Effective Multi-sensor Conditioning for Street-view Novel-view Synthesis
Pith reviewed 2026-06-28 15:31 UTC · model grok-4.3
The pith
StreetNVS fuses sparse LiDAR reprojections, surround-view images, and poses inside a video diffusion model to render coherent novel driving scenes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
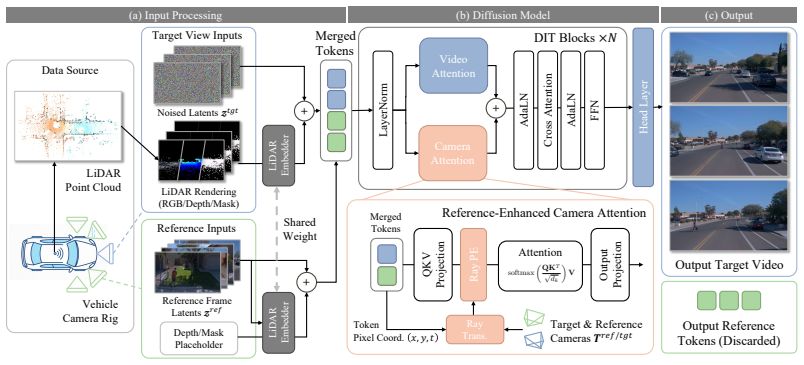
StreetNVS is a video diffusion framework that jointly conditions on sparse LiDAR reprojections for accurate but incomplete metric geometry, surround-view reference imagery for dense appearance, and camera poses, through a Reference-Enhanced Camera Attention module based on relative ray-level positional encoding together with a two-stage curriculum that gradually sparsifies the LiDAR input.
What carries the argument
Reference-Enhanced Camera Attention module with relative ray-level positional encoding, which aligns and fuses incomplete LiDAR geometry with dense image appearance across multiple views.
If this is right
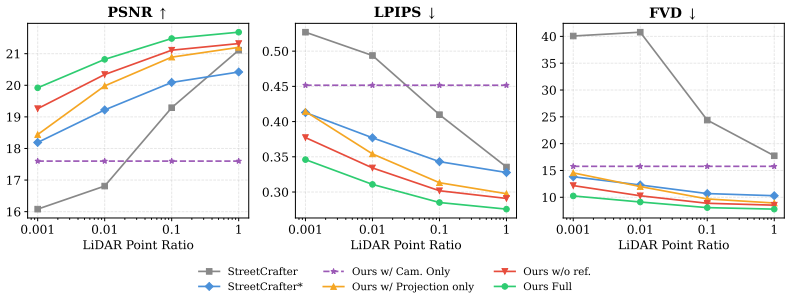
- The model substantially outperforms state-of-the-art baselines when given only sparse LiDAR.
- It reaches quality comparable to methods that use 10-100 times denser point clouds.
- It produces temporally coherent video along previously unseen paths including elevation change, lane shift, pullback, and rotation.
Where Pith is reading between the lines
- The same attention design could be tested on indoor or aerial capture setups where only partial depth and dense imagery are available.
- If the curriculum generalizes, future systems might train on cheaper, sparser sensor rigs without losing rendering quality.
- The ray-level positional encoding might be combined with other geometric cues such as semantic maps or optical flow to further constrain the diffusion process.
Load-bearing premise
The Reference-Enhanced Camera Attention module and the gradual LiDAR sparsification curriculum will continue to produce consistent geometry and appearance when the target camera path moves far from the recorded trajectory.
What would settle it
Visible geometric inconsistencies or flickering artifacts in output videos when the model is evaluated on elevation or rotation trajectories that exceed the range used in the second training stage.
