Density-Aware Translation of Spurious Correlations in Zero-Shot VLMs
Pith reviewed 2026-06-28 14:58 UTC · model grok-4.3
The pith
Density-aware translation mitigates spurious correlations in zero-shot VLMs by rescaling similarities using embedding density.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
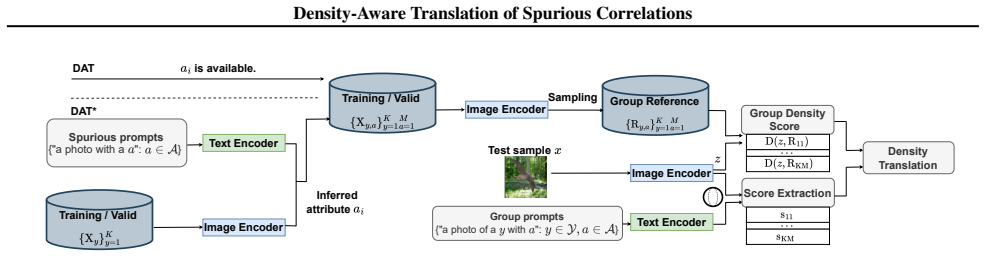
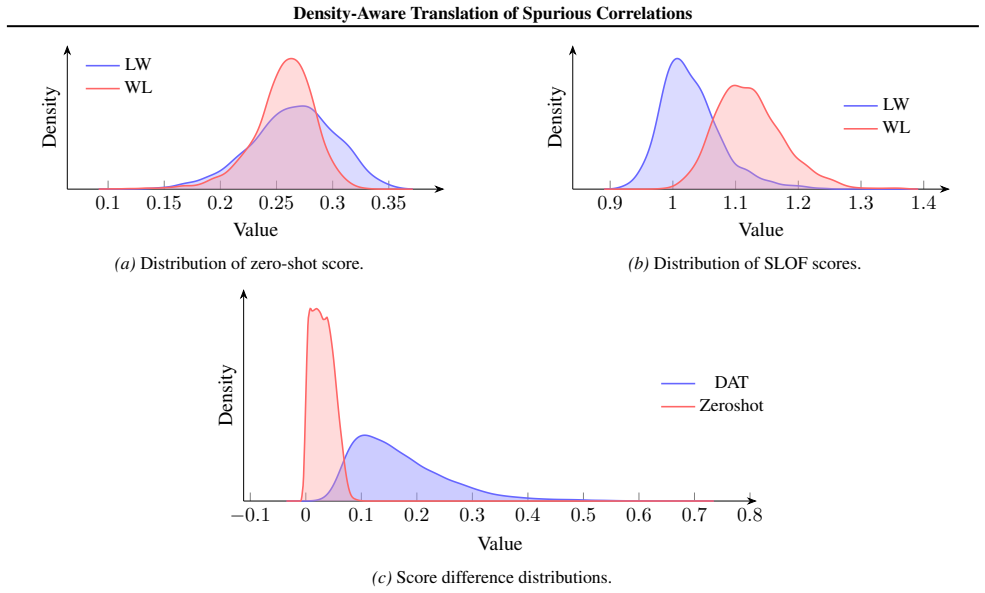
Density-Aware Translation refines image-text similarity scores using a local geometric density term derived from group reference sets. This corrects the uneven alignment in CLIP embeddings, where the modality gap and anisotropic shell amplify spurious correlations while marginalizing rare but meaningful cues. The approach suppresses overconfident scores in low-density regions, leading to more reliable zero-shot classification.
What carries the argument
Density-Aware Translation (DAT), which applies a relative density-based rescaling to image-text similarities to counteract the effects of anisotropic embedding distribution.
