Why Do Self-Harm Prediction Models Struggle to Generalise? Lexical and Semantic Variations in Emergency Department Triage Notes
Pith reviewed 2026-06-28 15:12 UTC · model grok-4.3
The pith
Lexical and semantic variations in emergency department notes reduce self-harm prediction model performance across hospitals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Our results reveal variation in lexical expression and feature importance related to self-harm across hospitals, despite consistent core themes such as self-poisoning and self-injury. These documentation differences are associated with reduced cross-site performance. Our findings provide insight into how institutional variation affects the identification of self-harm in clinical text and highlight potential methods to improve model generalisability.
What carries the argument
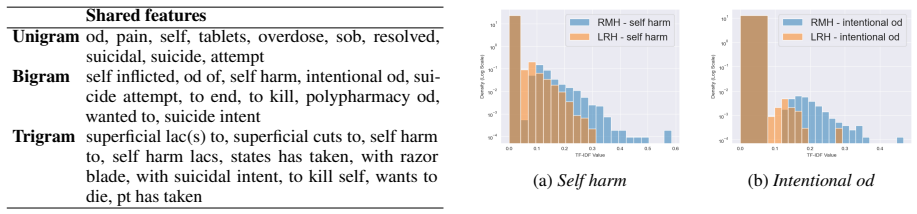
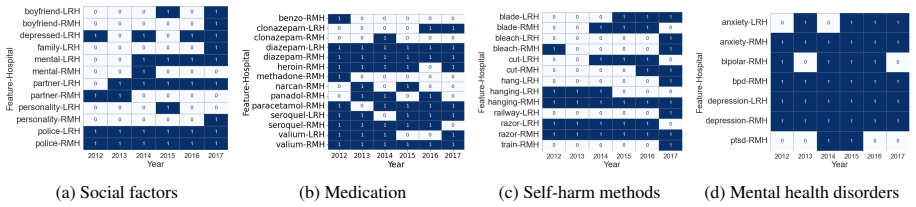
Comparison of lexical characteristics, predictive feature importance, and salient topics between triage notes from two different hospitals.
If this is right
- Documentation of self-harm shows site-specific lexical variations despite shared core themes.
- Feature importance for self-harm prediction shifts across hospital sites.
- Cross-site model performance declines due to these documentation differences.
- Analysis of such variations can guide improvements in model generalisability.
Where Pith is reading between the lines
- If documentation styles differ systematically, then models may benefit from techniques that normalize lexical features across sites.
- Similar generalization issues likely arise in other clinical NLP applications involving free-text notes.
- Efforts to standardize triage note formats could mitigate performance drops in multi-site deployments.
Load-bearing premise
That the observed differences in lexical expression and feature importance between the two hospitals primarily explain the drop in cross-site model performance rather than other unmeasured factors like patient demographics or note characteristics.
What would settle it
Evaluating models on notes rewritten to match the lexical patterns of the other hospital while preserving clinical content; if performance remains low, the claim that lexical variation drives the drop would be challenged.
Figures



read the original abstract
Self-harm presentations to emergency departments (EDs) are strongly associated with higher suicide risk. NLP models have shown robust performance in detecting self-harm from triage notes within single hospitals, yet performance often declines across institutions. To examine potential causes, we compare ED triage notes from two hospitals by analyzing lexical characteristics, highly associated predictive features, and salient topics. Our results reveal variation in lexical expression and feature importance related to self-harm across hospitals, despite consistent core themes such as self-poisoning and self-injury. These documentation differences are associated with reduced cross-site performance. Our findings provide insight into how institutional variation affects the identification of self-harm in clinical text and highlight potential methods to improve model generalisability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper compares ED triage notes from two hospitals to investigate why self-harm detection NLP models generalize poorly across sites. It analyzes lexical characteristics, highly associated predictive features, and salient topics, finding variation in lexical expression and feature importance related to self-harm (despite consistent core themes such as self-poisoning and self-injury) and associates these documentation differences with reduced cross-site performance.
