MoRE: A Mixture-of-Experts-Based Task-Adaptive End-to-End Network for Multimodal MRI Reconstruction
Pith reviewed 2026-06-28 12:33 UTC · model grok-4.3
The pith
A mixture-of-experts module added to a variational network lets one model reconstruct multiple MRI contrasts with stable quality and limited extra compute.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
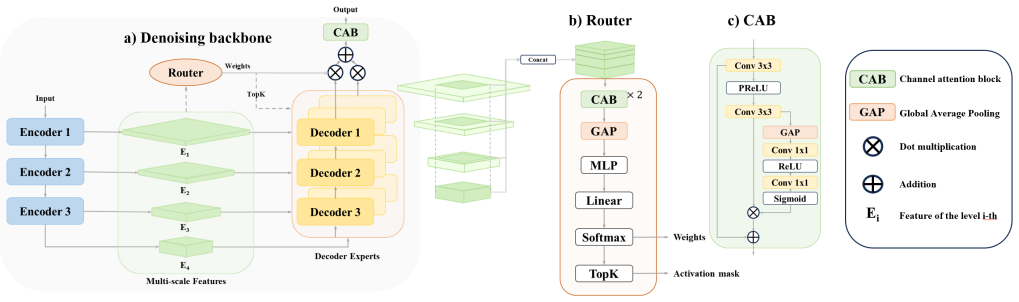
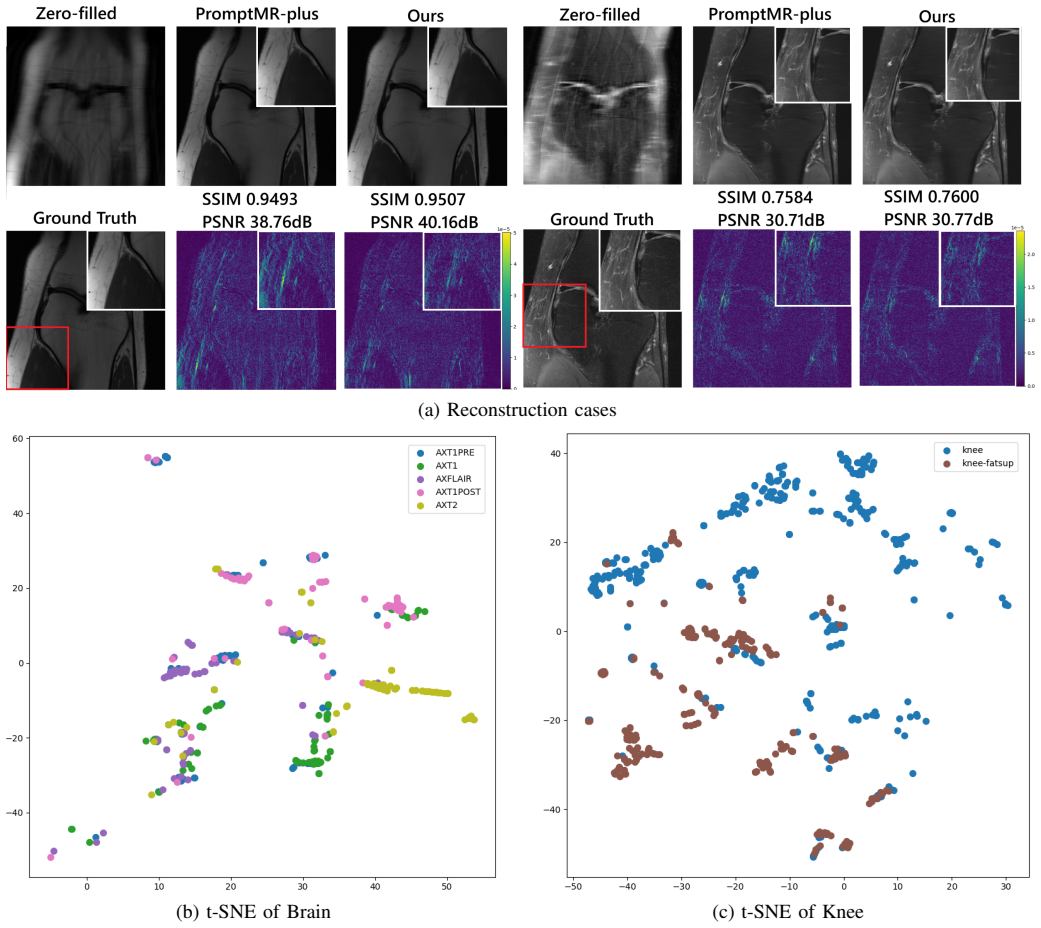
MoRE integrates a sparsely activated mixture-of-experts module into an end-to-end variational network for multimodal MRI reconstruction. The module couples a shared encoder with sample-wise unsupervised routing that activates only a minimal subset of expert decoders, while strictly preserving physics-based data consistency. On the fastMRI multi-coil brain and knee datasets under 8x undersampling, the network produces highly stable SSIM and PSNR scores across contrasts; routing embeddings visualized by t-SNE show modality-aware expert specialization, and the sparse conditional computation keeps architectural overhead modest.