Figures








read the original abstract
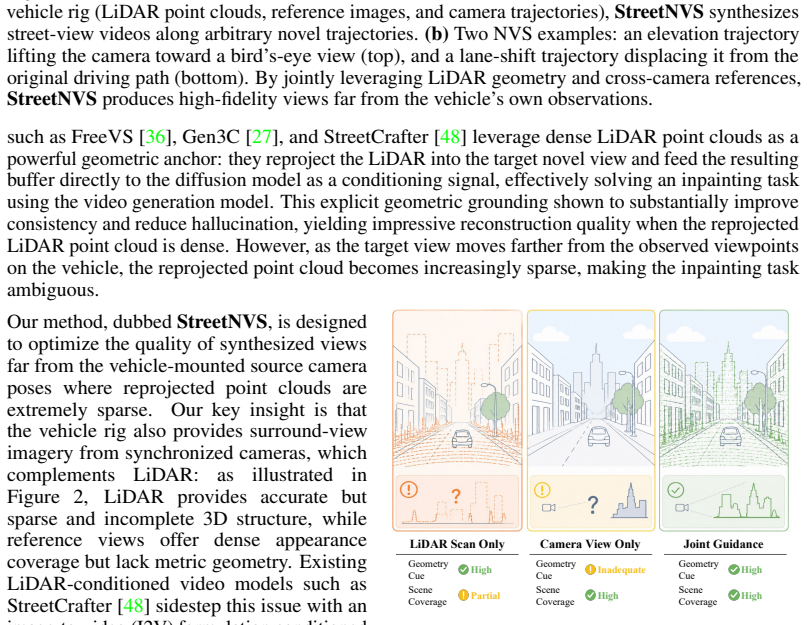
Modern vehicle platforms are equipped with a rich sensor suite, including LiDAR, calibrated multi-camera rigs, and accurate ego-motion, that in principle offers strong signal for re-rendering a driving scene from novel viewpoints. A growing line of recent work leverages video diffusion models for this task, using their generative priors to synthesize plausible novel views from sparse vehicle observations. In practice, however, existing methods exploit only a fragment of this signal, and their quality tends to degrade as the target trajectory departs from the recorded driving path. We argue that this is fundamentally a multi-sensor fusion problem: sparse LiDAR reprojections supply accurate but incomplete metric geometry, surround-view reference imagery supplies dense appearance but no metric depth, and camera poses tie the two together across views. We introduce StreetNVS, a video diffusion framework that jointly conditions on all three signals through a Reference-Enhanced Camera Attention module based on a relative ray-level positional encoding. We develop a two-stage curriculum training strategy that gradually exposes the model to increasingly sparse LiDAR. On the Waymo Open Dataset, StreetNVS substantially outperforms state-of-the-art baselines under sparse LiDAR conditioning, matches methods that rely on 10-100 times denser point clouds. We further show capabilities of synthesizing coherent videos along extreme out-of-trajectory paths such as elevation, lane-shift, pullback, and rotation. Our website: https://streetnvs.github.io
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces StreetNVS, a video diffusion framework for street-view novel-view synthesis that jointly conditions on sparse LiDAR reprojections (metric geometry), surround-view reference imagery (dense appearance), and camera poses. The core technical contribution is a Reference-Enhanced Camera Attention module that uses relative ray-level positional encoding to fuse these signals, combined with a two-stage curriculum that gradually sparsifies LiDAR during training. On the Waymo Open Dataset the method is reported to substantially outperform prior baselines under sparse LiDAR conditioning, match methods that use 10-100× denser point clouds, and produce coherent video along extreme out-of-trajectory paths (elevation, lane-shift, pullback, rotation).
Significance. If the quantitative claims and qualitative robustness results hold, the work provides a concrete demonstration that multi-sensor fusion via attention-based conditioning can close the gap between sparse and dense geometric inputs in generative novel-view synthesis for driving scenes. The curriculum strategy and ray-level encoding are presented as generalizable mechanisms that could influence subsequent multi-modal diffusion models for autonomous-driving simulation and mapping.
minor comments (3)
- [Abstract] Abstract: the phrase “matches methods that rely on 10-100 times denser point clouds” should be accompanied by an explicit citation to the compared methods and their reported point-cloud densities so readers can verify the factor.
- [Method] The two-stage curriculum is described only at a high level; a precise schedule (e.g., number of epochs per sparsity level, exact sparsity ratios) should be stated in the method section or an appendix table.