If this is right
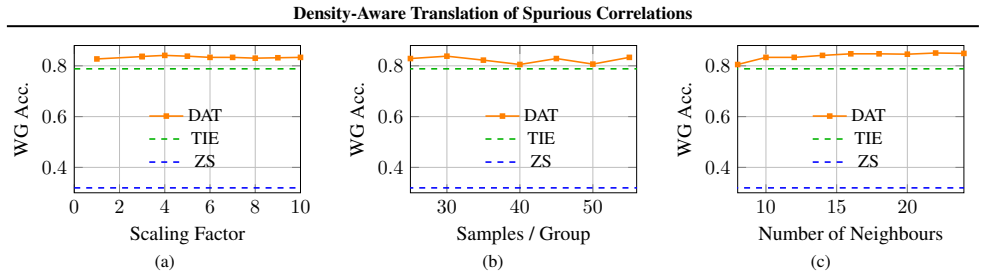
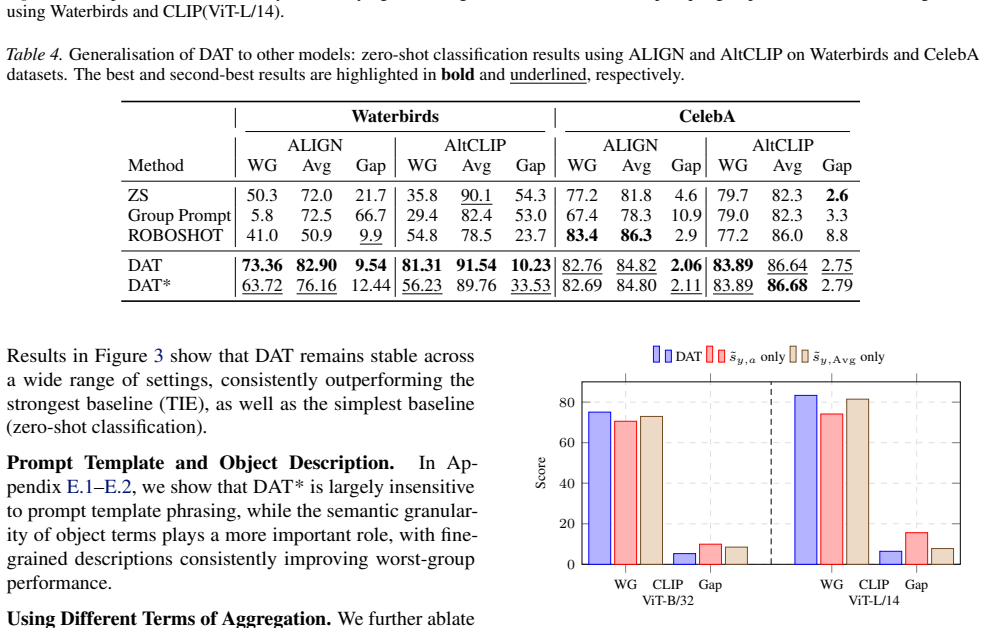
- Improves worst-group accuracy on benchmark datasets
- Also improves average accuracy
- Serves as a calibration mechanism without requiring fine-tuning or prompt engineering
- Preserves advantages of pre-trained multimodal models
Where Pith is reading between the lines
- The method could apply to other embedding-based models exhibiting similar geometric biases
- Density measures might help identify which patterns are over-represented in training data
- Combining DAT with existing debiasing techniques could yield additive benefits
Load-bearing premise
CLIP embeddings exhibit a modality gap and lie on an anisotropic shell, creating uneven alignment that amplifies spurious correlations.
What would settle it
Measuring the distribution of CLIP embeddings on a new dataset and finding it does not form an anisotropic shell with clustered common patterns, or observing that DAT does not improve accuracy on such data.