What carries the argument
The MoRE module, which uses unsupervised sample-wise routing from a shared encoder to activate a minimal subset of expert decoders inside a variational network while preserving data consistency.
If this is right
- Stable SSIM and PSNR performance holds across multi-contrast datasets at 8x undersampling.
- Sparse conditional computation keeps architectural overhead modest.
- t-SNE visualization of routing embeddings reveals interpretable modality-aware expert specialization.
- A single network can generalize across diverse anatomies and contrasts without proportional compute growth.
Where Pith is reading between the lines
- If the routing generalizes, clinical sites could deploy one model instead of separate ones for each contrast.
- The same unsupervised routing idea might apply to other reconstruction tasks such as CT or ultrasound if similar data-consistency layers are present.
- The modest overhead opens the possibility of running the network on edge hardware for varied scan protocols.
Load-bearing premise
The unsupervised sample-wise routing mechanism can reliably pick the right expert decoders for new inputs without any task labels or explicit supervision.
What would settle it
A held-out test set of a new contrast or anatomy where SSIM or PSNR drops sharply compared with the reported multi-contrast stability, or where the routing embeddings show no distinct expert specialization.
Figures
read the original abstract
Although accelerated MRI reconstruction has advanced rapidly through end-to-end learning, deploying a single unified network that generalizes across diverse anatomies and contrasts under constrained computational resources remains challenging. In this paper, we introduce MoRE, a sparsely activated mixture-of-experts (MoE) module integrated into an end-to-end variational network. MoRE couples a shared encoder with sample-wise, unsupervised routing to activate a minimal subset of expert decoders while strictly preserving physics-based data consistency. Evaluated on the fastMRI multi-coil brain and knee datasets under 8x undersampling, MoRE achieves highly stable SSIM and PSNR performance across multi-contrast datasets. Furthermore, t-SNE visualization of the routing embeddings reveals interpretable, modality-aware expert specialization. The sparse conditional computation mechanism ensures that the architectural overhead remains modest. These results demonstrate that MoE-style capacity scaling can significantly enhance general-purpose MRI reconstruction without requiring proportional increases in computational power.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MoRE, a sparsely activated mixture-of-experts (MoE) module integrated into an end-to-end variational network for multimodal MRI reconstruction. It uses a shared encoder with sample-wise unsupervised routing to activate a minimal subset of expert decoders while preserving physics-based data consistency. On fastMRI multi-coil brain and knee datasets at 8x undersampling, the method is reported to achieve highly stable SSIM and PSNR across multi-contrast data, with t-SNE visualizations of routing embeddings showing modality-aware expert specialization and only modest architectural overhead.
Significance. If the unsupervised routing mechanism reliably drives the claimed stability and generalization, the work would demonstrate a practical way to scale network capacity for MRI reconstruction without proportional compute increases, addressing a key deployment challenge for unified models across anatomies and contrasts.
major comments (2)
- [Abstract] Abstract: the headline claim of 'highly stable SSIM and PSNR performance across multi-contrast datasets' is attributed to the MoE with unsupervised sample-wise routing, yet the only supporting evidence referenced is post-hoc t-SNE visualization of routing embeddings; no ablation studies, routing-accuracy metrics, or failure-case analysis are described that would establish whether the routing (rather than the shared encoder or variational backbone) is responsible for the stability.