- [Experiments] Figure captions and the main text should consistently distinguish “sparse LiDAR conditioning” from the baseline methods’ input densities so that the claimed parity is immediately interpretable.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our work and the recommendation for minor revision. The referee's description accurately captures the key elements of StreetNVS, including the multi-sensor conditioning approach, the Reference-Enhanced Camera Attention module, the curriculum training strategy, and the reported results on the Waymo Open Dataset. Since the provided referee report lists no specific major comments under the MAJOR COMMENTS section, we have no point-by-point rebuttals to address at this time. We will incorporate any minor improvements suggested during the revision process to further strengthen the manuscript.
Circularity Check
No significant circularity detected
full rationale
The paper presents an empirical method (StreetNVS) for novel-view synthesis via a video diffusion model with Reference-Enhanced Camera Attention and a two-stage curriculum on sparse LiDAR. All central claims reduce to reported performance numbers on the external Waymo Open Dataset against baselines; no equations, fitted parameters renamed as predictions, self-definitional loops, or load-bearing self-citations appear in the abstract or method sketch. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Video diffusion models possess generative priors that can be effectively conditioned on geometric and appearance signals for novel-view synthesis.
Reference graph
Works this paper leans on
-
[1]
Bahmani, I
S. Bahmani, I. Skorokhodov, G. Qian, A. Siarohin, W. Menapace, A. Tagliasacchi, D. B. Lindell, and S. Tulyakov. Ac3d: Analyzing and improving 3d camera control in video diffusion transformers. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 22875–22889, 2025
2025
-
[2]
J. Bai, M. Xia, X. Fu, X. Wang, L. Mu, J. Cao, Z. Liu, H. Hu, X. Bai, P. Wan, and D. Zhang. Recammaster: Camera-controlled generative rendering from a single video, 2025
2025
-
[3]
Z. Chen, J. Yang, J. Huang, R. De Lutio, J. M. Esturo, B. Ivanovic, O. Litany, Z. Gojcic, S. Fidler, M. Pavone, et al. Omnire: Omni urban scene reconstruction.arXiv preprint arXiv:2408.16760, 2024
arXiv 2024
-
[4]
Z. Di, G. Zhu, Z. Duan, Z. Chu, Y . Chen, and W. Lu. Diffsynth-engine: a high-performance diffusion inference engine.https://github.com/modelscope/diffsynth-engine, 2025
2025
-
[5]
T. Fischer, J. Kulhanek, S. R. Bulo, L. Porzi, M. Pollefeys, and P. Kontschieder. Dynamic 3d gaussian fields for urban areas.arXiv preprint arXiv:2406.03175, 2024
arXiv 2024
-
[6]
Z. Gu, R. Yan, J. Lu, P. Li, Z. Dou, C. Si, Z. Dong, Q. Liu, C. Lin, Z. Liu, W. Wang, and Y . Liu. Diffusion as shader: 3d-aware video diffusion for versatile video generation control.SIGGRAPH, 2025
2025
-
[7]
H. He, Y . Xu, Y . Guo, G. Wetzstein, B. Dai, H. Li, and C. Yang. Cameractrl: Enabling camera control for text-to-video generation. InICLR, 2025
2025
-
[8]
H. He, C. Yang, S. Lin, Y . Xu, M. Wei, L. Gui, Q. Zhao, G. Wetzstein, L. Jiang, and H. Li. Cameractrl ii: Dynamic scene exploration via camera-controlled video diffusion models.arXiv preprint arXiv:2503.10592, 2025
arXiv 2025
- [9]
-
[10]
Huang, Q
J. Huang, Q. Zhou, H. Rabeti, A. Korovko, H. Ling, X. Ren, T. Shen, J. Gao, D. Slepichev, C.-H. Lin, J. Ren, K. Xie, J. Biswas, L. Leal-Taixe, and S. Fidler. Vipe: Video pose engine for 3d geometric perception. InNVIDIA Research Whitepapers, 2025
2025
-
[11]
Jiang, Z
Z. Jiang, Z. Han, C. Mao, J. Zhang, Y . Pan, and Y . Liu. Vace: All-in-one video creation and editing. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 17191–17202, 2025