Figures

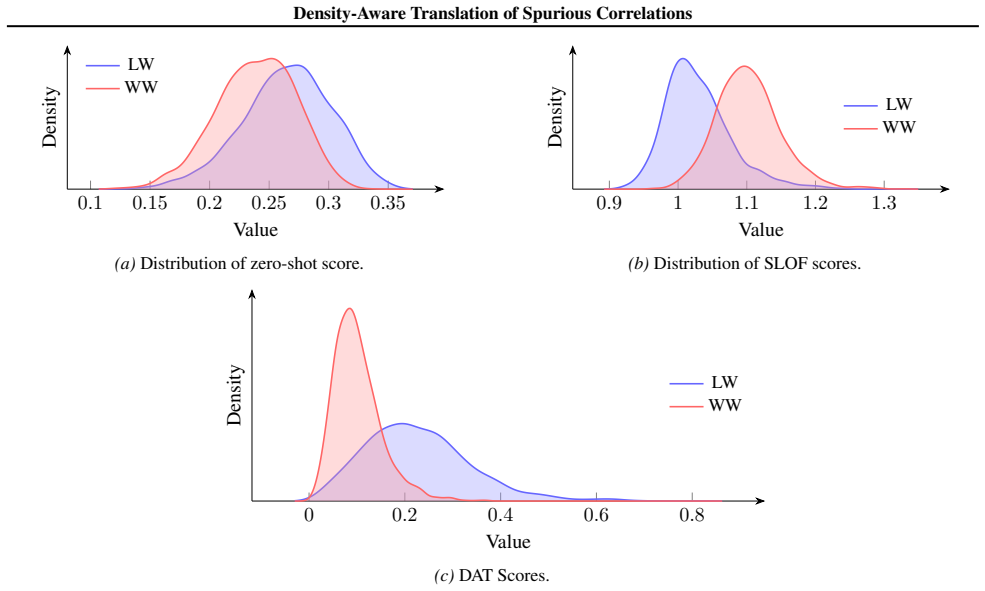
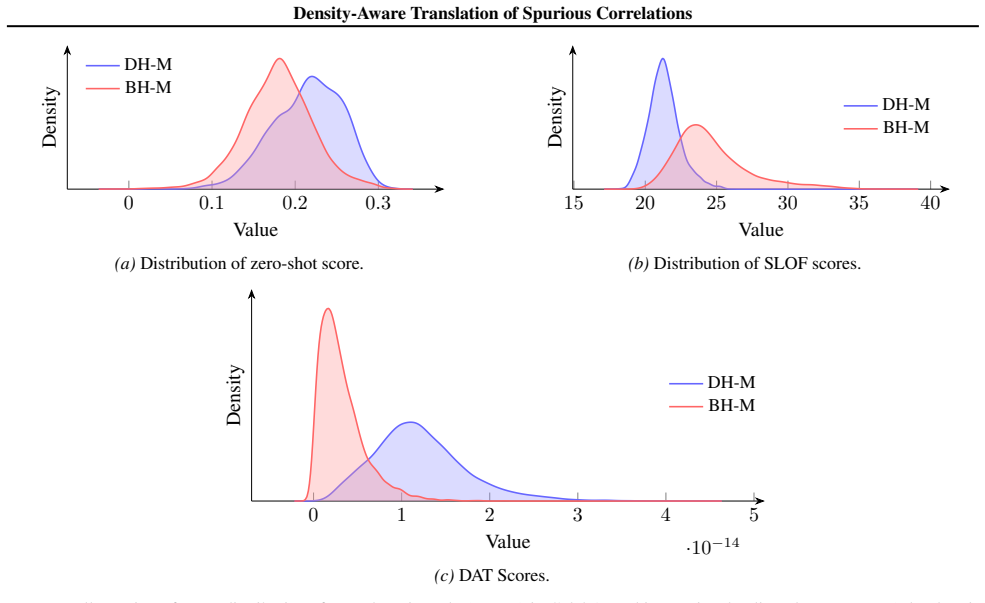
read the original abstract
Vision-Language models (VLMs), such as CLIP, achieve powerful zero-shot classification. However, their predictions remain sensitive to spurious correlations, where contextual cues dominate over semantic content. Earlier solutions typically rely on fine-tuning or prompt engineering, which either undermine the advantages of pre-trained models or are prone to hallucination. In this work, we propose Density-Aware Translation (DAT) that refines image-text similarity scores using a local geometric density term derived from group reference sets. Our approach is motivated by the phenomenon that CLIP embeddings exhibit a modality gap and lie on an anisotropic shell in the feature space: common patterns cluster near the mean, while rare patterns are pushed outward. This geometry creates uneven alignment, where spurious correlations are amplified while semantically meaningful but rare cues are marginalised. To address this, we employ a relative measure to rescale similarities based on embedding density, suppressing overconfident scores in diffuse regions while preserving dense, semantically consistent matches. Experimental results on benchmark datasets demonstrate consistent improvements in worst-group and average accuracy, highlighting density-aware translation as a simple and effective calibration mechanism for reliable zero-shot classification using multimodal models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Density-Aware Translation (DAT), a post-hoc calibration for zero-shot VLMs such as CLIP. DAT rescales image-text similarity scores via a local geometric density term computed from group reference sets, motivated by the claim that CLIP embeddings occupy an anisotropic shell with a modality gap that amplifies spurious correlations. The central claim is that this yields consistent gains in both worst-group and average accuracy on benchmark datasets while remaining a simple, training-free procedure.