Significance. If the attribution to lexical/semantic variation holds after appropriate controls, the work provides useful insight into institutional factors affecting clinical NLP generalizability and could guide domain-adaptation approaches. The direct two-site comparison is a strength, but the current evidence base is limited.
major comments (2)
- [Abstract] Abstract and Results: The central claim states that documentation differences 'are associated with reduced cross-site performance,' yet no quantitative results, statistical tests, effect sizes, or performance metrics (e.g., F1 deltas, AUC drops) are supplied to support the association.
- [Methods] Methods: The analysis compares notes from two independent sites but reports no matching, stratification, or regression adjustment for confounders such as note length, patient demographics, triage acuity, or label distributions; without these, the attribution of performance drop to lexical/semantic variation alone is under-supported.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address the major comments point by point below, outlining planned revisions where appropriate.
read point-by-point responses
-
Referee: [Abstract] Abstract and Results: The central claim states that documentation differences 'are associated with reduced cross-site performance,' yet no quantitative results, statistical tests, effect sizes, or performance metrics (e.g., F1 deltas, AUC drops) are supplied to support the association.
Authors: We agree that the abstract would benefit from explicit quantitative support for the association. The results section includes cross-site performance comparisons, but these are not highlighted in the abstract. In the revision we will add specific metrics (e.g., within-site vs. cross-site F1 and AUC values with deltas) and note any statistical comparisons to directly link the observed lexical/semantic differences to the performance drop. revision: yes
-
Referee: [Methods] Methods: The analysis compares notes from two independent sites but reports no matching, stratification, or regression adjustment for confounders such as note length, patient demographics, triage acuity, or label distributions; without these, the attribution of performance drop to lexical/semantic variation alone is under-supported.
Authors: We acknowledge that explicit controls would strengthen causal attribution. We will add stratification by note length and label distributions in the revised methods and results. Comparable patient demographics and triage acuity data are not available in matched form across sites, so we will instead discuss this as a limitation and its implications for interpretation rather than performing unsupported adjustments. revision: partial
Circularity Check
No circularity: empirical comparison of independent hospital notes
full rationale
The paper conducts direct lexical, feature, and topic analysis on triage notes drawn from two separate hospitals. No equations, fitted parameters, or derivations are described that reduce to their own inputs by construction. The central finding (lexical/semantic variation associated with cross-site performance drop) rests on observable differences between independent data sources rather than self-definition, renamed fits, or load-bearing self-citations. This is a standard empirical NLP study whose claims are externally falsifiable via the raw notes themselves.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
European conference on information retrieval , pages=
Exploration of a threshold for similarity based on uncertainty in word embedding , author=. European conference on information retrieval , pages=. 2017 , organization=
2017
-
[2]
JAMIA open , volume=
Rethinking domain adaptation for machine learning over clinical language , author=. JAMIA open , volume=. 2020 , publisher=
2020
-
[3]
Journal of the American Medical Informatics Association , volume=
Detection of self-harm and suicidal ideation in emergency department triage notes , author=. Journal of the American Medical Informatics Association , volume=. 2022 , publisher=
2022
-
[4]
npj Digital Medicine , volume=
Generalization—a key challenge for responsible AI in patient-facing clinical applications , author=. npj Digital Medicine , volume=. 2024 , publisher=