2025
-
[12]
Kapfer, K
C. Kapfer, K. Stine, B. Narasimhan, C. Mentzel, and E. Candes. Marlowe: Stanford’s gpu-based computa- tional instrument, Jan. 2025
2025
-
[13]
Kerbl, G
B. Kerbl, G. Kopanas, T. Leimkühler, and G. Drettakis. 3d gaussian splatting for real-time radiance field rendering.ACM Transactions on Graphics, 42(4), July 2023
2023
-
[14]
X. Kong, S. Liu, X. Lyu, M. Taher, X. Qi, and A. J. Davison. Eschernet: A generative model for scalable view synthesis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9503–9513, 2024
2024
-
[15]
Kuang, S
Z. Kuang, S. Cai, H. He, Y . Xu, H. Li, L. Guibas, and G. Wetzstein. Collaborative video diffusion: Consistent multi-video generation with camera control. InarXiv, 2024
2024
-
[16]
Kuang, T
Z. Kuang, T. Zhang, K. Zhang, H. Tan, S. Bi, Y . Hu, Z. Xu, M. Hasan, G. Wetzstein, and F. Luan. Buffer anytime: Zero-shot video depth and normal from image priors. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 17660–17670, 2025
2025
-
[17]
Y .-C. Lee, Z. Zhang, J. Huang, J.-H. Wang, J.-Y . Lee, J.-B. Huang, E. Shechtman, and Z. Li. Generative video motion editing with 3d point tracks.arXiv preprint arXiv:2512.02015, 2025
arXiv 2025
-
[18]
R. Li, B. Yi, J. Liu, H. Gao, Y . Ma, and A. Kanazawa. Cameras as relative positional encoding.arXiv preprint arXiv:2507.10496, 2025. 10
arXiv 2025
-
[19]
T. Li, G. Zheng, R. Jiang, T. Wu, Y . Lu, Y . Lin, X. Li, et al. Realcam-i2v: Real-world image-to-video generation with interactive complex camera control.arXiv preprint arXiv:2502.10059, 2025
arXiv 2025
-
[20]
H. Lin, S. Chen, J. H. Liew, D. Y . Chen, Z. Li, G. Shi, J. Feng, and B. Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025
Pith/arXiv arXiv 2025
-
[21]
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling. arXiv preprint arXiv:2210.02747, 2022
Pith/arXiv arXiv 2022
-
[22]
S. Liu, K. W. Ng, W. Jang, J. Guo, J. Han, H. Liu, Y . Douratsos, J. C. Pérez, Z. Zhou, C. Phung, et al. Scaling sequence-to-sequence generative neural rendering.arXiv preprint arXiv:2510.04236, 2025
Pith/arXiv arXiv 2025
-
[23]
X. Liu, C. Zhou, and S. Huang. 3dgs-enhancer: Enhancing unbounded 3d gaussian splatting with view-consistent 2d diffusion priors. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[24]
I. Loshchilov and F. Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
Pith/arXiv arXiv 2017
-
[25]
Mildenhall, P
B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, and R. Ng. Nerf: Representing scenes as neural radiance fields for view synthesis.Communications of the ACM, 65(1):99–106, 2021
2021
- [26]
-
[27]
X. Ren, T. Shen, J. Huang, H. Ling, Y . Lu, M. Nimier-David, T. Müller, A. Keller, S. Fidler, and J. Gao. Gen3c: 3d-informed world-consistent video generation with precise camera control. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 6121–6132, 2025
2025
-
[28]
J. Shin, Z. Li, R. Zhang, J.-Y . Zhu, J. Park, E. Shechtman, and X. Huang. MotionStream: Real-Time Video Generation with Interactive Motion Controls. InProceedings of the International Conference on Learning Representations (ICLR), 2026
2026
-
[29]
J. Su, M. Ahmed, Y . Lu, S. Pan, W. Bo, and Y . Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
2024
-
[30]
P. Sun, H. Kretzschmar, X. Dotiwalla, A. Chouard, V . Patnaik, P. Tsui, J. Guo, Y . Zhou, Y . Chai, B. Caine, V . Vasudevan, W. Han, J. Ngiam, H. Zhao, A. Timofeev, S. Ettinger, M. Krivokon, A. Gao, A. Joshi, Y . Zhang, J. Shlens, Z. Chen, and D. Anguelov. Scalability in perception for autonomous driving: Waymo open dataset. InProceedings of the IEEE/CVF ...