Significance. If DAT can be shown to operate without group-labeled data, the result would supply a lightweight, geometry-driven calibration that improves robustness of pre-trained multimodal models without fine-tuning or prompt engineering.
major comments (1)
- [Abstract] Abstract: The density term is stated to be 'derived from group reference sets,' yet the paper presents DAT as a zero-shot method. In the spurious-correlation setting, group reference sets are standardly formed from joint (class, spurious-attribute) labels. The manuscript provides no account of how these sets can be assembled from purely unlabeled or class-only data while still estimating the required local densities; this data requirement directly undercuts the headline zero-shot claim and is therefore load-bearing.
minor comments (1)
- [Abstract] Abstract: The claim of 'consistent improvements' is made without any numerical values, dataset names, or baseline comparisons; the full manuscript must supply these quantitative results for the experimental claim to be evaluable.
Simulated Author's Rebuttal
We appreciate the referee's careful reading and the opportunity to clarify the data requirements of our proposed method. We respond to the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The density term is stated to be 'derived from group reference sets,' yet the paper presents DAT as a zero-shot method. In the spurious-correlation setting, group reference sets are standardly formed from joint (class, spurious-attribute) labels. The manuscript provides no account of how these sets can be assembled from purely unlabeled or class-only data while still estimating the required local densities; this data requirement directly undercuts the headline zero-shot claim and is therefore load-bearing.
Authors: We agree that the abstract's phrasing could be misinterpreted as implying a fully unsupervised or class-label-only setting. To address this, we will revise the abstract to explicitly state that DAT is a training-free post-hoc calibration technique that utilizes group reference sets constructed from joint (class, spurious attribute) labels. This is consistent with standard evaluation protocols in the spurious correlation literature, where such labels are available for defining groups but no model training occurs. The 'zero-shot' designation in the title and abstract emphasizes the lack of fine-tuning on the target task, distinguishing our approach from methods that require gradient updates or prompt optimization. We will also expand the method section to include a discussion on the minimal data needed for reference sets and explore whether class-only labels suffice for density estimation in some cases, though empirical results suggest group labels improve performance. This clarification will strengthen rather than undercut the contribution by making the assumptions transparent. revision: yes
Circularity Check
No circularity; derivation introduces independent density rescaling
full rationale
The abstract describes DAT as refining similarity scores via a local geometric density term computed from group reference sets, motivated by the observed anisotropic shell geometry of CLIP embeddings. No equations, self-citations, or steps are exhibited that define the output similarity or accuracy gain as equivalent to the input density by construction, nor is any fitted parameter relabeled as a prediction. The method adds an explicit rescaling step whose grounding is the external geometric observation rather than tautological re-use of the target result. Concerns about group labels versus zero-shot status are assumption or data-requirement issues, not reductions of the claimed derivation to its own inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- density scaling factor
axioms (1)
- domain assumption CLIP embeddings lie on an anisotropic shell with common patterns clustering near the mean
Reference graph
Works this paper leans on
-
[1]
Proceedings of the International Conference on Machine Learning (ICML) , year=