- [Abstract] Abstract: the assertion that 'the sparse conditional computation mechanism ensures that the architectural overhead remains modest' and enables 'capacity scaling without requiring proportional increases in computational power' lacks quantitative comparison to non-MoE baselines or measurements of actual FLOPs/latency under the reported routing sparsity; without these, the efficiency claim cannot be evaluated.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive feedback on our manuscript. We address the two major comments below regarding the abstract claims. We agree that additional quantitative evidence would strengthen the presentation and will incorporate the requested analyses in the revised version.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claim of 'highly stable SSIM and PSNR performance across multi-contrast datasets' is attributed to the MoE with unsupervised sample-wise routing, yet the only supporting evidence referenced is post-hoc t-SNE visualization of routing embeddings; no ablation studies, routing-accuracy metrics, or failure-case analysis are described that would establish whether the routing (rather than the shared encoder or variational backbone) is responsible for the stability.
Authors: The abstract summarizes the key empirical observation of stability on fastMRI brain and knee data at 8x acceleration, with the t-SNE analysis provided as supporting evidence of modality-aware specialization. The full manuscript reports consistent SSIM/PSNR across contrasts for the complete MoRE model. We agree that isolating the contribution of the unsupervised routing versus the shared encoder or variational backbone requires explicit ablations. In the revision we will add (i) a direct comparison to a non-MoE variational baseline with identical encoder, (ii) routing-accuracy metrics where ground-truth modality labels are available, and (iii) a brief failure-case discussion. These additions will clarify the role of the routing mechanism. revision: yes
-
Referee: [Abstract] Abstract: the assertion that 'the sparse conditional computation mechanism ensures that the architectural overhead remains modest' and enables 'capacity scaling without requiring proportional increases in computational power' lacks quantitative comparison to non-MoE baselines or measurements of actual FLOPs/latency under the reported routing sparsity; without these, the efficiency claim cannot be evaluated.
Authors: The abstract states that the sparse activation keeps overhead modest, based on the design choice of activating only a small subset of experts per sample. The manuscript does not currently include explicit FLOPs or latency tables comparing MoRE to dense counterparts. We will add these measurements in the revision, reporting both theoretical FLOPs under the observed sparsity level and wall-clock inference times on the same hardware used for the non-MoE baselines. This will allow direct evaluation of the claimed efficiency benefit. revision: yes
Circularity Check
No significant circularity; empirical claims rest on external dataset evaluations
full rationale
The paper introduces an MoE architecture for MRI reconstruction and supports its claims through empirical results on fastMRI brain/knee datasets under 8x undersampling, including SSIM/PSNR stability and t-SNE visualizations of routing. No load-bearing derivations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described structure; the unsupervised routing is presented as a design choice whose effectiveness is assessed via post-training metrics rather than by construction from the inputs themselves. The central performance claims remain falsifiable against held-out data and do not reduce to self-definition.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption End-to-end variational networks can enforce physics-based data consistency in MRI reconstruction
invented entities (1)
-
MoRE module with sample-wise unsupervised routing
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Cardiac MRI: Recent progress and continued challenges,
J. P. Earls, V . B. Ho, T. K. Foo, E. Castillo, and S. D. Flamm, “Cardiac MRI: Recent progress and continued challenges,”Journal of Magnetic Resonance Imaging, vol. 16, no. 2, pp. 111–127, 2002. [Online]. Available: https://onlinelibrary.wiley.com/doi/abs/10.1002/jmri.10154
-
[2]
Recent advances in parallel imaging for MRI,