2020
-
[31]
Tancik, V
M. Tancik, V . Casser, X. Yan, S. Pradhan, B. Mildenhall, P. P. Srinivasan, J. T. Barron, and H. Kretzschmar. Block-nerf: Scalable large scene neural view synthesis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8248–8258, 2022
2022
-
[32]
Tewari, J
A. Tewari, J. Thies, B. Mildenhall, P. Srinivasan, E. Tretschk, W. Yifan, C. Lassner, V . Sitzmann, R. Martin- Brualla, S. Lombardi, et al. Advances in neural rendering. InComputer Graphics F orum, volume 41, pages 703–735. Wiley Online Library, 2022
2022
-
[33]
T. Unterthiner, S. Van Steenkiste, K. Kurach, R. Marinier, M. Michalski, and S. Gelly. Towards accurate generative models of video: A new metric & challenges.arXiv preprint arXiv:1812.01717, 2018
Pith/arXiv arXiv 2018
-
[34]
T. Wan, A. Wang, B. Ai, B. Wen, C. Mao, C.-W. Xie, D. Chen, F. Yu, H. Zhao, J. Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
Pith/arXiv arXiv 2025
-
[35]
J. Wang, M. Chen, N. Karaev, A. Vedaldi, C. Rupprecht, and D. Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025
2025
-
[36]
Q. Wang, L. Fan, Y . Wang, Y . Chen, and Z. Zhang. Freevs: Generative view synthesis on free driving trajectory.arXiv preprint arXiv:2410.18079, 2024
arXiv 2024
-
[37]
S. Wang, V . Leroy, Y . Cabon, B. Chidlovskii, and J. Revaud. Dust3r: Geometric 3d vision made easy. In CVPR, 2024
2024
-
[38]
Z. Wang, A. Bovik, H. Sheikh, and E. Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE Transactions on Image Processing, 13(4):600–612, 2004
2004
-
[39]
Z. Wang, Z. Yuan, X. Wang, Y . Li, T. Chen, M. Xia, P. Luo, and Y . Shan. Motionctrl: A unified and flexible motion controller for video generation. InACM SIGGRAPH 2024 Conference Papers, pages 1–11, 2024
2024
-
[40]
C. Wu, J. Sun, Z. Shen, and L. Zhang. Mapnerf: Incorporating map priors into neural radiance fields for driving view simulation. In2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 7082–7088. IEEE, 2023
2023
-
[41]
J. Z. Wu, Y . Zhang, H. Turki, X. Ren, J. Gao, M. Z. Shou, S. Fidler, Z. Gojcic, and H. Ling. Difix3d+: Improving 3d reconstructions with single-step diffusion models.CVPR, 2025
2025
-
[42]
R. Wu, R. Gao, B. Poole, A. Trevithick, C. Zheng, J. T. Barron, and A. Holynski. CAT4D: Create Anything in 4D with Multi-View Video Diffusion Models.arXiv:2411.18613, 2024
arXiv 2024
-
[43]
T. Wu, S. Yang, R. Po, Y . Xu, Z. Liu, D. Lin, and G. Wetzstein. Video world models with long-term spatial memory. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[44]
Y . Wu, M. Jeon, J.-H. R. Chang, O. Tuzel, and S. Tulsiani. Rayrope: Projective ray positional encoding for multi-view attention.arXiv preprint arXiv:2601.15275, 2026. 11
arXiv 2026
-
[45]
Xiong, S
K. Xiong, S. Gong, X. Ye, X. Tan, J. Wan, E. Ding, J. Wang, and X. Bai. Cape: Camera view position embedding for multi-view 3d object detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 21570–21579, 2023
2023
-
[46]
D. Xu, W. Nie, C. Liu, S. Liu, J. Kautz, Z. Wang, and A. Vahdat. Camco: Camera-controllable 3d-consistent image-to-video generation.arXiv preprint arXiv:2406.02509, 2024
Pith/arXiv arXiv 2024
-
[47]
Y . Yan, H. Lin, C. Zhou, W. Wang, H. Sun, K. Zhan, X. Lang, X. Zhou, and S. Peng. Street gaussians: Modeling dynamic urban scenes with gaussian splatting. InEuropean Conference on Computer Vision, pages 156–173. Springer, 2024
2024
-
[48]