Koh, Pang Wei and Sagawa, Shiori and Marklund, Henrik and Xie, Sang Michael and Zhang, Marvin and Balsubramani, Akshay and Hu, Weihua and Yasunaga, Michihiro and Phillips, Richard and Gao, Irena and others , pages=. Proceedings of the International Conference on Machine Learning (ICML) , year=
-
[2]
Proceedings of the International Conference on Learning Representations (ICLR) , year=
Distributionally robust neural networks for group shifts: On the importance of regularization for worst-case generalization , author=. Proceedings of the International Conference on Learning Representations (ICLR) , year=
-
[3]
Proceedings of the IEEE International Conference on Computer Vision (ICCV) , pages=
Deep learning face attributes in the wild , author=. Proceedings of the IEEE International Conference on Computer Vision (ICCV) , pages=
-
[4]
Skin lesion analysis toward Melanoma detection 2018: A challenge hosted by the international skin imaging collaboration (
Codella, Noel C F and Rotemberg, Veronica and Tschandl, Philipp and Celebi, M Emre and Dusza, Stephen and Gutman, David and Helba, Brian and Kalloo, Aadi and Liopyris, Konstantinos and Marchetti, Michael and others , journal=. Skin lesion analysis toward Melanoma detection 2018: A challenge hosted by the international skin imaging collaboration (
2018
-
[5]
Cohen, Joseph Paul and Morrison, Paul and Dao, Lan and Roth, Karsten and Duong, Tim and Ghassemi, Marzyeh and others , journal=
-
[6]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Functional map of the world , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[7]
Proceedings of the International Conference on Machine Learning (ICML) , pages=
What are Bayesian neural network posteriors really like? , author=. Proceedings of the International Conference on Machine Learning (ICML) , pages=
-
[8]
Proceedings of the International Conference on Machine Learning (ICML) , pages =
Environment inference for invariant learning , author=. Proceedings of the International Conference on Machine Learning (ICML) , pages =
-
[9]
Proceedings of the IEEE International Conference on Computer Vision (ICCV) , pages=
Linear spaces of meanings: compositional structures in vision-language models , author=. Proceedings of the IEEE International Conference on Computer Vision (ICCV) , pages=
-
[10]
Perception
Bang An and Sicheng Zhu and Michael-Andrei Panaitescu-Liess and Chaithanya Kumar Mummadi and Furong Huang , booktitle=. Perception
-
[11]
Debiasing vision- language models via biased prompts.arXiv preprint arXiv:2302.00070, 2023
Debiasing vision-language models via biased prompts , author=. arXiv preprint arXiv:2302.00070 , year=
-
[12]
Proceedings of the International Conference on Learning Representations (ICLR) , year=
Zero-shot robustification of zero-shot models , author=. Proceedings of the International Conference on Learning Representations (ICLR) , year=
-
[13]
Proceedings of the International Conference on Machine Learning (ICML) , pages=
Learning transferable visual models from natural language supervision , author=. Proceedings of the International Conference on Machine Learning (ICML) , pages=
-
[14]
Understanding transferable representation learning and zero-shot transfer in
Chen, Zixiang and Deng, Yihe and Li, Yuanzhi and Gu, Quanquan , booktitle=. Understanding transferable representation learning and zero-shot transfer in
-
[15]
Subramanian, Sanjay and Merrill, William and Darrell, Trevor and Gardner, Matt and Singh, Sameer and Rohrbach, Anna , booktitle=
-
[16]
Sain, Aneeshan and Bhunia, Ayan Kumar and Chowdhury, Pinaki Nath and Koley, Subhadeep and Xiang, Tao and Song, Yi-Zhe , booktitle=
-
[17]
Online zero-shot classification with
Qian, Qi and Hu, Juhua , booktitle=. Online zero-shot classification with
-
[18]
PLoS Medicine , volume=
Variable generalization performance of a deep learning model to detect pneumonia in chest radiographs: A cross-sectional study , author=. PLoS Medicine , volume=. 2018 , publisher=
2018
-
[19]
and Janizek, Joseph D
DeGrave, Alex J. and Janizek, Joseph D. and Lee, Su-In , journal=. 2021 , publisher=
2021
-
[20]
On the Opportunities and Risks of Foundation Models