J. Hamilton, D. Franson, and N. Seiberlich, “Recent advances in parallel imaging for MRI,”Progress in Nuclear Magnetic Resonance Spectroscopy, vol. 101, pp. 71–95, 2017. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0079656517300031
2017
-
[3]
Deep-Learning Methods for Parallel Magnetic Resonance Imaging Reconstruction: A Survey of the Current Approaches, Trends, and Issues,
F. Knoll, K. Hammernik, C. Zhanget al., “Deep-Learning Methods for Parallel Magnetic Resonance Imaging Reconstruction: A Survey of the Current Approaches, Trends, and Issues,”IEEE Signal Processing Magazine, vol. 37, no. 1, pp. 128–140, 2020
2020
-
[4]
Results of the 2020 fastMRI Challenge for Machine Learning MR Image Reconstruction,
M. J. Muckley, B. Riemenschneider, A. Radmaneshet al., “Results of the 2020 fastMRI Challenge for Machine Learning MR Image Reconstruction,”IEEE Transactions on Medical Imaging, vol. 40, no. 9, pp. 2306–2317, 2021
2020
-
[5]
End-to-End Variational Networks for Accelerated MRI Reconstruction,
A. Sriram, J. Zbontar, T. Murrellet al., “End-to-End Variational Networks for Accelerated MRI Reconstruction,” 2020. [Online]. Available: https://arxiv.org/abs/2004.06688
arXiv 2020
-
[6]
The state-of-the-art in cardiac MRI reconstruction: Results of the CMRxRecon challenge in MICCAI 2023,
J. Lyu, C. Qin, S. Wanget al., “The state-of-the-art in cardiac MRI reconstruction: Results of the CMRxRecon challenge in MICCAI 2023,” Medical Image Analysis, vol. 101, p. 103485, 2025. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S1361841525000337
2023
-
[7]
F. Wang, Z. Wang, Y . Liet al., “Towards Modality- and Sampling- Universal Learning Strategies for Accelerating Cardiovascular Imaging: Summary of the CMRxRecon2024 Challenge,” Dec. 2025. [Online]. Available: https://arxiv.org/abs/2503.03971
arXiv 2025
-
[8]
Robustness of Deep Learning for Accelerated MRI: Benefits of Diverse Training Data,
K. Lin and R. Heckel, “Robustness of Deep Learning for Accelerated MRI: Benefits of Diverse Training Data,” 2024. [Online]. Available: https://arxiv.org/abs/2312.10271
arXiv 2024
-
[9]
“A Comprehensive Survey of Mixture-of-Experts: Algorithms, Theory, and Applications, author=Siyuan Mu and Sen Lin,” 2026. [Online]. Available: https://arxiv.org/abs/2503.07137
arXiv 2026
-
[10]
Sparsely Activated Mixture-of-Experts are Robust Multi-Task Learners,
S. Gupta, S. Mukherjee, K. Subudhiet al., “Sparsely Activated Mixture-of-Experts are Robust Multi-Task Learners,” 2022. [Online]. Available: https://arxiv.org/abs/2204.07689
arXiv 2022
-
[11]
Rethinking U-Net: Task- Adaptive Mixture of Skip Connections for Enhanced Medical Image Segmentation,
Z. Luo, X. Zhu, L. Zhang, and B. Sun, “Rethinking U-Net: Task- Adaptive Mixture of Skip Connections for Enhanced Medical Image Segmentation,”Proceedings of the AAAI Conference on Artificial Intelligence, vol. 39, no. 6, p. 5874–5882, Apr. 2025. [Online]. Available: https://ojs.aaai.org/index.php/AAAI/article/view/32627
2025
-
[12]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikovet al., “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale,” 2021. [Online]. Available: https://arxiv.org/abs/2010.11929
Pith/arXiv arXiv 2021
-
[13]
The Prevalence of Code Smells in Machine Learning projects,
Z. Deng and J. Campbell, “Sparse Mixture-of-Experts for Non- Uniform Noise Reduction in MRI Images,” in2025 IEEE/CVF Winter Conference on Applications of Computer Vision Workshops (WACVW). IEEE, Feb. 2025, p. 260–268. [Online]. Available: http://dx.doi.org/10.1109/W ACVW65960.2025.00036
work page doi:10.1109/w 2025
-
[14]
fastMRI: An Open Dataset and Benchmarks for Accelerated MRI,
J. Zbontar, F. Knoll, A. Sriramet al., “fastMRI: An Open Dataset and Benchmarks for Accelerated MRI,” 2019. [Online]. Available: https://arxiv.org/abs/1811.08839
Pith/arXiv arXiv 2019
-
[15]
U-Net: Convolutional Networks for Biomedical Image Segmentation,
O. Ronneberger, P. Fischer, and T. Brox, “U-Net: Convolutional Networks for Biomedical Image Segmentation,” 2015. [Online]. Available: https://arxiv.org/abs/1505.04597
Pith/arXiv arXiv 2015
-
[16]
Image Super-Resolution Using Very Deep Residual Channel Attention Networks,
Y . Zhang, K. Li, K. Liet al., “Image Super-Resolution Using Very Deep Residual Channel Attention Networks,” 2018. [Online]. Available: https://arxiv.org/abs/1807.02758
Pith/arXiv arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.