2024
-
[5]
Critical Care Explorations , volume=
Generalization in clinical prediction models: the blessing and curse of measurement indicator variables , author=. Critical Care Explorations , volume=. 2021 , publisher=
2021
-
[6]
Australasian emergency care , volume=
Characteristics of self-harm presentations to the emergency department of the Royal Melbourne Hospital, 2012--2019: data from the self-harm monitoring system for Victoria , author=. Australasian emergency care , volume=. 2023 , publisher=
2012
-
[7]
JMIR medical informatics , volume=
Identifying and predicting intentional self-harm in electronic health record clinical notes: deep learning approach , author=. JMIR medical informatics , volume=. 2020 , publisher=
2020
-
[8]
PLoS one , volume=
Developing a natural language processing tool to identify perinatal self-harm in electronic healthcare records , author=. PLoS one , volume=. 2021 , publisher=
2021
-
[9]
JAMIA open , volume=
A common data model for the standardization of intensive care unit medication features , author=. JAMIA open , volume=. 2024 , publisher=
2024
-
[10]
PLoS one , volume=
Predicting self-harm within six months after initial presentation to youth mental health services: A machine learning study , author=. PLoS one , volume=. 2020 , publisher=
2020
-
[12]
2025 , note =
HuggingFace , title =. 2025 , note =
2025
-
[13]
Karyn Ayre, Andr \'e Bittar, Joyce Kam, Somain Verma, Louise M Howard, and Rina Dutta. 2021. Developing a natural language processing tool to identify perinatal self-harm in electronic healthcare records. PLoS one, 16(8):e0253809
2021
-
[14]
Joseph Futoma, Morgan Simons, Finale Doshi-Velez, and Rishikesan Kamaleswaran. 2021. Generalization in clinical prediction models: the blessing and curse of measurement indicator variables. Critical Care Explorations, 3(7):e0453
2021
-
[15]
Lea Goetz, Nabeel Seedat, Robert Vandersluis, and Mihaela van der Schaar. 2024. Generalization—a key challenge for responsible ai in patient-facing clinical applications. npj Digital Medicine, 7(1):126
2024
-
[16]
Maarten Grootendorst. 2022. Bertopic: Neural topic modeling with a class-based tf-idf procedure. arXiv preprint arXiv:2203.05794
Pith/arXiv arXiv 2022
-
[17]
HuggingFace. 2025. P retrained M odels --- S entence T ransformers documentation --- sbert.net. https://www.sbert.net/docs/sentence_transformer/pretrained_models.html. [Accessed 21-03-2025]
2025
-
[18]
Frank Iorfino, Nicholas Ho, Joanne S Carpenter, Shane P Cross, Tracey A Davenport, Daniel F Hermens, Hannah Yee, Alissa Nichles, Natalia Zmicerevska, Adam Guastella, et al. 2020. Predicting self-harm within six months after initial presentation to youth mental health services: A machine learning study. PLoS one, 15(12):e0243467
2020
-
[19]
Egoitz Laparra, Steven Bethard, and Timothy A Miller. 2020. https://doi.org/10.1093/jamiaopen/ooaa010 Rethinking domain adaptation for machine learning over clinical language . JAMIA open, 3(2):146--150
-
[20]
Jihad S Obeid, Jennifer Dahne, Sean Christensen, Samuel Howard, Tami Crawford, Lewis J Frey, Tracy Stecker, and Brian E Bunnell. 2020. Identifying and predicting intentional self-harm in electronic health record clinical notes: deep learning approach. JMIR medical informatics, 8(7):e17784
2020
-
[21]
Vlada Rozova, Katrina Witt, Jo Robinson, Yan Li, and Karin Verspoor. 2022. Detection of self-harm and suicidal ideation in emergency department triage notes. Journal of the American Medical Informatics Association, 29(3):472--480
2022
-
[22]
Andrea Sikora, Kelli Keats, David J Murphy, John W Devlin, Susan E Smith, Brian Murray, Mitchell S Buckley, Sandra Rowe, Lindsey Coppiano, and Rishikesan Kamaleswaran. 2024. A common data model for the standardization of intensive care unit medication features. JAMIA open, 7(2):ooae033
2024
-
[23]
Katrina Witt, Gowri Rajaram, Michelle Lamblin, Jonathan Knott, Angela Dean, Matthew J Spittal, Greg Carter, Andrew Page, Jane Pirkis, and Jo Robinson. 2023. Characteristics of self-harm presentations to the emergency department of the royal melbourne hospital, 2012--2019: data from the self-harm monitoring system for victoria. Australasian emergency care,...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.