On the opportunities and risks of foundation models , author=. arXiv preprint arXiv:2108.07258 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
The double-ellipsoid geometry of
Levi, Meir Yossef and Gilboa, Guy , booktitle=. The double-ellipsoid geometry of
-
[22]
Findings of the Association for Computational Linguistics: EMNLP 2025
Evaluating fairness in large vision-language models across diverse demographic attributes and prompts , author=. Findings of the Association for Computational Linguistics: EMNLP 2025
2025
-
[23]
Abbasi, Reza and Nazari, Ali and Sefid, Aminreza and Banayeeanzade, Mohammadali and Rohban, Mohammad Hossein and Baghshah, Mahdieh Soleymani , booktitle=
-
[24]
A survey on hallucination in Large Language Models: Principles, taxonomy, challenges, and open questions , volume=
Huang, Lei and Yu, Weijiang and Ma, Weitao and Zhong, Weihong and Feng, Zhangyin and Wang, Haotian and Chen, Qianglong and Peng, Weihua and Feng, Xiaocheng and Qin, Bing and Liu, Ting , year=. A survey on hallucination in Large Language Models: Principles, taxonomy, challenges, and open questions , volume=. ACM Transactions on Information Systems , publisher=
-
[25]
Molahasani, Mahdiyar and Motamedi, Azadeh and Greenspan, Michael and Kim, Il-Min and Etemad, Ali , booktitle=
-
[26]
Proceedings of the International Conference on Machine Learning (ICML) , pages=
Mitigating spurious correlations in multi-modal models during fine-tuning , author=. Proceedings of the International Conference on Machine Learning (ICML) , pages=
-
[27]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Finetune like you pretrain: Improved finetuning of zero-shot vision models , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[28]
Varma, Maya and Delbrouck, Jean-Benoit and Chen, Zhihong and Chaudhari, Akshay and Langlotz, Curtis , booktitle=
-
[29]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Contrastive adapters for foundation model group robustness , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[30]
Proceedings of the International Conference on Learning Representations (ICLR) , year=
Mitigating spurious correlations in zero-shot multimodal models , author=. Proceedings of the International Conference on Learning Representations (ICLR) , year=
-
[31]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Mind the gap: Understanding the modality gap in multi-modal contrastive representation learning , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[32]
Clustering on the unit hypersphere using von
Banerjee, Arindam and Dhillon, Inderjit S and Ghosh, Joydeep and Sra, Suvrit and Ridgeway, Greg , journal=. Clustering on the unit hypersphere using von
-
[33]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
Improving zero-shot generalization and robustness of multi-modal models , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , pages=
-
[34]
Invariant risk minimization , author=. arXiv preprint arXiv:1907.02893 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[35]
Proceedings of the International Conference on Machine Learning (ICML) , pages=
Amend to alignment: Decoupled prompt tuning for mitigating spurious correlation in vision-language models , author=. Proceedings of the International Conference on Machine Learning (ICML) , pages=
-
[36]
Proceedings of the AAAI Conference on Artificial Intelligence , pages=
Spurious feature eraser: Stabilizing test-time adaptation for vision-language foundation model , author=. Proceedings of the AAAI Conference on Artificial Intelligence , pages=
-
[37]
Sepehr Dehdashtian and Lan Wang and Vishnu Boddeti , booktitle=. Fairer
-
[38]
arXiv preprint arXiv:2403.07888 , year=
Cross-modality debiasing: using language to mitigate sub-population shifts in imaging , author=. arXiv preprint arXiv:2403.07888 , year=
-
[39]
Nashed and Sabyasachi Sahoo and Liam Paull , year=
Mahtab Sandhu and Yann Batiste Pequignot and Samer B. Nashed and Sabyasachi Sahoo and Liam Paull , year=
-
[40]
Proceedings of the ACM SIGMOD International Conference on Management of Data , pages=
Breunig, Markus M and Kriegel, Hans-Peter and Ng, Raymond T and Sander, J. Proceedings of the ACM SIGMOD International Conference on Management of Data , pages=