Y . Yan, Z. Xu, H. Lin, H. Jin, H. Guo, Y . Wang, K. Zhan, X. Lang, H. Bao, X. Zhou, and S. Peng. Streetcrafter: Street view synthesis with controllable video diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
2025
-
[49]
Z. Yang, Y . Chen, J. Wang, S. Manivasagam, W.-C. Ma, A. J. Yang, and R. Urtasun. Unisim: A neural closed-loop sensor simulator. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1389–1399, 2023
2023
-
[50]
M. YU, W. Hu, J. Xing, and Y . Shan. Trajectorycrafter: Redirecting camera trajectory for monocular videos via diffusion models.arXiv preprint arXiv:2503.05638, 2025
arXiv 2025
-
[51]
W. Yu, R. Qian, Y . Li, L. Wang, S. Yin, D. Anthony, Y . Ye, Y . Li, W. Wan, A. Garg, et al. Mosaicmem: Hybrid spatial memory for controllable video world models.arXiv preprint arXiv:2603.17117, 2026
arXiv 2026
-
[52]
W. Yu, J. Xing, L. Yuan, W. Hu, X. Li, Z. Huang, X. Gao, T.-T. Wong, Y . Shan, and Y . Tian. Viewcrafter: Taming video diffusion models for high-fidelity novel view synthesis.TPAMI, 2024
2024
-
[53]
S. Zhai, Z. Ye, J. Liu, W. Xie, J. Hu, Z. Peng, H. Xue, D. Chen, X. Wang, L. Yang, et al. Stargen: A spatiotemporal autoregression framework with video diffusion model for scalable and controllable scene generation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 26822–26833, 2025
2025
- [54]
- [55]
-
[56]
Zhang, A
L. Zhang, A. Rao, and M. Agrawala. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 3836–3847, October 2023
2023
-
[57]
Zhang, S
Q. Zhang, S. Zhai, M. A. B. Martin, K. Miao, A. Toshev, J. Susskind, and J. Gu. World-consistent video diffusion with explicit 3d modeling. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 21685–21695, 2025
2025
-
[58]
Zhang, P
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018
2018
-
[59]
G. Zhao, C. Ni, X. Wang, Z. Zhu, X. Zhang, Y . Wang, G. Huang, X. Chen, B. Wang, Y . Zhang, et al. Drivedreamer4d: World models are effective data machines for 4d driving scene representation. In Proceedings of the computer vision and pattern recognition conference, pages 12015–12026, 2025
2025
-
[60]
G. Zhao, X. Wang, C. Ni, Z. Zhu, W. Qin, G. Huang, and X. Wang. Recondreamer++: Harmonizing generative and reconstructive models for driving scene representation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 26718–26728, 2025
2025
- [61]
-
[62]
S. Zheng, Z. Peng, Y . Zhou, Y . Zhu, H. Xu, X. Huang, and Y . Fu. Vidcraft3: Camera, object, and lighting control for image-to-video generation.arXiv preprint arXiv:2502.07531, 2025
Pith/arXiv arXiv 2025
-
[63]
H. Zhou, J. Shao, L. Xu, D. Bai, W. Qiu, B. Liu, Y . Wang, A. Geiger, and Y . Liao. Hugs: Holistic urban 3d scene understanding via gaussian splatting. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21336–21345, 2024
2024
-
[64]
X. Zhou, Z. Lin, X. Shan, Y . Wang, D. Sun, and M.-H. Yang. Drivinggaussian: Composite gaussian splatting for surrounding dynamic autonomous driving scenes. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21634–21643, 2024
2024
-
[65]
L. Zhu, M. Narayana, M. Stary, W. Hutchcroft, G. Wetzstein, and I. Armeni. Gaussfusion: Improving 3d reconstruction in the wild with a geometry-informed video generator.arXiv preprint arXiv:2603.25053, 2026. 12 A More Results Please check our website (https://streetnvs.github.io) for all animated results. We provide a finer-grained comparison with baselin...
arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.