., Kautz, J., Iqbal, U.: Pace: Human and camera motion estimation from in-the-wild videos. In: 3DV. pp. 397–408. IEEE (2024)
2024
-
[15]
In: ICCV
Li, Z., Luo, M., Hou, R., Zhao, X., Liu, H., Chang, H., Liu, Z., Li, C.: Morph: A motion-free physics optimization framework for human motion generation. In: ICCV. pp. 14580–14589 (2025)
2025
-
[16]
In: CVPR
Lin, J., Zeng, A., Wang, H., Zhang, L., Li, Y.: One-stage 3d whole-body mesh recovery with component aware transformer. In: CVPR. pp. 21159–21168 (2023)
2023
-
[17]
TOG44(4), 1–12 (2025)
Liu, I., Xu, Z., Yifan, W., Tan, H., Xu, Z., Wang, X., Su, H., Shi, Z.: Riganything: Template-free autoregressive rigging for diverse 3d assets. TOG44(4), 1–12 (2025)
2025
-
[18]
In: Seminal Graphics Papers: Pushing the Boundaries, Volume 2, pp
Loper, M., Mahmood, N., Romero, J., Pons-Moll, G., Black, M.J.: Smpl: A skinned multi-person linear model. In: Seminal Graphics Papers: Pushing the Boundaries, Volume 2, pp. 851–866 (2023)
2023
-
[19]
Oquab, M., Darcet, T., Moutakanni, T., Vo, H.V., Szafraniec, M., Khalidov, V., Fernandez,P.,Haziza,D.,Massa,F.,El-Nouby,A.,Howes,R.,Huang,P.Y.,Xu,H., Sharma, V., Li, S.W., Galuba, W., Rabbat, M., Assran, M., Ballas, N., Synnaeve, G., Misra, I., Jegou, H., Mairal, J., Labatut, P., Joulin, A., Bojanowski, P.: Dinov2: Learning robust visual features without ...
2023
-
[20]
In: CVPR
Pavlakos, G., Choutas, V., Ghorbani, N., Bolkart, T., Osman, A.A., Tzionas, D., Black, M.J.: Expressive body capture: 3d hands, face, and body from a single image. In: CVPR. pp. 10975–10985 (2019)
2019
-
[21]
arXiv preprint arXiv:2312.17142 (2023)
Ren, J., Pan, L., Tang, J., Zhang, C., Cao, A., Zeng, G., Liu, Z.: Dreamgaussian4d: Generative 4d gaussian splatting. arXiv preprint arXiv:2312.17142 (2023)
-
[22]
CVPR (2026)
Sabathier, R., Novotny, D., Mitra, N.J., Monnier, T.: Actionmesh: Animated 3d mesh generation with temporal 3d diffusion. CVPR (2026)
2026
-
[23]
arXiv preprint arXiv:2506.07489 (2025)
Shi, Y., Liu, Y., Wu, Y., Liu, X., Zhao, C., Luo, J., Zhou, B.: Drive any mesh: 4d latent diffusion for mesh deformation from video. arXiv preprint arXiv:2506.07489 (2025)
-
[24]
NIPS38, 72152–72184 (2026)
Song, C., Li, X., Yang, F., Xu, Z., Wei, J., Liu, F., Feng, J., Lin, G., Zhang, J.: Puppeteer: Rig and animate your 3d models. NIPS38, 72152–72184 (2026)
2026
-
[25]
In: CVPR
Song, C., Zhang, J., Li, X., Yang, F., Chen, Y., Xu, Z., Liew, J.H., Guo, X., Liu, F., Feng, J., et al.: Magicarticulate: Make your 3d models articulation-ready. In: CVPR. pp. 15998–16007 (2025)
2025
-
[26]
In: ECCV
Sun, K., Litvak, D., Zhang, Y., Li, H., Wu, J., Wu, S.: Ponymation: Learning articulated 3d animal motions from unlabeled online videos. In: ECCV. pp. 100–
-
[27]
In: CVPR
Sun, Q., Wang, Y., Zeng, A., Yin, W., Wei, C., Wang, W., Mei, H., Leung, C.S., Liu, Z., Yang, L., et al.: Aios: All-in-one-stage expressive human pose and shape estimation. In: CVPR. pp. 1834–1843 (2024)
2024
-
[28]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., Zeng, J., Wang, J., Zhang, J., Zhou, J., Wang, J., Chen, J., Zhu, K., Zhao, K., Yan, K., Huang, L., Feng, M., Zhang, N., Li, P., Wu, P., Chu, R., Feng, R., Zhang, S., Sun, S., Fang, T., Wang, T., Gui, T., Weng, T., Shen, T., Lin, W., Wang, W., Wang, W., Zhou, W.,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
In: ECCV
Wang, Y., Wang, Z., Liu, L., Daniilidis, K.: Tram: Global trajectory and motion of 3d humans from in-the-wild videos. In: ECCV. pp. 467–487. Springer (2024)