-
[41]
Pacific-Asia Conference on Knowledge Discovery and Data Mining , pages=
Ranking outliers using symmetric neighborhood relationship , author=. Pacific-Asia Conference on Knowledge Discovery and Data Mining , pages=. 2006 , organization=
2006
-
[42]
Data Mining and Knowledge Discovery , volume=
On the evaluation of unsupervised outlier detection: measures, datasets, and an empirical study , author=. Data Mining and Knowledge Discovery , volume=. 2016 , publisher=
2016
-
[43]
Statistical Analysis and Data Mining: The ASA Data Science Journal , volume=
A survey on unsupervised outlier detection in high-dimensional numerical data , author=. Statistical Analysis and Data Mining: The ASA Data Science Journal , volume=. 2012 , publisher=
2012
-
[44]
The Annals of Mathematical Statistics , volume=
A nonparametric estimate of a multivariate density function , author=. The Annals of Mathematical Statistics , volume=. 1965 , publisher=
1965
-
[45]
2015 , publisher=
Lectures on the nearest neighbor method , author=. 2015 , publisher=
2015
-
[46]
Proceedings of the Conference on Uncertainty in Artificial Intelligence (UAI) , pages =
Super-samples from kernel herding , author=. Proceedings of the Conference on Uncertainty in Artificial Intelligence (UAI) , pages =
-
[47]
Data Mining and Knowledge Discovery , volume=
Local outlier detection reconsidered: a generalized view on locality with applications to spatial, video, and network outlier detection , author=. Data Mining and Knowledge Discovery , volume=. 2014 , publisher=
2014
-
[48]
Kent, John T , journal=. The. 1982 , publisher=
1982
-
[49]
2009 , publisher=
Directional statistics , author=. 2009 , publisher=
2009
-
[50]
A short note on parameter approximation for von
Sra, Suvrit , journal=. A short note on parameter approximation for von. 2012 , publisher=
2012
-
[51]
Saddlepoint approximations for the Bingham and
Kume, Alfred and Wood, Andrew TA , journal=. Saddlepoint approximations for the Bingham and. 2005 , publisher=
2005
-
[52]
Zhang, Sheng and Xu, Yanbo and Usuyama, Naoto and Xu, Hanwen and Bagga, Jaspreet and Tinn, Robert and Preston, Sam and Rao, Rajesh and Wei, Mu and Valluri, Naveen and others , journal=
-
[53]
2023 , howpublished =
OpenAI , title =. 2023 , howpublished =
2023
-
[54]
Rebuffi, Sylvestre-Alvise and Kolesnikov, Alexander and Sperl, Georg and Lampert, Christoph H , booktitle=
-
[55]
Intrinsic statistics on
Pennec, Xavier , journal=. Intrinsic statistics on. 2006 , publisher=
2006
-
[56]
Proceedings of the International Conference on Machine Learning (ICML) , pages =
Discover and cure: Concept-aware mitigation of spurious correlation , author=. Proceedings of the International Conference on Machine Learning (ICML) , pages =
-
[57]
Fellbaum, Christiane , year=
-
[58]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Maximum likelihood estimation of intrinsic dimension , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[59]
Data Mining and Knowledge Discovery , volume=
Extreme-value-theoretic estimation of local intrinsic dimensionality , author=. Data Mining and Knowledge Discovery , volume=. 2018 , publisher=
2018
-
[60]
Proceedings of the SIAM International Conference on Data Mining (SDM) , pages=
Dimensionality-aware outlier detection , author=. Proceedings of the SIAM International Conference on Data Mining (SDM) , pages=. 2024 , organization=
2024
-
[61]
ACM Transactions on Intelligent Systems and Technology (TIST) , volume=
A survey of zero-shot learning: Settings, methods, and applications , author=. ACM Transactions on Intelligent Systems and Technology (TIST) , volume=. 2019 , publisher=
2019
-
[62]
Advances in Neural Information Processing Systems (NeurIPS) , volume=
Zero-shot learning with semantic output codes , author=. Advances in Neural Information Processing Systems (NeurIPS) , volume=
-
[63]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
Attribute-based classification for zero-shot visual object categorization , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 2013 , publisher=
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.