2024
-
[30]
In: CVPR
Wu, S., Li, R., Jakab, T., Rupprecht, C., Vedaldi, A.: Magicpony: Learning artic- ulated 3d animals in the wild. In: CVPR. pp. 8792–8802 (2023)
2023
-
[31]
ICCV (2025)
Wu, Z., Yu, C., Wang, F., Bai, X.: Animateanymesh: A feed-forward 4d foundation model for text-driven universal mesh animation. ICCV (2025)
2025
-
[32]
In: ICCV
Xiao, L., Lu, S., Pi, H., Fan, K., Pan, L., Zhou, Y., Feng, Z., Zhou, X., Peng, S., Wang, J.: Motionstreamer: Streaming motion generation via diffusion-based autoregressive model in causal latent space. In: ICCV. pp. 10086–10096 (2025)
2025
-
[33]
In: CVPR
Xie, T., Chen, Y., Guo, Y., Yang, Y., Zhou, B., Terzopoulos, D., Jiang, Y., Jiang, C.: Animimic: Imitating 3d animation from video priors. In: CVPR. pp. 40266– 40276 (2026)
2026
-
[34]
Xie, Y., Yao, C.H., Voleti, V., Jiang, H., Jampani, V.: Sv4d: Dynamic 3d con- tent generation with multi-frame and multi-view consistency. arXiv preprint arXiv:2407.17470 (2024)
-
[35]
In: CVPR
Yang, G., Sun, D., Jampani, V., Vlasic, D., Cole, F., Chang, H., Ramanan, D., Freeman, W.T., Liu, C.: Lasr: Learning articulated shape reconstruction from a monocular video. In: CVPR. pp. 15980–15989 (2021)
2021
-
[36]
In: CVPR (2022) 18 Y
Yang, G., Vo, M., Neverova, N., Ramanan, D., Vedaldi, A., Joo, H.: Banmo: Build- ing animatable 3d neural models from many casual videos. In: CVPR (2022) 18 Y. Tao et al
2022
-
[37]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Yang, Z., Teng, J., Zheng, W., Ding, M., Huang, S., Xu, J., Yang, Y., Hong, W., Zhang, X., Feng, G., et al.: Cogvideox: Text-to-video diffusion models with an expert transformer. arXiv preprint arXiv:2408.06072 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
NIPS35, 15296–15308 (2022)
Yao, C.H., Hung, W.C., Li, Y., Rubinstein, M., Yang, M.H., Jampani, V.: Lassie: Learning articulated shapes from sparse image ensemble via 3d part discovery. NIPS35, 15296–15308 (2022)
2022
-
[39]
In: ICCV
Yao, C.H., Xie, Y., Voleti, V., Jiang, H., Jampani, V.: Sv4d 2.0: Enhancing spatio- temporal consistency in multi-view video diffusion for high-quality 4d generation. In: ICCV. pp. 13248–13258 (2025)
2025
-
[40]
ICLR (2026)
Yenphraphai, J., Mirzaei, A., Chen, J., Zou, J., Tulyakov, S., Yeh, R.A., Wonka, P., Wang, C.: Shapegen4d: Towards high quality 4d shape generation from videos. ICLR (2026)
2026
-
[41]
In: ECCV
Yi, H., Thies, J., Black, M.J., Peng, X.B., Rempe, D.: Generating human interac- tion motions in scenes with text control. In: ECCV. pp. 246–263. Springer (2024)
2024
-
[42]
In: ICCV
Zhang, B., Xu, S., Wang, C., Yang, J., Zhao, F., Chen, D., Guo, B.: Gaussian variation field diffusion for high-fidelity video-to-4d synthesis. In: ICCV. pp. 12502– 12513 (2025)
2025
-
[43]
NIPS37, 15272–15295 (2024)
Zhang, H., Chen, X., Wang, Y., Liu, X., Wang, Y., Qiao, Y.: 4diffusion: Multi-view video diffusion model for 4d generation. NIPS37, 15272–15295 (2024)
2024
-
[44]
arXiv preprint arXiv:2503.06955 (2025)
Zhang, Z., Wang, Y., Mao, W., Li, D., Zhao, R., Wu, B., Song, Z., Zhuang, B., Reid, I., Hartley, R.: Motion anything: Any to motion generation. arXiv preprint arXiv:2503.06955 (2025)
-
[45]
In: CVPR
Zuffi, S., Kanazawa, A., Jacobs, D.W., Black, M.J.: 3d menagerie: Modeling the 3d shape and pose of animals. In: CVPR. pp. 6365–6373 (2017)
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.